Conceptos de conjunto de aptitudes en Azure AI Search
Este artículo es para desarrolladores que necesitan una comprensión más profunda de los conceptos y la composición del conjunto de habilidades, y asume la familiaridad con los conceptos de alto nivel de IA aplicada en Búsqueda de Azure AI.
Un conjunto de aptitudes es un objeto reutilizable en Búsqueda de Azure AI que está asociado a un indexador. Contiene una o varias aptitudes que llaman a la inteligencia artificial integrada o al procesamiento personalizado externo sobre documentos recuperados de un origen de datos externo.
En el diagrama siguiente se muestra el flujo de datos básico de la ejecución del conjunto de aptitudes.
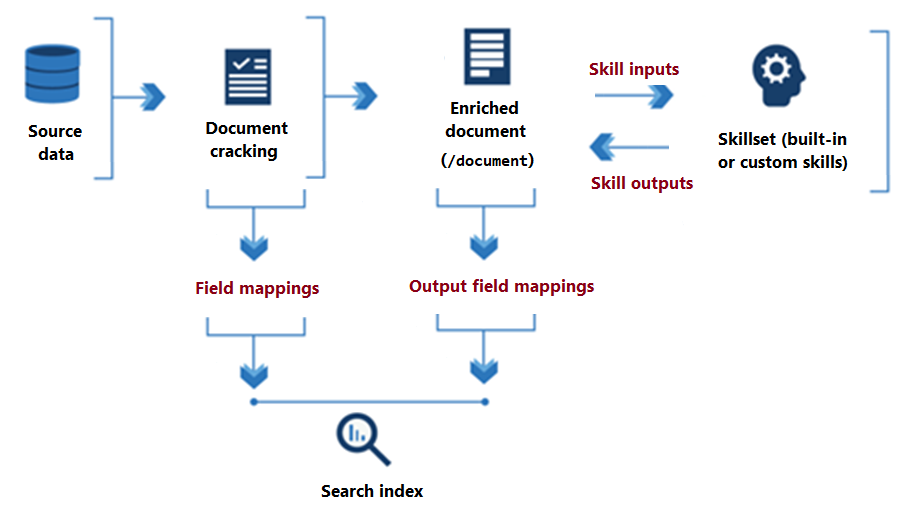
Desde el inicio del procesamiento del conjunto de habilidades hasta su conclusión, las habilidades leen y escriben en un documento enriquecido que existe en la memoria. Inicialmente, un documento enriquecido es solo el contenido sin procesar extraído de un origen de datos (articulado como el "/document" nodo raíz). Con cada ejecución de aptitudes, el documento enriquecido obtiene la estructura y la sustancia a medida que cada aptitud escribe su salida como nodos en el gráfico.
Una vez finalizada la ejecución del conjunto de competencias, la salida de un documento enriquecido encuentra su camino hacia un índice a través de asignaciones de campos de salida definidas por el usuario. Cualquier contenido sin procesar que desee transferir intacto, desde el origen a un índice, se define mediante asignaciones de campos.
Para configurar la inteligencia artificial aplicada, especifique los valores de un conjunto de aptitudes y un indexador.
Definición del conjunto aptitudes
Un conjunto de habilidades es un conjunto de una o más aptitudes que realizan un enriquecimiento, como la traducción de texto o el reconocimiento óptico de caracteres (OCR) en un archivo de imagen. Las aptitudes pueden ser las aptitudes integradas de Microsoft o aptitudes personalizadas para la lógica de procesamiento que hospede externamente. Un conjunto de aptitudes genera documentos enriquecidos que se consumen durante la indexación o se proyectan en un almacén de conocimiento.
Todas las aptitudes tienen un contexto, entradas y salidas.
