Alta disponibilidad del sistema de escalabilidad horizontal de SAP HANA en Red Hat Enterprise Linux
En este artículo se describe cómo implementar un sistema SAP HANA de alta disponibilidad en una configuración de escalabilidad horizontal. En concreto, la configuración usa la replicación del sistema HANA (HSR) y Pacemaker en máquinas virtuales (VM) Red Hat Enterprise Linux de Azure. Los sistemas de archivos compartidos de la arquitectura presentada se montan en NFS y los proporciona Azure NetApp Files o recurso compartido NFS en Azure Files.
En las configuraciones de ejemplo, como en los comandos de instalación, la instancia de HANA es 03 y el identificador del sistema HANA es HN1.
Requisitos previos
Algunos lectores se beneficiarán de consultar una variedad de notas y recursos de SAP antes de continuar con los temas de este artículo:
- Nota de SAP 1928533, que incluye:
- Una lista de los tamaños de máquina virtual de Azure que se admiten para la implementación de software de SAP.
- Información importante sobre capacidad para los tamaños de máquina virtual de Azure.
- Software de SAP admitido y combinaciones de sistema operativo y base de datos.
- La versión del kernel de SAP necesaria para Windows y Linux en Microsoft Azure.
- La nota de SAP 2015553 enumera los requisitos previos para las implementaciones de software de SAP admitidas por SAP en Azure.
- Nota de SAP [2002167]: se ha recomendado la configuración del sistema operativo para RHEL.
- Nota de SAP 2009879: tiene directrices de SAP HANA para RHEL.
- La nota de SAP 3108302 contiene las instrucciones de SAP HANA para Red Hat Enterprise Linux 9.x.
- Nota de SAP 2178632: contiene información detallada sobre todas las métricas de supervisión notificadas para SAP en Azure.
- Nota de SAP 2191498: incluye la versión de agente de host de SAP necesaria para Linux en Azure.
- Nota de SAP 2243692: contiene información sobre las licencias de SAP en Linux en Azure.
- Nota de SAP 1999351: contiene información adicional sobre la solución de problemas de la extensión de supervisión mejorada de Azure para SAP.
- Nota de SAP 1900823: incluye información sobre los requisitos de almacenamiento de SAP HANA.
- La wiki de la comunidad SAP contiene todas las notas de SAP que se necesitan para Linux.
- Planeación e implementación de Azure Virtual Machines para SAP en Linux.
- Implementación de Azure Virtual Machines para SAP en Linux.
- Implementación de DBMS de Azure Virtual Machines para SAP en Linux.
- Requisitos de red de SAP HANA.
- Documentación general de RHEL:
- Introducción al complemento de alta disponibilidad.
- Administración del complemento de alta disponibilidad.
- Referencia del complemento de alta disponibilidad.
- Guía de redes de Red Hat Enterprise Linux.
- Configuración de la replicación del sistema de escalabilidad horizontal de SAP HANA en un clúster de Pacemaker con sistemas de archivos HANA en recursos compartidos NFS.
- Activo/activo (habilitado para lectura): Escalabilidad horizontal y replicación del sistema de la solución de alta disponibilidad de RHEL para SAP HANA.
- Documentación de RHEL específica para Azure:
- Documentación sobre Azure NetApp Files.
- Volúmenes NFS v4.1 en Azure NetApp Files para SAP HANA.
- Documentación de Azure Files
Información general
Para lograr la alta disponibilidad de HANA para las instalaciones de escalabilidad horizontal de HANA, puede configurar la replicación del sistema HANA y proteger la solución con un clúster de Pacemaker para permitir la conmutación por error automática. Cuando se produce un error en un nodo activo, el clúster conmuta por error los recursos de HANA al otro sitio.
