Introducción a la supervisión del mantenimiento de Service Fabric
Azure Service Fabric presenta un modelo de mantenimiento que proporciona informes y datos de evaluación del mantenimiento completos, flexibles y extensibles. El modelo permite la supervisión casi en tiempo real del estado tanto del clúster como de los servicios que se ejecutan en él. Puede obtener con facilidad información sobre el mantenimiento, y corregir posibles problemas antes de que se propaguen y causen interrupciones masivas. En el modelo típico, los servicios envían informes basados en sus vistas locales, y dicha información se agrega para proporcionar una vista general del nivel del clúster.
Los componentes de Service Fabric usan este modelo de mantenimiento avanzado para informar de su estado actual. Este mismo mecanismo puede usar para informar del mantenimiento de las aplicaciones. Si invierte en informes sobre el mantenimiento de alta calidad, que capturan sus condiciones personalizadas, puede detectar y corregir problemas de la aplicación en ejecución mucho más fácilmente.
Nota:
El subsistema de mantenimiento se inició para cubrir la necesidad de actualizaciones supervisadas. Service Fabric proporciona actualizaciones supervisadas de clúster y de aplicación, que garantizan una disponibilidad completa, sin tiempo de inactividad y con una intervención del usuario mínima o nula. Para lograr estos objetivos, la actualización comprueba el estado en función de las directivas de actualización configuradas. Una actualización puede continuar solo cuando el estado respeta los umbrales deseados. De lo contrario, la actualización se revierte automáticamente o se pausa para ofrecer a los administradores una oportunidad de solucionar los problemas. Para más información sobre la actualización de aplicaciones, consulte este artículo.
Almacén de estado
El Almacén de estado conserva la información relacionada con el mantenimiento de las entidades del clúster, con el fin de facilitar su recuperación y evaluación. Se implementa como un servicio con estado persistente de Service Fabric para garantizar alta disponibilidad y escalabilidad. El Almacén de estado forma parte de la aplicación fabric:/System y está disponible cuando el clúster entra en funcionamiento.
Jerarquía y entidades de mantenimiento
Las entidades de mantenimiento se organizan en una jerarquía lógica que captura las interacciones y dependencias entre entidades diferentes. El almacén de estado crea automáticamente tanto las entidades como la jerarquía en función de los informes que recibe de los componentes de Service Fabric.
Las entidades de mantenimiento son un reflejo las entidades de Service Fabric (por ejemplo, la entidad de la aplicación de mantenimiento coincide con una instancia de aplicación implementada en el clúster, mientras que la entidad del nodo de mantenimiento coincide con un nodo de clúster de Service Fabric). La jerarquía de mantenimiento captura las interacciones de las entidades del sistema y es la base para la evaluación avanzada del mantenimiento. Para obtener información sobre los conceptos clave de Service Fabric, consulte Información general sobre la terminología de Service Fabric. Para obtener más información sobre la aplicación, consulte Modelar una aplicación en Service Fabric.
Las entidades de mantenimiento y la jerarquía permiten depurar, supervisar y realizar informes tanto del clúster como de las aplicaciones. El modelo de mantenimiento proporciona una representación pormenorizada y precisa del mantenimiento de las numerosas piezas móviles del clúster.
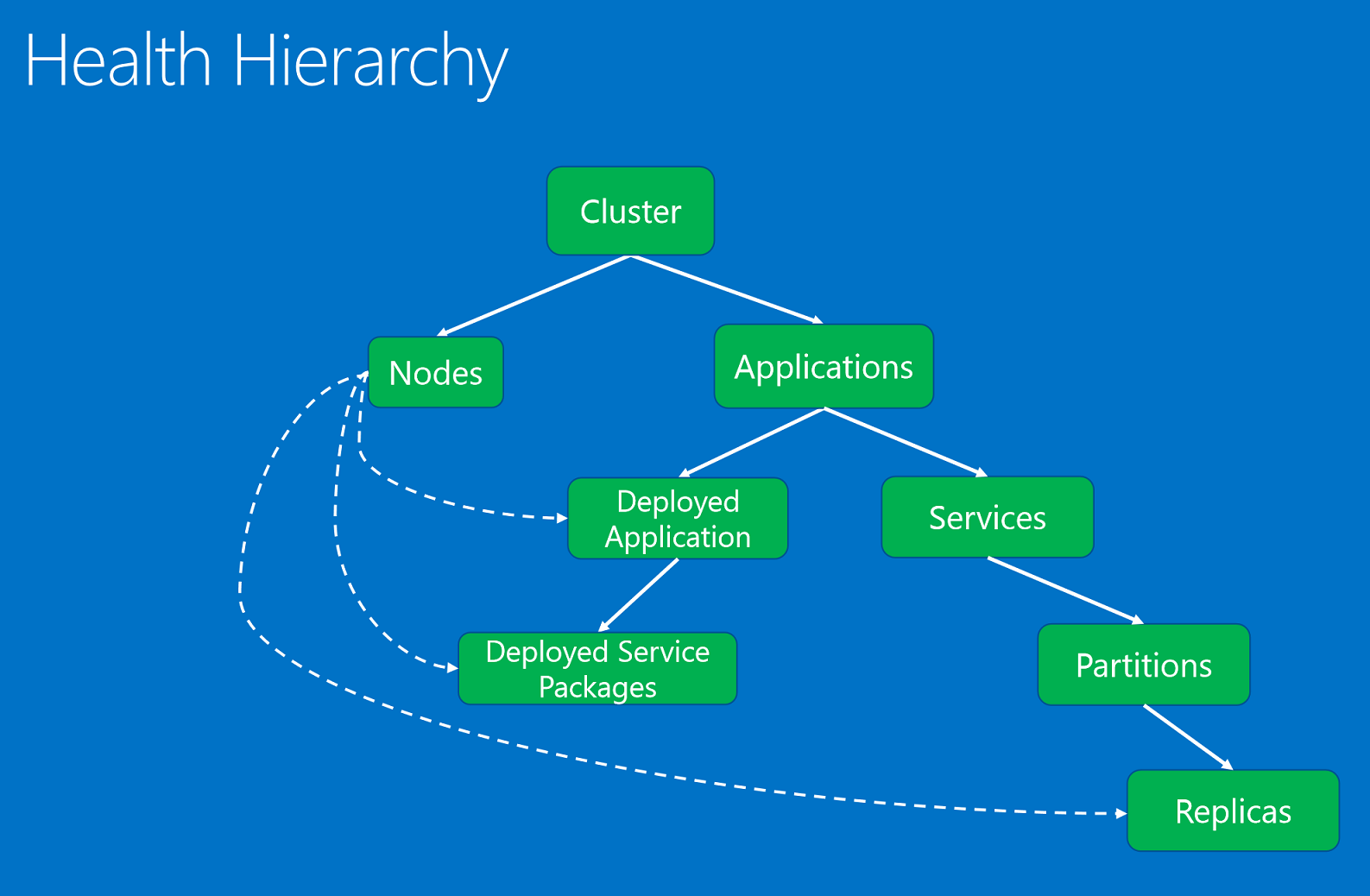 Las entidades de mantenimiento, organizadas en una jerarquía basada en relaciones entre elementos primarios y secundarios.
Las entidades de mantenimiento, organizadas en una jerarquía basada en relaciones entre elementos primarios y secundarios.