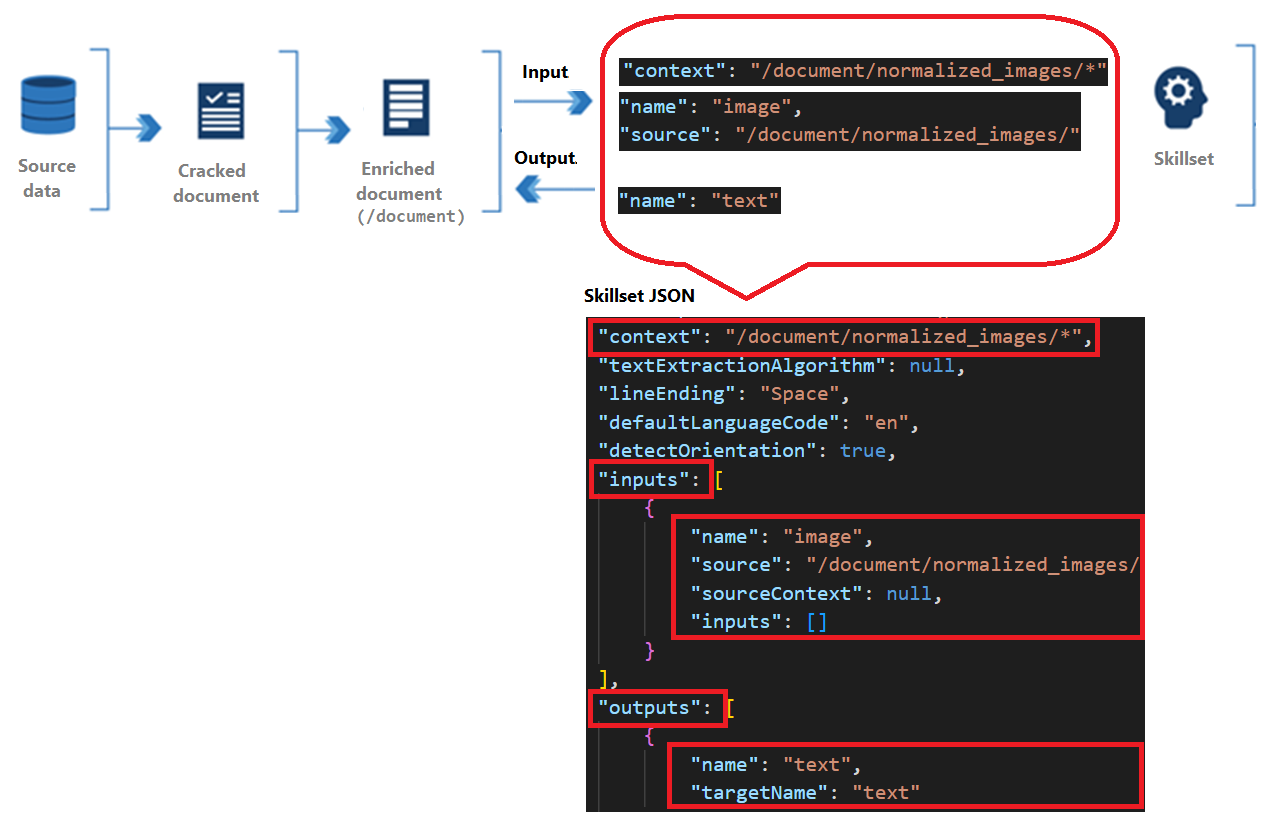
El contexto hace referencia al ámbito de la operación, que podría ser una vez por documento o una vez para cada elemento de una colección.
Las entradas se originan en nodos de un documento enriquecido, donde un "origen" y "nombre" identifican un nodo determinado.
La salida se devuelve al documento enriquecido como un nuevo nodo. Los valores son el contenido del nodo "name" y del nodo. Si se duplica un nombre de nodo, puede establecer un nombre de destino para la desambiguación.
Contexto de las aptitudes
Cada aptitud tiene un contexto, que puede ser todo el documento (/document) o un nodo inferior en el árbol (/document/countries/*).
Un contexto determina:
El número de veces que se ejecuta la aptitud, sobre un único valor (una vez por campo, por documento), o para una colección, donde si se añade un
/*se invoca la aptitud para cada instancia de la colección.La declaración de salida o dónde se agregan las salidas de la aptitud en el árbol de enriquecimiento. Las salidas siempre se agregan al árbol como elementos secundarios del nodo de contexto.
La forma de las entradas. En el caso de las colecciones de varios niveles, establecer el contexto en la colección primaria afecta a la forma de la entrada de la aptitud. Por ejemplo, si tiene un árbol de enriquecimiento con una lista de países o regiones, cada uno enriquecido con una lista de estados que contiene una lista de códigos postales, la forma en que establece el contexto determina cómo se interpreta la entrada.