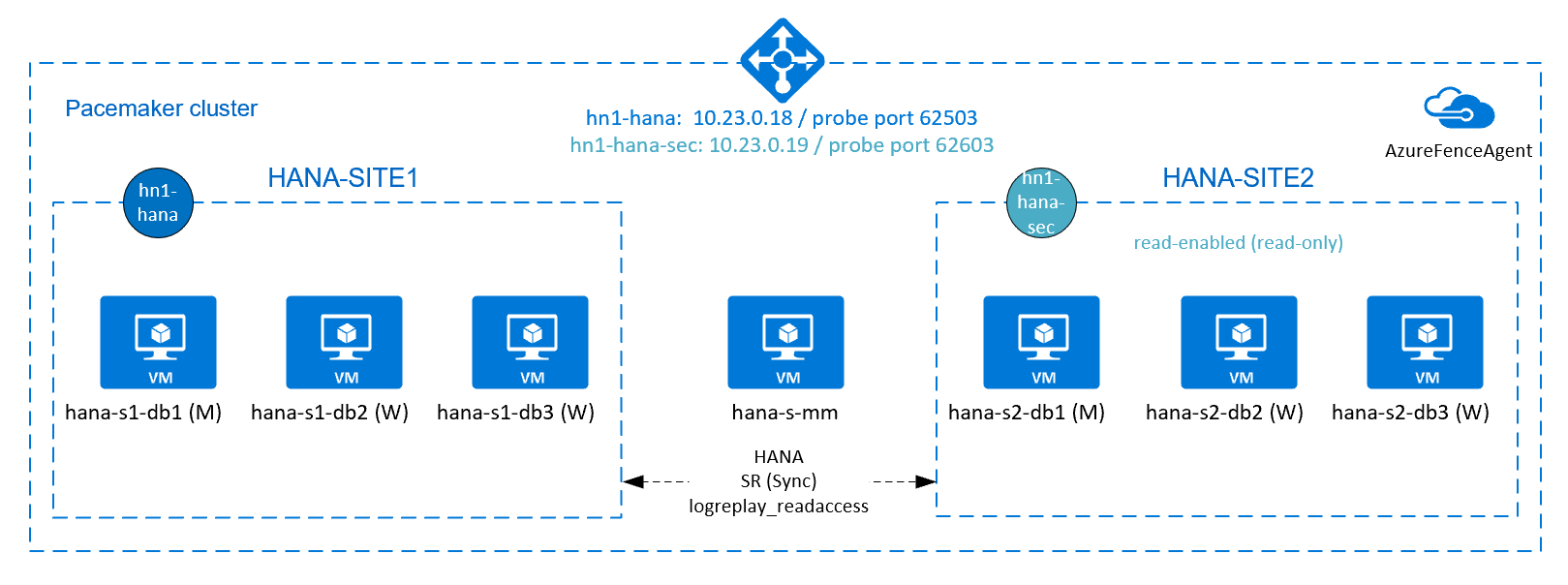
En el diagrama siguiente, hay tres nodos de HANA en cada sitio y un nodo creador mayoritario para evitar un escenario de "cerebro dividido". Las instrucciones se pueden adaptar para incluir más máquinas virtuales como nodos de base de datos HANA.
El sistema /hana/shared de archivos compartidos de HANA en la arquitectura presentada se puede proporcionar mediante Azure NetApp Files o el recurso compartido NFS en Azure Files. El sistema de archivos compartidos de HANA está montado en NFS en cada nodo de HANA en el mismo sitio de replicación del sistema de HANA. Los sistemas de archivos /hana/data y /hana/log son sistemas de archivos locales y no se comparten entre los nodos de la base de datos HANA. SAP HANA se instalará en modo no compartido.
Para las configuraciones de almacenamiento de SAP HANA recomendadas, consulte Configuraciones de almacenamiento de máquinas virtuales de Azure en SAP HANA.
Importante
Si se implementan todos los sistemas de archivos de HANA en Azure NetApp Files, en el caso de los sistemas de producción, donde el rendimiento es una clave, se recomienda evaluar y considerar el uso de un grupo de volúmenes de aplicación de Azure NetApp Files para SAP HANA.

En el diagrama anterior, se muestran tres subredes dentro de una red virtual de Azure, siguiendo las recomendaciones de la red de SAP HANA:
- Para la comunicación del cliente:
client10.23.0.0/24 - Para la comunicación interna entre nodos de HANA:
inter10.23.1.128/26 - Para la replicación del sistema HANA:
hsr10.23.1.192/26
Como /hana/data y /hana/log se han implementado en discos locales, no es necesario implementar una subred independiente ni tarjetas de red virtual independientes para la comunicación con el almacenamiento.
Si usa Azure NetApp Files, los volúmenes NFS para /hana/shared se implementan en una subred independiente, delegada en Azure NetApp Files: anf 10.23.1.0/26.
Configuración de la infraestructura
En las instrucciones siguientes, se supone que ya ha creado el grupo de recursos, la red virtual de Azure con tres subredes de la red de Azure: client, inter y hsr.
Implementación de máquinas virtuales Linux en Azure Portal
Implemente las máquinas virtuales de Azure. Para esta configuración, implemente siete máquinas virtuales:
- Tres máquinas virtuales que actúan como nodos de la base de datos HANA para la replicación del sitio 1 de HANA: hana-s1-db1, hana-s1-db2 y hana-s1-db3.
- Tres máquinas virtuales que actúan como nodos de la base de datos HANA para la replicación del sitio 2 de HANA: hana-s2-db1, hana-s2-db2 y hana-s2-db3.
