Guía de diseño de tablas distribuidas mediante un grupo de SQL dedicado en Azure Synapse Analytics
Este artículo contiene recomendaciones para diseñar tablas distribuidas por hash y por round robin en grupos de SQL dedicados.
En este artículo se da por supuesto que está familiarizado con los conceptos de distribución y movimiento de datos en un grupo de SQL dedicado. Para obtener más información, vea Arquitectura de Azure Synapse Analytics.
¿Qué es una tabla distribuida?
Una tabla distribuida aparece como una sola tabla pero las filas se almacenan realmente en 60 distribuciones. Las filas se distribuyen con un algoritmo hash o round robin.
La distribución por hash mejora el rendimiento de las consultas en tablas de hechos de gran tamaño y sobre ellas trata este artículo. La distribución por round robin es útil para mejorar la velocidad de carga. Estas opciones de diseño mejoran de manera significativa el rendimiento de las consultas y de la carga.
Otra opción de almacenamiento de tabla es replicar una tabla pequeña en todos los nodos de proceso. Para más información, consulte Instrucciones de diseño para el uso de tablas replicadas en Azure SQL Data Warehouse. Para elegir rápidamente entre las tres opciones, consulte Tablas distribuidas en Información general de Tablas.
Como parte del diseño de tablas, comprenda tanto como sea posible sobre los datos y cómo se consultan los datos. Por ejemplo, considere estas preguntas:
- ¿Qué tamaño tiene la tabla?
- ¿Con qué frecuencia se actualiza la tabla?
- ¿Se tienen tablas de hechos y de dimensiones en un de grupo de SQL dedicado?
Distribución por hash
Una tabla distribuida por hash distribuye filas de tabla entre todos los nodos de proceso mediante una función hash determinista para asignar cada fila a una distribución.
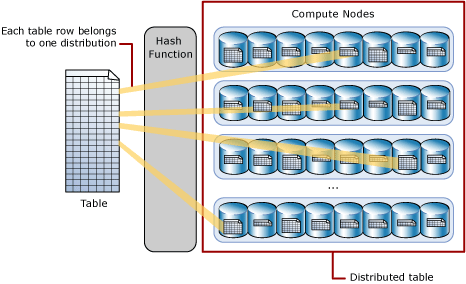
Como los valores idénticos siempre se distribuyen por hash a la misma distribución, SQL Analytics tiene conocimiento integrado de las ubicaciones de las filas. En un grupo de SQL dedicado, este conocimiento se usa para minimizar el movimiento de datos durante las consultas, lo que mejora el rendimiento de estas.
Las tablas distribuidas por hash funcionan bien para las tablas de hechos de gran tamaño en un esquema de estrella. Pueden tener un gran número de filas y lograr aún así un alto rendimiento. Hay algunas consideraciones de diseño que le ayudarán a obtener el rendimiento que el sistema distribuido está diseñado para proporcionar. La elección de una o varias columnas de distribución óptimas es una consideración de este tipo que se describe en este artículo.
Tenga en cuenta la posibilidad de usar una tabla distribuida por hash cuando:
- El tamaño de la tabla en el disco es superior a 2 GB.
- La tabla tiene operaciones frecuentes de inserción, actualización y eliminación.
Distribución round robin
Una tabla distribuida round robin distribuye las filas de la tabla uniformemente entre todas las distribuciones. La asignación de filas para las distribuciones es aleatoria. A diferencia de las tablas distribuidas por hash, no se garantiza que las filas con los mismos valores se asignen a la misma distribución.
Como consecuencia, el sistema a veces necesita invocar una operación de movimiento de datos para organizar mejor los datos antes de que pueda resolver una consulta. Este paso adicional puede ralentizar las consultas. Por ejemplo, la combinación de una tabla round robin suele requerir reconstruir las filas, lo que supone una disminución del rendimiento.
Considere la opción de usar la distribución round robin para la tabla en los siguientes casos:
- Cuando se empieza como un punto de partida sencillo, ya que es la opción predeterminada.
