Lenguaje de consulta Kusto en Microsoft Azure Sentinel
El lenguaje de consulta Kusto es el lenguaje que usará para trabajar con datos y manipularlos en Microsoft Sentinel. Los registros que se alimentan en el área de trabajo no sirven de mucho si no puede analizarlos y obtener la información importante oculta en todos esos datos. El lenguaje de consulta Kusto no solo tiene la eficacia y flexibilidad para obtener esa información, sino también la simplicidad para ayudarle a empezar a trabajar rápidamente. Si tiene experiencia en scripting o en bases de datos, gran parte del contenido de este artículo le resultará muy familiar. Si no es así, no se preocupe, ya que la naturaleza intuitiva del lenguaje le permite empezar a escribir rápidamente sus propias consultas y a impulsar el valor de su organización.
En este artículo se presentan los conceptos básicos del lenguaje de consulta Kusto, que abarcan algunas de las funciones y los operadores más usados, que deben abordar entre el 75 % y el 80 % de las consultas que escribirá día a día. Si necesita más información o ejecutar consultas más avanzadas, puede consultar el nuevo libro KQL avanzado para Microsoft Sentinel (vea esta entrada de blog introductoria). Consulte también la documentación oficial del lenguaje de consulta Kusto, así como una variedad de cursos en línea (como Pluralsight).
Contexto: ¿Por qué el lenguaje de consulta Kusto?
Microsoft Sentinel se basa en el servicio Azure Monitor y usa las áreas de trabajo de Log Analytics de Azure Monitor para almacenar todos sus datos. Estos datos incluyen cualquiera de los siguientes:
- datos ingeridos de orígenes externos en tablas predefinidas mediante conectores de datos de Microsoft Sentinel,
- datos ingeridos de orígenes externos en tablas personalizadas definidas por el usuario, mediante conectores de datos creados de forma personalizada, así como algunos tipos de conectores estándar,
- datos creados por Microsoft Sentinel, resultantes de los análisis que crea y realiza, por ejemplo, alertas, incidentes e información relacionada con UEBA,
- datos cargados en Microsoft Sentinel para ayudar con la detección y el análisis, por ejemplo, fuentes de inteligencia sobre amenazas y listas de control.
El lenguaje de consulta Kusto se desarrolló como parte del servicio Azure Data Explorer y, por tanto, está optimizado para buscar en almacenes de macrodatos en un entorno de nube. Se ha inspirado en el famoso oceanógrafo Jacques Cousteau (y se pronuncia en consecuencia "koo-STOH") y está diseñado para ayudarle a profundizar en los océanos de datos y explorar sus tesoros ocultos.
El lenguaje de consulta Kusto también se usa en Azure Monitor (y, por tanto, en Microsoft Sentinel), incluidas algunas características adicionales de Azure Monitor, que le permite recuperar, visualizar, analizar y examinar datos en almacenes de datos de Log Analytics. En Microsoft Sentinel, usa herramientas basadas en el lenguaje de consulta Kusto cada vez que visualiza y analiza datos y busca amenazas, ya sea en reglas y libros existentes, o en la creación de los suyos propios.
Dado que el lenguaje de consulta Kusto forma parte de casi todo lo que se hace en Microsoft Sentinel, una comprensión clara de cómo funciona le ayuda a sacar mucho más partido de SIEM.
¿Qué es una consulta?
Una consulta del lenguaje de consulta Kusto es una solicitud de solo lectura para procesar datos y devolver resultados; no escribe ningún dato. Las consultas se realizan en los datos organizados en una jerarquía de bases de datos, tablas y columnas, de forma similar a SQL.
Las solicitudes se declaran en lenguaje sin formato y usan un modelo de flujo de datos diseñado para que la sintaxis sea fácil de leer, escribir y automatizar. Veremos esto en detalle.
Las consultas del lenguaje de consulta Kusto se componen de instrucciones separadas por punto y coma. Hay muchos tipos de instrucciones, pero solo dos tipos ampliamente usados que trataremos aquí:
Las instrucciones de expresiones tabulares son las más habituales cuando hablamos de consultas, se trata del cuerpo real de la consulta. Lo importante que se debe saber sobre las instrucciones de expresiones tabulares es que aceptan una entrada tabular (una tabla u otra expresión tabular) y generan una salida tabular. Se requiere al menos uno de ellas. En lo que queda de este artículo se tratará principalmente este tipo de instrucción.
Las instrucciones let le permiten crear y definir variables y constantes fuera del cuerpo de la consulta, para facilitar la legibilidad y versatilidad. Son opcionales y dependen de sus necesidades concretas. Abordaremos este tipo de instrucción al final del artículo.
Entorno de demostración
Puede practicar instrucciones del lenguaje de consulta Kusto, incluidas las de este artículo, en un entorno de demostración de Log Analytics en Azure Portal. No se aplica ningún cargo por usar este entorno de práctica, pero necesita una cuenta de Azure para acceder a él.
Explore el entorno de demostración. Al igual que Log Analytics en el entorno de producción, se puede usar de varias maneras:
Elija una tabla en la que vaya a compilar una consulta. En la pestaña Tablas predeterminada (que se muestra en el rectángulo rojo de la esquina superior izquierda), seleccione una tabla de la lista de tablas agrupadas por temas (que se muestra en la parte inferior izquierda). Expanda los temas para ver las tablas individuales y puede expandir también cada tabla para ver todos sus campos (columnas). Al hacer doble clic en una tabla o en un nombre de campo, se colocará en el punto del cursor en la ventana de consulta. Escriba el resto de la consulta a continuación del nombre de la tabla, como se indica a continuación.
Busque una consulta existente para estudiarla o modificarla. Seleccione la pestaña Consultas (que se muestra en el rectángulo rojo de la parte superior izquierda) para ver una lista de las consultas disponibles de forma predeterminada. O bien, seleccione Consultas en la barra de botones de la parte superior derecha. Puede explorar las consultas que se incluyen con Microsoft Sentinel de forma predeterminada. Al hacer doble clic en una consulta, se colocará toda la consulta en la ventana de consulta en el punto del cursor.
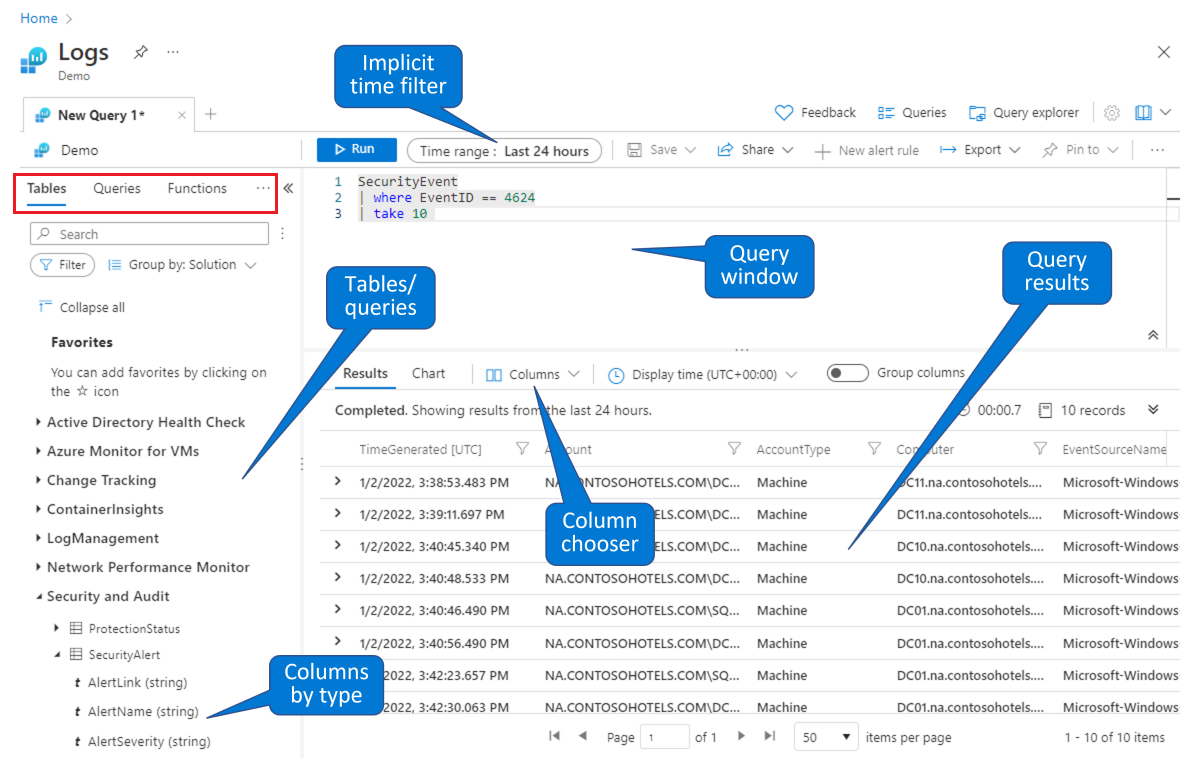
Al igual que en este entorno de demostración, puede consultar y filtrar datos en la página Registros de Microsoft Sentinel. Puede seleccionar una tabla y explorar en profundidad para ver las columnas. Puede modificar las columnas predeterminadas que se muestran mediante el Selector de columna y puede establecer el intervalo de tiempo predeterminado para las consultas. Si el intervalo de tiempo se define explícitamente en la consulta, el filtro de tiempo no estará disponible (atenuado).
