Hoja de referencia rápida de un grupo de SQL dedicado (anteriormente SQL DW) en Azure Synapse Analytics
En esta hoja de referencia, se proporcionan sugerencias útiles y procedimientos recomendados para la creación de soluciones de un grupo de SQL dedicado (anteriormente SQL DW).
En el gráfico siguiente se muestra el proceso de diseño de un almacenamiento de datos con un grupo de SQL dedicado (anteriormente SQL DW):
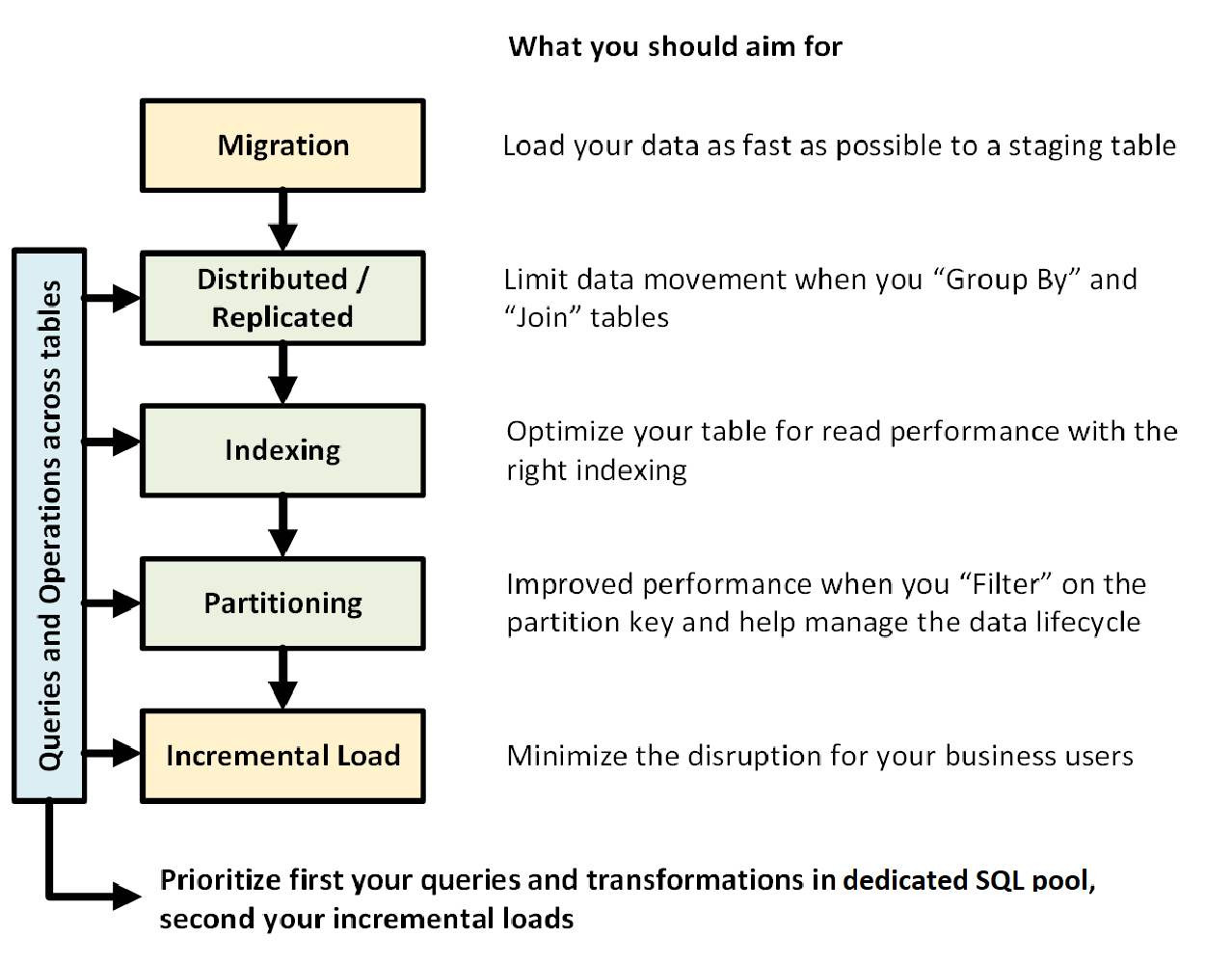
Consultas y operaciones entre tablas
Si se sabe de antemano las operaciones y las consultas principales que se van a ejecutar en el almacenamiento de datos, se puede dar prioridad a esas operaciones en la arquitectura de almacenamiento de datos. En estas consultas y operaciones se podría incluir:
- Combinar una o dos tablas de hechos con tablas de dimensiones, filtrar la tabla combinada y, luego, anexar los resultados a un data mart.
- Realizar actualizaciones grandes o pequeñas en las ventas de hechos.
- Anexar solo datos a las tablas.
Conocer los tipos de operaciones de antemano ayuda a optimizar el diseño de las tablas.
Migración de datos
Primero, cargue los datos en Azure Data Lake Storage o Azure Blob Storage. A continuación, use la instrucción COPY para cargar los datos en tablas de almacenamiento provisional. Use la configuración siguiente:
| Diseño | Recomendación |
|---|---|
| Distribución | Round Robin |
| Indización | Montón |
| Creación de particiones | None |
| Clase de recurso | largerc o xlargerc |
Obtenga más información sobre la migración de datos, la carga de datos y el proceso de extracción, carga y transformación (ETL).
Tablas replicadas o distribuidas
Use las siguientes estrategias, en función de las propiedades de tabla:
| Tipo | Muy adecuado para... | Esté atento a... |
|---|---|---|
| Replicado | * Tablas de pequeñas dimensiones en esquema de estrella con menos de 2 GB de almacenamiento tras la compresión (compresión ~5x) | * Se producen muchas transacciones de escritura en la tabla (por ejemplo, insertar, actualizar/insertar (upsert), eliminar, actualizar) * Cambia frecuentemente el aprovisionamiento de las unidades de almacenamiento de datos (DWU) * Solo usa 2 o 3 columnas, pero la tabla tiene muchas columnas * Va a indexar una tabla replicada |
| Round Robin (valor predeterminado) | * Tabla de almacenamiento provisional/temporal * Sin clave de combinación obvia o columna candidata correcta |
* El rendimiento es lento debido al movimiento de datos |
| Hash | * Tablas de hechos * Tablas de dimensiones grandes |
* La clave de distribución no se puede actualizar |
Sugerencias:
- Empiece con Round Robin, pero con miras a una estrategia de distribución hash para aprovechar la arquitectura masiva en paralelo.
- Asegúrese de que las claves hash comunes tengan el mismo formato de datos.
- No distribuya en formato varchar.
- Las tablas de dimensiones con una clave hash común para una tabla de hechos con operaciones frecuentes de combinación se pueden distribuir mediante hash.
- Use sys.dm_pdw_nodes_db_partition_stats para analizar los posibles sesgos en los datos.
- Use sys.dm_pdw_request_steps para analizar el movimiento de datos detrás de las consultas y supervisar lo que tardan las operaciones de difusión y orden aleatorio. Resulta útil para revisar la estrategia de distribución.
Aprenda más sobre las tablas replicadas y las tablas distribuidas.
Indexación de la tabla
La indexación es útil para leer rápidamente las tablas. Existe un conjunto único de tecnologías que puede usar en función de sus necesidades:
| Tipo | Muy adecuado para... | Esté atento a... |
|---|---|---|
| Montón | * Tabla de almacenamiento provisional/temporal * Tablas pequeñas con búsquedas pequeñas |
* Cualquier búsqueda recorre la tabla completa |
| Índice agrupado | * Tablas con hasta 100 millones de filas * Tablas grandes (más de 100 millones de filas) con solo 1 o 2 columnas muy usadas |
* Se usa en una tabla replicada * Tiene consultas complejas que implican varias operaciones de combinación y Agrupar por * Realiza actualizaciones en las columnas indexadas, lo que consume memoria |
| Índice de almacén de columnas agrupado (CCI) (predeterminado) | * Tablas grandes (más de 100 millones de filas) | * Se usa en una tabla replicada * Realiza operaciones masivas de actualización en la tabla * Crea demasiadas particiones de la tabla: los grupos de filas no se distribuyen entre diferentes particiones y nodos de distribución |
Sugerencias:
- A partir de un índice agrupado, puede que quiera agregar un índice no agrupado a una columna que se usa mucho como filtro.
- Tenga cuidado con cómo administra la memoria en una tabla con CCI. Al cargar los datos, querrá que el usuario (o la consulta) se beneficie de una clase de recursos grande. Asegúrese de evitar recortes y la creación de muchos grupos de filas comprimidos pequeños.
- En Gen2, las tablas de CCI se almacenan en caché de manera local en los nodos de proceso con el fin de maximizar el rendimiento.
- En CCI, puede producirse un rendimiento lento debido a la compresión deficiente de los grupos de filas. Si ocurre esto, recompile o reorganice el CCI. Es aconsejable tener al menos 100 000 filas por grupos de filas comprimidos. Lo más conveniente es 1 millón de filas en un grupo de filas.
