Seguimiento de modelos de Machine Learning con MLflow y Azure Machine Learning
SE APLICA A:  Azure ML del SDK de Python v1
Azure ML del SDK de Python v1
En este artículo, obtendrá información sobre cómo habilitar MLflow Tracking, para conectar Azure Machine Learning como el back-end de experimentos de MLflow.
MLflow es una biblioteca de código abierto para administrar el ciclo de vida de los experimentos de aprendizaje automático. MLFlow Tracking es un componente de MLflow que lleva a cabo un registro y un seguimiento de las métricas de ejecución de entrenamiento y de los artefactos del modelo, independientemente del entorno del experimento (localmente en su equipo, en un destino de proceso remoto, en una máquina virtual o en un clúster de Azure Databricks).
Consulte MLflow y Azure Machine Learning para ver todas las funcionalidades admitidas de MLflow y Azure Machine Learning, incluida la compatibilidad con MLflow Project (versión preliminar) y la implementación de modelos.
Sugerencia
Si desea realizar un seguimiento de los experimentos que se ejecutan en Azure Databricks o Azure Synapse Analytics, consulte los artículos dedicados Seguimiento de experimentos de Aprendizaje automático de Azure Databricks con MLflow y Azure Machine Learning o Seguimiento de experimentos de aprendizaje automático de Azure Synapse Analytics con MLflow y Azure Machine Learning.
Nota:
La información de este documento va destinada principalmente a aquellos científicos de datos y desarrolladores que deseen supervisar el proceso de entrenamiento del modelo. Los administradores que estén interesados en la supervisión del uso de recursos y eventos desde Azure Machine Learning, como cuotas, trabajos de entrenamiento completados o implementaciones de modelos completadas pueden consultar Supervisión de Azure Machine Learning.
Requisitos previos
Instale el paquete
mlflow.- Puede usar el cliente MLflow Skinny, que es un paquete MLflow ligero sin dependencias de almacenamiento SQL, servidor, interfaz de usuario o ciencia de datos. Esto se recomienda para los usuarios que necesitan principalmente las funcionalidades de seguimiento y registro sin importar el conjunto completo de características de MLflow, incluidas las implementaciones.
Instale el paquete
azureml-mlflow.Instale y configure la CLI de Azure Machine Learning (v1) y asegúrese de instalar la extensión ml.
Importante
Algunos de los comandos de la CLI de Azure de este artículo usan la extensión
azure-cli-mlo v1 para Azure Machine Learning. La compatibilidad con la extensión v1 finalizará el 30 de septiembre de 2025. La extensión v1 se podrá instalar y usar hasta esa fecha.Se recomienda pasar a la extensión
ml, o v2, antes del 30 de septiembre de 2025. Para más información sobre la extensión v2, consulte Extensión de la CLI de Azure ML y SDK de Python v2.Instale y configure el SDK de Azure Machine Learning para Python.
Seguimiento de ejecuciones desde la máquina local o el proceso remoto
El seguimiento mediante MLflow con Azure Machine Learning le permite almacenar las ejecuciones de las métricas y los artefactos registrados que se ejecutaron en su máquina local, en el área de trabajo de Azure Machine Learning.
Configuración del entorno de seguimiento
Para realizar un seguimiento de una ejecución que no se ejecuta en el proceso de Azure Machine Learning (a partir de ahora denominado "proceso local"), debe apuntar el proceso local al URI de seguimiento de MLflow de Azure Machine Learning.
Nota:
Cuando se ejecuta en Azure Compute (Azure Notebooks, en cuadernos de Jupyter Notebooks hospedados en instancias de Azure Compute o clústeres de proceso), no es necesario configurar el URI de seguimiento. Se configura automáticamente.
- Uso del SDK de Azure Machine Learning
- Uso de una variable de entorno
- Creación del URI de seguimiento de MLflow
SE APLICA A: Azure ML del SDK de Python v1
Puede obtener el URI de seguimiento MLflow en Azure Machine Learning con el SDK de Azure Machine Learning v1 para Python. Asegúrese de que tiene instalada la biblioteca azureml-sdk en el clúster que usa. En el ejemplo siguiente, se obtiene el URI de seguimiento de MLFLow único asociado al área de trabajo. A continuación, el método set_tracking_uri() apunta el URI de seguimiento de MLflow a ese URI.
