Alta disponibilidad del escalado vertical de SAP HANA con Azure NetApp Files en SUSE Enterprise Linux
En este artículo se describe cómo configurar la replicación del sistema de SAP HANA en una implementación de escalado vertical, cuando los sistemas de archivos de HANA se montan mediante NFS con Azure NetApp Files. En las configuraciones de ejemplo y comandos de instalación, se utiliza el número de instancia 03 y el identificador del sistema de HANA HN1. La replicación de SAP HANA se realiza con un nodo principal y al menos uno secundario.
Si los pasos de este documento se marcan con los siguientes prefijos, el significado es el siguiente:
- [A] : el paso se aplica a todos los nodos.
- [1]: El paso solo se aplica al nodo 1.
- [2]: El paso solo se aplica al nodo 2.
Lea primero las notas y los documentos de SAP siguientes:
- La nota de SAP 1928533 tiene:
- La lista de tamaños de máquina virtual de Azure que se admiten para la implementación del software de SAP.
- Información importante sobre capacidad según los tamaños de máquina virtual de Azure.
- Las combinaciones admitidas de software y sistema operativo y base de datos de SAP.
- Versión necesaria del kernel de SAP para Windows y Linux en Azure.
- La nota de SAP 2015553 enumera los requisitos previos para las implementaciones de software de SAP admitidas por SAP en Azure.
- La nota de SAP 405827 muestra el sistema de archivos recomendado para el entorno de HANA.
- La nota de SAP 2684254 contiene configuraciones recomendadas del sistema operativo para SUSE Linux Enterprise Server (SLES) 15 y SLES para SAP Applications 15.
- La nota de SAP 1944799 contiene instrucciones de SAP HANA para la instalación del sistema operativo de SLES.
- La nota de SAP 2178632 contiene información detallada sobre todas las métricas de supervisión notificadas para SAP en Azure.
- La nota de SAP 2191498 incluye la versión de SAP Host Agent necesaria para Linux en Azure.
- La nota de SAP 2243692 incluye información acerca de las licencias de SAP en Linux en Azure.
- La nota de SAP 1999351 contiene más información de solución de problemas sobre la extensión de supervisión mejorada de Azure para SAP.
- La nota de SAP 1900823 incluye información sobre los requisitos de almacenamiento de SAP HANA.
- Las guías de procedimientos recomendados de alta disponibilidad de SUSE SAP contienen toda la información necesaria para la configuración de NetWeaver HA y la replicación del sistema de SAP HANA en el entorno local (para su uso como línea de base). Proporcionan información mucho más detallada.
- La wiki de la comunidad SAP contiene todas las notas de SAP que se necesitan para Linux.
- Planeación e implementación de Azure Virtual Machines para SAP en Linux
- Implementación de Azure Virtual Machines para SAP en Linux
- Implementación de DBMS de Azure Virtual Machines para SAP en Linux
- Documentación general de SLES:
- Configuración de un clúster de SAP HANA
- Notas de la versión de la Extensión 15 SP3 de alta disponibilidad para SLES
- Guía de protección de seguridad del sistema operativo para SAP HANA para SUSE Linux Enterprise Server 15
- Guía de SUSE Linux Enterprise Server for SAP Applications 15 SP3
- Automatización de SAP para SUSE Linux Enterprise Server for SAP Applications 15 SP3
- Supervisión de SAP para SUSE Linux Enterprise Server for SAP Applications 15 SP3
- Documentación de SLES específica de Azure:
- Aplicaciones de NetApp SAP en Microsoft Azure que usan Azure NetApp Files
- Volúmenes NFS v4.1 en Azure NetApp Files para SAP HANA
- Planeación e implementación de Azure Virtual Machines para SAP en Linux
Nota:
Este artículo contiene referencias a un término que Microsoft ya no utiliza. Cuando se elimine el término del software, se eliminará también de este artículo.
Información general
Tradicionalmente, en un entorno de escalado vertical, todos los sistemas de archivos de SAP HANA se montan desde el almacenamiento local. La configuración de alta disponibilidad de la replicación del sistema de SAP HANA en SUSE Enterprise Linux se publicó en Configuración de la replicación del sistema de SAP HANA en SLES.
Para lograr una alta disponibilidad en SAP HANA de un sistema de escalado vertical en recursos compartidos NFS de Azure NetApp Files, necesitamos una configuración de recursos adicional en el clúster. Esta configuración es necesaria para que los recursos de HANA puedan recuperarse si un nodo pierde el acceso a los recursos compartidos de NFS en Azure NetApp Files.
