Almacén de conocimiento en Azure AI Search
El almacén de conocimiento es un almacenamiento secundario para Contenido enriquecido por la inteligencia artificial creado por un conjunto de aptitudes en Azure AI Search. En Azure AI Search, un trabajo de indexación siempre envía la salida a un índice de búsqueda, pero si asocia un conjunto de aptitudes a un indexador, también puede enviar una salida enriquecida por la IA a un contenedor o una tabla de Azure Storage. Un almacén de conocimiento se puede usar para el análisis independiente o el procesamiento descendente en escenarios que no son de búsqueda, como la minería de conocimiento.
Las dos salidas de indexación, un índice de búsqueda y un almacén de conocimiento, son productos mutuamente excluyentes de la misma canalización. Se derivan de las mismas entradas y contienen los mismos datos, pero su contenido está estructurado, almacenado y se usa en diferentes aplicaciones.

Físicamente, un almacén de conocimiento es Azure Storage, ya sea Azure Table Storage, Azure Blob Storage o ambos. Cualquier herramienta o proceso que pueda conectarse a Azure Storage puede consumir el contenido de un almacén de conocimiento. No hay compatibilidad con consultas en Azure AI Search para recuperar contenido de un almacén de conocimiento.
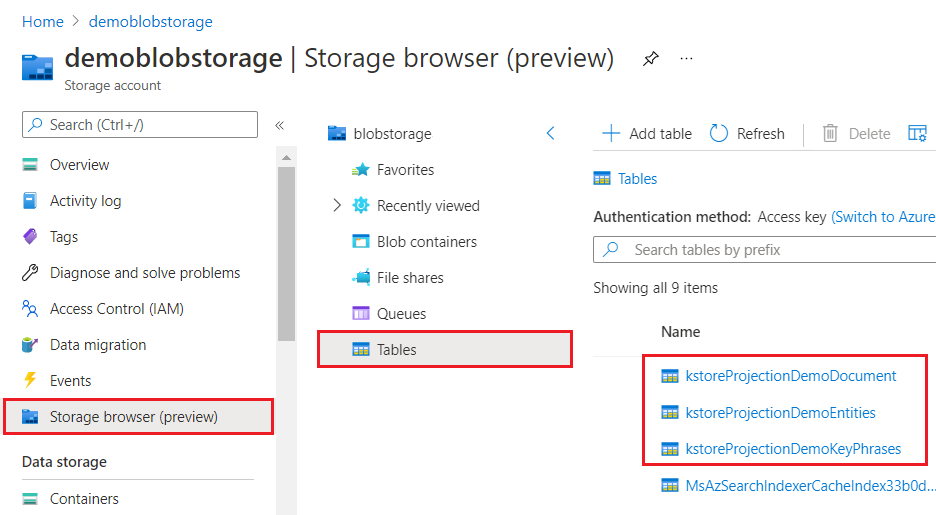
Cuando se visualiza a través de Azure Portal, un almacén de conocimiento es similar a cualquier otra colección de tablas, objetos o archivos. En la captura de pantalla siguiente se muestra un almacén de conocimiento compuesto de tres tablas. Puede adoptar una convención de nomenclatura, como un prefijo kstore, para mantener el contenido juntos.
Ventajas de Knowledge Store
Las principales ventajas de un almacén de conocimiento son dos: el acceso flexible al contenido y la capacidad de dar forma a los datos.
A diferencia de los índices de búsqueda, a los que solo se puede acceder a través de consultas de Azure AI Search, cualquier herramienta, aplicación o proceso que admita conexiones a Azure Storage puede acceder a un almacén de conocimiento. Esta flexibilidad abre nuevos escenarios para consumir el contenido analizado y enriquecido generado por una canalización de enriquecimiento.
El mismo conjunto de aptitudes que enriquece los datos también se puede usar para dar forma a los datos. Algunas herramientas como Power BI funcionan mejor con tablas, mientras que una carga de trabajo de ciencia de datos podría requerir una estructura de datos compleja en un formato de blob. La adición de una aptitud de Conformador a un conjunto de aptitudes le proporciona control sobre la forma de los datos. A continuación, puede pasar estas formas a proyecciones, ya sean tablas o blobs, para crear estructuras de datos físicos que se alineen con el uso previsto de los datos.
En el vídeo siguiente se explican estas ventajas y mucho más.
Definición del almacén de conocimiento
Un almacén de conocimiento se define dentro de una definición de conjunto de aptitudes y consta de dos componentes:
Una cadena de conexión a Azure Storage.
Proyecciones que determinan si el almacén de conocimiento consta de tablas, objetos o archivos. El elemento proyecciones es una matriz. Puede crear varios conjuntos de combinaciones de tabla-objeto-archivo dentro de un almacén de conocimiento.
"knowledgeStore": { "storageConnectionString":"<YOUR-AZURE-STORAGE-ACCOUNT-CONNECTION-STRING>", "projections":[ { "tables":[ ], "objects":[ ], "files":[ ] } ] }
El tipo de proyección que especifique en esta estructura determina el tipo de almacenamiento que usará el almacén de conocimiento, pero no su estructura. Los campos de las tablas, los objetos y los archivos los determina la salida de habilidades de Shaper si va a crear el almacén de conocimiento mediante programación, o mediante el Asistente para importar datos si usa el portal.
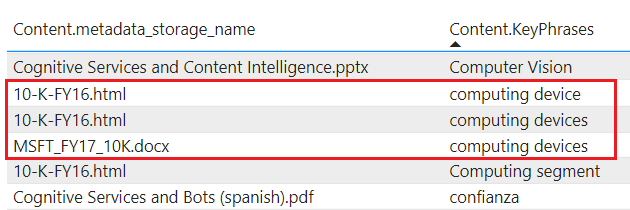
tablesproyecta el contenido enriquecido en Table Storage. Defina una proyección de tabla cuando necesite estructuras de informes tabulares para escribir entradas en herramientas analíticas o realizar exportaciones de tramas de datos en otros almacenes de datos. Puede especificar varios elementostablesen el mismo grupo de proyección para obtener un subconjunto o una sección transversal de documentos enriquecidos. Dentro del mismo grupo de proyección, las relaciones entre las tablas se conservan para que pueda trabajar con todas ellas.El contenido proyectado no se agrega ni se normaliza. En la captura de pantalla siguiente se muestra una tabla, ordenada por frase clave, con el documento primario indicado en la columna adyacente. En contraste con la ingesta de datos durante la indexación, no hay ningún análisis lingüístico ni agregación de contenido. Las formas plurales y las diferencias en las mayúsculas y minúsculas se consideran instancias únicas.
objectsproyecta el documento JSON en Blob Storage. La representación física de un elementoobjectes una estructura JSON jerárquica que representa un documento enriquecido.filesproyecta los archivos de imagen en Blob Storage. Un elementofilees una imagen extraída de un documento, que se transfiere sin cambios al almacenamiento de blobs. Aunque se denomina "archivos", se muestra en Blob Storage, no en el almacenamiento de archivos.
Crear un almacén de conocimientos
Para crear el almacén de conocimiento, use el portal o una API.
Necesita Azure Storage, un conjunto de aptitudes y un indexador. Dado que los indexadores requieren un índice de búsqueda, también tiene que proporcionar una definición de índice.
Opte por el enfoque del portal para obtener la ruta más rápida hacia un almacén de conocimiento terminado. O bien, elija la API de REST para comprender mejor cómo se definen y se relacionan los objetos.
Cree su primer almacén de conocimiento en cuatro pasos mediante el asistente para importación de datos.
Defina un origen de datos que contenga los datos que quiere enriquecer.
Defina un conjunto de aptitudes. El conjunto de aptitudes especifica los pasos de enriquecimiento y el almacén de conocimiento.
Defina un esquema de índice. Es posible que no necesite uno, pero los indexadores lo necesitan. El asistente puede inferir un índice.
Finalice el asistente. La extracción de datos, el enriquecimiento y la creación del almacén de conocimiento se producen en este último paso.
El asistente automatiza varias tareas. Específicamente, tanto el modelado como las proyecciones (definiciones de estructuras de datos físicas en Azure Storage) se crean automáticamente.
Conexión con aplicaciones
Una vez que el contenido enriquecido existe en el almacenamiento, puede usarse cualquier herramienta o tecnología que se conecte a Azure Storage para explorar, analizar o consumir el contenido. La lista siguiente es un comienzo:
Explorador de Storage o explorador de almacenamiento (versión preliminar) en Azure Portal para ver el contenido y la estructura de documentos enriquecidos. Considere esto como la herramienta de base de referencia para ver el contenido del almacén de conocimientos.
Power BI para crear informes y realizar análisis.
Azure Data Factory para manipulación adicional.
Ciclo de vida del contenido
Cada vez que se ejecutan el indexador y el conjunto de aptitudes, el almacén de conocimiento se actualiza si el conjunto de aptitudes o los datos de origen subyacentes han cambiado. Los cambios que recoge el indexador se propagan a través del proceso de enriquecimiento a las proyecciones del almacén de conocimiento, lo que garantiza que los datos proyectados son una representación actual del contenido en el origen de datos de origen.
Nota:
Aunque puede editar los datos en las proyecciones, las modificaciones se sobrescribirán en la invocación de la canalización siguiente, suponiendo que se actualice el documento en los datos de origen.
Cambios en los datos de origen
En el caso de los orígenes de datos que admiten el seguimiento de cambios, un indexador procesará documentos nuevos y modificados, y omitirá los documentos existentes que ya se han procesado. La información de marca de tiempo varía según el origen de datos, pero en un contenedor de blobs, el indexador examina la fecha lastmodified para determinar qué blobs se deben ingerir.
Cambios en un conjunto de aptitudes
Si va a realizar cambios en un conjunto de aptitudes, debe habilitar el almacenamiento en caché de documentos enriquecidos reutilizar los enriquecimientos existentes siempre que sea posible.
Sin el almacenamiento en caché incremental, el indexador siempre procesará los documentos por orden de límite máximo, sin retroceder. En el caso de los blobs, el indexador procesaría los blobs ordenados por lastModified, independientemente de los cambios en la configuración del indexador o en el conjunto de aptitudes. Si cambia un conjunto de aptitudes, los documentos procesados previamente no se actualizan para reflejar el nuevo conjunto de aptitudes. Los documentos procesados después del cambio del conjunto de aptitudes usarán el nuevo conjunto de aptitudes, lo que provocará que los documentos de índice sean una combinación de conjuntos de aptitudes antiguos y nuevos.
Con el almacenamiento en caché incremental y después de una actualización del conjunto de aptitudes, el indexador reutilizará los enriquecimientos que no se hayan visto afectados por el cambio del conjunto de aptitudes. Los enriquecimientos ascendentes se extraen de la memoria caché, al igual que los enriquecimientos independientes y aislados de la aptitud modificada.
Eliminaciones
Aunque un indexador crea y actualiza estructuras y contenido en Azure Storage, no los elimina. Las proyecciones siguen existiendo incluso cuando se elimina el indexador o el conjunto de aptitudes. Como propietario de la cuenta de almacenamiento, debe eliminar una proyección si ya no es necesaria.
Pasos siguientes
El almacén de conocimiento ofrece persistencia de documentos enriquecidos, lo cual resulta útil al diseñar un conjunto de aptitudes o durante la creación de nuevas estructuras y contenido para su consumo por parte de cualquier aplicación cliente capaz de acceder a una cuenta de Azure Storage.
El enfoque más sencillo para crear documentos enriquecidos es a través del portal, pero un cliente REST y las API de REST pueden proporcionar más información sobre cómo se crean y hacen referencia a los objetos mediante programación.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de