Uso del archivo de configuración del área de trabajo:
from azureml.core import Workspace import mlflow ws = Workspace.from_config() mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())Sugerencia
Puede descargar el archivo de configuración del área de trabajo mediante los pasos siguientes:
- Vaya a Estudio de Azure Machine Learning.
- Haga clic en la esquina superior derecha de la página -> Descargar archivo de configuración.
- Guarde el archivo
config.jsonen el mismo directorio en el que está trabajando.
Uso del identificador de suscripción, el nombre del grupo de recursos y el nombre del área de trabajo:
from azureml.core import Workspace import mlflow #Enter details of your Azure Machine Learning workspace subscription_id = '<SUBSCRIPTION_ID>' resource_group = '<RESOURCE_GROUP>' workspace_name = '<AZUREML_WORKSPACE_NAME>' ws = Workspace.get(name=workspace_name, subscription_id=subscription_id, resource_group=resource_group) mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
Establecimiento del nombre del experimento
Todas las ejecuciones de MLflow se registran en el experimento activo. Las ejecuciones se registran de manera predeterminada en un experimento denominado Default que se crea automáticamente. Para configurar el experimento en el que desea trabajar, use el comando mlflow.set_experiment() de MLflow.
experiment_name = 'experiment_with_mlflow'
mlflow.set_experiment(experiment_name)
Sugerencia
Al enviar trabajos mediante el SDK de Azure Machine Learning, puede establecer el nombre del experimento mediante la propiedad experiment_name al enviarlo. No es necesario configurarlo en el script de entrenamiento.
Inicio de la ejecución del entrenamiento
Tras establecer el nombre del experimento de MLflow, puede iniciar la ejecución del entrenamiento con start_run(). Después, use log_metric() para activar la API de registro de MLflow y empezar a registrar las métricas de la ejecución de entrenamiento.
import os
from random import random
with mlflow.start_run() as mlflow_run:
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
Para más información sobre cómo registrar métricas, parámetros y artefactos en una ejecución mediante la vista de MLflow, consulte Registro y visualización de métricas.
Seguimiento de trabajos que se ejecutan en Azure Machine Learning
SE APLICA A: Azure ML del SDK de Python v1
Las ejecuciones remotas (trabajos) permiten entrenar los modelos de forma más sólida y repetitiva. También pueden aprovechar los procesos más eficaces, como los clústeres de proceso de Machine Learning. Consulte Uso de destinos de proceso del entrenamiento del modelo para obtener información sobre las distintas opciones de proceso.
Al enviar trabajos, Azure Machine Learning configura automáticamente MLflow para que funcione con el área de trabajo en la que se ejecuta este. Esto significa que no es necesario configurar el URI de seguimiento de MLflow. Además, los experimentos se denominan automáticamente en función de los detalles de la realización del experimento.
Importante
Al enviar trabajos de entrenamiento a Azure Machine Learning, no es necesario configurar el URI de seguimiento de MLflow en la lógica de entrenamiento, ya que ya está configurado. No es necesario configurar el nombre del experimento en la rutina de entrenamiento.
Creación de una rutina de entrenamiento
En primer lugar, debe crear un subdirectorio src y crear un archivo con el código de entrenamiento en un archivo train.py en el subdirectorio src. Todo el código de entrenamiento entrará en el subdirectorio src, incluido train.py.
El código de entrenamiento se toma de este ejemplo de MLfLow en el repositorio de ejemplo de Azure Machine Learning.