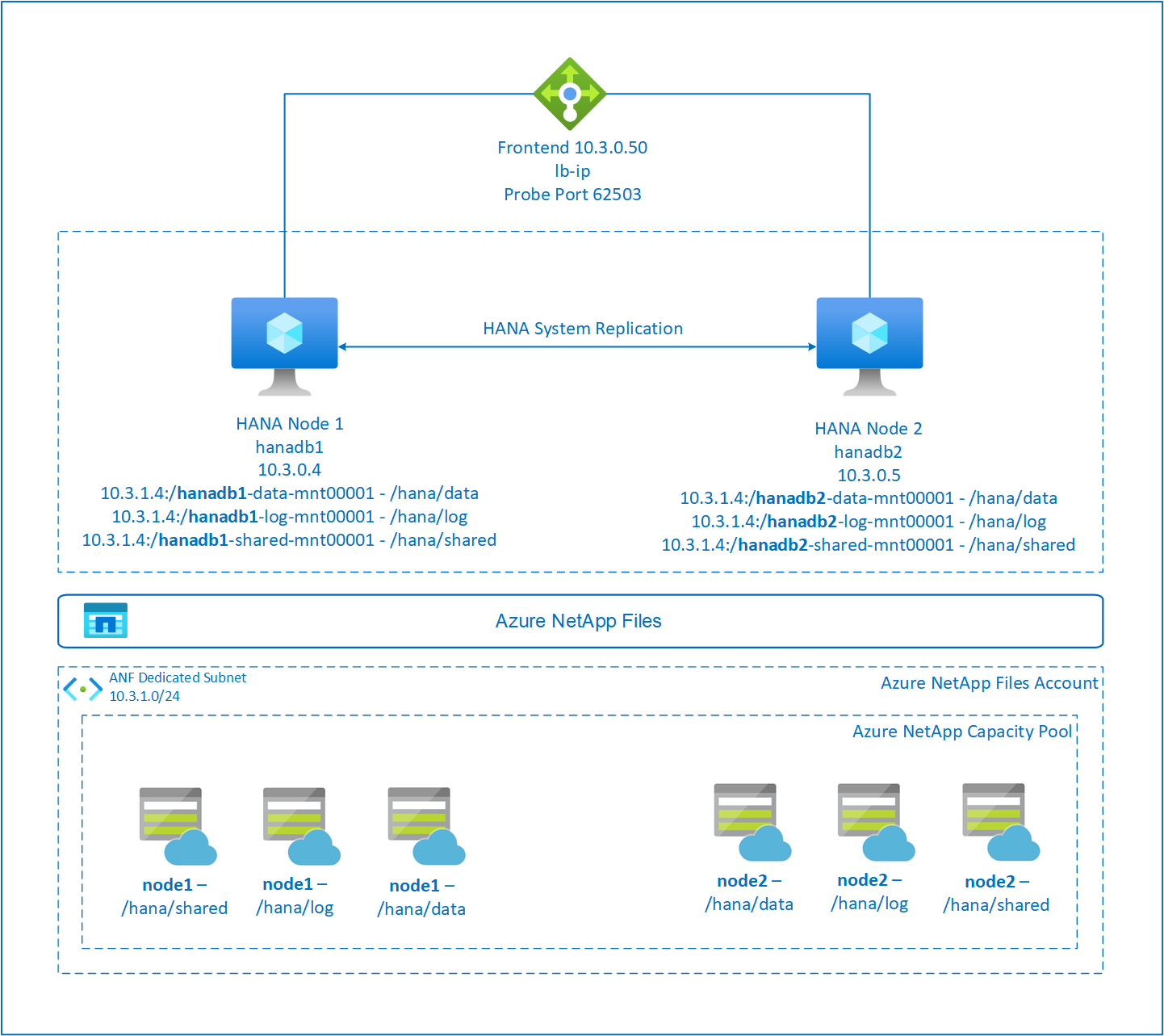
Los sistemas de archivos de SAP HANA se montan en recursos compartidos de NFS mediante Azure NetApp Files en cada nodo. Los sistemas de archivos /hana/data, /hana/log y /hana/shared son únicos para cada nodo.
Montado en el nodo 1 (hanadb1):
- 10.3.1.4:/hanadb1-data-mnt00001 en /hana/data
- 10.3.1.4:/hanadb1-log-mnt00001 en /hana/log
- 10.3.1.4:/hanadb1-shared-mnt00001 en /hana/shared
Montado en el nodo 2 (hanadb2):
- 10.3.1.4:/hanadb2-data-mnt00001 en /hana/data
- 10.3.1.4:/hanadb2-log-mnt00001 en /hana/log
- 10.3.1.4:/hanadb2-shared-mnt0001 en /hana/shared
Nota:
Los sistemas de archivos /hana/shared, /hana/data y /hana/log no se comparten entre los dos nodos. Cada nodo del clúster tiene sus propios sistemas de archivos independientes.
En la configuración de la replicación del sistema de SAP HANA de alta disponibilidad se usa un nombre de host virtual dedicado y direcciones IP virtuales. En Azure, se requiere un equilibrador de carga para usar una dirección IP virtual. La configuración presentada muestra un equilibrador de carga con:
- Dirección IP de configuración de front-end: 10.3.0.50 para hn1-db
- Puerto de sondeo: 62503
Configuración de la infraestructura de Azure NetApp Files
Antes de continuar con la configuración de la infraestructura de Azure NetApp Files, familiarícese con la documentación de Azure NetApp Files.
Azure NetApp Files está disponible en varias regiones de Azure. Compruebe si la región de Azure seleccionada ofrece Azure NetApp Files.
Para obtener información sobre la disponibilidad de Azure NetApp Files según la región de Azure, consulte Disponibilidad de Azure NetApp Files por región de Azure.
Consideraciones importantes
Al crear sus sistemas de escalado vertical de Azure NetApp Files para SAP HANA, tenga en cuenta las consideraciones importantes documentadas en Volúmenes NFS v4.1 en Azure NetApp Files para SAP HANA.