Las entidades de mantenimiento son:
- Clúster. Representa el estado de un clúster de Service Fabric. Los informes de mantenimiento del clúster describen las condiciones que afectan al clúster completo. Estas condiciones afectan a varias entidades en el clúster o al propio clúster. En función de la condición, el indicador no puede restringir el problema a uno o varios elementos secundarios con un estado incorrecto. Entre los ejemplos se incluye el cerebro de la división del clúster debida problema de creación de particiones de red o de comunicación.
- Node. Representa el estado de un nodo de Service Fabric. Los informes de mantenimiento del nodo describen las condiciones que afectan a la funcionalidad del nodo. Normalmente afectan a todas las entidades implementadas que se ejecutan en él. Entre los ejemplos se incluyen que un nodo se quede sin espacio en disco (u otra propiedad de la máquina como la memoria o las conexiones) y cuando un nodo está inactivo. La entidad del nodo se identifica por el nombre del nodo (cadena).
- Aplicación. Representa el estado de una instancia de aplicación que se ejecuta en el clúster. Los informes de mantenimiento de aplicación describen las condiciones que afectan el mantenimiento general de la aplicación. No se pueden restringir a elementos secundarios individuales (servicios o aplicaciones implementadas). Entre los ejemplos se incluye la interacción de un extremo a otro entre los diferentes servicios de la aplicación. La entidad de la aplicación se identifica mediante el nombre de la aplicación (identificador URI).
- Servicio. Representa el estado de un servicio que se ejecuta en el clúster. Los informes de mantenimiento del servicio describen las condiciones que afectan el mantenimiento general del servicio. El indicador no puede reducir el problema a una partición o una réplica con un estado incorrecto. Entre los ejemplos se incluye una configuración del servicio (como un puerto o un recurso compartido de archivos externo) que causa problemas en todas las particiones. La entidad de servicio se identifica mediante el nombre del servicio (identificador URI).
- Partición. Representa el estado de una partición de servicio. Los informes de mantenimiento de la partición describen las condiciones que afectan al conjunto completo de réplicas. Entre los ejemplos se incluye cuando el número de réplicas es inferior al recuento de destino y cuando la partición tiene una pérdida de cuórum. La entidad de la partición se identifica mediante el identificador de la partición (GUID).
- Réplica. Representa el estado de una réplica de servicio con estado o una instancia de servicio sin estado. La réplica es la unidad menor sobre la que los guardianes y los componentes del sistema pueden informar para una aplicación. En los servicios con estado, entre los ejemplos se incluye una réplica principal que no puede replicar operaciones a réplicas secundarias y ralentiza la replicación. Además, se puede notificar una instancia sin estado si se está quedando sin recursos o tiene problemas de conectividad. La entidad de réplica se identifica mediante el identificador de la partición (GUID) y el identificador de la réplica o instancia (largo).
- DeployedApplication. Representa el estado de a aplicación que se ejecuta en un nodo. Los informes de mantenimiento de la aplicación implementada describen las condiciones específicas de la aplicación en el nodo que no se pueden restringir a paquetes de servicio implementados en el mismo nodo. Entre los ejemplos se incluyen los errores que se producen cuando el paquete de aplicación no se puede descargar en ese nodo y aparecen problemas al configurar las entidades de seguridad de la aplicación en el nodo. La aplicación implementada se identifica mediante el nombre de la aplicación (identificador URI) y el nombre del nodo (cadena).