- Una máquina virtual pequeña que sirve para obtener la mayoría: hana-s-mm.
Las máquinas virtuales, implementadas como nodos de base de datos de SAP HANA, deben tener la certificación de SAP para HANA, tal como se publica en el directorio de hardware de SAP HANA. Al implementar los nodos de base de datos HANA, asegúrese de seleccionar la red acelerada.
Para el nodo que sirve para lograr la mayoría, puede implementar una máquina virtual pequeña, ya que esta máquina virtual no ejecuta ninguno de los recursos de SAP HANA. La máquina virtual para lograr la mayoría se usa en la configuración del clúster para obtener un número impar de nodos de clúster en un escenario de cerebro dividido. La máquina virtual para lograr la mayoría solo necesita una interfaz de red virtual en la subred
clienten este ejemplo.Implemente discos administrados locales para
/hana/datay/hana/log. La configuración de almacenamiento mínima recomendada para/hana/datay/hana/logse describe en Configuraciones de almacenamiento de máquinas virtuales de Azure en SAP HANA.Implemente la interfaz de red principal para cada máquina virtual en la subred de la red virtual
client. Cuando la máquina virtual se implementa mediante Azure Portal, el nombre de la interfaz de red se genera automáticamente. En este artículo, nos referiremos a las interfaces de red principales generadas automáticamente como hana-s1-db1-client, hana-s1-db2-client, hana-s1-db3-client y así sucesivamente. Estas interfaces de red se asocian a la subred de la red virtual de Azureclient.Importante
Asegúrese de que el sistema operativo seleccionado esté certificado por SAP para SAP HANA en los tipos específicos de VM que use. Para obtener una lista de los tipos de VM certificados para SAP HANA y las versiones de sistema operativo correspondientes, consulte Plataformas de IaaS certificadas para SAP HANA. Explore en profundidad los detalles del tipo de VM de la lista para obtener la lista completa de las versiones de sistema operativo compatibles con SAP HANA para ese tipo.
Cree seis interfaces de red, una para cada máquina virtual de base de datos HANA, en la subred de la red virtual
inter(en este ejemplo, hana-s1-db1-inter, hana-s1-db2-inter, hana-s1-db3-inter, hana-s2-db1-inter, hana-s2-db2-inter y hana-s2-db3-inter).Cree seis interfaces de red, una para cada máquina virtual de base de datos HANA, en la subred de la red virtual
hsr(en este ejemplo, hana-s1-db1-hsr, hana-s1-db2-hsr, hana-s1-db3-hsr, hana-s2-db1-hsr, hana-s2-db2-hsr y hana-s2-db3-hsr).Conexión de las interfaces de red virtual recién creadas a las máquinas virtuales correspondientes:
- Vaya a la máquina virtual en Azure Portal.
- En el panel de la izquierda, seleccione Máquinas virtuales. Filtre por el nombre de máquina virtual (por ejemplo, hana-s1-db1) y luego seleccione la máquina virtual.
- En el panel Información general, seleccione Detener para desasignar la máquina virtual.
- Seleccione Redes y adjunte la interfaz de red. En la lista desplegable Adjuntar interfaz de red, seleccione las interfaces de red ya creadas para las subredes
interyhsr. - Seleccione Guardar.
- Repita los pasos del b al e para las demás máquinas virtuales (en nuestro ejemplo, hana-s1-db2, hana-s1-db3, hana-s2-db1, hana-s2-db2 y hana-s2-db3).
- Deje las máquinas virtuales en estado detenido por ahora.
Haga lo siguiente para habilitar redes aceleradas para las interfaces de red adicionales de las subredes
interyhsr:Abra Azure Cloud Shell en Azure Portal.
Ejecute los siguientes comandos para habilitar las redes aceleradas para las interfaces de red adicionales, conectadas a las subredes
interyhsr.az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-hsr --accelerated-networking true
Inicie las máquinas virtuales de base de datos HANA.
Configurar Azure Load Balancer
Durante la configuración de la máquina virtual, tiene una opción para crear o seleccionar salir del equilibrador de carga en la sección de redes. Siga estos pasos para configurar el equilibrador de carga estándar para la configuración de alta disponibilidad de la base de datos de HANA.
Nota:
- Para el escalado horizontal de HANA, seleccione la NIC para la subred
cliental agregar las máquinas virtuales en el grupo de back-end. - El conjunto completo de comandos en la CLI de Azure y PowerShell agrega las máquinas virtuales con la NIC principal en el grupo de back-end.