Dimensionamiento de la base de datos HANA en Azure NetApp Files
El rendimiento de un volumen de Azure NetApp Files es una función del tamaño del volumen y del nivel de servicio, como se documenta en Nivel de servicio para Azure NetApp Files.
Al diseñar la infraestructura para SAP HANA en Azure con Azure NetApp Files, tenga en cuenta las recomendaciones de Volúmenes NFS v4.1 en Azure NetApp Files para SAP HANA.
La configuración de este artículo se presenta con volúmenes sencillos de Azure NetApp Files.
Importante
En el caso de los sistemas de producción, donde el rendimiento es clave, se recomienda evaluar y considerar el uso de un Grupo de volúmenes de aplicación de Azure NetApp Files para SAP HANA.
Todos los comandos para montar /hana/shared en este artículo se presentan para los volúmenes de /hana/shared de NFSv4.1. Si implementó los volúmenes /hana/shared como volúmenes de NFSv3, no olvide ajustar los comandos de montaje de /hana/shared para NFSv3.
Implementación de recursos de Azure NetApp Files
En las siguientes instrucciones se supone que ya ha implementado la red virtual de Azure. Los recursos de Azure NetApp Files y las máquinas virtuales en las que esos recursos se montan se deben implementar en la misma red virtual de Azure o en redes virtuales emparejadas.
Cree una cuenta de NetApp en la región de Azure seleccionada. Para ello, siga las instrucciones en Creación de una cuenta de NetApp.
Configure el grupo de capacidad de Azure NetApp Files según disponibles en Configuración en un grupo de capacidad de Azure NetApp Files.
La arquitectura de HANA que se presenta en este artículo utiliza un único grupo de capacidad de Azure NetApp Files en el nivel de servicio Ultra. Para las cargas de trabajo de HANA en Azure, se recomienda usar el nivel de servicio Ultra o Premium de Azure NetApp Files.
Delegue una subred en Azure NetApp Files tal como se describe en las instrucciones de Delegación de una subred en Azure NetApp Files.
Implemente los volúmenes de Azure NetApp Files según las instrucciones de Creación de un volumen de NFS para Azure NetApp Files.
Cuando vaya a implementar los volúmenes, asegúrese de seleccionar la versión NFSv4.1. Implemente los volúmenes en la subred de Azure NetApp Files designada. Las direcciones IP de los volúmenes de Azure NetApp Files se asignan automáticamente.
Los recursos de Azure NetApp Files y las VM de Azure deben estar en la misma red virtual de Azure o en redes virtuales de Azure del mismo nivel. Por ejemplo, hanadb1-data-mnt00001, hanadb1-log-mnt00001, etc. son los nombres de los volúmenes y nfs://10.3.1.4/hanadb1-data-mnt00001, nfs://10.3.1.4/hanadb1-log-mnt00001, etc. son las rutas de acceso de archivo de los volúmenes de Azure NetApp Files.
En hanadb1:
- Volumen hanadb1-data-mnt00001 (nfs://10.3.1.4:/hanadb1-data-mnt00001)
- Volumen hanadb1-log-mnt00001 (nfs://10.3.1.4:/hanadb1-log-mnt00001)
- Volumen hanadb1-shared-mnt00001 (nfs://10.3.1.4:/hanadb1-shared-mnt00001)
En hanadb2:
- Volumen hanadb2-data-mnt00001 (nfs://10.3.1.4:/hanadb2-data-mnt00001)
- Volumen hanadb2-log-mnt00001 (nfs://10.3.1.4:/hanadb2-log-mnt00001)
- Volumen hanadb2-shared-mnt00001 (nfs://10.3.1.4:/hanadb2-shared-mnt00001)
Preparación de la infraestructura
El agente de recursos para SAP HANA se incluye en SUSE Linux Enterprise Server para SAP Applications. En Azure Marketplace se puede encontrar una imagen para SUSE Linux Enterprise Server para SAP Applications 12 o 15. Puede usar la imagen para implementar nuevas máquinas virtuales.
Implementación manual de VM de Linux mediante Azure Portal
Este documento asume que ya ha implementado un grupo de recursos, Azure Virtual Network y una subred.
Implemente máquinas virtuales para SAP HANA. Elija una imagen de SLES adecuada que sea compatible con el sistema HANA. Puede implementar una máquina virtual en cualquiera de las opciones de disponibilidad: conjunto de escalado de máquinas virtuales, zona de disponibilidad o conjunto de disponibilidad.
Importante
Asegúrese de que el sistema operativo que selecciona está certificado por SAP para SAP HANA en los tipos específicos de máquinas virtuales que tiene previsto usar en su implementación. Puede buscar los tipos de máquina virtual certificados por SAP HANA y sus versiones del sistema operativo en Plataformas IaaS certificadas para SAP HANA. Asegúrese de consultar los detalles del tipo de máquina virtual para obtener la lista completa de versiones de SO compatibles con SAP HANA para el tipo de máquina virtual específico.
Configuración de Azure Load Balancer
Durante la configuración de la máquina virtual, tiene una opción para crear o seleccionar el equilibrador de carga existente en la sección de redes. Siga los pasos siguientes para configurar un equilibrador de carga estándar para la configuración de alta disponibilidad de la base de datos de HANA.