- Si no hay ninguna clave de combinación obvia.
- Si no hay ninguna columna que sea buena candidata para la distribución de la tabla por hash.
- Si la tabla no comparte una clave de combinación común con otras tablas.
- Si la combinación es menos importante que otras combinaciones de la consulta.
- Cuando la tabla es una tabla de almacenamiento provisional
El tutorial Load New York taxicab data (Carga de datos de taxis de Nueva York) proporciona un ejemplo de carga de datos en una tabla de almacenamiento provisional round robin.
Elección de una columna de distribución
Una tabla distribuida por hash tiene una columna o un conjunto de columnas de distribución que son la clave hash. Por ejemplo, el código siguiente crea una tabla distribuida por hash con ProductKey como columna de distribución.
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey])
);
La distribución hash se puede aplicar en varias columnas para una distribución más uniforme de la tabla base. La distribución de varias columnas le permite elegir hasta ocho columnas para la distribución. Esto no solo reduce la asimetría de datos a lo largo del tiempo, sino que también mejora el rendimiento de las consultas. Por ejemplo:
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey], [OrderDateKey], [CustomerKey] , [PromotionKey])
);
Nota
La distribución de varias columnas en Azure Synapse Analytics se puede habilitar cambiando el nivel de compatibilidad de la base de datos a 50 con este comando.
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; Para obtener más información sobre cómo establecer el nivel de compatibilidad de la base de datos, consulte ALTER DATABASE SCOPED CONFIGURATION. Para obtener más información sobre las distribuciones de varias columnas, consulte CREATE MATERIALIZED VIEW, CREATE TABLE o CREATE TABLE AS SELECT.
Los datos almacenados en las columnas de distribución se pueden actualizar. Las actualizaciones de los datos en columnas de distribución podrían dar lugar a la operación de orden aleatorio de los datos.
La elección de las columnas de distribución es una decisión de diseño importante, puesto que los valores de las columnas de hash determinan cómo se distribuyen las filas. La mejor opción depende de varios factores y, normalmente, supone tener que buscar un compromiso. Una vez que se ha elegido una o varias columnas de distribución, no se puede cambiar. Si no eligió las columnas más adecuadas la primera vez, puede usar CREATE TABLE AS SELECT (CTAS) para volver a crear la tabla con la clave de hash de distribución deseada.
Elección de una columna de distribución con datos que se distribuyen de manera uniforme
Para obtener el mejor rendimiento, todas las distribuciones deben tener aproximadamente el mismo número de filas. Cuando una o varias distribuciones tienen una cantidad desproporcionada de filas, algunas distribuciones finalizan su parte de una consulta en paralelo antes que otras. Como la consulta no se puede completar hasta que todas las distribuciones hayan terminado el procesamiento, la velocidad de cada consulta es igual de rápida que la de la distribución más lenta.
- La asimetría de los datos significa que los datos no se distribuyen de manera uniforme entre las distribuciones
- La asimetría de procesamiento significa que algunas distribuciones tardan más que otras al ejecutar consultas en paralelo. Esto puede ocurrir cuando los datos están sesgados.
Para equilibrar el procesamiento paralelo, seleccione una columna o un conjunto de columnas de distribución que:
- Tenga muchos valores únicos. Una o más columnas de distribución pueden tener valores duplicados. Todas las filas con el mismo valor se asignan a la misma distribución. Dado que hay 60 distribuciones, algunas distribuciones pueden tener > 1 valor único, mientras que otras pueden terminar con cero valores.
- No tenga valores NULL o solo tenga algunos valores NULL. Para ver un ejemplo extremo, si todos los valores de las columnas de distribución son NULL, todas las filas se asignan a la misma distribución. En consecuencia, el procesamiento de consultas está sesgado hacia una distribución y no se beneficia del procesamiento en paralelo.
- No sea una columna de fecha. Todos los datos de la misma fecha llegan a la misma distribución o agruparán los registros por fecha. Si varios usuarios están filtrando por la misma fecha (como, por ejemplo, la fecha de hoy), solo una de las sesenta distribuciones realiza todo el trabajo de procesamiento.