Estructura de la consulta
Un buen punto de partida para aprender el lenguaje de consulta Kusto es comprender la estructura general de las consultas. Lo primero que observará en una consulta Kusto es el uso del símbolo de la barra vertical (|). La estructura de una consulta Kusto comienza por obtener los datos de un origen de datos y, a continuación, pasar los datos a través de una "canalización", y cada paso proporciona algún nivel de procesamiento y, a continuación, transfiere los datos al paso siguiente. Al final de la canalización, obtendrá el resultado final. De hecho, esta es nuestra canalización:
Get Data | Filter | Summarize | Sort | Select
Este concepto de pasar datos por la canalización hace que sea una estructura muy intuitiva, ya que resulta fácil hacerse una imagen mental de los datos en cada paso.
Para ilustrar esto, echemos un vistazo a la consulta siguiente, que examina los registros de inicio de sesión de Microsoft Entra. A medida que lee cada línea, puede ver las palabras clave que indican lo que sucede con los datos. Hemos incluido la fase pertinente en la canalización como comentario en cada línea.
Nota
Puede agregar comentarios a cualquier línea de una consulta si los precede con una barra diagonal doble (//).
SigninLogs // Get data
| evaluate bag_unpack(LocationDetails) // Ignore this line for now; we'll come back to it at the end.
| where RiskLevelDuringSignIn == 'none' // Filter
and TimeGenerated >= ago(7d) // Filter
| summarize Count = count() by city // Summarize
| sort by Count desc // Sort
| take 5 // Select
Dado que la salida de cada paso actúa como entrada para el paso siguiente, el orden de los pasos puede determinar los resultados de la consulta y afectar a su rendimiento. Es fundamental que ordene los pasos según lo que desea obtener de la consulta.
Sugerencia
- Una buena regla general es filtrar los datos al principio, de tal forma que solo se pasarán los datos pertinentes por la canalización. Esto aumentará considerablemente el rendimiento y garantizará que no incluya accidentalmente datos irrelevantes en los pasos de resumen.
- En este artículo se indicarán otros procedimientos recomendados que debe tener en cuenta. Para obtener una lista más completa, vea Procedimientos recomendados sobre las consultas.
Esperamos que ahora conozca la estructura general de una consulta en el lenguaje de consulta Kusto. Ahora echemos un vistazo a los propios operadores de consulta reales, que se usan para crear una consulta.
Tipos de datos
Antes de abordar los operadores de consulta, echemos un vistazo rápido a los tipos de datos. Como en la mayoría de los lenguajes, el tipo de datos determina qué cálculos y manipulaciones se pueden ejecutar en un valor. Por ejemplo, si tiene un valor de tipo cadena, no podrá realizar cálculos aritméticos con él.
En el lenguaje de consulta Kusto, la mayoría de los tipos de datos siguen las convenciones estándar y tienen nombres que probablemente haya visto antes. En la tabla siguiente se muestra la lista completa:
Tabla de tipos de datos
| Tipo | Nombres adicionales | Tipo equivalente de .NET |
|---|---|---|
bool |
Boolean |
System.Boolean |
datetime |
Date |
System.DateTime |
dynamic |
System.Object |
|
guid |
uuid, uniqueid |
System.Guid |
int |
System.Int32 |
|
long |
System.Int64 |
|
real |
Double |
System.Double |
string |
System.String |
|
timespan |
Time |
System.TimeSpan |
decimal |
System.Data.SqlTypes.SqlDecimal |
Aunque la mayoría de los tipos de datos son estándar, es posible que esté menos familiarizado con tipos como dynamic, timespan y guid.
Dynamic tiene una estructura muy similar a JSON, pero con una diferencia clave: puede almacenar tipos de datos específicos del lenguaje de consulta Kusto que JSON tradicional no puede, como un valor dynamic anidado o un valor timespan. Este es un ejemplo de un tipo dynamic:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
Timespan es un tipo de datos que hace referencia a una medida de tiempo, como horas, días o segundos. No confunda timespan con datetime, que se evalúa como una fecha y hora reales, no como una medida de tiempo. En la tabla siguiente se muestra una lista de sufijos para timespan.
Sufijos de Timespan
| Función | Descripción |
|---|---|
D |
days |
H |
horas |
M |
minutes |
S |
segundos |
Ms |
milisegundos |
Microsecond |
microsegundos |
Tick |
nanosegundos |
Guid es un tipo de datos que representa un identificador único global de 128 bits, que sigue el formato estándar de [8]-[4]-[4]-[4]-[12], donde cada [número] representa el número de caracteres y cada carácter puede oscilar entre 0-9 o a-f.
Nota
El lenguaje de consulta Kusto tiene operadores tabulares y escalares. En el resto de este artículo, si simplemente ve la palabra "operador", puede suponer que hace referencia a operador tabular, a menos que se indique lo contrario.
Obtención, limitación, ordenación y filtrado de datos
El vocabulario principal del lenguaje de consulta Kusto (la base que le permitirá realizar la gran mayoría de las tareas) es una colección de operadores para filtrar, ordenar y seleccionar los datos. Las tareas restantes que tendrá que realizar requerirán mejorar el conocimiento del lenguaje para satisfacer sus necesidades más avanzadas. Vamos a ampliar un poco algunos de los comandos que hemos usado en el ejemplo anterior y también vamos a ver take, sort y where.
Para cada uno de estos operadores, examinaremos su uso en el ejemplo de SigninLogs anterior y aprenderemos una sugerencia útil o un procedimiento recomendado.
Obtención de datos
La primera línea de cualquier consulta básica especifica con qué tabla desea trabajar. En el caso de Microsoft Sentinel, probablemente será el nombre de un tipo de registro del área de trabajo, como SigninLogs, SecurityAlert o CommonSecurityLog. Por ejemplo:
SigninLogs
Tenga en cuenta que en el lenguaje de consulta Kusto, los nombres de registro distinguen mayúsculas de minúsculas, por lo que SigninLogs y signinLogs se interpretarán de forma diferente. Al elegir los nombres de los registros personalizados, debe tener cuidado para que sean fáciles de identificar y no sean demasiado similares a otros registros.
Limitación de datos: take / limit
El operador take y el operador limit idéntico se usan para limitar los resultados devolviendo solo un número determinado de filas. Van seguidos de un entero que especifica el número de filas que se devolverán. Normalmente, se usan al final de una consulta después de haber determinado el criterio de ordenación y, en tal caso, devolverán el número especificado de filas en la parte superior del criterio de ordenación.