Siga los pasos descritos en Creación de un equilibrador de carga para configurar un equilibrador de carga estándar para un sistema SAP de alta disponibilidad mediante Azure Portal. Durante la configuración del equilibrador de carga, tenga en cuenta los siguientes puntos:
- Configuración de IP de front-end: cree una dirección IP de front-end. Seleccione el mismo nombre de red virtual y subred que las máquinas virtuales de la base de datos.
- Grupo de back-end: cree un grupo de back-end y agregue máquinas virtuales de base de datos.
- Reglas de entrada: cree una regla de equilibrio de carga. Siga los mismos pasos para ambas reglas de equilibrio de carga.
- Dirección IP de front-end: seleccione una dirección IP de front-end.
- Grupo de back-end: seleccione un grupo de back-end.
- Puertos de alta disponibilidad: seleccione esta opción.
- Protocolo: seleccione TCP.
- Sondeo de estado: cree un sondeo de estado con los detalles siguientes:
- Protocolo: seleccione TCP.
- Puerto: por ejemplo, 625<instance-no.>.
- Intervalo: escriba 5.
- Umbral de sondeo: escriba 2.
- Tiempo de espera de inactividad (minutos): Escriba 30.
- Habilitar IP flotante: seleccione esta opción.
Nota:
No se respeta la propiedad de configuración del sondeo de estado numberOfProbes, también conocida como Umbral incorrecto en el portal. Para controlar el número de sondeos consecutivos correctos o erróneos, establezca la propiedad probeThreshold en 2. Actualmente, no es posible establecer esta propiedad mediante Azure Portal, por lo que debe usar la CLI de Azure o el comando de PowerShell.
Para obtener más información sobre los puertos necesarios para SAP HANA, lea el capítulo Connections to Tenant Databases (Conexiones a las bases de datos de inquilino) de la guía SAP HANA Tenant Databases (Bases de datos de inquilino de SAP HANA) o la nota de SAP 2388694.
Cuando las máquinas virtuales sin direcciones IP públicas se colocan en el grupo de back-end de una instancia interna de Azure Load Balancer estándar (sin dirección IP pública), no hay conectividad de salida a Internet a menos que se realicen más configuraciones para permitir el enrutamiento a puntos de conexión públicos. Para más información sobre cómo conseguir la conectividad de salida, consulte Conectividad de punto de conexión público para máquinas virtuales con Azure Standard Load Balancer en escenarios de alta disponibilidad de SAP.
Importante
- No habilite las marcas de tiempo TCP en VM de Azure que se encuentren detrás de Load Balancer. Si habilita las marcas de tiempo TCP provocará un error en los sondeos de estado. Establezca el parámetro
net.ipv4.tcp_timestampsen0. Para más información, consulte Sondeos de estado de Load Balancer y Nota de SAP 2382421. - Para evitar que saptune cambie el valor
net.ipv4.tcp_timestampsestablecido manualmente de0a nuevamente1, actualice la versión de saptune a la versión 3.1.1 o posterior. Para más información, consulte saptune 3.1.1: ¿Necesito actualizar?
Montaje de los volúmenes de Azure NetApp Files
[A] Cree puntos de montaje para los volúmenes de bases de datos HANA.
sudo mkdir -p /hana/data/HN1/mnt00001 sudo mkdir -p /hana/log/HN1/mnt00001 sudo mkdir -p /hana/shared/HN1[A] Compruebe la configuración del dominio NFS. Asegúrese de que el dominio esté configurado como dominio predeterminado de Azure NetApp Files, es decir, defaultv4iddomain.com, y de que la asignación se haya establecido en nobody.
sudo cat /etc/idmapd.confEjemplo:
[General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobodyImportante
Asegúrese de establecer el dominio NFS en /etc/idmapd.conf en la máquina virtual para que coincida con la configuración de dominio predeterminada en Azure NetApp Files: defaultv4iddomain.com. Si hay un error de coincidencia entre la configuración de dominio en el cliente NFS (es decir, la máquina virtual) y el servidor NFS (es decir, la configuración de Azure NetApp Files), los permisos para los archivos de los volúmenes de Azure NetApp Files que se montan en las máquinas virtuales se muestran como nobody.
[A] Edite
/etc/fstaben ambos nodos para montar permanentemente los volúmenes pertinentes para cada nodo. El siguiente ejemplo muestra cómo montar los volúmenes de forma permanente.sudo vi /etc/fstabAgregue las siguientes entradas en
/etc/fstaben ambos nodos.Ejemplo de hanadb1:
10.3.1.4:/hanadb1-data-mnt00001 /hana/data/HN1/mnt00001 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0 10.3.1.4:/hanadb1-log-mnt00001 /hana/log/HN1/mnt00001 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0 10.3.1.4:/hanadb1-shared-mnt00001 /hana/shared/HN1 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0Ejemplo de hanadb2:
10.3.1.4:/hanadb2-data-mnt00001 /hana/data/HN1/mnt00001 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0 10.3.1.4:/hanadb2-log-mnt00001 /hana/log/HN1/mnt00001 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0 10.3.1.4:/hanadb2-shared-mnt00001 /hana/shared/HN1 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0Monte todos los volúmenes.
