Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo, aprenderá a usar MLlib de Apache Spark para crear una aplicación de aprendizaje automático para efectuar análisis predictivos simples en un conjunto de datos abierto de Azure. Spark proporciona bibliotecas de aprendizaje automático integradas. En este ejemplo se usa la clasificación a través de la regresión logística.
SparkML y MLlib son bibliotecas básicas de Spark que proporcionan varias utilidades que resultan prácticas para las tareas de aprendizaje automático, incluidas las utilidades adecuadas para:
- Clasificación
- Regresión
- Agrupación en clústeres
- Modelado de tema
- Descomposición en valores singulares (SVD) y Análisis de los componentes principales (PCA)
- Comprobación de hipótesis y cálculo de estadísticas de ejemplo
Comprensión de la clasificación y la regresión logística
Clasificación, una tarea habitual en el aprendizaje automático, es el proceso de ordenación de datos de entrada en categorías. Es trabajo de un algoritmo de clasificación averiguar cómo asignar etiquetas a los datos de entrada que se proporcionan. Por ejemplo, piense en un algoritmo de aprendizaje automático que acepta información bursátil como entrada y divide las existencias en dos categorías: acciones que se deberían vender y acciones que se deberían conservar.
La Regresión logística es un algoritmo que puede usar para la clasificación. La API de regresión logística de Spark es útil para la clasificación binaria, o para la clasificación de datos de entrada en uno de los dos grupos. Para más información acerca de la regresión logística, consulte la Wikipedia.
En resumen, el proceso de regresión logística genera una función logística que se puede usar para predecir la probabilidad de que un vector de entrada pertenezca a un grupo o al otro.
Ejemplo de análisis predictivo en los datos de los taxis de Nueva York
En este ejemplo, se usa Spark para realizar un análisis predictivo de los datos de propinas de las carreras de taxi de Nueva York. Los datos están disponibles a través de Azure Open Datasets. Este subconjunto del conjunto de datos contiene información acerca de los viajes en taxi amarillo, incluida información sobre cada viaje, la hora y los lugares de inicio y finalización, los costos y otros atributos de interés.
Importante
Se pueden aplicar cargos adicionales por la extracción de estos datos de la ubicación de almacenamiento.
En los pasos siguientes, desarrollará un modelo para predecir si una carrera determinada incluye propina o no.
Creación de un modelo de Machine Learning de Apache Spark
Cree un cuaderno mediante el kernel de PySpark. Para obtener instrucciones, consulte Crear un cuaderno.
Importe los tipos necesarios para esta aplicación. Copie y pegue el siguiente código en una celda vacía y presione Mayús + Entrar. O bien, ejecute la celda con el icono de reproducción azul situado a la izquierda del código.
import matplotlib.pyplot as plt from datetime import datetime from dateutil import parser from pyspark.sql.functions import unix_timestamp, date_format, col, when from pyspark.ml import Pipeline from pyspark.ml import PipelineModel from pyspark.ml.feature import RFormula from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorIndexer from pyspark.ml.classification import LogisticRegression from pyspark.mllib.evaluation import BinaryClassificationMetrics from pyspark.ml.evaluation import BinaryClassificationEvaluatorDebido a la existencia del kernel PySpark, no necesitará crear ningún contexto explícitamente. El contexto de Spark se crea automáticamente al ejecutar la primera celda de código.
Construcción de una trama de datos de entrada
Dado que los datos sin procesar están en formato de Parquet, puede usar el contexto de Spark para extraer el archivo a la memoria como trama de datos directamente. Aunque el código de los pasos siguientes usa las opciones predeterminadas, es posible forzar la asignación de tipos de datos y otros atributos de esquema, de ser necesario.
Ejecute las líneas siguientes para crear un marco de datos de Spark pegando el código en una nueva celda. Se recupera este paso mediante la API de Open Datasets. La extracción de todos estos datos genera aproximadamente 1,5 millones de filas.
En función del tamaño del grupo de Apache Spark sin servidor, los datos sin procesar pueden ser demasiado grandes o tardar demasiado para poder trabajar con ellos. Puede filtrar estos datos hasta algo más pequeño. En el ejemplo de código siguiente se usa
start_dateyend_datepara aplicar un filtro que devuelve un mes único de datos.from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())El inconveniente del filtrado sencillo es que, desde una perspectiva estadística, podría introducir sesgos en los datos. Otro enfoque consiste en usar el muestreo integrado en Spark.