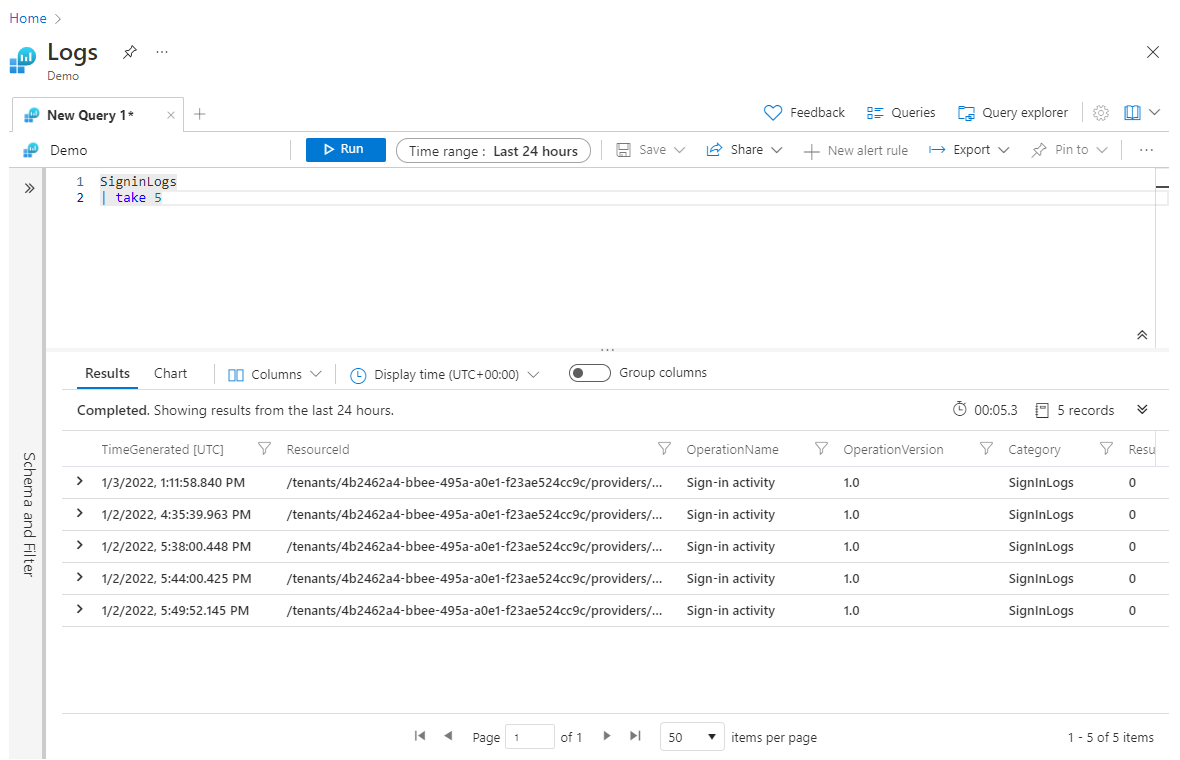
El uso de take anteriormente en la consulta puede ser útil para probar una consulta, cuando no desea devolver grandes conjuntos de datos. Sin embargo, si coloca la operación take antes que cualquier operación sort, take devolverá las filas seleccionadas de forma aleatoria y, posiblemente, un conjunto diferente de filas cada vez que se ejecute la consulta. Este es un ejemplo del uso de take:
SigninLogs
| take 5
Sugerencia
Al trabajar en una consulta completamente nueva en la que es posible que no sepa cuál será su aspecto, puede ser útil colocar una instrucción take al principio para limitar artificialmente el conjunto de datos para un procesamiento y experimentación más rápidos. Una vez que esté satisfecho con la consulta completa, puede quitar el paso take inicial.
Ordenación de datos: sort / order
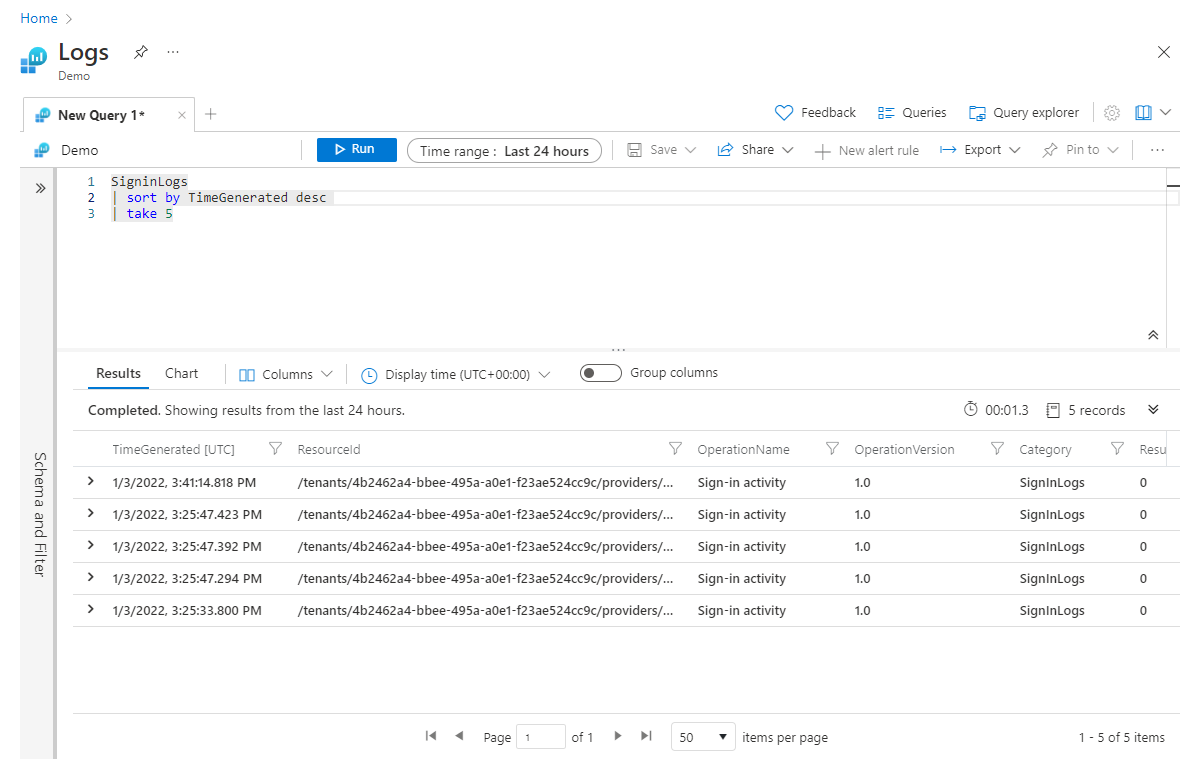
El operador sort y el operador order idéntico se usan para ordenar los datos según una columna especificada. En el ejemplo siguiente, ordenamos los resultados por TimeGenerated y establecemos la dirección del orden en descendente con el parámetro desc, colocando primero los valores más altos; para el orden ascendente, usaríamos asc.
Nota
La dirección predeterminada para las ordenaciones es descendente, por lo que técnicamente solo tiene que especificar si desea ordenar en orden ascendente. Sin embargo, especificar la dirección de ordenación en cualquier caso hará que la consulta sea más legible.
SigninLogs
| sort by TimeGenerated desc
| take 5
Como hemos mencionado, colocamos el operador sort antes que el operador take. Debemos ordenar primero para asegurarnos de que se obtengan los cinco registros adecuados.