Copie este código en el archivo:
# imports
import os
import mlflow
from random import random
# define functions
def main():
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
# run functions
if __name__ == "__main__":
# run main function
main()
Configuración del experimento
Deberá usar Python para enviar el experimento a Azure Machine Learning. En un cuaderno o un archivo de Python, configure el proceso y el entorno de ejecución de entrenamiento con la clase Environment.
from azureml.core import Environment
from azureml.core.conda_dependencies import CondaDependencies
env = Environment(name="mlflow-env")
# Specify conda dependencies with scikit-learn and temporary pointers to mlflow extensions
cd = CondaDependencies.create(
conda_packages=["scikit-learn", "matplotlib"],
pip_packages=["azureml-mlflow", "pandas", "numpy"]
)
env.python.conda_dependencies = cd
Después, construya ScriptRunConfig con el proceso remoto como destino de proceso.
from azureml.core import ScriptRunConfig
src = ScriptRunConfig(source_directory="src",
script=training_script,
compute_target="<COMPUTE_NAME>",
environment=env)
Con esta configuración del proceso y de la ejecución de entrenamiento, use el método Experiment.submit() para enviar una ejecución. Este método establece automáticamente el identificador URI de seguimiento de MLflow y dirige el registro de MLflow al área de trabajo.
from azureml.core import Experiment
from azureml.core import Workspace
ws = Workspace.from_config()
experiment_name = "experiment_with_mlflow"
exp = Experiment(workspace=ws, name=experiment_name)
run = exp.submit(src)
Visualización de las métricas y los artefactos en el área de trabajo
Las métricas y los artefactos procedentes del registro de MLflow se supervisan en el área de trabajo. Para verlos en cualquier momento, vaya al área de trabajo y busque el experimento por su nombre en el área de trabajo en Azure Machine Learning Studio. O bien, ejecute el código siguiente:
Recupere la métrica de ejecución usando get_run() de MLflow.
from mlflow.tracking import MlflowClient
# Use MlFlow to retrieve the run that was just completed
client = MlflowClient()
run_id = mlflow_run.info.run_id
finished_mlflow_run = MlflowClient().get_run(run_id)
metrics = finished_mlflow_run.data.metrics
tags = finished_mlflow_run.data.tags
params = finished_mlflow_run.data.params
print(metrics,tags,params)
Para ver los artefactos de una ejecución, puede usar MlFlowClient.list_artifacts()
client.list_artifacts(run_id)
Para descargar un artefacto en el directorio actual, puede usar MLFlowClient.download_artifacts()
client.download_artifacts(run_id, "helloworld.txt", ".")
Para más información sobre cómo recuperar información de experimentos y ejecuciones en Azure Machine Learning mediante la vista de MLflow Administración de experimentos y ejecuciones con MLflow.
Comparación y consulta
Compare y consulte todas las ejecuciones de MLflow en el área de trabajo de Azure Machine Learning con el código siguiente. Obtenga más información sobre cómo consultar ejecuciones con MLflow.
from mlflow.entities import ViewType
all_experiments = [exp.experiment_id for exp in MlflowClient().list_experiments()]
query = "metrics.hello_metric > 0"
runs = mlflow.search_runs(experiment_ids=all_experiments, filter_string=query, run_view_type=ViewType.ALL)
runs.head(10)
Registro automático
Con Azure Machine Learning y MLFlow, los usuarios pueden registrar métricas, parámetros de modelo y artefactos de modelo automáticamente al entrenar un modelo. Se admiten diversas bibliotecas de aprendizaje automático populares.
Para habilitar el registro automático, inserte el código siguiente antes del código de entrenamiento:
mlflow.autolog()
Obtenga más información sobre el registro automático con MLflow.
Administración de modelos
Registre y realice un seguimiento de los modelos con el registro de modelos de Azure Machine Learning, que admite el registro de modelos de MLflow. Los modelos de Azure Machine Learning se alinean con el esquema de modelos de MLflow, lo que facilita la exportación e importación de estos modelos en diferentes flujos de trabajo. Los metadatos relacionados con MLflow, como el id. de ejecución, también se supervisan con el modelo registrado para la rastreabilidad. Los usuarios pueden enviar las ejecuciones de entrenamiento, registrar e implementar los modelos generados a partir de las ejecuciones de MLflow.
Si quiere implementar y registrar el modelo preparado para producción en un solo paso, consulte Implementación y registro de modelos de MLflow.
Para registrar y ver un modelo a partir de una ejecución, siga estos pasos:
Una vez completada la ejecución, llame al método
register_model().# the model folder produced from a run is registered. This includes the MLmodel file, model.pkl and the conda.yaml. model_path = "model" model_uri = 'runs:/{}/{}'.format(run_id, model_path) mlflow.register_model(model_uri,"registered_model_name")Vea el modelo registrado en su área de trabajo con Azure Machine Learning Studio
En el ejemplo siguiente, el modelo registrado
my-modeltiene etiquetados metadatos de seguimiento de MLflow.
Seleccione la pestaña Artefactos para ver todos los archivos de modelo que se alinean con el esquema de modelos de MLflow (conda.yaml, MLmodel, model.pkl).
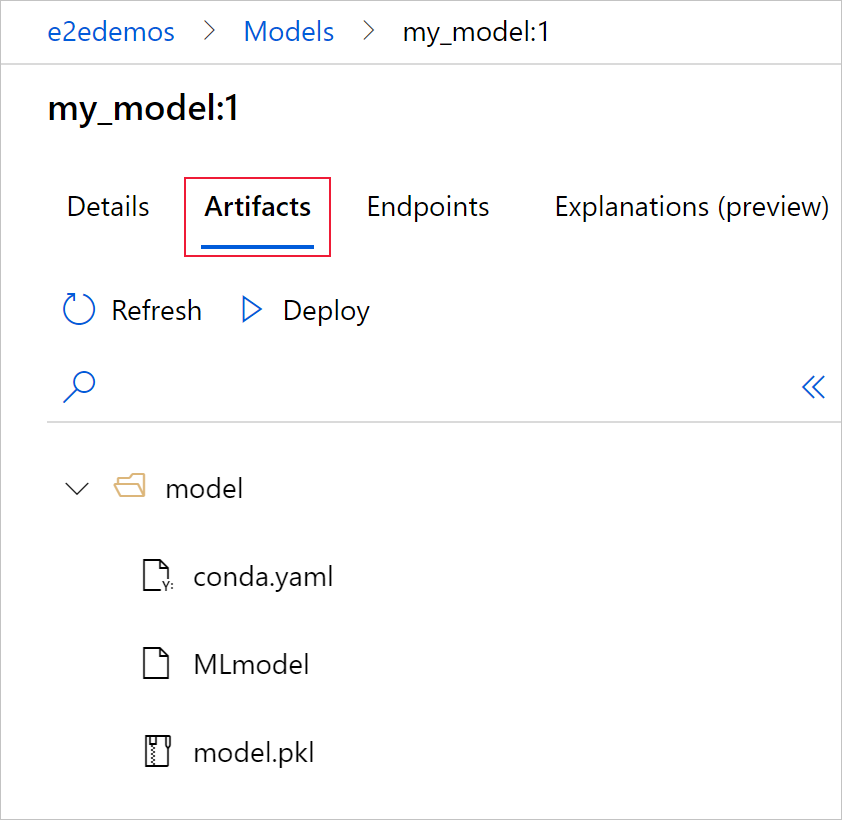
Seleccione MLmodel para ver el archivo MLmodel generado por la ejecución.

Limpieza de recursos
Si no tiene pensado usar los artefactos o las métricas registradas en el área de trabajo, la funcionalidad para eliminarlos de forma individual no está disponible actualmente. Por ello, deberá eliminar el grupo de recursos que contiene la cuenta de almacenamiento y el área de trabajo para no incurrir en cargos:
En Azure Portal, seleccione Grupos de recursos a la izquierda del todo.

En la lista, seleccione el grupo de recursos que creó.
Seleccione Eliminar grupo de recursos.
Escriba el nombre del grupo de recursos. A continuación, seleccione Eliminar.
Cuadernos de ejemplo
En MLflow con cuadernos de Azure Machine Learning se demuestran y se analizan con mayor profundidad los conceptos presentados en este artículo. Consulte también el repositorio controlado por la comunidad, AzureML-Examples.
Pasos siguientes
- Implementación de modelos con MLflow.
- Supervise los modelos de producción para el desfase de datos.
- Seguimiento de las ejecuciones de Azure Databricks con MLflow.
- Administra sus modelos.