sudo mount -aEn el caso de las cargas de trabajo que requieren un mayor rendimiento, considere la posibilidad de usar la opción de montaje
nconnect, como se describe en Volúmenes de NFS v4.1 en Azure NetApp Files para SAP HANA. Compruebe sinconnectes compatible con Azure NetApp Files en la versión de Linux.[A] Compruebe que todos los volúmenes de HANA están montados con la versión del protocolo NFS NFSv4.
sudo nfsstat -mCompruebe que la marca
versestá establecida en 4.1.Ejemplo de hanadb1:
/hana/log/HN1/mnt00001 from 10.3.1.4:/hanadb1-log-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.3.0.4,local_lock=none,addr=10.3.1.4 /hana/data/HN1/mnt00001 from 10.3.1.4:/hanadb1-data-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.3.0.4,local_lock=none,addr=10.3.1.4 /hana/shared/HN1 from 10.3.1.4:/hanadb1-shared-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.3.0.4,local_lock=none,addr=10.3.1.4[A] Compruebe nfs4_disable_idmapping. Debe establecerse en S. Para crear la estructura de directorios donde se encuentra nfs4_disable_idmapping, ejecute el comando mount. No podrá crear manualmente el directorio en
/sys/modules, ya que el acceso está reservado para el kernel y los controladores.#Check nfs4_disable_idmapping sudo cat /sys/module/nfs/parameters/nfs4_disable_idmapping #If you need to set nfs4_disable_idmapping to Y sudo echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmapping #Make the configuration permanent sudo echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.conf
Instalación de SAP HANA
[A] Configuración de la resolución del nombre de todos los hosts.
Puede usar un servidor DNS o modificar el archivo
/etc/hostsen todos los nodos. En este ejemplo se muestra cómo utilizar el archivo/etc/hosts. Reemplace la dirección IP y el nombre de host en los siguientes comandos:sudo vi /etc/hostsInserte las líneas siguientes en el archivo
/etc/hosts. Cambie la dirección IP y el nombre de host para que coincidan con su entorno.10.3.0.4 hanadb1 10.3.0.5 hanadb2[A] Prepare el sistema operativo para ejecutar SAP HANA en Azure NetApp con NFS, tal como se describe en la Nota de SAP 3024346: Configuración del kernel de Linux para NetApp NFS. Cree el archivo de configuración
/etc/sysctl.d/91-NetApp-HANA.confpara las opciones de configuración de NetApp.sudo vi /etc/sysctl.d/91-NetApp-HANA.confAgregue las siguientes entradas en el archivo de configuración:
net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[A] Cree el archivo de configuración
/etc/sysctl.d/ms-az.confcon más opciones de optimización.sudo vi /etc/sysctl.d/ms-az.confAgregue las siguientes entradas en el archivo de configuración:
net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10Sugerencia
Evite establecer
net.ipv4.ip_local_port_rangeynet.ipv4.ip_local_reserved_portsexplícitamente en los archivos de configuración sysctl para permitir que el agente de host de SAP administre los intervalos de puertos. Para más información, consulte la Nota de SAP 2382421.[A] Ajuste la configuración de
sunrpc, como se recomienda en la Nota de SAP 3024346 - Configuración del kernel de Linux para NetApp NFS.sudo vi /etc/modprobe.d/sunrpc.confInserte la línea siguiente:
options sunrpc tcp_max_slot_table_entries=128[A] Configure SLES para HANA.
Configure SLES como se describe en las notas de SAP siguientes en función de la versión de SLES:
- 2684254 Configuración del sistema operativo recomendada para SLES 15 o SLES for SAP Applications 15
- 2205917 Configuración del sistema operativo recomendada para SLES 12 o SLES for SAP Applications 12
- 2455582 Linux: Ejecución de aplicaciones SAP compiladas con GCC 6.x
- 2593824 Linux: Ejecución de aplicaciones SAP compiladas con GCC 7.x
- 2886607 Linux: Ejecución de aplicaciones SAP compiladas con GCC 9.x
[A] Instale SAP HANA.
A partir de HANA 2.0 SPS 01, los contenedores de base de datos multiinquilino (MDC) son la opción predeterminada. Al instalar el sistema HANA, SYSTEMDB y un inquilino con el mismo SID se crean juntos. En algunos casos, no se recomienda el inquilino predeterminado. En caso de que no desee crear un inquilino inicial junto con la instalación, siga las instrucciones de la nota de SAP 2629711.
Inicie el programa
hdblcmdesde el directorio de software de instalación de HANA../hdblcmEscriba los siguientes valores en el símbolo del sistema:
- En Choose installation (Elegir instalación): escriba 1 (para la instalación).
- En Select additional components for installation (Seleccionar componentes adicionales para la instalación): escriba 1.
- En Enter Installation Path [/hana/shared] (Especificar ruta de acceso de instalación [/hana/shared]): presione Entrar para aceptar el valor predeterminado.
- En Enter Local Host Name [..] (Especificar nombre de host local [..]): presione Entrar para aceptar el valor predeterminado.
- En Do you want to add additional hosts to the system? (y/n) [n] (¿Desea agregar hosts adicionales al sistema? (s/n) [n]): seleccione n.
- En Enter SAP HANA System ID (Especificar id. del sistema de SAP HANA): escriba HN1.