Top (Principales)
El operador top nos permite combinar las operaciones sort y take en un único operador:
SigninLogs
| top 5 by TimeGenerated desc
En los casos en los que dos o más registros tienen el mismo valor en la columna por la que se ordena, puede agregar más columnas por las que ordenar. Agregue columnas de ordenación adicionales en una lista separada por comas, situadas después de la primera columna de ordenación, pero antes de la palabra clave de criterio de ordenación. Por ejemplo:
SigninLogs
| sort by TimeGenerated, Identity desc
| take 5
Ahora, si TimeGenerated es el mismo entre varios registros, intentará ordenar por el valor de la columna Identity.
Nota
Cuándo usar sort y take, y cuándo usar top
Si solo está ordenando en un campo, use
top, ya que proporciona mayor rendimiento que la combinación desortytake.Si necesita ordenar en más de un campo (como en el último ejemplo anterior),
topno puede hacerlo, por lo que debe usarsortytake.
Filtrado de datos: where
El operador where posiblemente sea el operador más importante, ya que es la clave para asegurarse de que solo está trabajando con el subconjunto de datos que es relevante para su escenario. Debe hacer todo lo posible para filtrar los datos lo antes posible en la consulta, ya que esto mejorará el rendimiento de las consultas al reducir la cantidad de datos que se deben procesar en pasos posteriores; también garantiza que solo se estén realizando cálculos en los datos deseados. Consulte este ejemplo:
SigninLogs
| where TimeGenerated >= ago(7d)
| sort by TimeGenerated, Identity desc
| take 5
El operador where especifica una variable, un operador de comparación (escalar) y un valor. En nuestro caso, se usa >= para indicar que el valor de la columna TimeGenerated debe ser mayor (es decir, posterior a) o igual que hace siete días.
Hay dos tipos de operadores de comparación en el lenguaje de consulta Kusto: cadena y numérico. En la tabla siguiente se muestra la lista completa de operadores numéricos:
Operadores numéricos
| Operador | Descripción |
|---|---|
+ |
Suma |
- |
Resta |
* |
Multiplicación |
/ |
División |
% |
Módulo |
< |
Menor que |
> |
Mayor que |
== |
Igual a |
!= |
No es igual a |
<= |
Menor o igual que |
>= |
Mayor o igual que |
in |
Igual a uno de los elementos |
!in |
No es igual a ninguno de los elementos |
La lista de operadores de cadena es una lista mucho más larga porque tiene permutaciones para la distinción entre mayúsculas y minúsculas, las ubicaciones de subcadenas, los prefijos, los sufijos y mucho más. El operador == es un operador numérico y de cadena, lo que significa que se puede usar para números y texto. Por ejemplo, las dos instrucciones siguientes serían instrucciones where válidas:
| where ResultType == 0| where Category == 'SignInLogs'
Sugerencia
Procedimiento recomendado: en la mayoría de los casos, probablemente quiera filtrar los datos por más de una columna o filtrar la misma columna de más de una manera. En estos casos, hay dos procedimientos recomendados que debe tener en cuenta.
Puede combinar varias instrucciones where en un solo paso mediante la palabra clave and. Por ejemplo:
SigninLogs
| where Resource == ResourceGroup
and TimeGenerated >= ago(7d)
Si tiene varios filtros unidos en una sola instrucción where mediante la palabra clave and, como se mencionó anteriormente, aumentará el rendimiento colocando primero filtros que solo hagan referencia a una sola columna. Por lo tanto, una forma más conveniente de escribir la consulta anterior sería:
SigninLogs
| where TimeGenerated >= ago(7d)
and Resource == ResourceGroup
En este ejemplo, el primer filtro menciona una sola columna (TimeGenerated), mientras que el segundo hace referencia a dos columnas (Resource y ResourceGroup).
Resumen de los datos
Summarize es uno de los operadores tabulares más importantes del lenguaje de consulta Kusto, pero también es uno de los operadores más complejos para aprender si no está familiarizado con los lenguajes de consulta en general. El trabajo de summarize es utilizar una tabla de datos y generar una tabla nueva que se agrega mediante una o varias columnas.
Estructura de la instrucción summarize
La estructura básica de una instrucción summarize es la siguiente:
| summarize <aggregation> by <column>
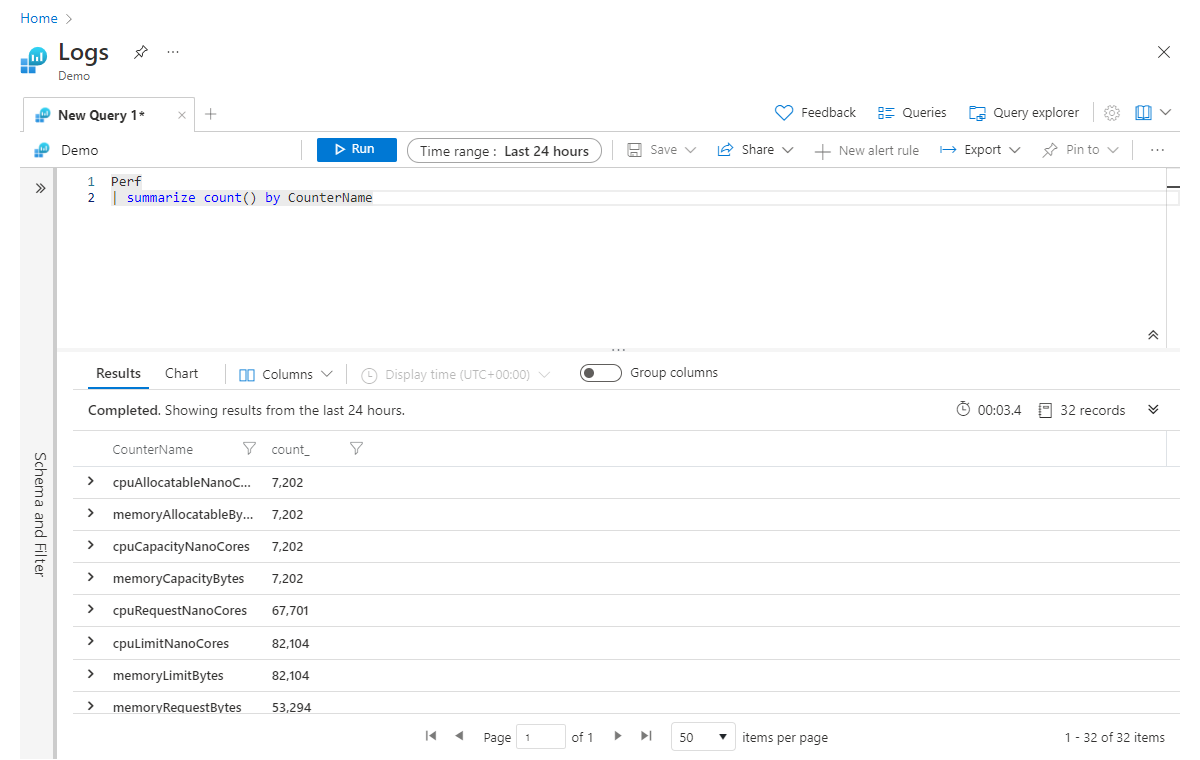
Por ejemplo, lo siguiente devolvería el recuento de registros para cada valor CounterName de la tabla Perf:
Perf
| summarize count() by CounterName
Dado que la salida de summarize es una tabla nueva, las columnas no especificadas explícitamente en la instrucción summarizeno pasarán por la canalización. Para ilustrar este concepto, considere este ejemplo:
Perf
| project ObjectName, CounterValue, CounterName
| summarize count() by CounterName
| sort by ObjectName asc
En la segunda línea, se especifica que solo nos importan las columnas ObjectName, CounterValue y CounterName. A continuación, resumimos para obtener el recuento de registros por CounterName y, por último, intentamos ordenar los datos en orden ascendente en función de la columna ObjectName. Lamentablemente, esta consulta producirá un error (que indica que objectName es desconocido) porque, cuando se resume, solo se incluyen las columnas Count y CounterName en la nueva tabla. Para evitar este error, podemos simplemente agregar ObjectName al final del paso summarize, como se muestra a continuación:
Perf
| project ObjectName, CounterValue , CounterName
| summarize count() by CounterName, ObjectName
| sort by ObjectName asc
La forma de leer la línea summarize del encabezado sería: "resumir el número de registros por CounterName y agrupar por ObjectName". Puede seguir agregando columnas, separadas por comas, al final de la instrucción summarize.