- DeployedServicePackage. Representa el mantenimiento de un paquete de servicio que se ejecuta en un nodo del clúster. Describe las condiciones específicas de un paquete de servicio que no afectan a los demás paquetes de servicio del mismo nodo para la misma aplicación. Entre los ejemplos se incluye un paquete de código del paquete de servicio que no se puede iniciar y un paquete de configuración que no se puede leer. El paquete de servicio implementado se identifica mediante el nombre de la aplicación (identificador URI), el nombre del nodo (cadena), el nombre del manifiesto de servicio (cadena) y el identificador de activación del paquete de servicio (cadena).
La granularidad del modelo de mantenimiento facilita la detección y corrección de problemas. Por ejemplo, si un servicio no responde, es viable informar de que la instancia de la aplicación es incorrecta. Sin embargo, la creación de informes en este nivel no es lo más adecuado, ya que es posible que el problema no afecte a todos los servicios de la aplicación. El informe se debe aplicar al servicio incorrecto o a una partición secundaria concreta, en caso de que otra información apunte a dicha partición. Los datos aparecen automáticamente en la jerarquía y se puede ver una partición incorrecta en los niveles de servicio y de aplicación. Esta agregación ayuda a identificar y resolver más rápidamente la causa principal del problema.
La jerarquía del mantenimiento se compone de relaciones entre elementos primarios y secundarios. Los clústeres se componen de nodos y aplicaciones. Las aplicaciones tienen servicios y aplicaciones implementadas. Las aplicaciones implementadas han implementado paquetes de servicio. Los servicios tienen particiones y cada partición tiene una o más réplicas. Hay una relación especial entre los nodos y las entidades implementadas. Un nodo en estado incorrecto, tal como lo notifica su componente del sistema de autoridad, el servicio Failover Manager, afecta a las aplicaciones implementadas, a los paquetes de servicios y a las réplicas implementadas en él.
La jerarquía de estado representa el estado más reciente del sistema basándose en los informes de mantenimiento más recientes, que es información casi en tiempo real. Los guardianes internos y externos pueden informar de las mismas entidades según la lógica específica de la aplicación o las condiciones supervisadas personalizadas. Los informes de usuario coexisten con los informes del sistema.
Invierta tiempo en el plan para informar y responder al estado durante el diseño de un servicio en la nube grande. Esta inversión inicial facilita la depuración, supervisión y funcionamiento del servicio.
Estados de mantenimiento
Service Fabric usa tres estados de mantenimiento para describir si una entidad es correcta o no: Correcto, Advertencia y Error. Todos los informes que se envíen al Almacén de estado deben especificar uno de estos estados. El resultado de la evaluación de estado es uno de estos estados.
Los posibles estados de mantenimiento son:
- OK(Correcto). La entidad es correcta. No hay ningún problema conocido notificado en ella o en sus elementos secundarios (en los casos aplicables).
- Warning(Advertencia). La entidad tiene algunos problemas, pero todavía puede funcionar correctamente. Por ejemplo, hay retrasos, pero todavía no causan problemas funcionales. En algunos casos, la condición de advertencia puede corregirse sin intervención externa. En estas ocasiones, los informes de mantenimiento aumentan el conocimiento y proporcionan visibilidad sobre lo que está sucediendo. En otros casos, la condición de advertencia puede dar lugar a un problema grave si no interviene el usuario.
- Error. La entidad es incorrecta. Se debe realizar una acción para corregir el estado de la entidad, ya que no puede funcionar correctamente.
- Unknown(Desconocido). La entidad no existe en el Almacén de estado. Este resultado puede obtenerse a partir de las consultas distribuidas que combinan los resultados de varios componentes. Por ejemplo, la consulta para obtener la lista de nodos se dirige a FailoverManager, ClusterManager y HealthManager; la consulta para obtener la lista de aplicaciones se dirige a ClusterManager y HealthManager. Estas consultas combinan los resultados de varios componentes del sistema. Si otro componente del sistema devuelve una entidad que no está presente en el almacén de estado, el resultado combinado tiene el estado de mantenimiento desconocido. Una entidad no está en el almacén porque aún no se han procesado los informes de estado o la entidad se ha limpiado después de la eliminación.
Directivas de mantenimiento
El Almacén de estado aplica directivas de mantenimiento para determinar si una entidad es correcta en función de sus informes y sus elementos secundarios.
Nota:
Las directivas de mantenimiento se pueden especificar en el manifiesto de clúster (para la evaluación del mantenimiento del clúster y el nodo) o en el manifiesto de aplicación (para la evaluación de la aplicación y cualquiera de sus elementos secundarios). Las solicitudes de evaluación del estado también pueden pasar directivas de evaluación de estado personalizadas, que solo se usan para esa evaluación.
De manera predeterminada, Service Fabric aplica reglas estrictas (todo debe estar correcto) a la relación jerárquica entre elementos primarios y secundarios. Si uno solo de los elementos secundarios tiene un evento incorrecto, el elemento primario se considera incorrecto.