- Según la frecuencia y el tamaño de la carga incremental, querrá automatizar la reorganización o recompilación de los índices. Hacer limpieza primaveral siempre es útil.
- Cree una estrategia cuando desee recortar un grupo de filas. ¿Qué tamaño tienen los grupos de filas abiertos? ¿cuántos datos espera cargar los próximos días?
Aprenda más sobre los índices.
Creación de particiones
Cuando tenga tablas de hechos de gran tamaño (más de 1000 millones de filas), puede particionarlas. En el 99 % de los casos, la clave de partición debe basarse en la fecha.
Con tablas de almacenamiento provisional que requieren ELT, puede beneficiarse de la creación de particiones, ya que facilita la administración del ciclo de vida de los datos. Tenga cuidado de no crear particiones en exceso de la tabla de hecho o de almacenamiento provisional, en especial en un índice de almacén de columnas agrupado.
Aprenda más sobre las particiones.
Carga incremental
Si se va a cargar los datos incrementalmente, primero asegúrese de que asigna clases de recursos mayores para la carga de los datos. Esto es especialmente importante al cargar en tablas con índices de almacén de columnas en clúster. Consulte Clases de recursos para más información.
Se recomienda usar PolyBase y ADF V2 para la automatización de las canalizaciones ELT en el almacenamiento de datos.
En el caso de un lote grande de actualizaciones en los datos históricos, considere la posibilidad de utilizar CTAS para escribir los datos que desea conservar en una tabla en lugar de usar INSERT, UPDATE y DELETE.
Mantenimiento de estadísticas
Es importante actualizar las estadísticas cuando se produzcan cambios significativos en los datos. Consulte Actualizar estadísticas para determinar si se han producido cambios significativos. Las estadísticas actualizadas optimizan los planes de consulta. Si observa que el mantenimiento de todas las estadísticas tarda demasiado, sea más selectivo sobre qué columnas tienen estadísticas.
También puede definir la frecuencia de las actualizaciones. Por ejemplo, puede actualizar las columnas de fecha, donde se pueden añadir valores nuevos todos los días. Se beneficiará enormemente de tener estadísticas sobre las columnas que intervienen en combinaciones, las columnas que se usan en la cláusula WHERE y las columnas que se encuentran en GROUP BY.
Aprenda más sobre las estadísticas.
clase de recursos
Los grupos de recursos se utilizan como para asignar memoria a las consultas. Si necesita más memoria para mejorar la velocidad de las consultas o de la carga, debe asignar clases de recursos superiores. Por otro lado, el uso de clases de recursos más grandes afecta a la simultaneidad. Esto lo deberá tener en cuenta antes de mover todos los usuarios a una clase de recursos grande.
Si observa que las consultas tardan demasiado tiempo, compruebe que los usuarios no se ejecutan en clases de recursos grandes. Las clases de recursos grande consumen mucho espacio de simultaneidad y pueden enviar a otras consultas a la cola.
Por último, si se usa la segunda generación del grupo de SQL dedicado (anteriormente SQL DW), cada clase de recurso obtiene 2,5 veces más memoria que en el caso de la primera generación.
Aprenda más sobre cómo trabajar con clases de recursos y simultaneidad.
Reducción de los costos
Una de las características principales de Azure Synapse es la posibilidad de administrar los recursos de proceso. Si un grupo de SQL dedicado (anteriormente SQL DW) no se usa, se puede poner en pausa, lo que interrumpe la facturación de los recursos de proceso. Puede escalar los recursos para satisfacer la demanda de rendimiento. Para realizar una pausa, use Azure Portal o PowerShell. Para realizar el escalado, use Azure Portal, PowerShell, T-SQL o una API REST.
Realice el escalado automático ahora, en el momento que quiera con Azure Functions:

Optimización de la arquitectura para aumentar el rendimiento
Se recomienda considerar la posibilidad de una arquitectura hub-and-spoke (concentrador y radio) con SQL Database y Azure Analysis Services. Esta solución puede proporcionar el aislamiento de la carga de trabajo entre diferentes grupos de usuarios, al tiempo que se aprovechan algunas características de seguridad avanzadas de SQL Database y Azure Analysis Services. También es una manera de proporcionar simultaneidad ilimitada a los usuarios.
Más información sobre las arquitecturas típicas que utilizan un grupo de SQL dedicado (anteriormente SQL DW) en Azure Synapse Analytics.
Implemente con un clic sus radios en bases de datos SQL desde un grupo de SQL dedicado (anteriormente SQL DW):