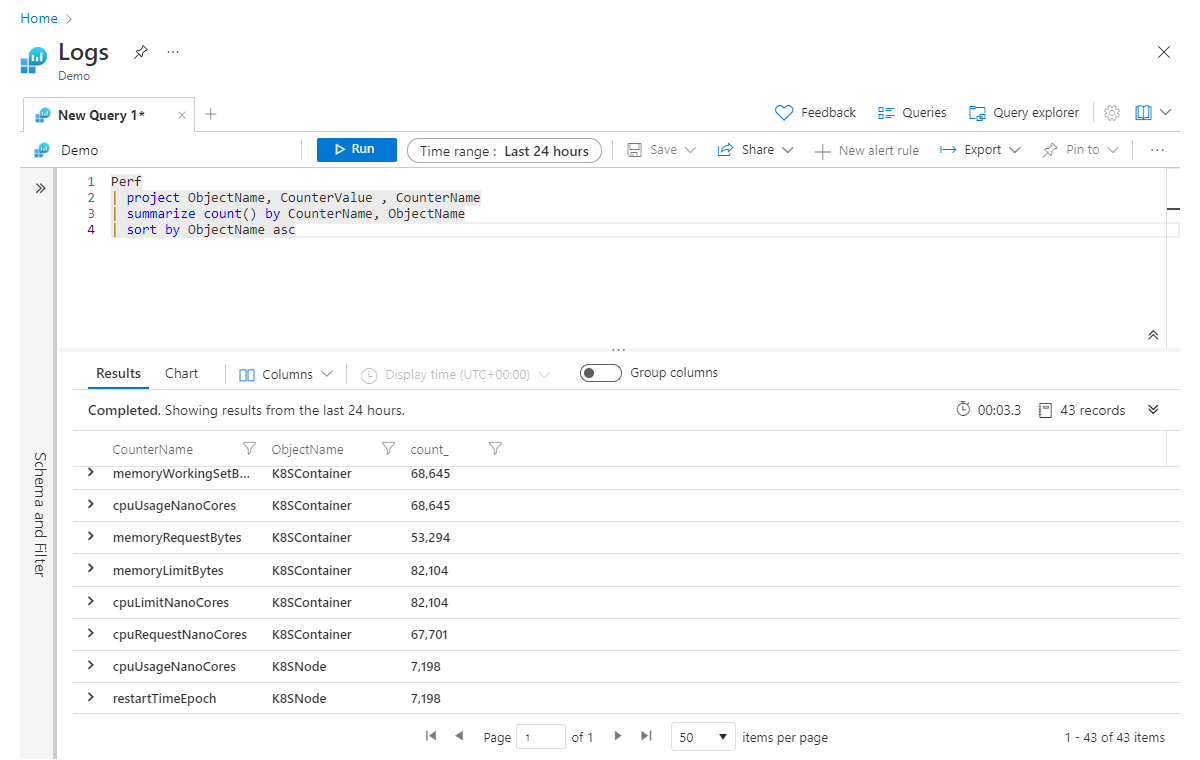
A raíz del ejemplo anterior, si queremos agregar varias columnas al mismo tiempo, podemos hacerlo realizando agregaciones al operador summarize, separadas por comas. En el ejemplo siguiente, estamos obteniendo no solo un recuento de todos los registros, sino también una suma de los valores de la columna CounterValue en todos los registros (que coinciden con cualquier filtro de la consulta):
Perf
| project ObjectName, CounterValue , CounterName
| summarize count(), sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
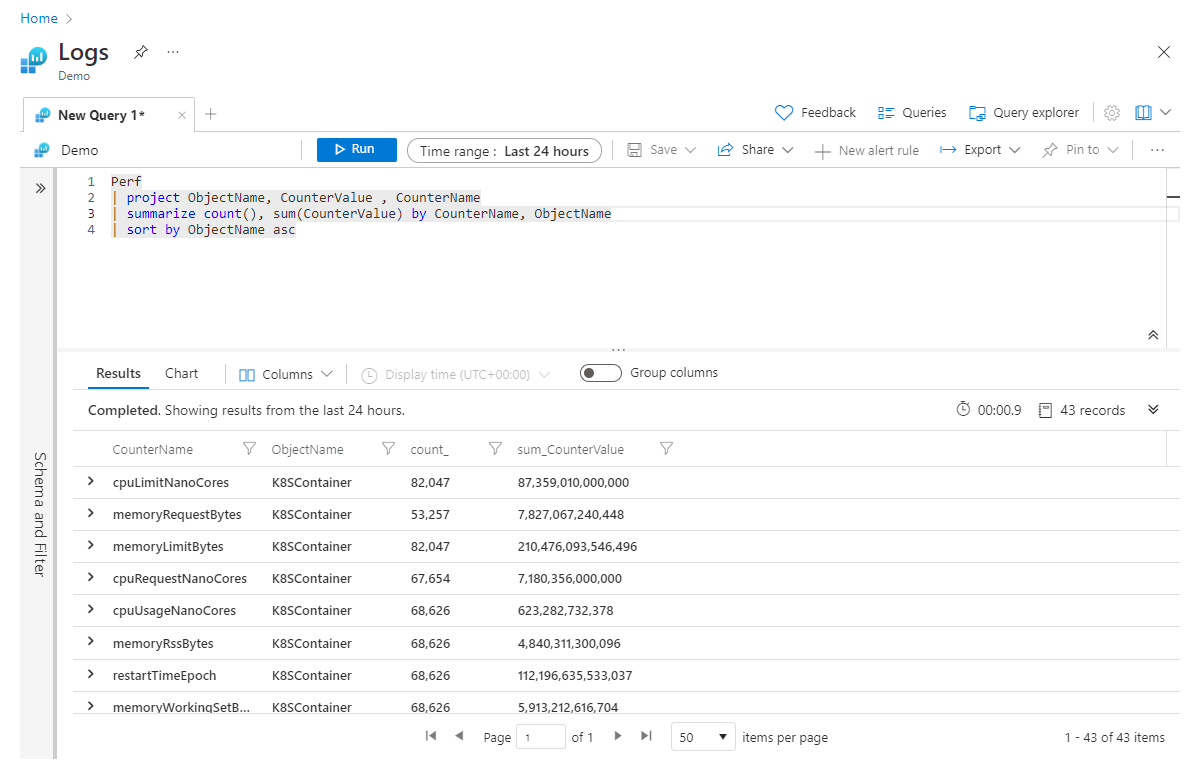
Cambio del nombre de las columnas agregadas
Parece un buen momento para hablar sobre los nombres de columna de estas columnas agregadas. Al principio de esta sección, hemos dicho que el operador summarize utiliza una tabla de datos y genera una nueva tabla, y solo las columnas que especifique en la instrucción summarize continuarán por la canalización. Por lo tanto, si ejecutara el ejemplo anterior, las columnas resultantes para nuestra agregación serían count_ y sum_CounterValue.