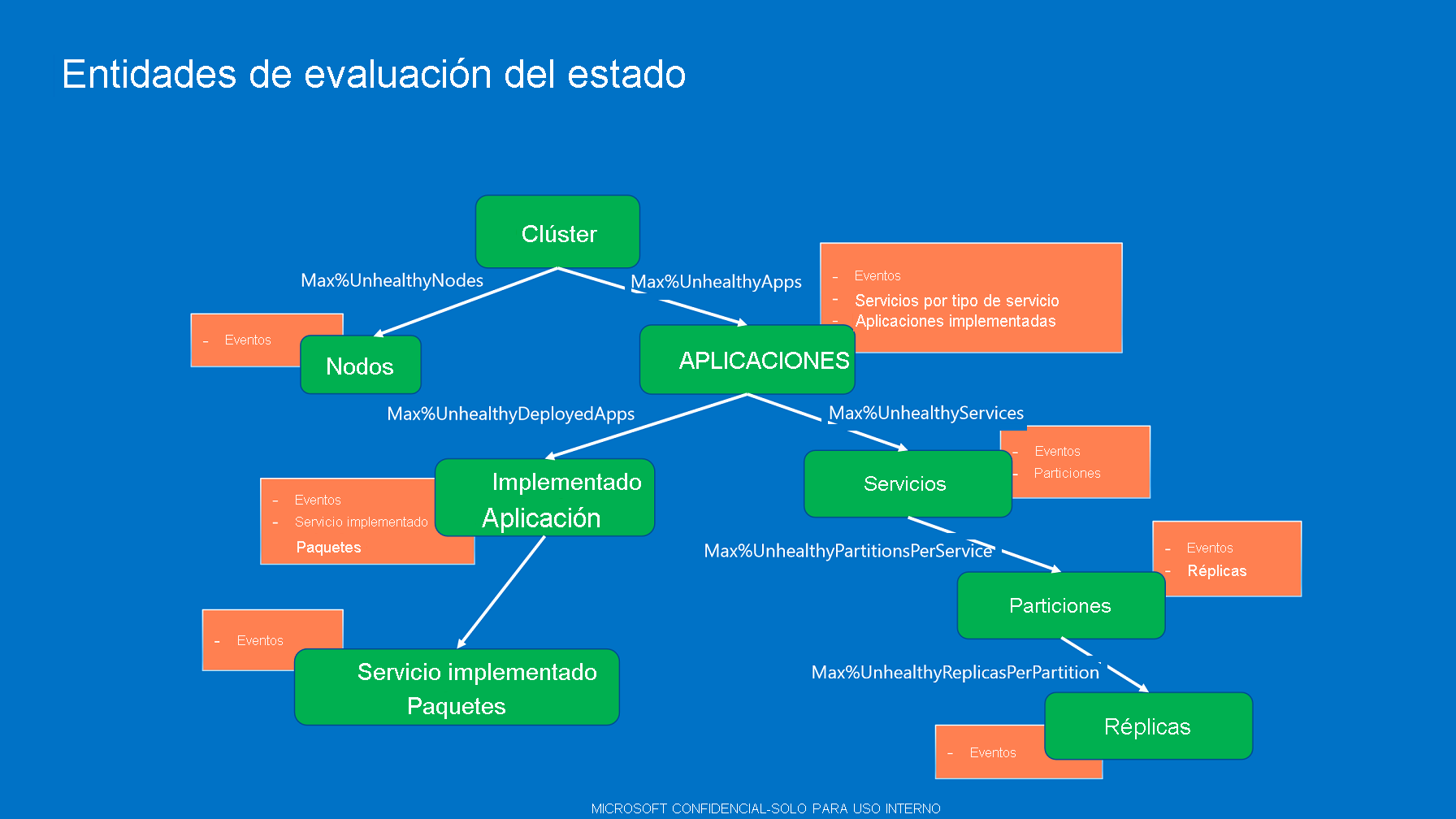
Directiva de mantenimiento de clúster
La directiva de mantenimiento de clúster se usa para evaluar el estado de mantenimiento del clúster y los estados de mantenimiento del nodo. La directiva se puede definir en el manifiesto de clúster. Si no está presente, se utiliza la directiva predeterminada (cero errores tolerados).
La directiva de mantenimiento de clúster contiene:
ConsiderWarningAsError. Especifica si los informes de mantenimiento de advertencia se tratan como errores durante la evaluación del mantenimiento. Valor predeterminado: false.
MaxPercentUnhealthyApplications. Especifica el porcentaje máximo tolerado de aplicaciones que pueden ser incorrectas antes de que el clúster se considere erróneo.
MaxPercentUnhealthyNodes. Especifica el porcentaje máximo tolerado de nodos que pueden ser incorrectas antes de que el clúster se considere erróneo. En los clústeres grandes, siempre hay nodos inactivos o inoperativos debido a reparaciones, por lo que este porcentaje debe configurarse para tolerar ese hecho.