Siga los pasos descritos en Creación de un equilibrador de carga para configurar un equilibrador de carga estándar para un sistema SAP de alta disponibilidad mediante Azure Portal. Durante la configuración del equilibrador de carga, tenga en cuenta los siguientes puntos:
- Configuración de IP de front-end: cree una dirección IP de front-end. Seleccione el mismo nombre de red virtual y subred que las máquinas virtuales de la base de datos.
- Grupo de back-end: cree un grupo de back-end y agregue máquinas virtuales de base de datos.
- Reglas de entrada: cree una regla de equilibrio de carga. Siga los mismos pasos para ambas reglas de equilibrio de carga.
- Dirección IP de front-end: seleccione una dirección IP de front-end.
- Grupo de back-end: seleccione un grupo de back-end.
- Puertos de alta disponibilidad: seleccione esta opción.
- Protocolo: seleccione TCP.
- Sondeo de estado: cree un sondeo de estado con los detalles siguientes:
- Protocolo: seleccione TCP.
- Puerto: por ejemplo, 625<instance-no.>.
- Intervalo: escriba 5.
- Umbral de sondeo: escriba 2.
- Tiempo de espera de inactividad (minutos): escriba 30.
- Habilitar IP flotante: seleccione esta opción.
Nota:
No se respeta la propiedad de configuración del sondeo de estado numberOfProbes, lo que se conoce como Umbral incorrecto en el portal. Para controlar el número de sondeos consecutivos correctos o erróneos, establezca la propiedad probeThreshold en 2. Actualmente no es posible establecer esta propiedad mediante Azure Portal, por lo que debe usar la CLI de Azure o el comando de PowerShell.
Importante
La dirección IP flotante no se admite en una configuración de IP secundaria de NIC en escenarios de equilibrio de carga. Para ver detalles, consulte Limitaciones de Azure Load Balancer. Si necesita una dirección IP adicional para la VM, implemente una segunda NIC.
Nota:
Cuando use el equilibrador de carga estándar, debe tener en cuenta la siguiente limitación. Al colocar máquinas virtuales sin direcciones IP públicas en el grupo de back-end de un equilibrador de carga interno, no hay conectividad saliente a Internet. Para permitir el enrutamiento a puntos de conexión públicos, debe realizar una configuración adicional. Para más información, consulte Conectividad del punto de conexión público para las máquinas virtuales que usan Azure Standard Load Balancer en escenarios de alta disponibilidad de SAP.
Importante
No habilite las marcas de tiempo TCP en VM de Azure que se encuentren detrás de Azure Load Balancer. Si habilita las marcas de tiempo TCP provocará un error en los sondeos de estado. Establezca el parámetro net.ipv4.tcp_timestamps en 0. Para obtener más información, consulte Sondeos de estado de Load Balancer y la nota de SAP 2382421.
Implementar NFS
Hay dos opciones para implementar el NFS nativo de Azure para /hana/shared. Puede implementar un volumen NFS en Azure NetApp Files o un recurso compartido NFS en Azure Files. Azure Files admite el protocolo NFSv4.1, NFS en Azure NetApp Files admite NFSv4.1 y NFSv3.
En las secciones siguientes se describen los pasos para implementar NFS: tendrá que seleccionar solo una de las opciones.
Sugerencia
Eligió implementar /hana/shared en recurso NFS en Azure Files o volumen NFS en Azure NetApp Files.
Implementación de la infraestructura de Azure NetApp Files
Implemente los volúmenes de Azure NetApp Files para el sistema de archivos /hana/shared. Necesita un volumen /hana/shared independiente para cada sitio de replicación del sistema HANA. Para más información, consulte Configuración de la infraestructura de Azure NetApp Files.
En este ejemplo, se usan los siguientes volúmenes de Azure NetApp Files:
- volumen HN1-shared-s1 (nfs://10.23.1.7/HN1-shared-s1)
- volumen HN1-shared-s2 (nfs://10.23.1.7/HN1-shared-s2)
Implementación de NFS en infraestructura de Azure Files
Implemente recursos compartidos NFS de Azure Files para el sistema de archivos /hana/shared. Necesitará un recurso compartido NFS de Azure Files /hana/shared independiente para cada sitio de replicación del sistema HANA. Para más información, consulte Creación de un recurso compartido NFS.