Context Entrada Forma de la entrada Invocación de la aptitud /document/countries/*/document/countries/*/states/*/zipcodes/*Lista de todos los códigos postales del país o región Una vez por país o región /document/countries/*/states/*/document/countries/*/states/*/zipcodes/*Lista de todos los códigos postales del estado Una vez por combinación de país o región y estado
Dependencias de las aptitudes
Las aptitudes se pueden ejecutar de forma independiente y en paralelo, o secuencialmente si se alimenta la salida de una aptitud en otra aptitud. En el ejemplo siguiente se muestran dos aptitudes integradas que se ejecutan en secuencia:
La aptitud n.º 1 es una aptitud de división del texto que acepta el contenido del campo de origen "reviews_text" como entrada y divide el contenido en "pages" de 5.000 caracteres como salida. Dividir el texto grande en fragmentos más pequeños puede producir mejores resultados para aptitudes como la detección de opiniones.
La aptitud n.º 2 es una aptitud de detección de opinión que acepta "pages" como entrada y genera un nuevo campo denominado "sentiment" como salida que contiene los resultados del análisis de opiniones.
Observe cómo se usa la salida de la primera aptitud ("pages") en el análisis de opiniones, donde "/document/reviews_text/pages/*" es el contexto y la entrada. Para más información sobre la formulación de la ruta de acceso, consulte Cómo hacer referencia al enriquecimiento.
{
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SentimentSkill",
"name": "#2",
"description": null,
"context": "/document/reviews_text/pages/*",
"defaultLanguageCode": "en",
"inputs": [
{
"name": "text",
"source": "/document/reviews_text/pages/*",
}
],
"outputs": [
{
"name": "sentiment",
"targetName": "sentiment"
},
{
"name": "confidenceScores",
"targetName": "confidenceScores"
},
{
"name": "sentences",
"targetName": "sentences"
}
]
}
. . .
]
}
Árbol de enriquecimiento
Un documento enriquecido es una estructura de datos temporal similar a un árbol creada durante la ejecución del conjunto de aptitudes que recopila todos los cambios introducidos a través de aptitudes. Colectivamente, los enriquecimientos se representan como una jerarquía de nodos direccionables. Los nodos también incluyen los campos no enriquecidos que se pasan textualmente desde el origen de datos externo.
Existe un documento enriquecido durante la ejecución del conjunto de aptitudes, pero se puede almacenar en caché o enviarse a un almacén de conocimiento.
Inicialmente, un documento enriquecido es simplemente el contenido extraído de un origen de datos durante el descifrado de documentos, donde el texto y las imágenes se extraen del origen y están disponibles para el análisis de idioma o imagen.
El contenido inicial son los metadatos y el nodo raíz (document/content). El nodo raíz suele ser un documento completo o una imagen normalizada que se extrae de un origen de datos durante el descifrado de documentos. La forma en que se articula en un árbol de enriquecimiento varía según cada tipo de origen de datos. En la tabla siguiente se muestra el estado de un documento que entra en la canalización de enriquecimiento para varios orígenes de datos compatibles:
| Origen de datos\Modo de análisis | Valor predeterminado | JSON, líneas JSON y CSV |
|---|---|---|
| Blob Storage | /document/content /document/normalized_images/* … |
/document/{key1} /document/{key2} … |
| Azure SQL | /document/{column1} /document/{column2} … |
N/D |
| Azure Cosmos DB | /document/{key1} /document/{key2} … |
N/D |
A medida que se ejecutan las aptitudes, la salida se agrega al árbol de enriquecimiento como nodos nuevos. Si la ejecución de aptitudes se realiza en todo el documento, los nodos se agregan en el primer nivel bajo la raíz.
Los nodos se pueden usar como entradas para las aptitudes de nivel inferior. Por ejemplo, las aptitudes que crean contenido, como las cadenas traducidas, podrían convertirse en entradas para aptitudes que reconozcan entidades o extraigan frases clave.
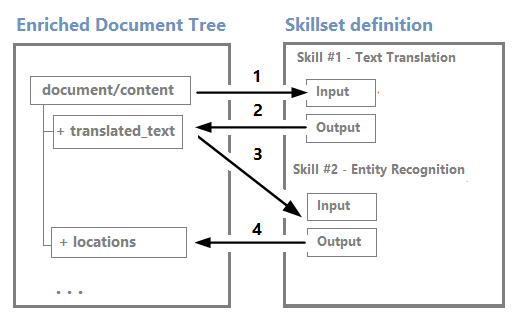
Aunque puede visualizar y trabajar con un árbol de enriquecimiento a través del editor visual de sesiones de depuración, se trata principalmente de una estructura interna.
Los enriquecimientos no son mutables: una vez creados, los nodos no se pueden editar. A medida que los conjuntos de aptitudes se vuelven más complejos, también lo hará el árbol de enriquecimiento, pero no todos los nodos del árbol de enriquecimiento deben asignarse al índice o al almacén de conocimiento.
Puede conservar de forma selectiva solo un subconjunto de las salidas de enriquecimiento para que solo mantenga lo que piensa usar. Las asignaciones de campos de salida de la definición del indexador determinan qué contenido se ingiere realmente en el índice de búsqueda. Del mismo modo, si va a crear un almacén de conocimiento, puede asignar salidas a formas asignadas a proyecciones.
Nota:
El formato de árbol de enriquecimiento permite que la canalización de enriquecimiento adjunte metadatos incluso a tipos de datos primitivos. Los metadatos no serán un objeto JSON válido, pero se pueden proyectar en un formato JSON válido en definiciones de proyección en un almacén de conocimiento. Para obtener más información, consulte Aptitud de conformador.
Definición del indexador
Un indexador tiene propiedades y parámetros usados para configurar la ejecución del indexador. Entre estas propiedades se encuentran las asignaciones que establecen la ruta de acceso de datos a los campos de un índice de búsqueda.

Hay dos conjuntos de asignaciones:
"fieldMappings" asigna un campo de origen a un campo de búsqueda.
"outputFieldMappings" asigna un nodo de un documento enriquecido a un campo de búsqueda.
La propiedad "sourceFieldName" especifica un campo del origen de datos o un nodo en un árbol de enriquecimiento. La propiedad "targetFieldName" especifica el campo de búsqueda de un índice que recibe el contenido.
Ejemplo de enriquecimiento
Con el conjunto de aptitudes de reseñas de hoteles como punto de referencia, en este ejemplo se explica cómo evoluciona un árbol de enriquecimiento a través de la ejecución de aptitudes mediante diagramas conceptuales.
Este ejemplo también muestra lo siguiente:
- Cómo funcionan el contexto y las entradas de una aptitud para determinar el número de veces que se ejecuta una aptitud.
- Qué forma tiene la entrada según el contexto.
En este ejemplo, los campos de origen de un archivo CSV incluyen reseñas de clientes sobre hoteles ("reviews_text") y clasificaciones ("reviews_rating"). El indexador agrega campos de metadatos desde Blob Storage y las aptitudes agregan texto traducido, puntuaciones de opiniones y detección de frases clave.
En el ejemplo de reseñas de hotel, un elemento "document" dentro del proceso de enriquecimiento representa una sola reseña de hotel.
Sugerencia
Puede crear un índice de búsqueda y un almacén de conocimiento para estos datos en Azure Portal o a través de las API REST. También puede usar sesiones de depuración para obtener información sobre la composición del conjunto de aptitudes, las dependencias y los efectos en un árbol de enriquecimiento. Las imágenes de este artículo se extraen de sesiones de depuración.
Conceptualmente, el árbol de enriquecimiento inicial tiene el siguiente aspecto:

El nodo raíz de todos los enriquecimientos es "/document". Al trabajar con indexadores de blobs, el nodo "/document" tiene nodos secundarios de "/document/content" y "/document/normalized_images". Cuando se trabaja con datos CSV, como en este ejemplo, los nombres de columna se asignan a los nodos situados debajo de "/document".
Aptitud 1: aptitud División
Cuando el contenido de origen se compone de grandes fragmentos de texto, resulta útil dividirlo en componentes más pequeños para una mayor precisión en la detección del idioma, la opinión y las frases clave. Hay dos intervalos disponibles: páginas y oraciones. Una página consta de aproximadamente 5.000 caracteres.
Una aptitud de división de texto suele ir primero en un conjunto de aptitudes.
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
Con el contexto de aptitud de "/document/reviews_text", la aptitud de división se ejecutará una vez para reviews_text. La salida de la aptitud es una lista donde reviews_text se fragmenta en segmentos de 5.000 caracteres. La salida de la aptitud de división se denomina pages y se agrega al árbol de enriquecimiento. La característica targetName permite cambiar el nombre de una salida de aptitud antes de agregarla al árbol de enriquecimiento.
El árbol enriquecimiento tiene ahora un nuevo nodo colocado en el contexto de la aptitud. Este nodo está disponible para cualquier aptitud, proyección o asignación de campos de salida.

Para acceder a cualquiera de los enriquecimientos agregados a un nodo mediante una aptitud, se necesita la ruta de acceso completa para el enriquecimiento. Por ejemplo, si desea usar el texto del nodo pages como entrada para otra aptitud, especifíquelo como "/document/reviews_text/pages/*". Para obtener más información sobre las rutas de acceso, consulte Enriquecimiento de referencia.
Aptitud 2: detección de idioma
Los documentos de reseñas de hoteles incluyen comentarios de los clientes realizados en varios idiomas. La aptitud de detección de idiomas determina el idioma que se usó. A continuación, el resultado se pasará a la extracción de frases clave y a la detección de opiniones (no se muestra), teniendo en cuenta el idioma durante la detección de la opinión y las frases.
Aunque la aptitud de detección de idioma es la tercera (aptitud 3) definida en el conjunto de aptitudes, es la siguiente aptitud que se ejecuta. No requiere ninguna entrada para que se ejecute en paralelo con la aptitud anterior. Al igual que la aptitud de división que la precedía, la aptitud de detección de idioma también se invoca una vez para cada documento. El árbol de enriquecimiento tiene ahora un nuevo nodo para Language.

Aptitudes 3 y 4: análisis de opiniones y detección de frases clave
Los comentarios de los clientes reflejan una gran variedad de experiencias positivas y negativas. La aptitud de análisis de opiniones analiza los comentarios y asigna una puntuación a lo largo de una continuación de números negativos a positivos, o neutral si la opinión no está determinada. En paralelo al análisis de opiniones, la detección de frases clave identifica y extrae palabras y frases cortas que aparecen como consecuencia.
Dado el contexto de /document/reviews_text/pages/*, tanto las aptitudes de análisis de opiniones como de frases clave se invocan una vez para cada uno de los elementos de la colección pages. La salida de la aptitud será un nodo bajo el elemento de página asociado.
Ahora deberá poder observar el resto de las aptitudes del conjunto y visualizar cómo sigue creciendo el árbol de enriquecimientos con la ejecución de cada una de las aptitudes. Algunas aptitudes, como la aptitud de combinación y la aptitud de conformador, también crean nuevos nodos, pero solo usan datos de los nodos existentes y no crean nuevos enriquecimientos netos.

Los colores de los conectores en el árbol anterior indican que los enriquecimientos se crearon mediante distintas aptitudes y que los nodos deben abordarse de forma individual y no formarán parte del objeto devuelto al seleccionar el nodo primario.
Aptitud 5: aptitud de conformador
Si la salida incluye un almacén de conocimiento, agregue una aptitud de conformador como último paso. La aptitud de conformador crea formas de datos de nodos en un árbol de enriquecimiento. Por ejemplo, es posible que desee consolidar varios nodos en una sola forma. Después, puede proyectar esta forma como una tabla (los nodos se convierten en las columnas de una tabla), pasando la forma por nombre a una proyección de tabla.
Trabajar con la aptitud de conformador resulta sencillo porque se centra en dar forma a una aptitud. Como alternativa, puede optar por dar forma en línea dentro de proyecciones individuales. La aptitud de conformador no agrega ni resta de un árbol de enriquecimiento, por lo que no se visualiza. En su lugar, puede pensar en una aptitud de conformador como el medio por el que vuelve a articular el árbol de enriquecimiento que ya tiene. Conceptualmente, esto es similar a la creación de vistas de tablas en una base de datos.
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "#5",
"description": null,
"context": "/document",
"inputs": [
{
"name": "name",
"source": "/document/name"
},
{
"name": "reviews_date",
"source": "/document/reviews_date"
},
{
"name": "reviews_rating",
"source": "/document/reviews_rating"
},
{
"name": "reviews_text",
"source": "/document/reviews_text"
},
{
"name": "reviews_title",
"source": "/document/reviews_title"
},
{
"name": "AzureSearch_DocumentKey",
"source": "/document/AzureSearch_DocumentKey"
},
{
"name": "pages",
"sourceContext": "/document/reviews_text/pages/*",
"inputs": [
{
"name": "Sentiment",
"source": "/document/reviews_text/pages/*/Sentiment"
},
{
"name": "LanguageCode",
"source": "/document/Language"
},
{
"name": "Page",
"source": "/document/reviews_text/pages/*"
},
{
"name": "keyphrase",
"sourceContext": "/document/reviews_text/pages/*/Keyphrases/*",
"inputs": [
{
"name": "Keyphrases",
"source": "/document/reviews_text/pages/*/Keyphrases/*"
}
]
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "tableprojection"
}
]
}
Pasos siguientes
Con una introducción y un ejemplo a sus espaldas, pruebe a crear su primer conjunto de aptitudes mediante aptitudes integradas.