ApplicationTypeHealthPolicyMap. La asignación de directiva de mantenimiento de tipo de aplicación se puede usar durante la evaluación de mantenimiento del clúster para describir tipos de aplicación especiales. De forma predeterminada, todas las aplicaciones se colocan en un grupo y se evalúan con MaxPercentUnhealthyApplications. Si algunos tipos de aplicaciones deben tratarse de manera diferente, es posible sacarlos fuera del grupo global. Entonces, se evalúan con los porcentajes asociados con su nombre de tipo de aplicación en el mapa. Por ejemplo, en un clúster hay miles de aplicaciones de distintos tipos y algunas instancias de la aplicación de control de un tipo especial de aplicación. Las aplicaciones de control nunca deben estar en estado de error. Puede especificar un MaxPercentUnhealthyApplications global al 20 % para tolerar algunos errores pero para el tipo de aplicación "ControlApplicationType", establezca MaxPercentUnhealthyApplications en 0. Así, si alguna de las muchas aplicaciones se encuentra en un estado incorrecto, pero por debajo del porcentaje de error global, el clúster se evaluará con estado de Warning (Advertencia). Un estado de advertencia no afecta a la actualización del clúster ni a ninguna supervisión desencadenada por el estado de mantenimiento de Error. Incluso una única aplicación de control con error hará que el clúster sea incorrecto, lo que desencadena la reversión o pone en pausa la actualización del clúster, en función de la configuración de actualización. En el caso de los tipos de aplicación que se definen en la asignación, todas las instancias de la aplicación se sacan del grupo global de aplicaciones. Se evalúan en función del número total de aplicaciones del tipo de aplicación, mediante el MaxPercentUnhealthyApplications específico de la asignación. El resto de las aplicaciones permanecen en el grupo global y se evalúan con MaxPercentUnhealthyApplications.
El ejemplo siguiente es un extracto de un manifiesto de clúster. Para definir entradas en la asignación de tipos de aplicación, anteponga "ApplicationTypeMaxPercentUnhealthyApplications-" al nombre de parámetro, seguido del nombre del tipo de aplicación.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="ApplicationTypeMaxPercentUnhealthyApplications-ControlApplicationType" Value="0" /> </Section> </FabricSettings>NodeTypeHealthPolicyMap. La asignación de directiva de mantenimiento de tipo de nodo se puede usar durante la evaluación del mantenimiento de clúster para describir tipos de nodo especiales. Los tipos de nodo se evalúan en relación con los porcentajes asociados con el nombre del tipo de nodo en la asignación. La configuración de este valor no tiene efecto sobre el grupo global de nodos usados paraMaxPercentUnhealthyNodes. Por ejemplo, un clúster tiene cientos de nodos de distinta naturaleza y algunos tipos de nodos que hospedan trabajo importante. Ninguno de estos tipos de nodos deberían estar inactivos. Puede establecer el valor global deMaxPercentUnhealthyNodesen 20 % para que tolere algunos errores en todos los nodos, pero para el tipo de nodoSpecialNodeType, establezcaMaxPercentUnhealthyNodesen 0. De este modo, si algunos de los diversos nodos son incorrectos pero están por debajo del porcentaje global incorrecto, el clúster se evaluará como si tuviera el estado de mantenimiento de advertencia. El estado de mantenimiento de advertencia no afecta a la actualización del clúster ni a otras actividades de supervisión desencadenada por el estado de mantenimiento de error. Pero incluso un nodo de tipoSpecialNodeTypeen un estado de mantenimiento de error haría que el clúster fuera incorrecto y desencadenara la reversión o detuviera la actualización del clúster, dependiendo de la configuración de actualización. Por el contrario, si el valor global deMaxPercentUnhealthyNodesse establece en 0 y el porcentaje máximo de nodosSpecialNodeTypeincorrectos se establece en 100, con un nodo de tipoSpecialNodeTypeen estado de error, el clúster se mantendrá en estado de error porque la restricción global es más estricta en este caso.El ejemplo siguiente es un extracto de un manifiesto de clúster. Para definir entradas en la asignación de tipo de nodo, agregue el prefijo "NodeTypeMaxPercentUnhealthyNodes-" al nombre del parámetro, seguido de nombre del tipo de nodo.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="NodeTypeMaxPercentUnhealthyNodes-SpecialNodeType" Value="0" /> </Section> </FabricSettings>
Directiva de mantenimiento de aplicación
La directiva de mantenimiento de aplicación describe cómo se realiza la evaluación de la agregación de eventos y estados secundarios en las aplicaciones y sus elementos secundarios. Se puede definir en el manifiesto de la aplicación, ApplicationManifest.xml, del paquete de aplicación. Si no se especifican directivas, Service Fabric asume que la entidad es incorrecta si tiene un informe de mantenimiento o un elemento secundario en los estados de mantenimiento Advertencia o Error. Las directivas configurables son:
- ConsiderWarningAsError. Especifica si los informes de mantenimiento de advertencia se tratan como errores durante la evaluación del mantenimiento. Valor predeterminado: false.
- MaxPercentUnhealthyDeployedApplications. Especifica el porcentaje máximo tolerado de aplicaciones implementadas que pueden ser incorrectas antes de que la aplicación se considere errónea. Dicho porcentaje se calcula dividiendo el número de aplicaciones implementadas incorrectas entre el número de nodos en los que las aplicaciones están implementadas actualmente en el clúster. El cálculo se redondea hacia arriba para tolerar un error en números reducidos de nodos. Porcentaje de predeterminado: cero.
- DefaultServiceTypeHealthPolicy. Especifica la directiva de mantenimiento del tipo de servicio predeterminada, que reemplaza a la directiva de mantenimiento predeterminada para todos los tipos de servicio de la aplicación.
- ServiceTypeHealthPolicyMap. Proporciona un mapa de las directivas de mantenimiento de servicios por tipo de servicio. Estas directivas reemplazan a las directivas de mantenimiento del tipo de servicio predeterminadas en todos los tipos de servicio especificados. Por ejemplo, si una aplicación tiene un tipo de servicio de puerta de enlace sin estado y un tipo de servicio de motor con estado, puede configurar las directivas de mantenimiento para su evaluación de una manera diferente. Si especifica una directiva por tipo de servicio, podrá obtener un control más pormenorizado del mantenimiento del servicio.
Directiva de mantenimiento de tipo de servicio
La directiva de mantenimiento de tipo de servicio especifica cómo evaluar y agregar los servicios y los elementos secundarios de servicios. La directiva contiene:
- MaxPercentUnhealthyPartitionsPerService. Especifica el porcentaje máximo tolerado de particiones incorrectas antes de que un servicio se considere incorrecto. Porcentaje de predeterminado: cero.
- MaxPercentUnhealthyReplicasPerPartition. Especifica el porcentaje máximo tolerado de réplicas incorrectas antes de que una partición se considere incorrecta. Porcentaje de predeterminado: cero.
- MaxPercentUnhealthyServices. Especifica el porcentaje máximo tolerado de servicios incorrectos antes de que la aplicación se considere incorrecta. Porcentaje de predeterminado: cero.
El ejemplo siguiente es un extracto de un manifiesto de aplicación:
<Policies>
<HealthPolicy ConsiderWarningAsError="true" MaxPercentUnhealthyDeployedApplications="20">
<DefaultServiceTypeHealthPolicy
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="10"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="FrontEndServiceType"
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="20"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="BackEndServiceType"
MaxPercentUnhealthyServices="20"
MaxPercentUnhealthyPartitionsPerService="0"
MaxPercentUnhealthyReplicasPerPartition="0">
</ServiceTypeHealthPolicy>
</HealthPolicy>
</Policies>
Evaluación de estado
Los usuarios y servicios automatizados pueden evaluar el mantenimiento de cualquier entidad en cualquier momento. Para evaluar el mantenimiento de una entidad, el Almacén de estado agrega todos los informes de mantenimiento en la entidad y evalúa todos sus elementos secundarios (si procede). El algoritmo de agregación de mantenimiento usa las directivas de mantenimiento que especifican cómo se evalúan los informes de mantenimiento y cómo se agregan los estados de mantenimiento de los elementos secundarios (si procede).
Agregación de informes de mantenimiento
Una entidad puede tener varios informes de mantenimiento enviados por informadores diferentes (componentes del sistema o guardianes) en diferentes propiedades. La agregación usa las directivas de mantenimiento asociadas, en concreto, el miembro ConsiderWarningAsError de la aplicación o la directiva de mantenimiento del clúster. ConsiderWarningAsError especifica cómo evaluar las advertencias.
El estado de mantenimiento agregado se desencadena por los peores informes de mantenimiento sobre la entidad. Si hay al menos un informe de mantenimiento que indica un error, el estado de mantenimiento agregado será Error.
Una entidad de mantenimiento con uno o más informes de mantenimiento de error se evalúa como Error. Lo mismo puede decirse de un informe de mantenimiento expirado, independientemente de su estado de mantenimiento.
Si no hay informes de error, pero aparecen una o varias advertencias, el estado de mantenimiento agregado es Advertencia o Error, en función de la marca de la directiva ConsiderWarningAsError.
Agregación del informe de mantenimiento con el informe de advertencia y ConsiderWarningAsError establecido en false (valor predeterminado).
Agregación de mantenimiento de elementos secundarios
El estado de mantenimiento agregado de una entidad refleja los estados de mantenimiento de los elementos secundarios (si procede). El algoritmo para la agregación de estados de mantenimiento de elementos secundarios usa las directivas de mantenimiento aplicables según el tipo de entidad.
Agregación de elementos secundarios basada en directivas de mantenimiento.
Después de que el Almacén de estado haya evaluado todos los elementos secundarios, agrega sus estados de mantenimiento en función del porcentaje máximo configurado de los elementos secundarios incorrectos. Este porcentaje se obtiene de la directiva según el tipo de entidad y de elemento secundario.
- Si el estado de todos los elementos secundarios es Correcto, el estado de mantenimiento agregado de los elementos secundarios es Correcto.
- Si los elementos secundarios tienen los estados Correcto y Advertencia, el estado de mantenimiento agregado de los elementos secundarios es Advertencia.
- Si hay elementos secundarios con los estados Error que no respetan el porcentaje máximo permitido de elementos secundarios incorrectos, el estado de mantenimiento principal agregado es Error.
- Si los elementos secundarios con estados de Error respetan el porcentaje máximo permitido de los elementos secundarios incorrectos, el estado de mantenimiento principal agregado es Advertencia.
Informes de mantenimiento
Tanto los componentes del sistema como los guardianes internos o externos pueden generar informes de las entidades de Service Fabric. Los informadores realizan determinaciones locales del mantenimiento de las entidades supervisadas en función de las condiciones que supervisan. No necesitan examinar ningún estado global ni agregar datos. El comportamiento deseado es tener informadores sencillos y no organismos complejos que necesitan examinar muchos datos para inferir la información que van a enviar.
Para enviar datos de mantenimiento al Almacén de estado, los informadores necesitan identificar la entidad afectada y crear un informe de mantenimiento. Para enviar el informe, utilice la API FabricClient.HealthClient.ReportHealth, las API de informe de mantenimiento expuestas en los objetos Partition o CodePackageActivationContext, cmdlets de PowerShell o REST.
Informes de mantenimiento
Los informes de mantenimiento para cada una de las entidades del clúster contienen la siguiente información:
SourceId. Cadena que identifica de forma única el informador del evento de estado.
Identificador de entidad. Identifica la entidad en la que se aplica el informe. Es diferente según el tipo de entidad:
- Clúster. Ninguno.
- Nodo. Nombre de nodo (cadena).
- Aplicación. Nombre de aplicación (identificador URI). Representa el nombre de la instancia de aplicación implementada en el clúster.
- Servicio. Nombre de servicio (identificador URI). Representa el nombre de la instancia de servicio implementada en el clúster.
- Partición. Identificador de partición (GUID). Representa el identificador único de la partición.
- Réplica. El identificador de réplica de servicio con estado o el identificador de instancia de servicio sin estado (INT64).
- DeployedApplication. Nombre de aplicación (identificador URI) y nombre de nodo (cadena).
- DeployedServicePackage. Nombre de aplicación (identificador URI), nombre de nodo (cadena) y nombre de manifiesto de servicio (cadena).
Propiedad. Un cadena (no una enumeración fija) que permite al informador clasificar el evento de estado para una propiedad específica de la entidad. Por ejemplo, el informador A puede notificar el estado de la propiedad de "almacenamiento" de Node01 y el informador B puede notificar el estado de la propiedad de "conectividad" de Node01. En el Almacén de estado, estos informes se tratan como eventos de mantenimiento de la entidad Node01.
Descripción. Una cadena que permite a un informador proporcionar información detallada sobre el evento de mantenimiento. SourceId, Property y HealthState deben describir por completo el informe. La descripción agrega información en lenguaje natural sobre el informe. El texto facilita la comprensión, tanto a usuarios como a administradores, del informe de mantenimiento.
HealthState. Una enumeración que describe el estado de mantenimiento del informe. Los valores aceptados son Correcto, Advertencia y Error.
TimeToLive. Intervalo de tiempo que indica cuánto tiempo es válido el informe de mantenimiento. Si se combina con RemoveWhenExpired, permite al Almacén de estado saber cómo evaluar los eventos expirados. De forma predeterminada, el valor es infinito y el informe es válido para siempre.
RemoveWhenExpired. Un valor booleano. Si está establecido en true, el informe de mantenimiento expirado se elimina automáticamente del Almacén de estado y no afecta a la evaluación del mantenimiento de la entidad. Se usa cuando el informe es válido solo durante un período de tiempo y el informador no necesita vaciarlo de manera explícita. También se utiliza para eliminar informes del Almacén de estado (por ejemplo, se cambia un guardián y deja de enviar informes con la propiedad y el origen anteriores). Puede enviar un informe con valor de TimeToLive pequeño, junto con RemoveWhenExpired para borrar cualquier estado anterior del Almacén de estado. Si el valor se establece en false, el informe expirado se trata como un error en la evaluación del mantenimiento. El valor false indica al Almacén de estado que el origen debe notificar periódicamente esta propiedad. Si no lo hace, debe haber algún error en el guardián. El mantenimiento del guardián se captura considerando el evento como error.
SequenceNumber. Un entero positivo que debe ir en constante aumento y representa el orden de los informes. Lo usa el Almacén de estado para detectar informes obsoletos que se reciben tarde debido a retrasos en la red u otros problemas. Un informe se rechaza si el número de secuencia es menor o igual que el último número aplicado a la misma entidad, origen y propiedad. Si no se especifica, el número de secuencia se genera automáticamente. Solo es necesario colocar el número de secuencia cuando se informa de las transiciones de estado. En esta situación, el origen necesita recordar los informes que envió y conservar la información para la recuperación de conmutación por error.
Estos cuatro datos (SourceId, entity identifier, Property y HealthState) se requieren en todos los informes de mantenimiento. No se permite que la cadena de SourceId comience por el prefijo "System. ", que se reserva para los informes del sistema. Para la misma entidad solo hay un informe del mismo origen y propiedad. Los informes del mismo origen y propiedad se invalidan entre sí, ya sea en el lado del cliente de mantenimiento (si se procesan por lotes) o en el lado del Almacén de estado. La sustitución se realiza basándose en los números de secuencia; los informes más recientes (con un número de secuencia mayor) reemplazan a los informes anteriores.
Eventos de estado
Internamente, el Almacén de estado conserva los eventos de mantenimiento, que contienen toda la información de los informes y metadatos adicionales. Los metadatos incluyen la hora en que el informe se dio al cliente de mantenimiento y la hora en que se modificó en el servidor. Los eventos de mantenimiento los devuelven las consultas de mantenimiento.
Los metadatos agregados contienen:
- SourceUtcTimestamp. La hora en que el informe se dio al cliente de mantenimiento (hora universal coordinada)
- LastModifiedUtcTimestamp. La hora en que el informe se modificó por última vez en el servidor (hora universal coordinada)
- IsExpired. Marca que indica si el informe había expirado cuando el Almacén de estado ejecutó la consulta. Un evento ha expirado solo si RemoveWhenExpired está establecido en false. De lo contrario, la consulta no devuelve el evento y se elimina del almacén.
- LastOkTransitionAt, LastWarningTransitionAt, LastErrorTransitionAt. La última hora de las transiciones correctas, con advertencia o con error. Estos campos muestran el historial de las transiciones del estado de mantenimiento del evento.
Los campos de la transición de estado se pueden usar para alertas inteligentes o información del "historial" de eventos de mantenimiento. Habilitan escenarios como:
- Alertar cuando una propiedad ha estado en los estados Advertencia o Error durante más de X minutos. La comprobación de la condición durante un período de tiempo evita las alertas sobre condiciones temporales. Por ejemplo, una alerta si el estado de mantenimiento ha sido Advertencia durante más de cinco minutos se puede traducir como (HealthState == Warning y Now - LastWarningTransitionTime > 5 minutes).
- Alertar solo sobre las condiciones que han cambiado en los últimos X minutos. Si el estado de un informe ya era Error antes de la hora especificada, se puede ignorar, porque ya se había señalado con anterioridad.
- Si una propiedad alterna entre Advertencia y Error, determine cuánto tiempo ha sido incorrecta (es decir, que no ha sido correcta). Por ejemplo, una alerta si la propiedad no ha sido correcta durante más de cinco minutos se pueden traducir como (HealthState != Ok y Now - LastOkTransitionTime > 5 minutes).
Ejemplo: informar y evaluar el mantenimiento de una aplicación
En el ejemplo siguiente se envía un informe de mantenimiento a través de PowerShell en la aplicación fabric:/WordCountdesde el MyWatchdog de origen. El informe de mantenimiento contiene información sobre la "disponibilidad" de la propiedad de mantenimiento en un estado de mantenimiento de error, con un valor de TimeToLive infinito. Luego consulta el mantenimiento de la aplicación, que devuelve los errores del estado de mantenimiento agregado y los eventos de mantenimiento notificados en la lista de eventos de mantenimiento.
PS C:\> Send-ServiceFabricApplicationHealthReport –ApplicationName fabric:/WordCount –SourceId "MyWatchdog" –HealthProperty "Availability" –HealthState Error
PS C:\> Get-ServiceFabricApplicationHealth fabric:/WordCount -ExcludeHealthStatistics
ApplicationName : fabric:/WordCount
AggregatedHealthState : Error
UnhealthyEvaluations :
Error event: SourceId='MyWatchdog', Property='Availability'.
ServiceHealthStates :
ServiceName : fabric:/WordCount/WordCountService
AggregatedHealthState : Error
ServiceName : fabric:/WordCount/WordCountWebService
AggregatedHealthState : Ok
DeployedApplicationHealthStates :
ApplicationName : fabric:/WordCount
NodeName : _Node_0
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_2
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_3
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_4
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_1
AggregatedHealthState : Ok
HealthEvents :
SourceId : System.CM
Property : State
HealthState : Ok
SequenceNumber : 360
SentAt : 3/22/2016 7:56:53 PM
ReceivedAt : 3/22/2016 7:56:53 PM
TTL : Infinite
Description : Application has been created.
RemoveWhenExpired : False
IsExpired : False
Transitions : Error->Ok = 3/22/2016 7:56:53 PM, LastWarning = 1/1/0001 12:00:00 AM
SourceId : MyWatchdog
Property : Availability
HealthState : Error
SequenceNumber : 131032204762818013
SentAt : 3/23/2016 3:27:56 PM
ReceivedAt : 3/23/2016 3:27:56 PM
TTL : Infinite
Description :
RemoveWhenExpired : False
IsExpired : False
Transitions : Ok->Error = 3/23/2016 3:27:56 PM, LastWarning = 1/1/0001 12:00:00 AM
Uso del modelo de estado
El modelo de mantenimiento permite escalar los servicios en la nube y la plataforma de Service Fabric subyacente, ya que las determinaciones de supervisión y mantenimiento se distribuyen entre los distintos monitores del clúster. Otros sistemas tienen un solo servicio centralizado en el nivel de clúster que analiza toda la información potencialmente útil que emiten los servicios. Este enfoque dificulta su escalabilidad. Tampoco les permite recopilar información específica para ayudar a identificar problemas reales y potenciales acercándose lo máximo posible a su causa raíz.
El modelo de mantenimiento se usa mucho para la supervisión y el diagnóstico, para evaluar el mantenimiento de clústeres y aplicaciones, y para las actualizaciones supervisadas. Otros servicios usan los datos de mantenimiento para realizar reparaciones automáticas, generar el historial de mantenimiento de los clústeres y emitir alertas en determinadas condiciones.
Pasos siguientes
Vista de los informes de estado de Service Fabric
Uso de informes de mantenimiento del sistema para solucionar problemas
Notificación y comprobación del estado del servicio
Incorporación de informes de mantenimiento de Service Fabric personalizados