En este ejemplo, se usaron los siguientes recursos compartidos NFS de Azure Files:
- share hn1-shared-s1 (sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1)
- share hn1-shared-s2 (sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2)
Configuración y preparación del sistema operativo
Las instrucciones de las secciones siguientes tienen como prefijo una de las siguientes abreviaturas:
- [A] : Aplicable a todos los nodos
- [AH]: Aplicable a todos los nodos de base de datos HANA
- [M]: Aplicable al nodo que sirve para lograr la mayoría
- [AH1]: Aplicable a todos los nodos de base de datos HANA en el sitio 1
- [AH1]: Aplicable a todos los nodos de base de datos HANA en el sitio 2
- [1]: Aplicable solo al nodo 1 de base de datos HANA, sitio 1
- [2]: Aplicable solo al nodo 1 de base de datos HANA, sitio 2
Haga lo siguiente para configurar y preparar el sistema operativo:
[A] Mantenga los archivos de host en las máquinas virtuales. Incluya las entradas para todas las subredes. En este ejemplo se agregaron las siguientes entradas a
/etc/hosts.# Client subnet 10.23.0.11 hana-s1-db1 10.23.0.12 hana-s1-db1 10.23.0.13 hana-s1-db2 10.23.0.14 hana-s2-db1 10.23.0.15 hana-s2-db2 10.23.0.16 hana-s2-db3 10.23.0.17 hana-s-mm # Internode subnet 10.23.1.138 hana-s1-db1-inter 10.23.1.139 hana-s1-db2-inter 10.23.1.140 hana-s1-db3-inter 10.23.1.141 hana-s2-db1-inter 10.23.1.142 hana-s2-db2-inter 10.23.1.143 hana-s2-db3-inter # HSR subnet 10.23.1.202 hana-s1-db1-hsr 10.23.1.203 hana-s1-db2-hsr 10.23.1.204 hana-s1-db3-hsr 10.23.1.205 hana-s2-db1-hsr 10.23.1.206 hana-s2-db2-hsr 10.23.1.207 hana-s2-db3-hsr[A] Cree el archivo de configuración /etc/sysctl.d/MS-AZ.conf con las opciones de configuración de Microsoft para Azure.
vi /etc/sysctl.d/ms-az.conf # Add the following entries in the configuration file net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10Sugerencia
Evite establecer
net.ipv4.ip_local_port_rangeynet.ipv4.ip_local_reserved_portsexplícitamente en los archivos de configuraciónsysctlpara permitir que el agente de host de SAP administre los intervalos de puertos. Para más información, consulte la nota de SAP 2382421.[A] Instale el paquete de cliente NFS.
yum install nfs-utils[AH] Configuración de Red Hat para HANA.
Configure RHEL tal como se describe en Portal del cliente de Red Hat y en las siguientes notas de SAP:
- 2292690 - SAP HANA DB: Recommended OS settings for RHEL 7 (2292690 - SAP HANA DB: configuraciones de sistema operativo recomendadas para RHEL 7)
- 2777782 - base de datos de SAP HANA: configuraciones de sistema operativo recomendadas para RHEL 8
- 2455582 - Linux: Running SAP applications compiled with GCC 6.x (Nota de compatibilidad de SAP n.º 2455582 - Linux: Ejecución de aplicaciones SAP compiladas con GCC 6.x)
- 2593824 - Linux: Ejecución de aplicaciones SAP compiladas con GCC 7.x
- 2886607 - Linux: Ejecución de aplicaciones SAP compiladas con GCC 9.x
Preparación de los sistemas de archivos
En las secciones siguientes se proporcionan los pasos para la preparación de los sistemas de archivos. Eligió implementar “/hana/shared” en el recursos compartido de NFS en Azure Files o el volumen NFS en Azure NetApp Files.
Montaje de los sistemas de archivos compartidos (NFS de Azure NetApp Files)
En este ejemplo, los sistemas de archivos de HANA compartidos se implementan en Azure NetApp Files y se montan en NFSv4.1. Siga los pasos de esta sección solo si usa NFS en Azure NetApp Files.
[AH] Prepare el sistema operativo para ejecutar SAP HANA en sistemas NetApp con NFS, tal como se describe en la nota de SAP 3024346 - Configuración de Linux Kernel para NetApp NFS. Cree el archivo de configuración /etc/sysctl.d/91-NetApp-HANA.conf para la configuración de NetApp.
vi /etc/sysctl.d/91-NetApp-HANA.conf # Add the following entries in the configuration file net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[AH] Ajuste la configuración de sunrpc, como se recomienda en la nota de SAP 3024346 - Configuración de Linux Kernel para NetApp NFS.
vi /etc/modprobe.d/sunrpc.conf # Insert the following line options sunrpc tcp_max_slot_table_entries=128[AH] Cree puntos de montaje para los volúmenes de bases de datos HANA.
mkdir -p /hana/shared[AH] Compruebe la configuración del dominio NFS. Asegúrese de que el dominio esté configurado como dominio predeterminado de Azure NetApp Files:
defaultv4iddomain.com. Asegúrese de que la asignación está establecida ennobody.
(Este paso solo es necesario si usa Azure NetAppFiles NFS v4.1).Importante
Asegúrese de establecer el dominio NFS de
/etc/idmapd.confen la máquina virtual para que coincida con la configuración de dominio predeterminada en Azure NetApp Files:defaultv4iddomain.com. Si hay una discrepancia entre la configuración de dominio en el cliente NFS y el servidor NFS, los permisos para los archivos en los volúmenes de Azure NetApp montados en las VM se mostrarán comonobody.sudo cat /etc/idmapd.conf # Example [General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobody[AH] Compruebe
nfs4_disable_idmapping. Se debe establecer enY. Para crear la estructura de directorio en la que se encuentranfs4_disable_idmapping, ejecute el comando mount. No podrá crear manualmente el directorio en /sys/modules, ya que el acceso está reservado para el kernel o los controladores.
Este paso solo es necesario si usa Azure NetAppFiles NFSv4.1.# Check nfs4_disable_idmapping cat /sys/module/nfs/parameters/nfs4_disable_idmapping # If you need to set nfs4_disable_idmapping to Y mkdir /mnt/tmp mount 10.9.0.4:/HN1-shared /mnt/tmp umount /mnt/tmp echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmapping # Make the configuration permanent echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.confPara más información sobre cómo cambiar el parámetro
nfs4_disable_idmapping, consulte el Portal de clientes de Red Hat.[AH1] Monte los volúmenes de Azure NetApp Files compartidos en las máquinas virtuales de base de datos HANA del sitio 1.
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s1 /hana/shared[AH2] Monte los volúmenes de Azure NetApp Files compartidos en las máquinas virtuales de base de datos HANA del sitio 2.
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s2 /hana/shared[AH] Compruebe que los sistemas de archivos
/hana/shared/correspondientes estén montados en todas las máquinas virtuales de base de datos HANA con la versión del protocolo NFS NFSv4.sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7
Montaje de los sistemas de archivos compartidos (NFS de Azure Files)
En este ejemplo, los sistemas de archivos de HANA compartidos se implementan en NFS de Azure Files. Siga los pasos de esta sección solo si usa NFS en Azure Files.
[AH] Cree puntos de montaje para los volúmenes de bases de datos HANA.
mkdir -p /hana/shared[AH1] Monte los volúmenes de Azure NetApp Files compartidos en las máquinas virtuales de base de datos HANA del sitio 1.
sudo vi /etc/fstab # Add the following entry sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount all volumes sudo mount -a[AH2] Monte los volúmenes de Azure NetApp Files compartidos en las máquinas virtuales de base de datos HANA del sitio 2.
sudo vi /etc/fstab # Add the following entries sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount the volume sudo mount -a[AH] Compruebe que los sistemas de archivos
/hana/shared/correspondientes estén montados en todas las máquinas virtuales de base de datos HANA con la versión del protocolo NFS NFSv4.1.sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
Preparación de los sistemas de archivos locales de registro y datos
En la configuración presentada, se implementan sistemas de archivos /hana/data y /hana/log en un disco administrado, y se asocian estos sistemas de archivos localmente a cada máquina virtual de base de datos de HANA. Ejecute los pasos necesarios para crear los volúmenes locales de datos y de registro en cada máquina virtual de base de datos de HANA.
Configure el diseño de disco con el Administrador de volúmenes lógicos (LVM) . En el ejemplo siguiente se supone que cada máquina virtual HANA tiene tres discos de datos conectados que se usan para crear dos volúmenes.
[AH] Enumere todos los discos disponibles:
ls /dev/disk/azure/scsi1/lun*Salida de ejemplo:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2[AH] Cree volúmenes físicos para todos los discos que quiera usar:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2[AH] Cree un grupo de volúmenes para los archivos de datos. Use un grupo de volúmenes para los archivos de registro y otro para el directorio compartido de SAP HANA:
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2[AH] Cree los volúmenes lógicos. Cuando se usa
lvcreatesin el modificador-i, se crea un volumen lineal. Se recomienda crear un volumen seccionado para mejorar el rendimiento de E/S. Alinee los tamaños de sección con los valores documentados en las configuraciones de almacenamiento de máquinas virtuales de SAP HANA. El argumento-idebe ser el número de volúmenes físicos subyacentes y-I, el tamaño de la sección. En este artículo, se usan dos volúmenes físicos para el volumen de datos, por lo que el argumento de modificador-ise establece en2. El tamaño de sección para el volumen de datos es256 KiB. Se usa un volumen físico para el volumen de registro, no necesita usar explícitamente ningún modificador-io-Ipara los comandos del volumen de registro.Importante
Use el modificador
-iy establézcalo en el número del volumen físico subyacente cuando se usa más de un volumen físico para cada volumen de datos o de registro. Use el modificador-Ipara especificar el tamaño de las secciones al crear un volumen seccionado. Consulte Configuraciones de almacenamiento de máquinas virtuales de Azure en SAP HANA para conocer las configuraciones de almacenamiento recomendadas, incluidos los tamaños de sección y el número de discos.sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log[AH] Cree los directorios de montaje y copie el UUID de todos los volúmenes lógicos:
sudo mkdir -p /hana/data/HN1 sudo mkdir -p /hana/log/HN1 # Write down the ID of /dev/vg_hana_data_HN1/hana_data and /dev/vg_hana_log_HN1/hana_log sudo blkid[AH] Cree entradas
fstabpara los volúmenes lógicos y móntelos:sudo vi /etc/fstabInserte la siguiente línea en el archivo
/etc/fstab:/dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_data_HN1-hana_data /hana/data/HN1 xfs defaults,nofail 0 2 /dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_log_HN1-hana_log /hana/log/HN1 xfs defaults,nofail 0 2Monte los nuevos volúmenes:
sudo mount -a
Instalación
En este ejemplo para implementar SAP HANA en la configuración de escalabilidad horizontal con HSR en máquinas virtuales de Azure, se usa HANA 2.0 SP4.
Preparación de la instalación de HANA
[AH] Antes de realizar la instalación de HANA, establezca la contraseña raíz. Puede deshabilitar la contraseña raíz una vez completada la instalación. Ejecute
rootcomo comandopasswdpara establecer la contraseña.[1,2] Cambie los permisos para
/hana/shared.chmod 775 /hana/shared[1] Compruebe que puede iniciar sesión en hana-s1-db2 y hana-s1-db3, a través de Secure Shell (SSH) sin que se le pida una contraseña. Si no es el caso, intercambie las claves
ssh, tal como se documenta en Utilización de la autenticación basada en claves.ssh root@hana-s1-db2 ssh root@hana-s1-db3[2] Compruebe que puede iniciar sesión en hana-s2-db2 y hana-s2-db3, a través de SSH sin que se le pida una contraseña. Si no es el caso, intercambie las claves
ssh, tal como se documenta en Utilización de la autenticación basada en claves.ssh root@hana-s2-db2 ssh root@hana-s2-db3[AH] Instale paquetes adicionales, necesarios para HANA 2.0 SP4. Para más información, consulte las notas de SAP 2593824 para RHEL 7.
# If using RHEL 7 yum install libgcc_s1 libstdc++6 compat-sap-c++-7 libatomic1 # If using RHEL 8 yum install libatomic libtool-ltdl.x86_64[A] Deshabilite el firewall temporalmente para que no interfiera con la instalación de HANA. Puede volver a habilitarlo después de realizar la instalación de HANA.
# Execute as root systemctl stop firewalld systemctl disable firewalld
Instalación de HANA en el primer nodo de cada sitio
[1] Instale SAP HANA. Para ello, siga las instrucciones de la guía de instalación y actualización de SAP HANA 2.0. En las instrucciones siguientes, se muestra la instalación de SAP HANA en el primer nodo del SITIO 1.
Inicie el programa
hdblcmcomorootdesde el directorio de software de instalación de HANA. Use el parámetrointernal_networky pase el espacio de direcciones a la subred que se usa para la comunicación interna entre nodos de HANA../hdblcm --internal_network=10.23.1.128/26Escriba los siguientes valores en el símbolo del sistema:
- En Elegir una acción, escriba 1 (para la instalación).
- En Additional components for installation (Componentes adicionales para la instalación), especifique 2, 3.
- Para la ruta de instalación: presione ENTRAR (el valor predeterminado es /hana/shared).
- En Nombre de host local, presione ENTRAR para aceptar el valor predeterminado.
- En Do you want to add hosts to the system? (¿Desea agregar hosts al sistema?), escriba n.
- En SAP HANA ID (Id. de SAP HANA) del sistema, escriba HN1.
- En Instance number (Número de instancia) [00], escriba 03.
- En Local Host Worker Group (Grupo de trabajo de host local) [valor predeterminado], presione ENTRAR para aceptar el valor predeterminado.
- En Select System Usage / Enter index [4] (Seleccionar uso del sistema o especificar el índice [4]), escriba 4 (para personalizar).
- En Location of Data Volumes (Ubicación de los volúmenes de datos) [/hana/data/HN1], presione ENTRAR para aceptar el valor predeterminado.