- En Enter Instance Number [00] (Especificar número de instancia [00]): escriba 03.
- En Select Database Mode / Enter Index [1] (Seleccionar modo de base de datos o escribir índice [1]): presione Entrar para aceptar el valor predeterminado.
- En Select System Usage / Enter Index [4] (Seleccionar uso del sistema o especificar el índice [4]): escriba 4 (para personalizar).
- En Enter Location of Data Volumes [/hana/data] (Especificar ubicación de volúmenes de datos [/hana/data]): presione Entrar para aceptar el valor predeterminado.
- En Enter Location of Log Volumes [/hana/log] (Especificar ubicación de volúmenes de registro [/hana/log)]: presione Entrar para aceptar el valor predeterminado.
- En Restrict maximum memory allocation? [n] (¿Restringir la asignación de memoria máxima? [n]: presione Entrar para aceptar el valor predeterminado.
- En Enter Certificate Host Name For Host '...' [...] (Especificar nombre de host de certificado para host '...' [...]): presione Entrar para aceptar el valor predeterminado.
- En Enter SAP Host Agent User (sapadm) Password (Especificar contraseña de usuario de agente de host de SAP (sapadm)): escriba la contraseña de usuario del agente de host.
- En Confirm SAP Host Agent User (sapadm) Password (Confirmar contraseña de usuario de agente de host de SAP (sapadm)): escriba de nuevo la contraseña de usuario del agente de host para confirmar.
- En Enter System Administrator (hn1adm) Password (Especificar contraseña de administrador del sistema (hn1adm)): escriba la contraseña del administrador del sistema.
- En Confirm System Administrator (hn1adm) Password (Confirmar contraseña de administrador del sistema (hn1adm)): escriba de nuevo la contraseña del administrador del sistema para confirmar.
- En Enter System Administrator Home Directory [/usr/sap/HN1/home] (Especificar directorio principal de administrador del sistema [/usr/sap/HN1/home]): presione Entrar para aceptar el valor predeterminado.
- En Enter System Administrator Login Shell [/bin/sh] (Especificar shell de inicio de sesión de administrador del sistema [/bin/sh]): presione Entrar para aceptar el valor predeterminado.
- En Enter System Administrator User ID [1001] (Especificar identificador de usuario de administrador del sistema [1001]): presione Entrar para aceptar el valor predeterminado.
- En Enter ID of User Group (sapsys) [79] [Escriba el id. del grupo de usuarios (sapsys)] [79]: presione Entrar para aceptar el valor predeterminado.
- En Enter Database User (SYSTEM) Password (Especificar contraseña de usuario de base de datos (SYSTEM)): escriba la contraseña del usuario de la base de datos.
- En Confirm Database User (SYSTEM) Password (Confirmar contraseña de usuario de base de datos (SYSTEM)): escriba de nuevo la contraseña del usuario de la base de datos para confirmar.
- En Restart system after machine reboot? [n] (Reiniciar el sistema tras el reinicio de la máquina? [n]): presione Entrar para aceptar el valor predeterminado.
- En Do you want to continue? (y/n) (¿Desea continuar? (s/n)): valide el resumen. Escriba s para continuar.
[A] Actualización del agente de host de SAP.
Descargue el archivo más reciente del agente de host de SAP desde SAP Software Center y ejecute el siguiente comando para actualizar el agente. Reemplace la ruta de acceso al archivo para que apunte al archivo que descargó.
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP Host Agent SAR>
Configure SAP HANA system replication (Configuración de la replicación del sistema de SAP HANA)
Siga los pasos de Replicación del sistema de SAP HANA para configurar la replicación.
Configuración de clúster
En esta sección se describen los pasos necesarios para que el clúster funcione sin problemas cuando SAP HANA está instalado en recursos compartidos de NFS mediante Azure NetApp Files.
Creación de un clúster de Pacemaker
Siga los pasos de Configuración de Pacemaker en SUSE Enterprise Linux en Azure para crear un clúster de Pacemaker básico para este servidor HANA.
Implementación de los enlaces de HANA SAPHanaSR y susChkSrv
Este importante paso optimiza la integración con el clúster y mejora la detección cuando es necesaria una conmutación por error del clúster. Se recomienda encarecidamente configurar los enlaces de Python SAPHanaSR y susChkSrv. Siga los pasos de Implementación de los enlaces de replicación del sistema Python SAPHanaSR/SAPHanaSR-angi y susChkSrv.
Configuración de recursos de clúster de SAP HANA
En esta sección se describen los pasos necesarios para configurar los recursos de clúster de SAP HANA.
Creación de recursos de clúster de SAP HANA
Siga los pasos de Creación de recursos de clúster de SAP HANA para crear los recursos de clúster del servidor HANA. Una vez creados los recursos, debería ver el estado del clúster con el comando siguiente:
sudo crm_mon -r
Ejemplo:
# Online: [ hn1-db-0 hn1-db-1 ]
# Full list of resources:
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
Creación de recursos del sistema de archivos
El sistema de archivos /hana/shared/SID es necesario para la operación de HANA y también para las acciones de supervisión de Pacemaker que determinan el estado de HANA. Implemente agentes de recursos para supervisar y actuar en caso de errores. La sección contiene dos opciones, una para SAPHanaSR y otra para SAPHanaSR-angi.