El motor de Kusto creará automáticamente un nombre de columna sin tener que ser explícito, pero a menudo, verá que prefiere que la nueva columna tenga un nombre más descriptivo. Puede cambiar fácilmente el nombre de la columna en la instrucción summarize especificando un nuevo nombre, seguido de = y la agregación, de la siguiente manera:
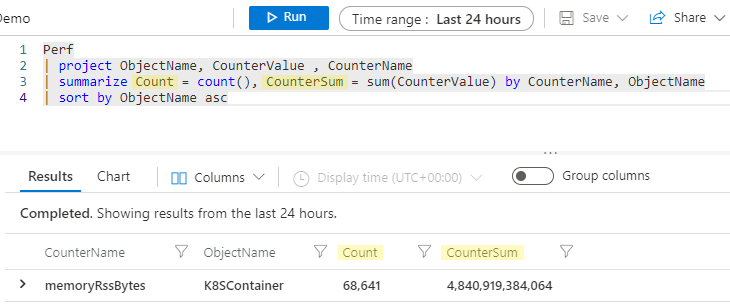
Perf
| project ObjectName, CounterValue , CounterName
| summarize Count = count(), CounterSum = sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
Ahora, nuestras columnas resumidas se denominarán Count y CounterSum.
Hay mucho más para el operador summarize de lo que podemos tratar aquí, pero debe invertir tiempo en aprenderlo porque es un componente clave para cualquier análisis de datos que planee realizar en los datos de Microsoft Sentinel.
Referencia de agregación
Hay muchas funciones de agregación, pero las que más suelen utilizarse con sum(), count() y avg(). Esta es una lista parcial (vea la lista completa):
Funciones de agregación
| Función | Descripción |
|---|---|
arg_max() |
Devuelve una o varias expresiones cuando el argumento está maximizado. |
arg_min() |
Devuelve una o varias expresiones cuando el argumento está minimizado. |
avg() |
Devuelve el valor promedio de todo el grupo. |
buildschema() |
Devuelve el esquema mínimo que admite todos los valores de la entrada dinámica. |
count() |
Devuelve el recuento del grupo. |
countif() |
Devuelve el recuento con el predicado del grupo. |
dcount() |
Devuelve el recuento único aproximado de los elementos del grupo. |
make_bag() |
Devuelve un contenedor de propiedades de los valores dinámicos dentro del grupo. |
make_list() |
Devuelve una lista de todos los valores del grupo. |
make_set() |
Devuelve un conjunto de valores únicos dentro del grupo. |
max() |
Devuelve el valor máximo de todo el grupo |
min() |
Devuelve el valor mínimo de todo el grupo |
percentiles() |
Devuelve la aproximación percentil del grupo. |
stdev() |
Devuelve la desviación estándar del grupo. |
sum() |
Devuelve la suma de los elementos dentro del grupo. |
take_any() |
Devuelve el valor aleatorio no vacío para el grupo. |
variance() |
Devuelve la varianza del grupo. |
Selección: agregar y quitar columnas
A medida que empiece a trabajar más con las consultas, es posible que tenga más información de la que necesita sobre sus temas (es decir, demasiadas columnas en la tabla). O bien, puede que necesite más información de la que tiene (es decir, que necesite agregar una nueva columna que contenga los resultados del análisis de otras columnas). Echemos un vistazo a algunos de los operadores clave para la manipulación de columnas.
Project y project-away
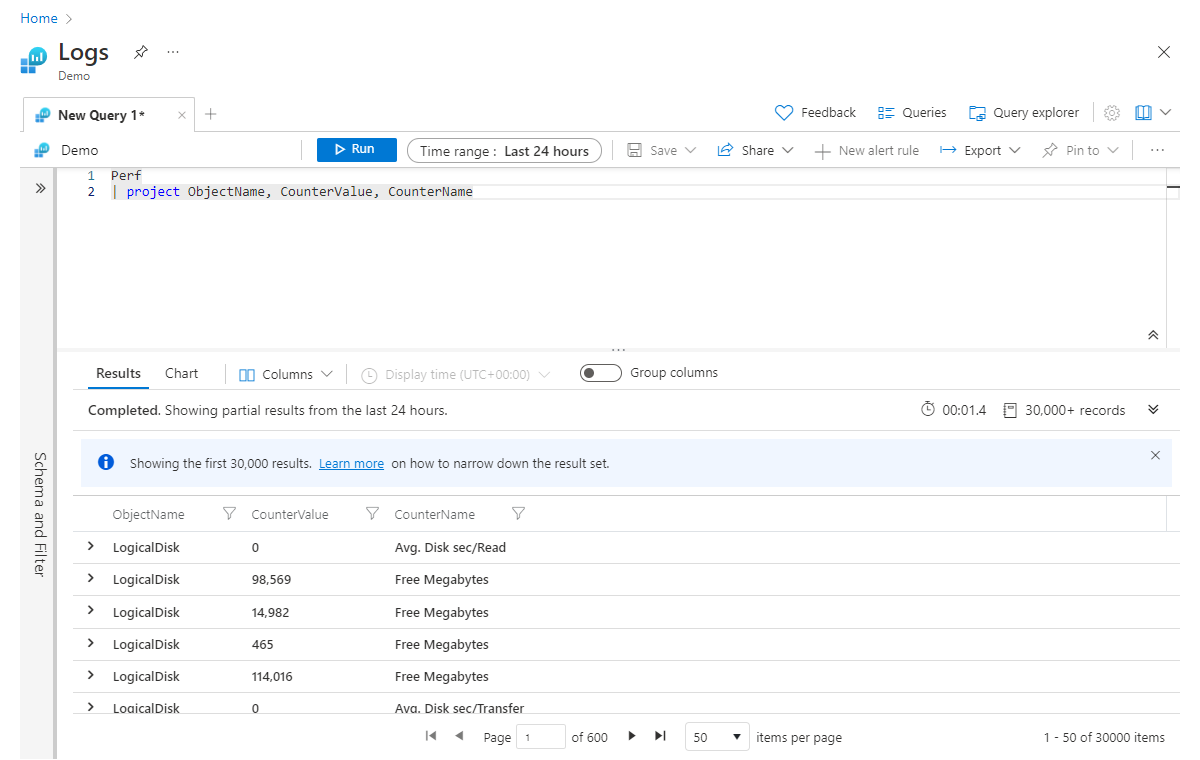
Project es muy similar a las instrucciones select de muchos lenguajes. Permite elegir las columnas que se desean mantener. El orden de las columnas devueltas coincidirá con el orden de las columnas que se muestran en la instrucción project, como se muestra en este ejemplo:
Perf
| project ObjectName, CounterValue, CounterName
Como puede imaginar, cuando se trabaja con conjuntos de datos muy grandes, es posible que tenga muchas columnas que desea conservar, y especificarlas todas por nombre requeriría mucho escribir. Para estos casos, está project-away, que le permite especificar qué columnas quitar, en lugar de cuáles conservar, de la siguiente manera:
Perf
| project-away MG, _ResourceId, Type
Sugerencia
Puede ser útil usar project en dos ubicaciones de las consultas, al principio y de nuevo al final. Usar project al principio de la consulta puede ayudar a mejorar el rendimiento quitando grandes fragmentos de datos que no es necesario pasar por la canalización. Si vuelve a usarlo al final, podrá deshacerse de las columnas que se hayan creado en pasos anteriores y que no sean necesarias en la salida final.
