Alta disponibilidad de SAP HANA en máquinas virtuales de Azure en SUSE Linux Enterprise Server
Para establecer una alta disponibilidad en una implementación de SAP HANA local, puede usar la replicación del sistema SAP HANA o el almacenamiento compartido.
En las máquinas virtuales (VM) de Azure, la replicación del sistema de SAP HANA en Azure es actualmente la única función admitida de alta disponibilidad.
La replicación del sistema SAP HANA se realiza con un nodo principal y al menos uno secundario. Los cambios en los datos del nodo principal se replican en los secundarios de forma sincrónica o asincrónica.
En este artículo se describe cómo implementar y configurar las máquinas virtuales, instalar la plataforma del clúster e instalar y configurar la replicación del sistema SAP HANA.
Antes de comenzar, consulte las siguientes notas y documentos de SAP:
- Nota de SAP 1928533. La nota incluye:
- La lista de tamaños de máquina virtual de Azure que se admiten para la implementación del software de SAP.
- Información importante sobre capacidad para los tamaños de máquina virtual de Azure.
- El software de SAP admitido y las combinaciones de sistema operativo y base de datos.
- Las versiones del kernel de SAP necesarias para Windows y Linux en Microsoft Azure.
- La nota de SAP 2015553 enumera los requisitos previos para las implementaciones de software de SAP admitidas por SAP en Azure.
- La nota de SAP 2205917 contiene configuraciones recomendadas del sistema operativo para SUSE Linux Enterprise Server 12 (SLES 12) para SAP Applications.
- La nota de SAP 2684254 contiene configuraciones recomendadas del sistema operativo para SUSE Linux Enterprise Server 15 (SLES 15) para SAP Applications.
- La nota de SAP 2235581 tiene sistemas operativos compatibles con SAP HANA
- La nota de SAP 2178632 contiene información detallada sobre todas las métricas de supervisión notificadas para SAP en Azure.
- La nota de SAP 2191498 incluye la versión del agente host de SAP necesaria para Linux en Azure.
- La nota de SAP 2243692 incluye información acerca de las licencias de SAP en Linux en Azure.
- La nota de SAP 1984787 incluye información general sobre SUSE Linux Enterprise Server 12.
- La nota de SAP 1999351 contiene más información de solución de problemas sobre la extensión de supervisión mejorada de Azure para SAP.
- La nota de SAP 401162 tiene información sobre cómo evitar errores de "dirección en uso" al configurar la replicación del sistema HANA.
- La Wiki de soporte de la comunidad SAP contiene todas las notas de SAP necesarias para Linux.
- Plataformas IaaS certificadas para SAP HANA.
- Guía Implementación y planeamiento de Azure Virtual Machines para SAP en Linux.
- Guía de Implementación de Azure Virtual Machines para SAP en Linux.
- Guía Implementación de DBMS de Azure Virtual Machines para SAP en Linux.
- Guías de procedimientos recomendados de SUSE Linux Enterprise Server para SAP Applications 15 y Guías de procedimientos recomendados de SUSE Linux Enterprise Server para SAP Applications 12:
- Configuración de una infraestructura optimizada para rendimiento de SR de SAP HANA (SLES para aplicaciones SAP). La guía contiene toda la información necesaria para configurar la replicación del sistema de SAP HANA para el desarrollo en el entorno local. Esta guía sirve como orientación.
- Configuración de una infraestructura optimizada para costo de SR de SAP HANA (SLES para SAP Applications).
Planear la alta disponibilidad de SAP HANA
Para lograr una alta disponibilidad, instale SAP HANA en dos máquinas virtuales. Los datos se replican mediante la replicación del sistema de HANA.
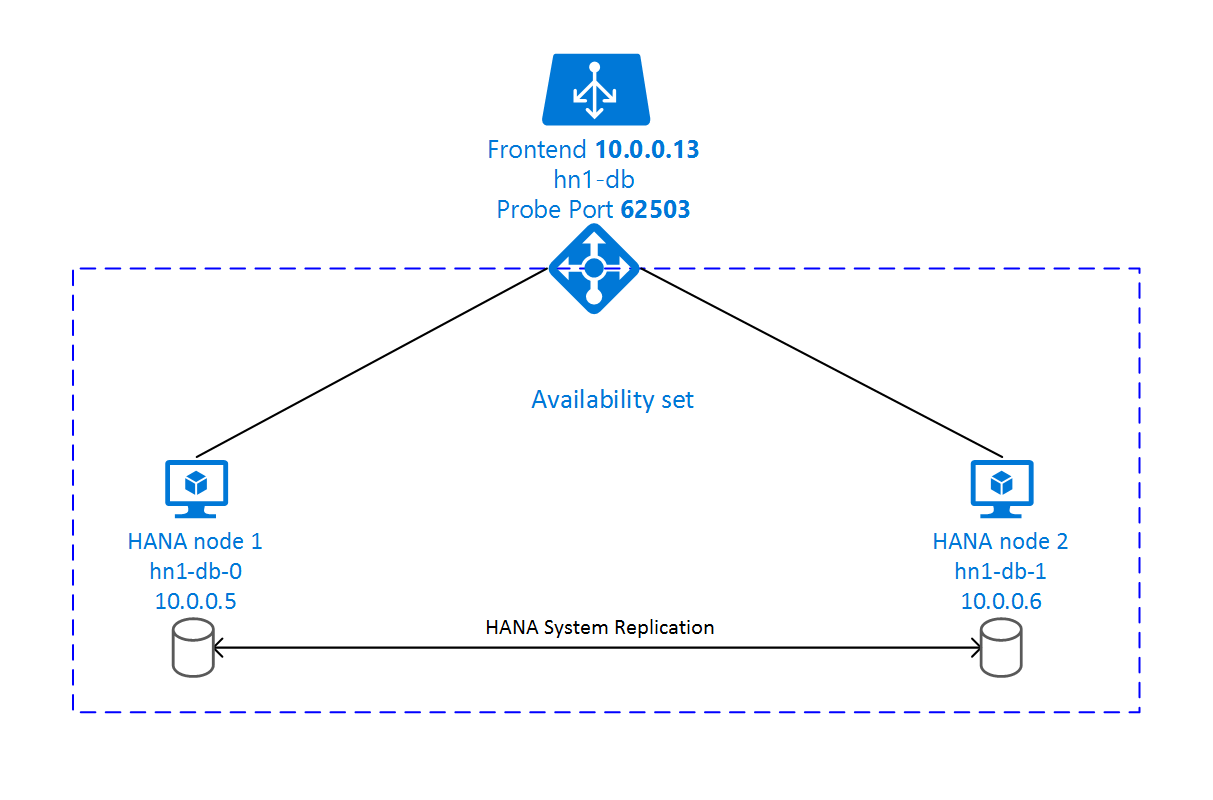
En la instalación de la replicación del sistema de SAP HANA se usa un nombre de host virtual dedicado y direcciones IP virtuales. En Azure, necesita un equilibrador de carga para implementar una dirección IP virtual.
En la ilustración anterior se muestra un equilibrador de carga de ejemplo que tiene estas configuraciones:
- Dirección IP de front-end: 10.0.0.13 para HN1-db
- Puerto de sondeo: 62503
Preparación de la infraestructura
El agente de recursos para SAP HANA se incluye en SUSE Linux Enterprise Server para SAP Applications. En Azure Marketplace se puede encontrar una imagen para SUSE Linux Enterprise Server para SAP Applications 12 o 15. Puede usar la imagen para implementar nuevas máquinas virtuales.
Implementación manual de VM de Linux mediante Azure Portal
Este documento asume que ya ha implementado un grupo de recursos, Azure Virtual Network y una subred.
Implemente máquinas virtuales para SAP HANA. Elija una imagen SLES adecuada compatible con el sistema HANA. Puede implementar la máquina virtual en cualquiera de las opciones de disponibilidad: conjunto de escalado de máquinas virtuales, zona de disponibilidad o conjunto de disponibilidad.
Importante
Asegúrese de que el sistema operativo que selecciona está certificado por SAP para SAP HANA en los tipos específicos de máquinas virtuales que tiene previsto usar en su implementación. Puede buscar los tipos de máquina virtual certificados por SAP HANA y sus versiones del sistema operativo en Plataformas IaaS certificadas para SAP HANA. Asegúrese de consultar los detalles del tipo de máquina virtual para obtener la lista completa de versiones de SO compatibles con SAP HANA para el tipo de máquina virtual específico.
Configurar Azure Load Balancer
Durante la configuración de la máquina virtual, tiene una opción para crear o seleccionar salir del equilibrador de carga en la sección de redes. Siga estos pasos para configurar el equilibrador de carga estándar para la configuración de alta disponibilidad de la base de datos de HANA.
Siga los pasos descritos en Creación de un equilibrador de carga para configurar un equilibrador de carga estándar para un sistema SAP de alta disponibilidad mediante Azure Portal. Durante la configuración del equilibrador de carga, tenga en cuenta los siguientes puntos:
- Configuración de IP de front-end: cree una dirección IP de front-end. Seleccione el mismo nombre de red virtual y subred que las máquinas virtuales de la base de datos.
- Grupo de back-end: cree un grupo de back-end y agregue máquinas virtuales de base de datos.
- Reglas de entrada: cree una regla de equilibrio de carga. Siga los mismos pasos para ambas reglas de equilibrio de carga.
- Dirección IP de front-end: seleccione una dirección IP de front-end.
- Grupo de back-end: seleccione un grupo de back-end.
- Puertos de alta disponibilidad: seleccione esta opción.
- Protocolo: seleccione TCP.
- Sondeo de estado: cree un sondeo de estado con los detalles siguientes:
- Protocolo: seleccione TCP.
- Puerto: por ejemplo, 625<instance-no.>.
- Intervalo: escriba 5.
- Umbral de sondeo: escriba 2.
- Tiempo de espera de inactividad (minutos): Escriba 30.
- Habilitar IP flotante: seleccione esta opción.
Nota:
No se respeta la propiedad de configuración del sondeo de estado numberOfProbes, también conocida como Umbral incorrecto en el portal. Para controlar el número de sondeos consecutivos correctos o erróneos, establezca la propiedad probeThreshold en 2. Actualmente, no es posible establecer esta propiedad mediante Azure Portal, por lo que debe usar la CLI de Azure o el comando de PowerShell.
Para obtener más información sobre los puertos necesarios para SAP HANA, lea el capítulo Connections to Tenant Databases (Conexiones a las bases de datos de inquilino) de la guía SAP HANA Tenant Databases (Bases de datos de inquilino de SAP HANA) o la nota de SAP 2388694.
Importante
No se admite una dirección IP flotante en una configuración de IP secundaria de tarjeta de interfaz de red (NIC) en escenarios de equilibrio de carga. Para ver detalles, consulte Limitaciones de Azure Load Balancer. Si necesita otra dirección IP para la VM, implemente una segunda NIC.
Nota:
Cuando las máquinas virtuales que no tienen direcciones IP públicas se colocan en el grupo de back-end de una instancia estándar interna (sin dirección IP pública) de Azure Load Balancer, la configuración predeterminada es sin conectividad saliente a Internet. Puede realizar pasos adicionales para permitir el enrutamiento a puntos de conexión públicos. Para obtener más información sobre cómo obtener conectividad saliente, vea Conectividad de punto de conexión público para máquinas virtuales con Azure Standard Load Balancer en escenarios de alta disponibilidad de SAP.
Importante
- No habilite las marcas de tiempo TCP en VM de Azure que se encuentren detrás de Azure Load Balancer. Si habilita las marcas de tiempo TCP provocará un error en los sondeos de estado. Establezca el parámetro
net.ipv4.tcp_timestampsen0. Para más información, consulte Sondeos de estado de Load Balancer y la nota de SAP 2382421. - Para evitar que saptune cambie el valor
net.ipv4.tcp_timestampsestablecido manualmente de0a nuevamente1, actualice la versión de saptune a la versión 3.1.1 o posterior. Para más información, consulte saptune 3.1.1: ¿Necesito actualizar?
Creación de un clúster de Pacemaker
Siga los pasos de Configuración de Pacemaker en SUSE Linux Enterprise Server en Azure para crear un clúster de Pacemaker básico para este servidor HANA. También puede usar el mismo clúster de Pacemaker con SAP HANA y SAP NetWeaver (A)SCS.
Instalación de SAP HANA
En los pasos de esta sección se usan los siguientes prefijos:
- [A] : el paso se aplica a todos los nodos.
- [1]: El paso solo se aplica al nodo 1.
- [2]: El paso solo se aplica al nodo 2 del clúster de Pacemaker.
Reemplace <placeholders> por los valores de la instalación de SAP HANA.
[A] Configuración del diseño del disco mediante el administrador de volúmenes lógicos (LVM).
Se recomienda usar LVM para volúmenes que almacenen datos y archivos de registro. En el ejemplo siguiente se supone que las máquinas virtuales tienen cuatro discos de datos conectados que se usan para crear dos volúmenes.
Ejecute este comando para enumerar todos los discos disponibles:
/dev/disk/azure/scsi1/lun*Ejemplo:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3Cree volúmenes físicos para todos los discos que quiera usar:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3Cree un grupo de volúmenes para los archivos de datos. Use un grupo de volúmenes para los archivos de registro y otro para el directorio compartido de SAP HANA:
sudo vgcreate vg_hana_data_<HANA SID> /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_<HANA SID> /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_<HANA SID> /dev/disk/azure/scsi1/lun3Cree los volúmenes lógicos.
Cuando se usa
lvcreatesin el modificador-i, se crea un volumen lineal. Se recomienda crear un volumen seccionado para mejorar el rendimiento de E/S. Alinee los tamaños de franja con los valores documentados en las configuraciones de almacenamiento de máquinas virtuales de SAP HANA. El argumento-idebe ser el número de volúmenes físicos subyacentes y-I, el tamaño de la franja.Por ejemplo, si se usan dos volúmenes físicos para el volumen de datos, el argumento switch de
-ise establece en 2 y el tamaño de franja del volumen de datos es 256KiB. Se usa un volumen físico para el volumen de registro, así que no se usa explícitamente ningún modificador-io-Ipara los comandos del volumen de registro.Importante
Use el modificador
-iy establézcalo en el número del volumen físico subyacente cuando se usa más de un volumen físico para cada volumen de datos, de registro o compartido. Al crear un volumen seccionado, use el modificador-Ipara especificar el tamaño de franja.Consulte Configuraciones de almacenamiento de máquinas virtuales de Azure en SAP HANA para conocer las configuraciones de almacenamiento recomendadas, incluidos los tamaños de sección y el número de discos.
sudo lvcreate <-i number of physical volumes> <-I stripe size for the data volume> -l 100%FREE -n hana_data vg_hana_data_<HANA SID> sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_<HANA SID> sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_<HANA SID> sudo mkfs.xfs /dev/vg_hana_data_<HANA SID>/hana_data sudo mkfs.xfs /dev/vg_hana_log_<HANA SID>/hana_log sudo mkfs.xfs /dev/vg_hana_shared_<HANA SID>/hana_sharedCree los directorios de montaje y copie el identificador único universal (UUID) de todos los volúmenes lógicos:
sudo mkdir -p /hana/data/<HANA SID> sudo mkdir -p /hana/log/<HANA SID> sudo mkdir -p /hana/shared/<HANA SID> # Write down the ID of /dev/vg_hana_data_<HANA SID>/hana_data, /dev/vg_hana_log_<HANA SID>/hana_log, and /dev/vg_hana_shared_<HANA SID>/hana_shared sudo blkidEdite el archivo /etc/fstab para crear entradas
fstabpara los tres volúmenes lógicos:sudo vi /etc/fstabInserte las líneas siguientes en el archivo /etc/fstab:
/dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_data_<HANA SID>-hana_data> /hana/data/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_log_<HANA SID>-hana_log> /hana/log/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_shared_<HANA SID>-hana_shared> /hana/shared/<HANA SID> xfs defaults,nofail 0 2Monte los nuevos volúmenes:
sudo mount -a
[A] Configure el diseño del disco mediante discos sin formato.
Para sistemas demostración, puede colocar los archivos de datos y de registro HANA en un disco.
Cree una partición en /dev/disk/azure/scsi1/lun0 y aplíquele formato con XFS:
sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun0' sudo mkfs.xfs /dev/disk/azure/scsi1/lun0-part1 # Write down the ID of /dev/disk/azure/scsi1/lun0-part1 sudo /sbin/blkid sudo vi /etc/fstabInserte esta línea en el archivo /etc/fstab:
/dev/disk/by-uuid/<UUID> /hana xfs defaults,nofail 0 2Cree el directorio de destino y monte el disco:
sudo mkdir /hana sudo mount -a
[A] Configuración de la resolución del nombre de todos los hosts.
Puede usar un servidor DNS o modificar el archivo /etc/hosts en todos los nodos. En este ejemplo se muestra cómo usar el archivo /etc/hosts. Reemplace las direcciones IP y los nombres de host en los siguientes comandos.
Compruebe el archivo /etc/hosts:
sudo vi /etc/hostsInserte las líneas siguientes en el archivo /etc/hosts. Cambie la dirección IP y el nombre de host para que coincidan con su entorno.
10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] Instalación de los paquetes de alta disponibilidad de SAP HANA:
Ejecute el siguiente comando para instalar los paquetes de alta disponibilidad:
sudo zypper install SAPHanaSR
Para instalar la replicación del sistema de SAP HANA, siga el capítulo 4 de la Guía del escenario optimizado para el rendimiento de SR de SAP HANA.
[A] Ejecute el programa hdblcm desde el medio de instalación de HANA.
Se le pedirá que escriba los siguientes valores:
- Elija la instalación: Especifique 1.
- Seleccione los componentes adicionales para la instalación: Especifique 1.
- Escriba la ruta de instalación: escriba /hana/shared y presione Entrar.
- Escriba el nombre de host local: escriba .. y presione Entrar.
- ¿Desea agregar hosts adicionales al sistema? (y/n): escriba n y presione Entrar.
- Escriba el id. del sistema de SAP HANA: escriba el SID de HANA.
- Número de instancia: escriba el número de instancia de HANA. Si ha implementado mediante la plantilla de Azure o si ha seguido la sección de implementación manual de este artículo, escriba 03.
- Seleccione el modo de base de datos / Escriba el índice: escriba o seleccione 1 y presione Entrar.
- Seleccione el uso del sistema / Escriba el índice: seleccione el valor de uso del sistema 4.
- Escriba la ubicación de los volúmenes de datos: escriba /hana/data/<HANA SID> y presione Entrar.
- Escriba la ubicación de los volúmenes de registro: escriba /hana/log/<HANA SID> y presione Entrar.
- ¿Restringir la asignación máxima de memoria?: escriba n y presione Entrar.
- Escriba el nombre de host del certificado para el host: Escriba ... y presione Entrar.
- Escriba la contraseña de usuario del agente host de SAP (sapadm): escriba la contraseña de usuario del agente host y, a continuación, presione Entrar.
- Confirme la contraseña de usuario del agente host de SAP (sapadm): vuelva a escribir la contraseña de usuario del agente host y, a continuación, presione Entrar.
- Escriba la contraseña del administrador del sistema (hdbadm): escriba la contraseña del administrador del sistema y, a continuación, presione Entrar.
- Confirmar la contraseña de administrador del sistema (hdbadm): vuelva a escribir la contraseña de administrador del sistema para confirmarla, presione Entrar.
- Escriba el directorio principal del administrador del sistema: escriba /usr/sap/<HANA SID>/home y presione Entrar.
- Escriba el shell de inicio de sesión del administrador del sistema: escriba /bin/sh y presione Entrar.
- Escriba el id. de usuario del administrador del sistema: escriba 1001 y presione Entrar.
- Escriba el identificador del grupo de usuarios (sapsys): escriba 79 y presione Entrar.
- Escriba la contraseña de usuario de base de datos (SYSTEM): escriba la contraseña de usuario de la base de datos y, a continuación, presione Entrar.
- Confirme la contraseña del usuario de la base de datos (SYSTEM): vuelva a escribir la contraseña de usuario de la base de datos y, a continuación, presione Entrar.
- ¿Reiniciar el sistema tras el reinicio de la máquina? (y/n): escriba n y presione Entrar.
- ¿Desea continuar? (s/n): valide el resumen. Escriba s para continuar.
[A] Actualización del agente host de SAP.
Descargue el archivo del agente host de SAP más reciente desde el Centro de software de SAP. Para actualizar al agente, ejecute el siguiente comando. Reemplace la ruta de acceso al archivo para que apunte al archivo que descargó.
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP host agent SAR>
Configuración de la Replicación del sistema de SAP HANA 2.0
En los pasos de esta sección se usan los siguientes prefijos:
- [A] : el paso se aplica a todos los nodos.
- [1]: El paso solo se aplica al nodo 1.
- [2]: El paso solo se aplica al nodo 2 del clúster de Pacemaker.
Reemplace <placeholders> por los valores de la instalación de SAP HANA.
[1] Creación de la base de datos de inquilino.
Si usa SAP HANA 2.0 o MDC, cree una base de datos de inquilino para el sistema SAP NetWeaver.
Ejecute el siguiente comando como adm de <HANA SID>:
hdbsql -u SYSTEM -p "<password>" -i <instance number> -d SYSTEMDB 'CREATE DATABASE <SAP SID> SYSTEM USER PASSWORD "<password>"'[1] Configuración de la replicación del sistema en el primer nodo:
En primer lugar, realice una copia de seguridad de las bases de datos como adm de <HANA SID>:
hdbsql -d SYSTEMDB -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SYS>')" hdbsql -d <HANA SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for HANA SID>')" hdbsql -d <SAP SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SAP SID>')"A continuación, copie los archivos de infraestructura de clave pública (PKI) del sistema en el sitio secundario:
scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/SSFS_<HANA SID>.DAT hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/ scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/SSFS_<HANA SID>.KEY hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/Cree el sitio principal:
hdbnsutil -sr_enable --name=<site 1>[2] Configuración de la replicación del sistema en el segundo nodo:
Registre el segundo nodo para iniciar la replicación del sistema.
Ejecute el siguiente comando como adm de <HANA SID>:
sapcontrol -nr <instance number> -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2>
Configuración de la replicación del sistema de SAP HANA 1.0
En los pasos de esta sección se usan los siguientes prefijos:
- [A] : el paso se aplica a todos los nodos.
- [1]: El paso solo se aplica al nodo 1.
- [2]: El paso solo se aplica al nodo 2 del clúster de Pacemaker.
Reemplace <placeholders> por los valores de la instalación de SAP HANA.
[1] Creación de los usuarios necesarios.
Ejecute el siguiente comando como raíz:
PATH="$PATH:/usr/sap/<HANA SID>/HDB<instance number>/exe" hdbsql -u system -i <instance number> 'CREATE USER hdbhasync PASSWORD "<password>"' hdbsql -u system -i <instance number> 'GRANT DATA ADMIN TO hdbhasync' hdbsql -u system -i <instance number> 'ALTER USER hdbhasync DISABLE PASSWORD LIFETIME'[A] Creación de la entrada del almacén de claves.
Ejecute el siguiente comando como raíz para crear una entrada del almacén de claves:
PATH="$PATH:/usr/sap/<HANA SID>/HDB<instance number>/exe" hdbuserstore SET hdbhaloc localhost:3<instance number>15 hdbhasync <password>[1] Realización de una copia de seguridad de la base de datos.
Haga una copia de seguridad de las bases de datos como raíz:
PATH="$PATH:/usr/sap/<HANA SID>/HDB<instance number>/exe" hdbsql -d SYSTEMDB -u system -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file>')"Si usa una instalación multiinquilino, haga también una copia de seguridad de la base de datos de inquilino:
hdbsql -d <HANA SID> -u system -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file>')"[1] Configuración de la replicación del sistema en el primer nodo.
Cree el sitio principal como adm de <HANA SID>:
su - hdbadm hdbnsutil -sr_enable --name=<site 1>[2] Configuración de la replicación del sistema en el nodo secundario.
Registre el sitio secundario como adm de <HANA SID>:
sapcontrol -nr <instance number> -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=<HANA SID>-db-<database 1> --remoteInstance=<instance number> --replicationMode=sync --name=<site 2>
Implementación de los enlaces de HANA SAPHanaSR y susChkSrv
Este paso es importante para optimizar la integración con el clúster y mejorar la detección cuando se requiere una conmutación por error del clúster. Se recomienda encarecidamente configurar el enlace de Python de SAPHanaSR. Para HANA 2.0 SP5 y versiones posteriores, se recomienda implementar el enlace SAPHanaSR y el enlace susChkSrv.
SusChkSrv amplía la funcionalidad del proveedor de alta disponibilidad SAPHanaSR principal. Actúa cuando el proceso de HANA hdbindexserver se bloquea. Si un único proceso se bloquea, normalmente HANA intenta reiniciarlo. El reinicio del proceso de indexserver puede tardar mucho tiempo, durante el cual la base de datos de HANA no responde.
Con susChkSrv implementado, se ejecuta una acción inmediata y configurable. La acción desencadena una conmutación por error en el período de tiempo de espera configurado en lugar de esperar a que el proceso de hdbindexserver se reinicie en el mismo nodo.
[A] Instale el "enlace de replicación del sistema" de HANA. El enlace debe instalarse en ambos nodos de base de datos de HANA.
Sugerencia
El enlace de Python SAPHanaSR solo se puede implementar para HANA 2.0. El paquete SAPHanaSR debe ser al menos la versión 0.153.
El enlace de Python susChkSrv requiere la instalación de la versión de SAP HANA 2.0 SP5 y SAPHanaSR 0.161.1_BF o superior.
Detenga HANA en ambos nodos.
Ejecute el código siguiente como adm de <SAP SID>:
sapcontrol -nr <instance number> -function StopSystemAjuste global.ini en cada nodo de clúster. Si no se cumplen los requisitos del enlace susChkSrv, quite todo el bloque
[ha_dr_provider_suschksrv]de los parámetros siguientes.Puede ajustar el comportamiento de
susChkSrvmediante el parámetroaction_on_lost. Los valores válidos son [ignore|stop|kill|fence].# add to global.ini [ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR execution_order = 3 action_on_lost = fence [trace] ha_dr_saphanasr = infoSi apunta a la ubicación estándar /usr/share/SAPHanaSR, el código de enlace de Python se actualiza automáticamente a través de actualizaciones del sistema operativo o actualizaciones de paquetes. HANA usa las actualizaciones de código de enlace cuando se reinicie la próxima vez. Con una ruta de acceso opcional propia, como /hana/shared/myHooks, puede desacoplar las actualizaciones del sistema operativo de la versión de enlace usada.
[A] El clúster requiere la configuración de elementos que usan el programa sudo en cada nodo de clúster para el adm de <SAP SID>. En este ejemplo, esto se consigue mediante la creación de un archivo nuevo.
Ejecute el siguiente comando como raíz:
cat << EOF > /etc/sudoers.d/20-saphana # Needed for SAPHanaSR and susChkSrv Python hooks hn1adm ALL=(ALL) NOPASSWD: /usr/sbin/crm_attribute -n hana_hn1_site_srHook_* hn1adm ALL=(ALL) NOPASSWD: /usr/sbin/SAPHanaSR-hookHelper --sid=HN1 --case=fenceMe EOFPara más información sobre cómo implementar el enlace de replicación del sistema de SAP HANA, consulte Configuración de proveedores de alta disponibilidad y recuperación ante desastres de HANA.
[A] Inicie SAP HANA en ambos nodos.
Ejecute el siguiente comando como adm de <SAP SID>:
sapcontrol -nr <instance number> -function StartSystem[1] Compruebe la instalación del enlace.
Ejecute el siguiente comando como adm de <SAP SID> en el sitio de replicación del sistema de HANA activo:
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example output # 2021-04-08 22:18:15.877583 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:18:46.531564 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:21:26.816573 ha_dr_SAPHanaSR SOKCompruebe la instalación del enlace susChkSrv.
Ejecute el siguiente comando como adm de <SAP SID> en todas las máquinas virtuales de HANA:
cdtrace egrep '(LOST:|STOP:|START:|DOWN:|init|load|fail)' nameserver_suschksrv.trc # Example output # 2022-11-03 18:06:21.116728 susChkSrv.init() version 0.7.7, parameter info: action_on_lost=fence stop_timeout=20 kill_signal=9 # 2022-11-03 18:06:27.613588 START: indexserver event looks like graceful tenant start # 2022-11-03 18:07:56.143766 START: indexserver event looks like graceful tenant start (indexserver started)
Creación de recursos de clúster de SAP HANA
Primero, cree la topología de HANA.
Ejecute los comandos siguientes en uno de los nodos del clúster de Pacemaker:
sudo crm configure property maintenance-mode=true
# Replace <placeholders> with your instance number and HANA system ID
sudo crm configure primitive rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> ocf:suse:SAPHanaTopology \
operations \$id="rsc_sap2_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10" timeout="600" \
op start interval="0" timeout="600" \
op stop interval="0" timeout="300" \
params SID="<HANA SID>" InstanceNumber="<instance number>"
sudo crm configure clone cln_SAPHanaTopology_<HANA SID>_HDB<instance number> rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> \
meta clone-node-max="1" target-role="Started" interleave="true"
A continuación, cree los recursos de HANA:
Importante
En las pruebas recientes, netcat deja de responder a las solicitudes debido a un trabajo pendiente y debido a su limitación de controlar solo una conexión. El recurso netcat deja de escuchar las solicitudes de Azure Load Balancer y la dirección IP flotante deja de estar disponible.
En el caso de los clústeres de Pacemaker existentes, anteriormente recomendábamos reemplazar netcat por socat. Actualmente, se recomienda usar el agente de recursos azure-lb, que forma parte de un paquete de resource-agents. Se requieren las siguientes versiones de paquete:
- En el caso de SLES 12 SP4/SP5, la versión debe ser, al menos, resource-agents-4.3.018.a7fb5035-3.30.1.
- Para SLES 15/15 SP1, la versión debe ser al menos resource-agents-4.3.0184.6ee15eb2-4.13.1.
Realizar este cambio requiere un breve tiempo de inactividad.
En el caso de los clústeres de Pacemaker existentes, si la configuración ya se cambió para usar socat como se describe en Protección de la detección de Azure Load Balancer, no es necesario cambiar inmediatamente al agente de recursos azure-lb.
Nota:
Este artículo contiene referencias a términos que Microsoft ya no utiliza. Cuando se eliminen estos términos del software, se eliminarán de este artículo.
# Replace <placeholders> with your instance number, HANA system ID, and the front-end IP address of the Azure load balancer.
sudo crm configure primitive rsc_SAPHana_<HANA SID>_HDB<instance number> ocf:suse:SAPHana \
operations \$id="rsc_sap_<HANA SID>_HDB<instance number>-operations" \
op start interval="0" timeout="3600" \
op stop interval="0" timeout="3600" \
op promote interval="0" timeout="3600" \
op monitor interval="60" role="Master" timeout="700" \
op monitor interval="61" role="Slave" timeout="700" \
params SID="<HANA SID>" InstanceNumber="<instance number>" PREFER_SITE_TAKEOVER="true" \
DUPLICATE_PRIMARY_TIMEOUT="7200" AUTOMATED_REGISTER="false"
sudo crm configure ms msl_SAPHana_<HANA SID>_HDB<instance number> rsc_SAPHana_<HANA SID>_HDB<instance number> \
meta notify="true" clone-max="2" clone-node-max="1" \
target-role="Started" interleave="true"
sudo crm resource meta msl_SAPHana_<HANA SID>_HDB<instance number> set priority 100
sudo crm configure primitive rsc_ip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_ip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<front-end IP address>"
sudo crm configure primitive rsc_nc_<HANA SID>_HDB<instance number> azure-lb port=625<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
sudo crm configure group g_ip_<HANA SID>_HDB<instance number> rsc_ip_<HANA SID>_HDB<instance number> rsc_nc_<HANA SID>_HDB<instance number>
sudo crm configure colocation col_saphana_ip_<HANA SID>_HDB<instance number> 4000: g_ip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Master
sudo crm configure order ord_SAPHana_<HANA SID>_HDB<instance number> Optional: cln_SAPHanaTopology_<HANA SID>_HDB<instance number> \
msl_SAPHana_<HANA SID>_HDB<instance number>
# Clean up the HANA resources. The HANA resources might have failed because of a known issue.
sudo crm resource cleanup rsc_SAPHana_<HANA SID>_HDB<instance number>
sudo crm configure property priority-fencing-delay=30
sudo crm configure property maintenance-mode=false
sudo crm configure rsc_defaults resource-stickiness=1000
sudo crm configure rsc_defaults migration-threshold=5000
Importante
Se recomienda establecer AUTOMATED_REGISTER en false solo mientras se completan las pruebas de conmutación por error exhaustivas para evitar que una instancia principal con errores se registre automáticamente como secundaria. Cuando las pruebas de conmutación por error se completen correctamente, establezca AUTOMATED_REGISTER en true, de modo que después de la adquisición, la replicación del sistema se reanude automáticamente.
Asegúrese de que el estado del clúster sea OK y que todos los recursos se hayan iniciado. No importa en qué nodo se ejecutan los recursos.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
Configuración de la replicación del sistema de HANA activo/habilitado para lectura en el clúster de Pacemaker
En SAP HANA 2.0 SPS 01 y versiones posteriores, SAP permite una configuración activa o habilitada para lectura para la replicación del sistema SAP HANA. En este escenario, los sistemas secundarios de replicación del sistema SAP HANA se pueden usar activamente para cargas de trabajo de lectura intensiva.
Para admitir esta configuración en un clúster, se requiere una segunda dirección IP virtual que permita a los clientes tener acceso a la base de datos secundaria de SAP HANA habilitada para lectura. Para garantizar que todavía se puede tener acceso al sitio de replicación secundario tras una adquisición, el clúster debe mover la dirección IP virtual con el sistema secundario del recurso SAPHana.
En esta sección se describen los pasos adicionales necesarios para administrar la replicación del sistema de HANA activo/habilitado para lectura en un clúster de alta disponibilidad de SUSE con una segunda dirección IP virtual.
Antes de continuar, asegúrese de que ha configurado completamente el clúster de alta disponibilidad de SUSE que administra la base de datos de SAP HANA como se describe en las secciones anteriores.
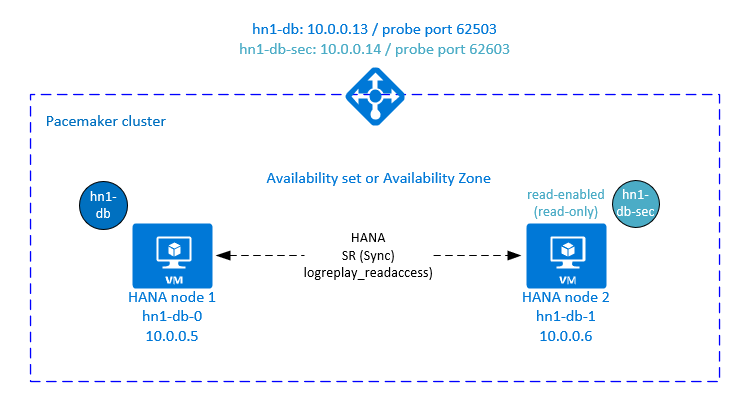
Configuración del equilibrador de carga para la replicación del sistema activa o habilitada para lectura
Para continuar con pasos adicionales para aprovisionar la segunda dirección IP virtual, asegúrese de configurar Azure Load Balancer como se describe en Implementación manual de máquinas virtuales Linux mediante Azure Portal.
Para el equilibrador de carga estándar, complete estos pasos adicionales en el mismo equilibrador de carga que creó anteriormente.
- Crear un segundo grupo de direcciones IP de front-end:
- Abra el equilibrador de carga, seleccione frontend IP pool (Grupo de direcciones IP de front-end) y haga clic en Agregar.
- Escriba el nombre del segundo grupo de direcciones IP de front-end (por ejemplo, hana-secondaryIP).
- Establezca Assignment (Asignación) en Static (Estática) y escriba la dirección IP (por ejemplo, 10.0.0.14).
- Seleccione Aceptar.
- Una vez creado el nuevo grupo de direcciones IP de front-end, anote la dirección IP del front-end.
- Cree un sondeo de estado:
- Abra el equilibrador de carga, seleccione Sondeos de estado y haga clic en Agregar.
- Escriba el nombre del sondeo de estado nuevo (por ejemplo hana-secondaryhp).
- Seleccione TCP como el protocolo y el >número de instancia del puerto 626<. Mantenga el valor de Intervalo en 5 y el valor de Umbral incorrecto en 2.
- Seleccione Aceptar.
- Cree las reglas de equilibrio de carga:
- Abra el equilibrador de carga, seleccione Reglas de equilibrio de carga y haga clic en Agregar.
- Escriba el nombre de la nueva regla del equilibrador de carga (por ejemplo, hana-secondarylb).
- Seleccione la dirección IP de front-end, el grupo de back-end y el sondeo de estado que creó anteriormente (por ejemplo, hana-secondaryIP, hana-backend y hana-secondaryhp).
- Seleccione Puertos HA.
- Aumente el tiempo de espera de inactividad a 30 minutos.
- Asegúrese de habilitar la dirección IP flotante.
- Seleccione Aceptar.
Configuración de la replicación del sistema de HANA activo/habilitado para lectura
Los pasos para configurar la replicación del sistema de HANA se describen en la sección Configuración de la replicación del sistema de SAP HANA 2.0. Si va a implementar un escenario secundario habilitado para lectura, al configurar la replicación del sistema en el segundo nodo, ejecute el siguiente comando como adm de <HANA SID>:
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> --operationMode=logreplay_readaccess
Agregar un recurso de dirección IP virtual secundaria
Puede configurar la segunda dirección IP virtual y la restricción de coubicación adecuada mediante los siguientes comandos:
crm configure property maintenance-mode=true
crm configure primitive rsc_secip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_secip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<secondary IP address>"
crm configure primitive rsc_secnc_<HANA SID>_HDB<instance number> azure-lb port=626<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
crm configure group g_secip_<HANA SID>_HDB<instance number> rsc_secip_<HANA SID>_HDB<instance number> rsc_secnc_<HANA SID>_HDB<instance number>
crm configure colocation col_saphana_secip_<HANA SID>_HDB<instance number> 4000: g_secip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Slave
crm configure property maintenance-mode=false
Asegúrese de que el estado del clúster sea OK y que todos los recursos se hayan iniciado. La segunda dirección IP virtual se ejecutará en el sitio secundario junto con el recurso secundario SAPHana.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# Resource Group: g_secip_HN1_HDB03:
# rsc_secip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
# rsc_secnc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
En la sección siguiente se describe el conjunto típico de pruebas de conmutación por error que se van a ejecutar.
Consideraciones al probar un clúster de HANA configurado con una secundaria habilitada para lectura:
Al migrar el recurso del clúster
SAPHana_<HANA SID>_HDB<instance number>ahn1-db-1, la segunda dirección IP virtual se mueve ahn1-db-0. Si ha configuradoAUTOMATED_REGISTER="false"y la replicación del sistema HANA no se registra automáticamente, la segunda dirección IP virtual se ejecuta enhn1-db-0porque el servidor está disponible y los servicios de clúster están en línea.Al probar el bloqueo del servidor, los recursos de la segunda IP virtual (
rsc_secip_<HANA SID>_HDB<instance number>) y el recurso de puerto de Azure Load Balancer (rsc_secnc_<HANA SID>_HDB<instance number>) se ejecutarán en el servidor principal junto con los recursos de la IP virtual principal. Mientras el servidor secundario está inactivo, las aplicaciones que están conectadas a la base de datos de HANA habilitada para lectura se conectarán a la base de datos de HANA principal. El comportamiento es el esperado, ya que no desea que las aplicaciones que están conectadas a la base de datos de HANA habilitada para lectura sean inaccesibles mientras el servidor secundario no esté disponible.Cuando el servidor secundario esté disponible y los servicios de clúster estén en línea, la segunda dirección IP virtual y los recursos de puerto se trasladarán automáticamente al servidor secundario, incluso si la replicación del sistema de HANA no se registra como secundaria. Es muy importante registrar la base de datos secundaria de HANA como habilitada para lectura antes de iniciar los servicios de clúster en ese servidor. Puede configurar el recurso de clúster de instancia de HANA para registrar automáticamente la replicación secundaria estableciendo el parámetro
AUTOMATED_REGISTER="true".Durante la conmutación por error y por reserva, se pueden interrumpir las conexiones existentes de las aplicaciones mediante la conexión de la segunda dirección IP virtual a la base de datos de HANA.
Prueba de la configuración del clúster
En esta sección se describe cómo se puede probar la configuración. Cada prueba supone que ha iniciado sesión como raíz y que el maestro de SAP HANA se ejecuta en la máquina virtual hn1-db-0.
Prueba de la migración
Antes de comenzar la prueba, asegúrese de que Pacemaker no tenga acciones con error (ejecute crm_mon -r), no haya restricciones de ubicación inesperadas (por ejemplo, restos de una prueba de migración) y de que HANA se encuentre en estado de sincronización, por ejemplo ejecutando SAPHanaSR-showAttr.
hn1-db-0:~ # SAPHanaSR-showAttr
Sites srHook
----------------
SITE2 SOK
Global cib-time
--------------------------------
global Mon Aug 13 11:26:04 2018
Hosts clone_state lpa_hn1_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
hn1-db-0 PROMOTED 1534159564 online logreplay nws-hana-vm-1 4:P:master1:master:worker:master 150 SITE1 sync PRIM 2.00.030.00.1522209842 nws-hana-vm-0
hn1-db-1 DEMOTED 30 online logreplay nws-hana-vm-0 4:S:master1:master:worker:master 100 SITE2 sync SOK 2.00.030.00.1522209842 nws-hana-vm-1
Puede migrar el nodo maestro de SAP HANA con el siguiente comando:
crm resource move msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1 force
El clúster migraría el nodo maestro de SAP HANA y el grupo que contiene la dirección IP virtual a hn1-db-1.
Cuando finalice la migración, la salida crm_mon -r tendrá el siguiente aspecto:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Failed Actions:
* rsc_SAPHana_HN1_HDB03_start_0 on hn1-db-0 'not running' (7): call=84, status=complete, exitreason='none',
last-rc-change='Mon Aug 13 11:31:37 2018', queued=0ms, exec=2095ms
Con AUTOMATED_REGISTER="false", el clúster no reiniciaría la base de datos de HANA con errores ni la registraría en la nueva base de datos principal en hn1-db-0. En este caso, configure la instancia de HANA como secundaria mediante la ejecución de este comando:
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> sapcontrol -nr <instance number> -function StopWait 600 10
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
La migración crea restricciones de ubicación que deben eliminarse de nuevo:
# Switch back to root and clean up the failed state
exit
hn1-db-0:~ # crm resource clear msl_SAPHana_<HANA SID>_HDB<instance number>
También debe limpiar el estado del recurso de nodo secundario:
hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
Supervise el estado del recurso de HANA mediante crm_mon -r. Cuando se inicia HANA en hn1-db-0, la salida tiene el siguiente aspecto:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Bloqueo de la comunicación de red
Estado del recurso antes de iniciar la prueba:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Ejecute la regla de firewall para bloquear la comunicación en uno de los nodos.
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
Cuando los nodos del clúster no se pueden comunicar entre sí, existe el riesgo de un escenario de cerebro dividido. En tales situaciones, los nodos de clúster intentarán cercarse simultáneamente, lo que da lugar a una carrera de barreras.
Al configurar un dispositivo de barrera, se recomienda configurar la propiedad pcmk_delay_max. Por lo tanto, en caso de escenario de cerebro dividido, el clúster introduce un retraso aleatorio hasta el valor pcmk_delay_max, a la acción de barrera en cada nodo. El nodo con el retraso más corto se seleccionará para la barrera.
Además, para asegurarse de que el nodo que ejecuta el maestro de HANA tiene prioridad y gana la carrera de barreras en un escenario de cerebro dividido, se recomienda establecer la propiedad priority-fencing-delay en la configuración del clúster. Al habilitar la propiedad priority-fencing-delay, el clúster puede introducir un retraso adicional en la acción de barrera específicamente en el nodo que hospeda el recurso maestro de HANA, lo que permite al nodo ganar la carrera de barreras.
Ejecute el comando siguiente para eliminar la regla de firewall.
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
Prueba de delimitación de SBD
Para probar la configuración de SBD, termine el proceso inquisidor:
hn1-db-0:~ # ps aux | grep sbd
root 1912 0.0 0.0 85420 11740 ? SL 12:25 0:00 sbd: inquisitor
root 1929 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014056f268462316e4681b704a9f73 - slot: 0 - uuid: 7b862dba-e7f7-4800-92ed-f76a4e3978c8
root 1930 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014059bc9ea4e4bac4b18808299aaf - slot: 0 - uuid: 5813ee04-b75c-482e-805e-3b1e22ba16cd
root 1931 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-36001405b8dddd44eb3647908def6621c - slot: 0 - uuid: 986ed8f8-947d-4396-8aec-b933b75e904c
root 1932 0.0 0.0 90524 16656 ? SL 12:25 0:00 sbd: watcher: Pacemaker
root 1933 0.0 0.0 102708 28260 ? SL 12:25 0:00 sbd: watcher: Cluster
root 13877 0.0 0.0 9292 1572 pts/0 S+ 12:27 0:00 grep sbd
hn1-db-0:~ # kill -9 1912
El nodo de clúster <HANA SID>-db-<database 1> se reinicia. Es posible que el servicio Pacemaker no se reinicie. Asegúrese de empezar de nuevo.
Prueba de una conmutación por error manual
Para probar una conmutación por error manual, detenga el servicio de Pacemaker en el nodo hn1-db-0:
service pacemaker stop
Después de la conmutación por error, puede reiniciar el servicio. Si establece AUTOMATED_REGISTER="false", el recurso de SAP HANA en el nodo hn1-db-0 no se podrá iniciar como secundario.
En este caso, configure la instancia de HANA como secundaria mediante la ejecución de este comando:
service pacemaker start
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
# Switch back to root and clean up the failed state
exit
crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
Pruebas de SUSE
Importante
Asegúrese de que el sistema operativo seleccionado está certificado por SAP para SAP HANA en los tipos específicos de máquina virtual que planea usar. Puede buscar los tipos de máquina virtual certificados por SAP HANA y sus versiones del sistema operativo en Plataformas IaaS certificadas para SAP HANA. Asegúrese de consultar los detalles del tipo de máquina virtual para obtener la lista completa de versiones de SO compatibles con SAP HANA para el tipo de máquina virtual específico.
Ejecute todos los casos de prueba que se indican en la guía del escenario optimizado para el rendimiento de SR de SAP HANA o la guía de escenarios optimizados para costo de SR de SAP HANA, en función de su caso de uso. Puede encontrar las guías enumeradas en SLES para procedimientos recomendados de SAP.
Las siguientes pruebas son una copia de las descripciones de pruebas de la guía del escenario optimizado para el rendimiento de SR de SAP HANA de SUSE Linux Enterprise Server para SAP Applications 12 SP1. Para obtener una versión actualizada, lea siempre también la propia guía. Antes de iniciar la prueba, asegúrese de que HANA esté sincronizado y de que la configuración de Pacemaker sea correcta.
En las siguientes descripciones de prueba, se supone PREFER_SITE_TAKEOVER="true" y AUTOMATED_REGISTER="false".
Nota:
Las siguientes pruebas están diseñadas para ejecutarse en secuencia. Cada prueba depende del estado de salida de la prueba anterior.
Prueba 1: Detener la base de datos principal en el nodo 1.
Estado del recurso antes de iniciar la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Ejecute los siguientes comandos como adm de <HANA SID> en el nodo
hn1-db-0:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB stopPacemaker detecta la instancia de HANA detenida y conmuta por error al otro nodo. Cuando finaliza la conmutación por error, se detiene la instancia de HANA en el nodo
hn1-db-0porque Pacemaker no registra automáticamente el nodo como secundario de HANA.Ejecute los siguientes comandos para registrar el nodo
hn1-db-0como secundario y limpiar el recurso con error:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Estado del recurso después de la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Prueba 2: Detener la base de datos principal en el nodo 2.
Estado del recurso antes de iniciar la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Ejecute los siguientes comandos como adm de <HANA SID> en el nodo
hn1-db-1:hn1adm@hn1-db-1:/usr/sap/HN1/HDB01> HDB stopPacemaker detecta la instancia de HANA detenida y conmuta por error al otro nodo. Cuando finaliza la conmutación por error, se detiene la instancia de HANA en el nodo
hn1-db-1porque Pacemaker no registra automáticamente el nodo como secundario de HANA.Ejecute los siguientes comandos para registrar el nodo
hn1-db-1como secundario y limpiar el recurso con error:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Estado del recurso después de la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Prueba 3: Bloquear la base de datos principal en el nodo 1.
Estado del recurso antes de iniciar la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Ejecute los siguientes comandos como adm de <HANA SID> en el nodo
hn1-db-0:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker detecta la instancia de HANA eliminada y conmuta por error al otro nodo. Cuando finaliza la conmutación por error, se detiene la instancia de HANA en el nodo
hn1-db-0porque Pacemaker no registra automáticamente el nodo como secundario de HANA.Ejecute los siguientes comandos para registrar el nodo
hn1-db-0como secundario y limpiar el recurso con error:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Estado del recurso después de la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Prueba 4: Bloquear la base de datos principal en el nodo 2.
Estado del recurso antes de iniciar la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Ejecute los siguientes comandos como adm de <HANA SID> en el nodo
hn1-db-1:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker detecta la instancia de HANA eliminada y conmuta por error al otro nodo. Cuando finaliza la conmutación por error, se detiene la instancia de HANA en el nodo
hn1-db-1porque Pacemaker no registra automáticamente el nodo como secundario de HANA.Ejecute los siguientes comandos para registrar el nodo
hn1-db-1como secundario y limpiar el recurso con error.hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Estado del recurso después de la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Prueba 5: Bloquear el nodo del sitio primario (nodo 1).
Estado del recurso antes de iniciar la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Ejecute los siguientes comandos como raíz en el nodo
hn1-db-0:hn1-db-0:~ # echo 'b' > /proc/sysrq-triggerPacemaker detecta el nodo de clúster eliminado y lo cerca. Una vez que el nodo está delimitado, Pacemaker desencadenará una adquisición de la instancia de HANA. Cuando se reinicia el nodo delimitado, Pacemaker no se inicia automáticamente.
Ejecute los siguientes comandos para iniciar Pacemaker, limpiar los mensajes SBD del nodo
hn1-db-0, registrar el nodohn1-db-0como secundario y limpiar el recurso con errores:# run as root # list the SBD device(s) hn1-db-0:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-0:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-0 clear hn1-db-0:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Estado del recurso después de la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Prueba 6: Bloquear el nodo del sitio secundario (nodo 2).
Estado del recurso antes de iniciar la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Ejecute los siguientes comandos como raíz en el nodo
hn1-db-1:hn1-db-1:~ # echo 'b' > /proc/sysrq-triggerPacemaker detecta el nodo de clúster eliminado y lo cerca. Una vez que el nodo está delimitado, Pacemaker desencadenará una adquisición de la instancia de HANA. Cuando se reinicia el nodo delimitado, Pacemaker no se inicia automáticamente.
Ejecute los siguientes comandos para iniciar Pacemaker, limpiar los mensajes SBD del nodo
hn1-db-1, registrar el nodohn1-db-1como secundario y limpiar el recurso con errores:# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Estado del recurso después de la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0 </code></pre>Prueba 7: Detenga la base de datos secundaria en el nodo 2.
Estado del recurso antes de iniciar la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Ejecute los siguientes comandos como adm de <HANA SID> en el nodo
hn1-db-1:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB stopPacemaker detecta la instancia de HANA detenida y marca el recurso como erróneo en el nodo
hn1-db-1. Pacemaker reinicia automáticamente la instancia de HANA.Ejecute el siguiente comando para limpiar el estado de error:
# run as root hn1-db-1>:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Estado del recurso después de la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Prueba 8: Bloquear la base de datos secundaria en el nodo 2.
Estado del recurso antes de iniciar la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Ejecute los siguientes comandos como adm de <HANA SID> en el nodo
hn1-db-1:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker detecta la instancia de HANA eliminada y marca el recurso como erróneo en el nodo
hn1-db-1. Ejecute el siguiente comando para limpiar el estado de error. Pacemaker reinicia automáticamente la instancia de HANA.# run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> HN1-db-1Estado del recurso después de la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Prueba 9: Bloquear el nodo de sitio secundario (nodo 2) que ejecuta la base de datos secundaria de HANA.
Estado del recurso antes de iniciar la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Ejecute los siguientes comandos como raíz en el nodo
hn1-db-1:hn1-db-1:~ # echo b > /proc/sysrq-triggerPacemaker detecta el nodo de clúster eliminado y ha cercado el nodo. Cuando se reinicia el nodo delimitado, Pacemaker no se inicia automáticamente.
Ejecute los siguientes comandos para iniciar Pacemaker, limpiar los mensajes de SBD del nodo
hn1-db-1y limpiar el recurso con error:# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Estado del recurso después de la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Prueba 10: Bloquear el servidor de índices de la base de datos principal
Esta prueba solo es relevante cuando haya configurado el enlace susChkSrv como se describe en Implementación de enlaces de HANA SAPHanaSR y susChkSrv.
Estado del recurso antes de iniciar la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Ejecute los siguientes comandos como raíz en el nodo
hn1-db-0:hn1-db-0:~ # killall -9 hdbindexserverCuando el indexserver finaliza, el enlace susChkSrv detecta el evento y desencadena una acción para cercar el nodo "hn1-db-0" e iniciar el proceso de adquisición.
Ejecute los siguientes comandos para registrar el nodo
hn1-db-0como secundario y limpiar el recurso con error:# run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Estado del recurso después de la prueba:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Puede ejecutar un caso de prueba comparable haciendo que el indexserver del nodo secundario se bloquee. En caso de bloqueo de indexserver, el enlace susChkSrv reconocerá la aparición e iniciará una acción para cercar el nodo secundario.