Cree un recurso de clúster de sistema de archivos ficticio. Este supervisará y avisará de los errores si hay un problema al acceder al sistema de archivos montado en NFS /hana/shared. Esto permite que el clúster desencadene la conmutación por error, en caso de que se produzca un problema al acceder a /hana/shared. Para más información, vea Control de recursos compartidos de NFS con errores en el clúster de alta disponibilidad de SUSE para la replicación del sistema HANA.
[A] Cree la estructura de directorios en ambos nodos.
sudo mkdir -p /hana/shared/HN1/check sudo mkdir -p /hana/shared/check[1] Configure el clúster para agregar la estructura de directorios para la supervisión.
sudo crm configure primitive rsc_fs_check_HN1_HDB03 Filesystem params \ device="/hana/shared/HN1/check/" \ directory="/hana/shared/check/" fstype=nfs \ options="bind,defaults,rw,hard,rsize=262144,wsize=262144,proto=tcp,noatime,_netdev,nfsvers=4.1,lock,sec=sys" \ op monitor interval=120 timeout=120 on-fail=fence \ op_params OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 \ op stop interval=0 timeout=120[1] Clone y compruebe el volumen recién configurado en el clúster.
sudo crm configure clone cln_fs_check_HN1_HDB03 rsc_fs_check_HN1_HDB03 meta clone-node-max=1 interleave=trueEjemplo:
sudo crm status # Cluster Summary: # Stack: corosync # Current DC: hanadb1 (version 2.0.5+20201202.ba59be712-4.9.1-2.0.5+20201202.ba59be712) - partition with quorum # Last updated: Tue Nov 2 17:57:39 2021 # Last change: Tue Nov 2 17:57:38 2021 by root via crm_attribute on hanadb1 # 2 nodes configured # 11 resource instances configured # Node List: # Online: [ hanadb1 hanadb2 ] # Full List of Resources: # Clone Set: cln_azure-events [rsc_azure-events]: # Started: [ hanadb1 hanadb2 ] # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]: # rsc_SAPHanaTopology_HN1_HDB03 (ocf::suse:SAPHanaTopology): Started hanadb1 (Monitoring) # rsc_SAPHanaTopology_HN1_HDB03 (ocf::suse:SAPHanaTopology): Started hanadb2 (Monitoring) # Clone Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] (promotable): # rsc_SAPHana_HN1_HDB03 (ocf::suse:SAPHana): Master hanadb1 (Monitoring) # Slaves: [ hanadb2 ] # Resource Group: g_ip_HN1_HDB03: # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hanadb1 # rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hanadb1 # rsc_st_azure (stonith:fence_azure_arm): Started hanadb2 # Clone Set: cln_fs_check_HN1_HDB03 [rsc_fs_check_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ]El atributo
OCF_CHECK_LEVEL=20se agrega a la operación de supervisión, de modo que las operaciones de supervisión realicen una prueba de lectura y escritura en el sistema de archivos. Sin este atributo, la operación de supervisión solo comprueba que el sistema de archivos esté montado. Esto puede ser un problema porque, cuando se pierde la conectividad, el sistema de archivos puede permanecer montado, a pesar de que no se pueda acceder.El atributo
on-fail=fencetambién se agrega a la operación de supervisión. Con esta opción, si se produce un error en la operación de supervisión en un nodo, ese nodo se delimita inmediatamente.
Importante
Es posible que los tiempos de espera de la configuración anterior deban adaptarse a la configuración específica de HANA para evitar acciones de barrera innecesarias. No establezca unos valores de tiempo de espera demasiado bajos. Tenga en cuenta que la supervisión del sistema de archivos no está relacionada con la replicación del sistema HANA. Para más información, consulte la documentación de SUSE.
Prueba de la configuración del clúster
En esta sección se describe cómo se puede probar la configuración.