El código siguiente reduce el conjunto de datos hasta aproximadamente 2000 filas, si se aplica después del código anterior. Puede usar este paso de muestreo en lugar del filtro simple o junto con él.
# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234)Ahora es posible examinar los datos para ver qué se ha leído. Normalmente, es mejor revisar los datos con un subconjunto en lugar del conjunto completo, en función del tamaño del conjunto de datos.
El código siguiente ofrece dos maneras de ver los datos. La primera es básica. La segunda proporciona una experiencia de cuadrícula mucho más rica, junto con la capacidad de visualizar los datos gráficamente.
#sampled_taxi_df.show(5) display(sampled_taxi_df)En función del tamaño del conjunto de datos generado y de la necesidad de experimentar o ejecutar el cuaderno muchas veces, podría querer almacenar en caché el conjunto de datos localmente en el área de trabajo. Hay tres maneras de realizar el almacenamiento en caché explícito:
- Guardar el marco de datos localmente como un archivo
- Usar el marco de datos como vista o tabla temporal
- Guardar el marco de datos como tabla permanente
Los dos primeros enfoques se incluyen en los siguientes ejemplos de código.
La creación de una vista o tabla temporal ofrece diferentes rutas de acceso a los datos, pero solo durante la vigencia de la sesión de la instancia de Spark.
sampled_taxi_df.createOrReplaceTempView("nytaxi")
Preparación de los datos
Los datos en su formato sin procesar no suelen ser adecuados para pasar directamente a un modelo. Debe realizar una serie de acciones en los datos para llevarlos a un estado en el que el modelo pueda consumirlos.
En el código siguiente, se realizan cuatro clases de operaciones:
- La eliminación de valores atípicos o valores incorrectos a través del filtrado.
- La eliminación de columnas que no son necesarias.
- La creación de nuevas columnas derivadas de los datos sin procesar para que el modelo funcione de forma más eficaz. Esta operación a veces se denomina caracterización.
- Etiquetado. Como está llevando a cabo una clasificación binaria (habrá una propina o no en una carrera determinada), es necesario convertir el importe de la propina en un valor 0 o 1.
taxi_df = sampled_taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\
, 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\
, date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\
, date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\
, (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\
, (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped')
)\
.filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\
& (sampled_taxi_df.tipAmount >= 0) & (sampled_taxi_df.tipAmount <= 25)\
& (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\
& (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\
& (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 100)\
& (sampled_taxi_df.rateCodeId <= 5)
& (sampled_taxi_df.paymentType.isin({"1", "2"}))
)
Después, realice un segundo paso sobre los datos para agregar las características finales.
taxi_featurised_df = taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'passengerCount'\
, 'tripDistance', 'weekdayString', 'pickupHour','tripTimeSecs','tipped'\
, when((taxi_df.pickupHour <= 6) | (taxi_df.pickupHour >= 20),"Night")\
.when((taxi_df.pickupHour >= 7) & (taxi_df.pickupHour <= 10), "AMRush")\
.when((taxi_df.pickupHour >= 11) & (taxi_df.pickupHour <= 15), "Afternoon")\
.when((taxi_df.pickupHour >= 16) & (taxi_df.pickupHour <= 19), "PMRush")\
.otherwise(0).alias('trafficTimeBins')
)\
.filter((taxi_df.tripTimeSecs >= 30) & (taxi_df.tripTimeSecs <= 7200))
Crear un modelo de regresión logística
La última tarea consiste en convertir los datos etiquetados a un formato que se pueda analizar mediante la regresión logística. La entrada a un algoritmo de regresión logística debe ser un conjunto de pares de vector de etiqueta-característica, donde el vector de característica es un vector de números que representa el punto de entrada.
Por lo tanto, es necesario convertir las columnas de categorías en números. En concreto, debe convertir las columnas trafficTimeBins y weekdayString en representaciones de enteros. Hay varios enfoques para realizar la conversión. En el ejemplo siguiente, se adopta el enfoque de OneHotEncoder, que es común.
# Because the sample uses an algorithm that works only with numeric features, convert them so they can be consumed
sI1 = StringIndexer(inputCol="trafficTimeBins", outputCol="trafficTimeBinsIndex")
en1 = OneHotEncoder(dropLast=False, inputCol="trafficTimeBinsIndex", outputCol="trafficTimeBinsVec")
sI2 = StringIndexer(inputCol="weekdayString", outputCol="weekdayIndex")
en2 = OneHotEncoder(dropLast=False, inputCol="weekdayIndex", outputCol="weekdayVec")
# Create a new DataFrame that has had the encodings applied
encoded_final_df = Pipeline(stages=[sI1, en1, sI2, en2]).fit(taxi_featurised_df).transform(taxi_featurised_df)
Esta acción da como resultado un nuevo marco de datos con todas las columnas en el formato correcto para entrenar un modelo.
Entrenamiento de un modelo de regresión logística
La primera tarea consiste en dividir el conjunto de filas en un conjunto de entrenamiento y un conjunto de pruebas o validación. La división aquí es arbitraria. Experimente con diferentes configuraciones de división para ver si afectan al modelo.
# Decide on the split between training and testing data from the DataFrame
trainingFraction = 0.7
testingFraction = (1-trainingFraction)
seed = 1234
# Split the DataFrame into test and training DataFrames
train_data_df, test_data_df = encoded_final_df.randomSplit([trainingFraction, testingFraction], seed=seed)
Ahora que hay dos marcos de datos, la siguiente tarea consiste en crear la fórmula del modelo y ejecutarla en el marco de datos de entrenamiento. Después, puede realizar la validación en la trama de datos de la prueba. Experimente con versiones diferentes de la fórmula del modelo para ver el impacto de las distintas combinaciones.
Nota:
Para guardar el modelo, asigne el rol de colaborador de datos de Storage Blob al ámbito del recurso de servidor de Azure SQL Database. Para obtener pasos detallados, consulte Asignación de roles de Azure mediante Azure Portal. Solo los miembros con el privilegio de propietario pueden realizar este paso.
## Create a new logistic regression object for the model
logReg = LogisticRegression(maxIter=10, regParam=0.3, labelCol = 'tipped')
## The formula for the model
classFormula = RFormula(formula="tipped ~ pickupHour + weekdayVec + passengerCount + tripTimeSecs + tripDistance + fareAmount + paymentType+ trafficTimeBinsVec")
## Undertake training and create a logistic regression model
lrModel = Pipeline(stages=[classFormula, logReg]).fit(train_data_df)
## Saving the model is optional, but it's another form of inter-session cache
datestamp = datetime.now().strftime('%m-%d-%Y-%s')
fileName = "lrModel_" + datestamp
logRegDirfilename = fileName
lrModel.save(logRegDirfilename)
## Predict tip 1/0 (yes/no) on the test dataset; evaluation using area under ROC
predictions = lrModel.transform(test_data_df)
predictionAndLabels = predictions.select("label","prediction").rdd
metrics = BinaryClassificationMetrics(predictionAndLabels)
print("Area under ROC = %s" % metrics.areaUnderROC)
La salida de esta celda es:
Area under ROC = 0.9779470729751403
Creación de una representación visual de la predicción
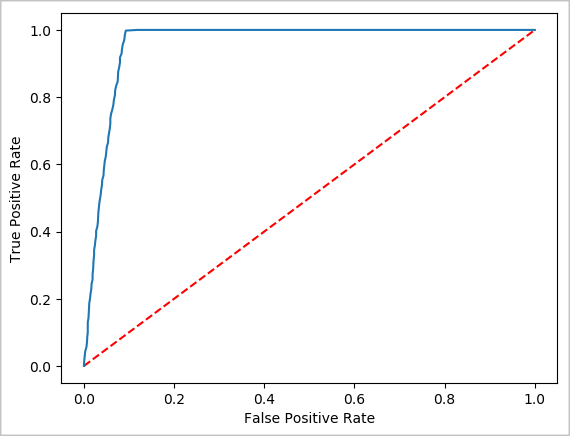
Ahora se puede crear una visualización final para facilitar el análisis de los resultados de esta prueba. Una curva ROC es una manera de revisar el resultado.
## Plot the ROC curve; no need for pandas, because this uses the modelSummary object
modelSummary = lrModel.stages[-1].summary
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(modelSummary.roc.select('FPR').collect(),
modelSummary.roc.select('TPR').collect())
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
Apagado de la instancia de Spark
Después de finalizar la ejecución de la aplicación, cierre el cuaderno para liberar los recursos cerrando la pestaña. O bien, seleccione Finalizar sesión en el panel de estado en la parte inferior del cuaderno.