Elección de una columna de distribución que minimiza el movimiento de datos
Para obtener el resultado de la consulta correcto, las consultas pueden mover datos de un nodo de proceso a otro. El movimiento de datos suele ocurrir cuando las consultas tienen combinaciones y agregaciones en tablas distribuidas. La elección de una columna o un conjunto de columnas de distribución que ayuda a minimizar el movimiento de datos es una de las estrategias más importantes para optimizar el rendimiento del grupo de SQL dedicado.
Para minimizar el movimiento de datos, seleccione una columna o un conjunto de columnas de distribución que:
- Se utilice en las cláusulas
JOIN,GROUP BY,DISTINCT,OVERyHAVING. Cuando dos tablas de hechos de gran tamaño tienen combinaciones frecuentes, el rendimiento de las consultas mejora cuando distribuye ambas tablas en una de las columnas de combinación. Cuando una tabla no se utiliza en las combinaciones, considere la posibilidad de distribuir la tabla en una columna o un conjunto de columnas que se encuentre con frecuencia en la cláusulaGROUP BY. - No se utilice en las cláusulas
WHERE. Cuando la cláusula de una consultaWHEREy las columnas de distribución de la tabla se encuentran en la misma columna, la consulta podría encontrar una asimetría de datos alta, lo que provoca que la carga de procesamiento caiga en solo algunas distribuciones. Esto afecta al rendimiento de las consultas, idealmente muchas distribuciones comparten la carga de procesamiento. - No sea una columna de fecha. A menudo, las cláusulas
WHEREse filtran por fecha. Cuando esto sucede, todo el procesamiento podría ejecutarse solo en unas pocas distribuciones, lo que afectaría el rendimiento de las consultas. Idealmente, muchas distribuciones comparten la carga de procesamiento.
Una vez diseñada una tabla distribuida por hash, el paso siguiente es cargar datos en la tabla. Para instrucciones sobre la carga, consulte Información general de Carga.
Cómo saber si la distribución es una buena elección
Después de cargar datos en una tabla distribuida por hash, compruebe con qué uniformidad están distribuidas las filas entre las 60 distribuciones. Las filas por distribución pueden variar hasta un 10 % sin que esto afecte de forma perceptible al rendimiento.
Tenga en cuenta los sistemas siguientes para evaluar sus columnas de distribución.
Determinar si la tabla tiene asimetría de datos
Una forma rápida de comprobar la asimetría de datos consiste en usar DBCC PDW_SHOWSPACEUSED. El siguiente código SQL devuelve el número de filas de la tabla que están almacenadas en cada una de las 60 distribuciones. Para obtener el máximo rendimiento equilibrado, las filas de la tabla distribuida se deben repartir uniformemente entre todas las distribuciones.
-- Find data skew for a distributed table
DBCC PDW_SHOWSPACEUSED('dbo.FactInternetSales');
Para identificar las tablas que tienen más de un 10 % de asimetría de datos:
- Cree la vista
dbo.vTableSizesque se muestra en el artículo Información general de tablas. - Ejecute la siguiente consulta:
select *
from dbo.vTableSizes
where two_part_name in
(
select two_part_name
from dbo.vTableSizes
where row_count > 0
group by two_part_name
having (max(row_count * 1.000) - min(row_count * 1.000))/max(row_count * 1.000) >= .10
)
order by two_part_name, row_count;
Comprobación de los planes de consulta para el movimiento de datos
Un conjunto de columnas de distribución óptimo permite que las combinaciones y agregaciones tengan un movimiento de datos mínimo. Esto afecta a la manera en que se deben escribir las combinaciones. Para que el movimiento de datos sea mínimo para una combinación en dos tablas distribuidas por hash, una de las columnas de combinación debe estar en la columna o columnas de distribución. Cuando se combinan dos tablas distribuidas por hash en una columna de distribución del mismo tipo de datos, la combinación no requiere movimiento de datos. Las combinaciones pueden utilizar columnas adicionales sin incurrir en movimiento de datos.