Antes de iniciar una prueba, asegúrese de que Pacemaker no tiene ninguna acción con error (a través del estado de crm) y que no hay restricciones de ubicación inesperadas (por ejemplo, restos de una prueba de migración). Además, asegúrese de que la replicación del sistema de HANA está en estado de sincronización, por ejemplo, con
systemReplicationStatus.sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"Compruebe el estado de los recursos de HANA mediante el comando siguiente:
SAPHanaSR-showAttr # You should see something like below # hanadb1:~ SAPHanaSR-showAttr # Global cib-time maintenance # -------------------------------------------- # global Mon Nov 8 22:50:30 2021 false # Sites srHook # ------------- # SITE1 PRIM # SITE2 SOK # Site2 SOK # Hosts clone_state lpa_hn1_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost # -------------------------------------------------------------------------------------------------------------------------------------------------------------- # hanadb1 PROMOTED 1636411810 online logreplay hanadb2 4:P:master1:master:worker:master 150 SITE1 sync PRIM 2.00.058.00.1634122452 hanadb1 # hanadb2 DEMOTED 30 online logreplay hanadb1 4:S:master1:master:worker:master 100 SITE2 sync SOK 2.00.058.00.1634122452 hanadb2Compruebe la configuración del clúster para un escenario de error, cuando un nodo se apaga. En el ejemplo siguiente se muestra el nodo 1 apagándose:
sudo crm status sudo crm resource move msl_SAPHana_HN1_HDB03 hanadb2 force sudo crm resource cleanupEjemplo:
sudo crm status #Cluster Summary: # Stack: corosync # Current DC: hanadb2 (version 2.0.5+20201202.ba59be712-4.9.1-2.0.5+20201202.ba59be712) - partition with quorum # Last updated: Mon Nov 8 23:25:36 2021 # Last change: Mon Nov 8 23:25:19 2021 by root via crm_attribute on hanadb2 # 2 nodes configured # 11 resource instances configured # Node List: # Online: [ hanadb1 hanadb2 ] # Full List of Resources: # Clone Set: cln_azure-events [rsc_azure-events]: # Started: [ hanadb1 hanadb2 ] # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ] # Clone Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] (promotable): # Masters: [ hanadb2 ] # Stopped: [ hanadb1 ] # Resource Group: g_ip_HN1_HDB03: # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hanadb2 # rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hanadb2 # rsc_st_azure (stonith:fence_azure_arm): Started hanadb2 # Clone Set: cln_fs_check_HN1_HDB03 [rsc_fs_check_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ]Detenga HANA en Node1:
sudo su - hn1adm sapcontrol -nr 03 -function StopWait 600 10Registre el Nodo 1 como nodo secundario y compruebe el estado:
hdbnsutil -sr_register --remoteHost=hanadb2 --remoteInstance=03 --replicationMode=sync --name=SITE1 --operationMode=logreplayEjemplo:
#adding site ... #nameserver hanadb1:30301 not responding. #collecting information ... #updating local ini files ... #done.sudo crm statussudo SAPHanaSR-showAttrCompruebe la configuración del clúster para un escenario de error cuando un nodo pierde el acceso al recurso compartido de NFS (/hana/shared).
Los agentes de recursos de SAP HANA dependen de los archivos binarios almacenados en /hana/shared para realizar operaciones durante la conmutación por error. El sistema de archivos /hana/shared se monta en NFS en el escenario presentado.
Es difícil simular un error, en el que uno de los servidores pierde el acceso al recurso compartido NFS. Como prueba, puede volver a montar el sistema de archivos como de solo lectura. Este enfoque valida que el clúster pueda realizar la conmutación por error si se pierde el acceso a /hana/shared en el nodo activo.
Resultado esperado: al hacer que /hana/shared sea un sistema de archivos de solo lectura, se produce un error en el atributo
OCF_CHECK_LEVELdel recursohana_shared1, que realiza operaciones de lectura y escritura en sistemas de archivos. Se produce un error porque no puede escribir nada en el sistema de archivos y se realiza una conmutación por error de recursos de HANA. Se espera el mismo resultado cuando el nodo de HANA pierde el acceso a los recursos compartidos de NFS.Estado del recurso antes de iniciar la prueba:
sudo crm status #Cluster Summary: # Stack: corosync # Current DC: hanadb2 (version 2.0.5+20201202.ba59be712-4.9.1-2.0.5+20201202.ba59be712) - partition with quorum # Last updated: Mon Nov 8 23:01:27 2021 # Last change: Mon Nov 8 23:00:46 2021 by root via crm_attribute on hanadb1 # 2 nodes configured # 11 resource instances configured #Node List: # Online: [ hanadb1 hanadb2 ] #Full List of Resources: # Clone Set: cln_azure-events [rsc_azure-events]: # Started: [ hanadb1 hanadb2 ] # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ] # Clone Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] (promotable): # Masters: [ hanadb1 ] # Slaves: [ hanadb2 ] # Resource Group: g_ip_HN1_HDB03: # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hanadb1 # rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hanadb1 # rsc_st_azure (stonith:fence_azure_arm): Started hanadb2 # Clone Set: cln_fs_check_HN1_HDB03 [rsc_fs_check_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ]Puede colocar /hana/shared en modo de solo lectura en el nodo de clúster activo mediante este comando:
sudo mount -o ro 10.3.1.4:/hanadb1-shared-mnt00001 /hana/sharedbEl servidor
hanadb1se reiniciará o apagará en función de la acción establecida. Una vez que el servidor (hanadb1) está inactivo, el recurso de HANA se mueve ahanadb2. Puede comprobar el estado del clúster desdehanadb2.sudo crm status #Cluster Summary: # Stack: corosync # Current DC: hanadb2 (version 2.0.5+20201202.ba59be712-4.9.1-2.0.5+20201202.ba59be712) - partition with quorum # Last updated: Wed Nov 10 22:00:27 2021 # Last change: Wed Nov 10 21:59:47 2021 by root via crm_attribute on hanadb2 # 2 nodes configured # 11 resource instances configured #Node List: # Online: [ hanadb1 hanadb2 ] #Full List of Resources: # Clone Set: cln_azure-events [rsc_azure-events]: # Started: [ hanadb1 hanadb2 ] # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ] # Clone Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] (promotable): # Masters: [ hanadb2 ] # Stopped: [ hanadb1 ] # Resource Group: g_ip_HN1_HDB03: # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hanadb2 # rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hanadb2 # rsc_st_azure (stonith:fence_azure_arm): Started hanadb2 # Clone Set: cln_fs_check_HN1_HDB03 [rsc_fs_check_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ]Se recomienda probar la configuración del clúster de SAP HANA exhaustivamente mediante las pruebas descritas en Replicación del sistema de SAP HANA.