Extender
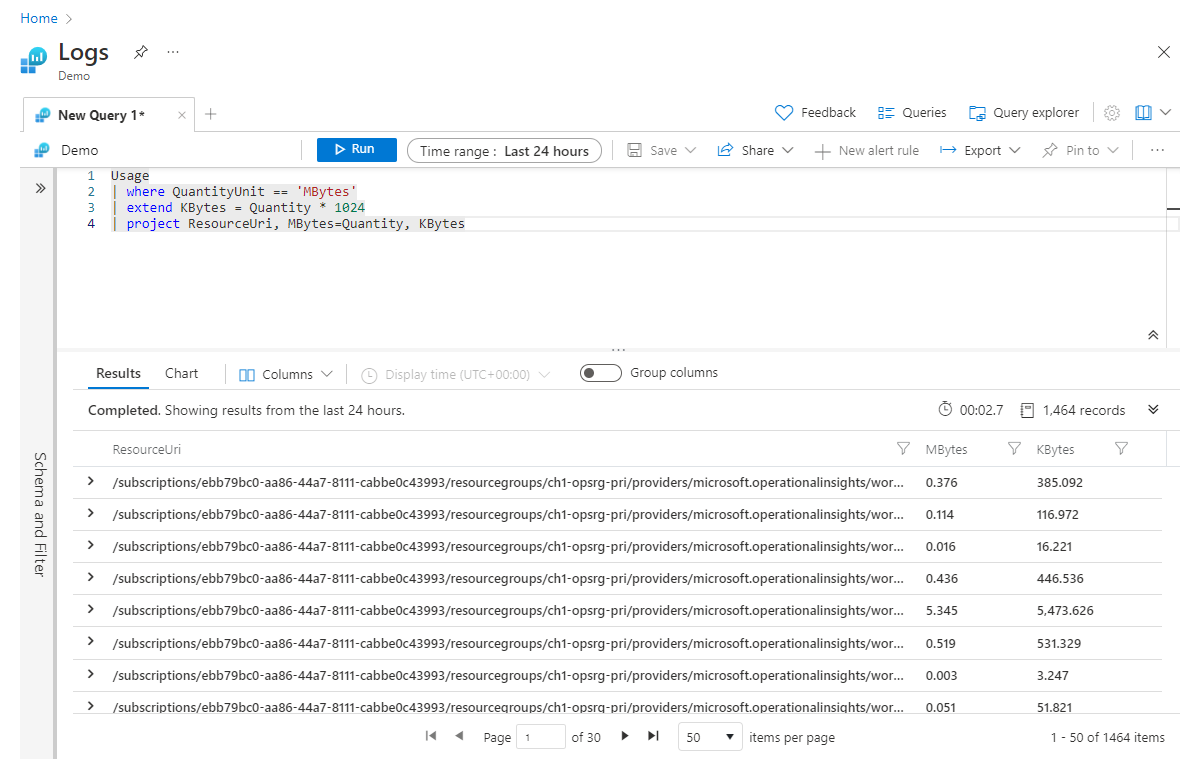
Extend se usa para crear una nueva columna calculada. Esto puede ser útil cuando desea realizar un cálculo en columnas existentes y ver la salida de cada fila. Echemos un vistazo a un ejemplo sencillo en el que calculamos una nueva columna denominada Kbytes, que podemos calcular multiplicando el valor de MB (en la columna Quantity existente) por 1024.
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| project ResourceUri, MBytes=Quantity, KBytes
En la línea final de nuestra instrucción project, cambiamos el nombre de la columna Quantity por Mbytes, y de esta forma podemos saber fácilmente qué unidad de medida es relevante para cada columna.
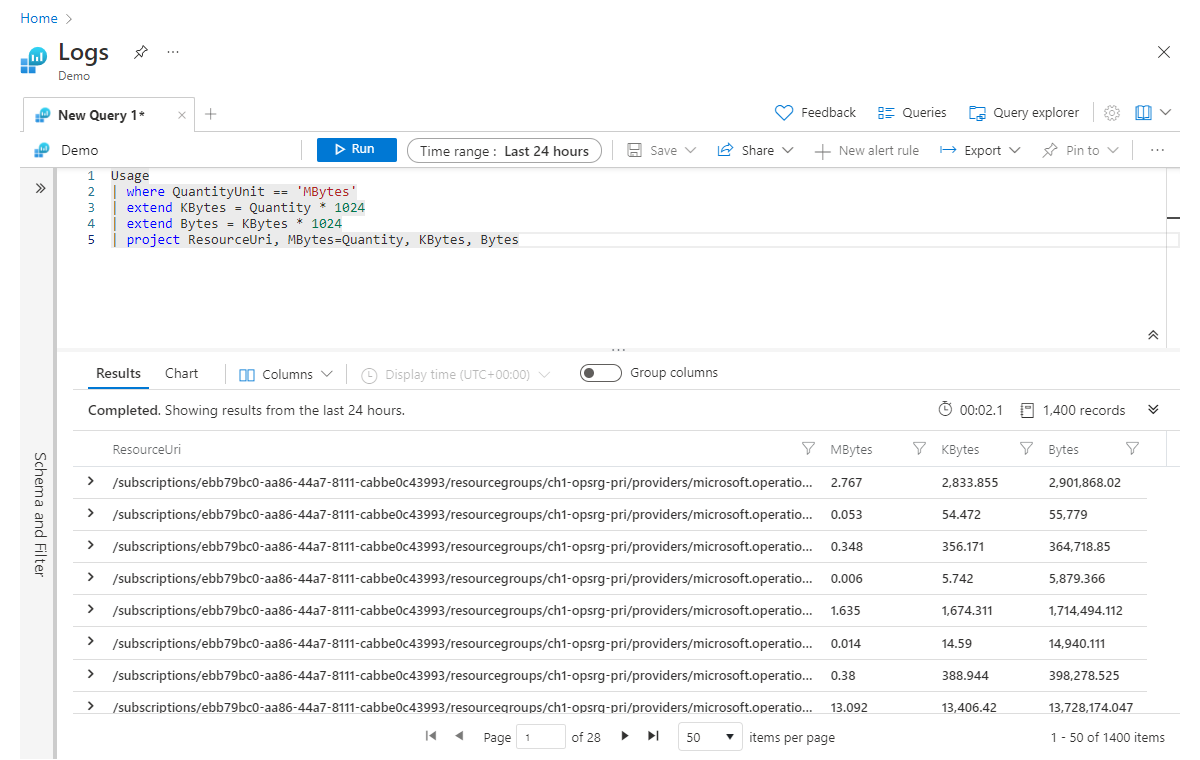
Merece la pena tener en cuenta que extend también funciona con columnas ya calculadas. Por ejemplo, podemos agregar una columna más denominada Bytes que se calcula a partir de Kbytes:
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| extend Bytes = KBytes * 1024
| project ResourceUri, MBytes=Quantity, KBytes, Bytes
Combinación de tablas
Gran parte de su trabajo en Microsoft Sentinel se puede realizar mediante un único tipo de registro, pero hay ocasiones en las que querrá correlacionar los datos o realizar una búsqueda en otro conjunto de datos. Al igual que la mayoría de los lenguajes de consulta, el lenguaje de consulta Kusto ofrece algunos operadores que se usan para realizar varios tipos de combinaciones. En esta sección, se verán los operadores más usados, union y join.
Unión
Union simplemente usa dos o más tablas y devuelve todas las filas. Por ejemplo:
OfficeActivity
| union SecurityEvent
Esto devolvería todas las filas de las tablas OfficeActivity y SecurityEvent. Union ofrece algunos parámetros que se pueden usar para ajustar el comportamiento de la unión. Dos de los más útiles son withsource y kind:
OfficeActivity
| union withsource = SourceTable kind = inner SecurityEvent
El parámetro withsource permite especificar el nombre de una nueva columna cuyo valor en una fila determinada será el nombre de la tabla de la que procede la fila. En el ejemplo anterior, asignamos el nombre SourceTable a la columna y, en función de la fila, el valor será OfficeActivity o SecurityEvent.
El otro parámetro que especificamos era kind, que tiene dos opciones: : inner u outer. En el ejemplo anterior, especificamos inner, lo que significa que las únicas columnas que se conservarán durante la unión son las que existen en ambas tablas. Como alternativa, si se hubiera especificado outer (que es el valor predeterminado), se devolverían todas las columnas de ambas tablas.
Join
Join funciona de forma similar a union, salvo que, en lugar de unir tablas para crear una tabla, estamos uniendo filas para crear una tabla. Al igual que la mayoría de los lenguajes de base de datos, hay varios tipos de combinaciones que puede realizar. La sintaxis general para join es:
T1
| join kind = <join type>
(
T2
) on $left.<T1Column> == $right.<T2Column>
Después del operador join, especificamos el tipo de combinación que queremos realizar seguido de un paréntesis abierto. Dentro de los paréntesis es donde se especifica la tabla que desea combinar, así como cualquier otra instrucción de consulta en esa tabla que desea agregar. Después del paréntesis de cierre, usamos la palabra clave on seguida de las columnas de la izquierda (palabra clave $left.<columnName>) y la derecha ($right.<columnName>) separadas por el operador ==. A continuación se muestra un ejemplo de inner join:
OfficeActivity
| where TimeGenerated >= ago(1d)
and LogonUserSid != ''
| join kind = inner (
SecurityEvent
| where TimeGenerated >= ago(1d)
and SubjectUserSid != ''
) on $left.LogonUserSid == $right.SubjectUserSid
Nota
Si ambas tablas tienen el mismo nombre para las columnas en las que va a realizar una combinación, no es necesario usar $left y $right; en su lugar, solo puede especificar el nombre de la columna. Usar $left y $right, sin embargo, es más explícito y generalmente se considera una buena práctica.
Como referencia, en la tabla siguiente se muestra una lista de tipos de combinaciones disponibles.
Tipos de combinaciones
| Tipo de unión | Descripción |
|---|---|
inner |
Devuelve un único resultado para cada combinación de filas coincidentes de ambas tablas. |
innerunique |
Devuelve filas de la tabla izquierda con valores distintos en el campo vinculado que tienen una coincidencia en la tabla derecha. Este es el tipo de combinación no especificado predeterminado. |
leftsemi |
Devuelve todos los registros de la tabla izquierda que tienen una coincidencia en la tabla derecha. Solo se devolverán las columnas de la tabla izquierda. |
rightsemi |
Devuelve todos los registros de la tabla derecha que tienen una coincidencia en la tabla izquierda. Solo se devolverán las columnas de la tabla derecha. |
leftanti/leftantisemi |
Devuelve todos los registros de la tabla izquierda que no tienen ninguna coincidencia en la tabla derecha. Solo se devolverán las columnas de la tabla izquierda. |
rightanti/rightantisemi |
Devuelve todos los registros de la tabla derecha que no tienen ninguna coincidencia en la tabla izquierda. Solo se devolverán las columnas de la tabla derecha. |
leftouter |
Devuelve todos los registros de la tabla izquierda. Para los registros que no tienen ninguna coincidencia en la tabla derecha, los valores de celda serán NULL. |
rightouter |
Devuelve todos los registros de la tabla derecha. Para los registros que no tienen ninguna coincidencia en la tabla izquierda, los valores de celda serán NULL. |
fullouter |
Devuelve todos los registros de las tablas izquierda y derecha, independientemente de que tengan coincidencias o no. Los valores no coincidentes serán NULL. |
Sugerencia
Es un procedimiento recomendado tener la tabla más pequeña a la izquierda. En algunos casos, seguir esta regla puede proporcionar enormes ventajas de rendimiento, en función de los tipos de combinaciones que se realicen y del tamaño de las tablas.
Evaluate
Es posible que recuerde que, en el primer ejemplo, vimos el operador evaluate en una de las líneas. El operador evaluate se usa con menos frecuencia que los que hemos abordado anteriormente. Sin embargo, merece la pena saber cómo funciona el operador evaluate. Una vez más, esta es la primera consulta, donde verá evaluate en la segunda línea.
SigninLogs
| evaluate bag_unpack(LocationDetails)
| where RiskLevelDuringSignIn == 'none'
and TimeGenerated >= ago(7d)
| summarize Count = count() by city
| sort by Count desc
| take 5
Este operador permite invocar complementos disponibles (básicamente funciones integradas). Muchos de estos complementos se centran en la ciencia de datos, como autocluster, diffpatterns y sequence_detect, lo que permite realizar análisis avanzados y detectar anomalías estadísticas y valores atípicos.
El complemento usado en el ejemplo anterior se denominaba bag_unpack y facilita significativamente el uso de un fragmento de datos dinámicos y su conversión en columnas. Recuerde que los datos dinámicos son un tipo de datos muy similar a JSON, como se muestra en este ejemplo:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
En este caso, queríamos resumir los datos por ciudad, pero city se incluye como una propiedad dentro de la columna LocationDetails. Para usar la propiedad city en nuestra consulta, primero había que convertirla en una columna mediante bag_unpack.
Al volver a nuestros pasos de canalización originales, vimos lo siguiente:
Get Data | Filter | Summarize | Sort | Select
Ahora que hemos considerado el operador evaluate, podemos ver que representa una nueva fase en la canalización, que ahora tiene este aspecto:
Get Data | Parse | Filter | Summarize | Sort | Select
Hay muchos otros ejemplos de operadores y funciones que se pueden usar para analizar orígenes de datos en un formato más legible y manipulable. Puede obtener información sobre ellos y el resto del lenguaje de consulta Kusto en la documentación completa y en el libro.
Instrucciones let
Ahora que hemos abordado muchos de los principales operadores y tipos de datos, vamos a terminar con la instrucción let, que es una excelente manera de facilitar la lectura, la edición y el mantenimiento de las consultas.
Let permite crear y establecer una variable o asignar un nombre a una expresión. Esta expresión podría ser un valor único, pero también podría ser una consulta completa. A continuación, se muestra un ejemplo sencillo:
let aWeekAgo = ago(7d);
SigninLogs
| where TimeGenerated >= aWeekAgo
Aquí, especificamos un nombre de aWeekAgo y lo establecemos para que sea igual a la salida de una función timespan, que devuelve un valor datetime. A continuación, finalizamos la instrucción let con un punto y coma. Ahora tenemos una nueva variable denominada aWeekAgo que se puede usar en cualquier lugar de la consulta.
Como se acaba de mencionar, puede usar una instrucción let para usar una consulta completa y dar un nombre al resultado. Puesto que los resultados de la consulta, que son expresiones tabulares, se pueden usar como entradas de consultas, puede tratar este resultado con nombre como una tabla con el fin de ejecutar otra consulta en él. Esta es una pequeña modificación del ejemplo anterior:
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
En este caso, creamos una segunda instrucción let, donde encapsulamos toda la consulta en una nueva variable denominada getSignins. Al igual que antes, finalizamos la segunda instrucción let con un punto y coma. A continuación, llamamos a la variable en la línea final, que ejecutará la consulta. Observe que pudimos usar aWeekAgo en la segunda instrucción let. Esto se debe a que se especificó en la línea anterior; si intercambiamos las instrucciones let para que getSignins apareciera en primer lugar, recibiríamos un error.
Ahora podemos usar getSignins como base de otra consulta (en la misma ventana):
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
| where level >= 3
| project IPAddress, UserDisplayName, Level
Las instrucciones let proporcionan más eficacia y flexibilidad para ayudar a organizar las consultas. Let puede definir valores escalares y tabulares, así como crear funciones definidas por el usuario. Realmente son útiles cuando se organizan consultas más complejas que pueden estar realizando varias combinaciones.
Pasos siguientes
Aunque en este artículo se ha abordado el tema muy por encima, ahora tiene los fundamentos necesarios, y hemos abordado las partes que va a usar con más frecuencia para realizar su trabajo en Microsoft Sentinel.
Libro KQL avanzado para Microsoft Sentinel
Aproveche las ventajas de un libro sobre el lenguaje de consulta Kusto directamente en Microsoft Sentinel: el libro KQL avanzado para Microsoft Sentinel. Proporciona ayuda paso a paso y ejemplos para muchas de las situaciones que es probable que encuentre durante las operaciones de seguridad diarias y también le remite a una gran cantidad de ejemplos listos para usar de reglas de análisis, libros, reglas de búsqueda y más elementos que usan consultas Kusto. Inicie este libro desde la hoja Libros de Microsoft Sentinel.
Libro sobre el marco KQL avanzado: cómo convertirse en un experto en KQL es una excelente entrada de blog en la que se explica cómo usar este libro.
Más recursos
Consulte esta colección de recursos de capacitación, aprendizaje y aptitudes para ampliar y profundizar sus conocimientos sobre el lenguaje de consulta Kusto.