Para evitar el movimiento de datos durante una combinación:
- Las tablas implicadas en la combinación deben distribuirse por hash en una de las columnas que participan en la combinación.
- Los tipos de datos de las columnas de combinación deben coincidir en ambas tablas.
- Las columnas deben combinarse con un operador equals.
- El tipo de combinación no puede ser
CROSS JOIN.
Para ver si las consultas están experimentando un movimiento de datos, puede ver el plan de consulta.
Resolución de un problema de la columna de distribución
No es necesario resolver todos los casos de asimetría de datos. Lo importante al distribuir datos es hallar el equilibrio perfecto entre minimizar la asimetría de datos y reducir el movimiento de datos. No siempre es posible minimizar la asimetría de datos y el movimiento de datos. A veces la ventaja que reporta reducir el movimiento de datos al mínimo podría compensar el efecto de tener asimetría de datos.
Para decidir si merece la pena resolver la asimetría de datos en una tabla, conviene tener el mayor conocimiento posible sobre los volúmenes de datos y consultas en la carga de trabajo. Puede usar los pasos descritos en el artículo Supervisión de consultas para supervisar el efecto de la asimetría en el rendimiento de las consultas. En concreto, busque el tiempo que tardan en finalizar las consultas grandes en distribuciones individuales.
Como no se puede cambiar la columna de distribución de una tabla existente, la forma habitual de resolver la asimetría de datos es volver a crear la tabla con columnas de distribución diferentes.
Volver a crear la tabla con un conjunto de columnas de distribución nuevo
En este ejemplo se usa CREATE TABLE AS SELECT para volver a crear una tabla con columnas de distribución por hash diferente.
En primer lugar, use CREATE TABLE AS SELECT (CTAS) en la nueva tabla con la nueva clave. A continuación, vuelva a crear las estadísticas y, por último, intercambie las tablas modificando su nombre.
CREATE TABLE [dbo].[FactInternetSales_CustomerKey]
WITH ( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([CustomerKey])
, PARTITION ( [OrderDateKey] RANGE RIGHT FOR VALUES ( 20000101, 20010101, 20020101, 20030101
, 20040101, 20050101, 20060101, 20070101
, 20080101, 20090101, 20100101, 20110101
, 20120101, 20130101, 20140101, 20150101
, 20160101, 20170101, 20180101, 20190101
, 20200101, 20210101, 20220101, 20230101
, 20240101, 20250101, 20260101, 20270101
, 20280101, 20290101
)
)
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
OPTION (LABEL = 'CTAS : FactInternetSales_CustomerKey')
;
--Create statistics on new table
CREATE STATISTICS [ProductKey] ON [FactInternetSales_CustomerKey] ([ProductKey]);
CREATE STATISTICS [OrderDateKey] ON [FactInternetSales_CustomerKey] ([OrderDateKey]);
CREATE STATISTICS [CustomerKey] ON [FactInternetSales_CustomerKey] ([CustomerKey]);
CREATE STATISTICS [PromotionKey] ON [FactInternetSales_CustomerKey] ([PromotionKey]);
CREATE STATISTICS [SalesOrderNumber] ON [FactInternetSales_CustomerKey] ([SalesOrderNumber]);
CREATE STATISTICS [OrderQuantity] ON [FactInternetSales_CustomerKey] ([OrderQuantity]);
CREATE STATISTICS [UnitPrice] ON [FactInternetSales_CustomerKey] ([UnitPrice]);
CREATE STATISTICS [SalesAmount] ON [FactInternetSales_CustomerKey] ([SalesAmount]);
--Rename the tables
RENAME OBJECT [dbo].[FactInternetSales] TO [FactInternetSales_ProductKey];
RENAME OBJECT [dbo].[FactInternetSales_CustomerKey] TO [FactInternetSales];
Contenido relacionado
Para crear una tabla distribuida, use una de estas instrucciones: