Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure Stream Analytics admite la creación de particiones de salida de blob personalizada con atributos o campos personalizados y patrones personalizados de ruta de acceso de DateTime.
Atributos o campos personalizados
Los campos o atributos de entrada personalizados mejoran los flujos de trabajo de procesamiento de datos e informes descendentes, ya que le otorgan más control sobre la salida.
Opciones de clave de partición
La clave de partición, o el nombre de columna, que se usa para particionar los datos de entrada pueden contener cualquier carácter que se acepte para nombres de blob. No es posible usar los campos anidados como clave de partición, a menos que se usen junto con los alias. Sin embargo, puede usar determinados caracteres para crear una jerarquía de archivos. Por ejemplo, para crear una columna que combine datos de otras dos columnas para crear una clave de partición única, puede usar la siguiente consulta:
SELECT name, id, CONCAT(name, "/", id) AS nameid
La clave de partición debe ser NVARCHAR(MAX), BIGINT, FLOAT o BIT (nivel de compatibilidad 1.2 o superior). Los tipos DateTime, Array y Records no se admiten, pero se pueden usar como claves de partición si se convierten en cadenas. Para más información, consulte los tipos de datos de Azure Stream Analytics.
Ejemplo
Supongamos que un trabajo toma datos de entrada de sesiones de usuarios en directo que están conectadas a un servicio externo de videojuegos en el que los datos incorporados contienen una columna client_id para identificar las sesiones. Para crear particiones de los datos por client_id, establezca el blob Patrón de ruta de acceso para incluir un token de partición {client_id} en las propiedades de salida del blob al crear un trabajo. A medida que los datos con varios valores de client_id pasan por el trabajo de Stream Analytics, los datos de salida se guardan en carpetas independientes con un valor de client_id único por carpeta.

De forma similar, si la entrada del trabajo eran datos de sensor de millones de sensores, de forma que cada uno tenía un sensor_id, el patrón de ruta de acceso sería {sensor_id} para particionar los datos de cada sensor en una carpeta diferente.
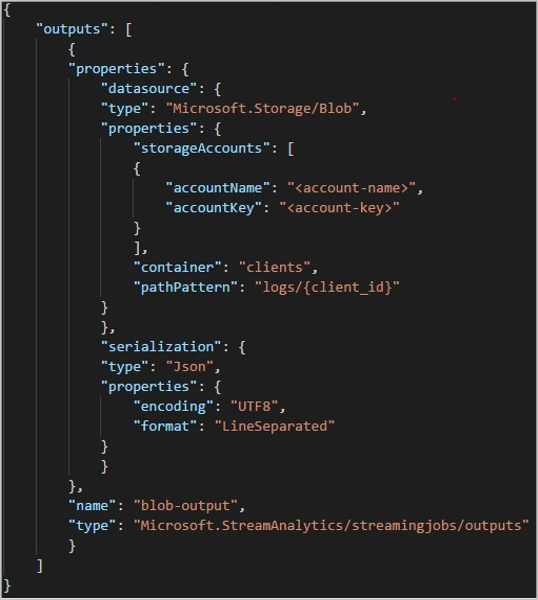
Cuando usa la API de REST, la sección de salida de un archivo JSON que se ha usado para dicha solicitud puede ser similar a la siguiente imagen:
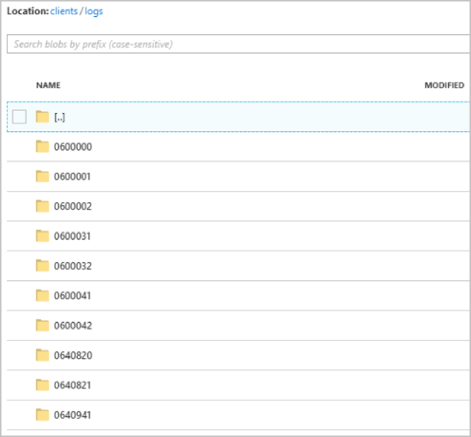
Una vez que se inicia la ejecución del trabajo, el contenedor de clients podría ser similar a la siguiente imagen:
Cada carpeta puede contener varios blobs, de forma que cada blob contiene uno o más registros. En el ejemplo anterior, hay un único blob en una carpeta etiquetada como "06000000" con el siguiente contenido:
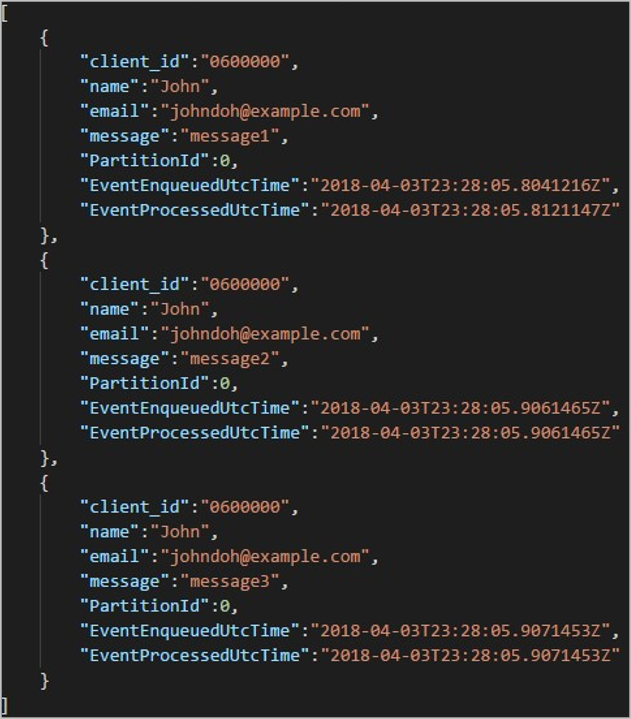
Tenga en cuenta que cada registro en el blob tiene una columna client_id que coincide con el nombre de la carpeta porque se usó la columna client_id para particionar la salida en la ruta de acceso.
Limitaciones
Solo se permite una clave de partición personalizada en la propiedad de patrón de ruta de acceso de la salida del blob. Todos los patrones de ruta de acceso siguientes son válidos:
cluster1/{date}/{aFieldInMyData}cluster1/{time}/{aFieldInMyData}cluster1/{aFieldInMyData}cluster1/{date}/{time}/{aFieldInMyData}
Si los clientes quieren usar más de un campo de entrada, pueden crear una clave compuesta en la consulta para la partición de ruta de acceso personalizada en la salida del blob mediante
CONCAT. Un ejemplo esselect concat (col1, col2) as compositeColumn into blobOutput from input. A continuación, pueden especificarcompositeColumncomo ruta de acceso personalizada en Azure Blob Storage.Las claves de partición no distinguen mayúsculas de minúsculas, por lo que los valores como
Johnyjohnson equivalentes. Además, no pueden usarse expresiones como clave de partición. Por ejemplo,{columnA + columnB}no funciona.Cuando un flujo de entrada consta de registros con una cardinalidad de clave de partición menor que 8,000, los registros se anexan a los blobs existentes. Solo crean nuevos blobs cuando sea necesario. Si la cardinalidad es superior a 8000, no hay ninguna garantía de que se escriban blobs existentes. Los nuevos blobs no se crearán para un número arbitrario de registros con la misma clave de partición.
Si el resultado del blob está configurado como inmutable, Stream Analytics crea un blob cada vez que se envíen los datos.
Patrones personalizados de ruta de acceso de fecha y hora
Los patrones de la ruta de acceso de DateTime personalizados le permiten especificar un formato de salida que se alinee con las convenciones de Hive Streaming, lo que le proporciona a Stream Analytics la capacidad de enviar datos a Azure HDInsight y Azure Databricks para su procesamiento posterior. Los patrones de la ruta de acceso de DateTime personalizados se implementan fácilmente utilizando la palabra clave datetime en el campo Prefijo de ruta de acceso de la salida de blob, así como el especificador de formato. Un ejemplo es {datetime:yyyy}.
Tokens admitidos
Los siguientes tokens del especificador de formato se pueden utilizar solos o en combinación para conseguir formatos personalizados de DateTime.
| Especificador de formato | Descripción | Resultados en la hora de ejemplo 2018-01-02T10: 06: 08 |
|---|---|---|
| {datetime:yyyy} | El año como un número de cuatro dígitos | 2018 |
| {datetime:MM} | Mes desde 01 hasta 12 | 01 |
| {datetime:M} | Mes desde 1 hasta 12 | 1 |
| {datetime:dd} | Día desde 01 hasta 31 | 02 |
| {datetime:d} | Día desde 1 hasta 31 | 2 |
| {datetime:HH} | Hora con el formato de 24 horas, de 00 a 23 | 10 |
| {datetime:mm} | Minutos de 00 a 60 | 06 |
| {datetime:m} | Minutos de 0 a 60 | 6 |
| {datetime:ss} | Segundos de 00 a 60 | 08 |
Si no quiere usar patrones de DateTime personalizados, puede agregar el token {date} o {time} al prefijo de ruta de acceso para crear un menú desplegable con los formatos incorporados de DateTime.
Extensibilidad y restricciones
Puede usar tantos tokens ({datetime:<specifier>}) como desee en el patrón de ruta de acceso hasta alcanzar el límite de caracteres de prefijo de ruta de acceso. Los especificadores de formato no se pueden combinar en un solo token si van más allá de las combinaciones ya enumeradas en los menús desplegables de fecha y hora.
Para una partición de ruta de logs/MM/dd:
| Expresión válida | Expresión no válida |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
Puede usar el mismo especificador de formato varias veces en el prefijo de ruta de acceso. El token debe repetirse cada vez.
Convenciones de Hive Streaming
Los patrones de ruta de acceso personalizados para Blob Storage se pueden usar con la convención Hive Streaming, que espera que las carpetas estén etiquetadas con column= en el nombre de la carpeta.
Un ejemplo es year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}.
La salida personalizada elimina la necesidad de tener que alterar las tablas y agregar particiones manualmente a los datos de puertos que estén entre Stream Analytics y Hive. En su lugar, muchas carpetas se pueden agregar automáticamente mediante:
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
Ejemplo
Cree una cuenta de almacenamiento, un grupo de recursos, un trabajo de Stream Analytics y un origen de entrada de acuerdo con el inicio rápido de Stream Analytics mediante Azure Portal. Use los mismos datos de ejemplo usados en el inicio rápido. Los datos de ejemplo también están disponibles en GitHub.
Cree un receptor de salida de blob con la siguiente configuración:
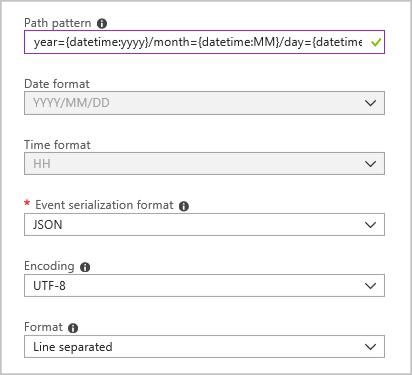
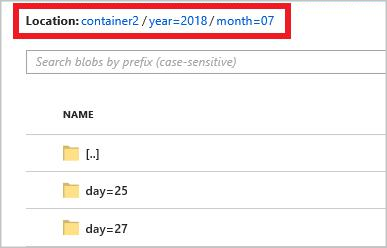
El patrón de ruta de acceso completa es:
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
Cuando inicie el trabajo, se creará una estructura de carpetas basada en el patrón de la ruta de acceso en el contenedor de blobs. Puede explorar en profundidad hasta llegar al nivel del día.