- En Location of Log Volumes (Ubicación de los volúmenes de registro) [/hana/log/HN1], presione ENTRAR para aceptar el valor predeterminado.
- En Restrict maximum memory allocation? [n], escriba n.
- En Certificate Host Name For Host hana-s1-db1 (Nombre de host del certificado para el host hana-s1-db1) [hana-s1-db1], presione ENTRAR para aceptar el valor predeterminado.
- En SAP Host Agent User (sapadm) Password [Contraseña del usuario del agente de host de SAP (sapadm)], escriba la contraseña.
- En Confirm SAP Host Agent User (sapadm) Password [Confirmar contraseña de usuario del agente de host de SAP (sapadm)], escriba la contraseña.
- En System Administrator (hn1adm) Password (Contraseña del administrador del sistema (hn1adm)), escriba la contraseña.
- En System Administrator Home Directory (Directorio principal de administrador del sistema) [/usr/sap/HN1/home], presione ENTRAR para aceptar el valor predeterminado.
- En System Administrator Login Shell (Shell de inicio de sesión de administrador del sistema) [/bin/sh], presione ENTRAR para aceptar el valor predeterminado.
- En System Administrator User ID (Id. de usuario de administrador del sistema) [1001], presione ENTRAR para aceptar el valor predeterminado.
- En Enter ID of User Group (sapsys) [Escriba el id. del grupo de usuarios (sapsys)] [79], presione ENTRAR para aceptar el valor predeterminado.
- En System Database User (system) Password (Contraseña de usuario de base de datos del sistema (sistema)), escriba la contraseña del sistema.
- En Confirm System Database User (system) Password (Confirmar la contraseña del usuario (sistema) de la base de datos del sistema), escriba la contraseña del sistema.
- En Restart system after machine reboot? [n], escriba n.
- En Do you want to continue (y/n) (¿Desea continuar (sí/no)?), valide el resumen y, si todo es correcto, especifique y.
[2] Repita el paso anterior para instalar SAP HANA en el primer nodo del sitio 2.
[1,2] Compruebe global.ini.
Muestre global.ini y asegúrese de que la configuración de la comunicación interna entre nodos de SAP HANA esté presente. Compruebe la sección
communication. Debe tener el espacio de direcciones para la subredinter, ylisteninterfacedebe estar establecido en.internal. Compruebe la seccióninternal_hostname_resolution. Debe tener las direcciones IP de las máquinas virtuales de HANA que pertenezcan a la subredinter.sudo cat /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini # Example from SITE1 [communication] internal_network = 10.23.1.128/26 listeninterface = .internal [internal_hostname_resolution] 10.23.1.138 = hana-s1-db1 10.23.1.139 = hana-s1-db2 10.23.1.140 = hana-s1-db3[1,2] Prepare global.ini para la instalación en un entorno no compartido, como se describe en la nota de SAP 2080991.
sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini [persistence] basepath_shared = no[1,2] Reinicie SAP HANA para activar los cambios.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem[1,2] Compruebe que la interfaz de cliente utiliza las direcciones IP de la subred
clientpara la comunicación.# Execute as hn1adm /usr/sap/HN1/HDB03/exe/hdbsql -u SYSTEM -p "password" -i 03 -d SYSTEMDB 'select * from SYS.M_HOST_INFORMATION'|grep net_publicname # Expected result - example from SITE 2 "hana-s2-db1","net_publicname","10.23.0.14"Para más información sobre cómo comprobar la configuración, consulte la nota de SAP 2183363 - Configuración de la red interna de SAP HANA.
[AH] Cambie los permisos en los directorios de datos y de registro para evitar errores de instalación de HANA.
sudo chmod o+w -R /hana/data /hana/log[1] Instale los nodos secundarios de HANA. Las instrucciones de ejemplo de este paso son para el sitio 1.
Inicie el programa residente
hdblcmcomoroot.cd /hana/shared/HN1/hdblcm ./hdblcmEscriba los siguientes valores en el símbolo del sistema:
- En Elegir una acción, escriba 2 (para agregar hosts).
- En Enter comma-separated host names to add (Escriba los nombres de host separados por comas que se deben agregar), escriba hana-s1-db2, hana-s1-db3.
- En Additional components for installation (Componentes adicionales para la instalación), especifique 2, 3.
- En Enter Root User Name [root] (Escriba el nombre de usuario raíz [raíz]), presione ENTRAR para aceptar el valor predeterminado.
- En Select roles for host 'hana-s1-db2' [1] (Seleccione los roles para el host "hana-s1-db2" [1]), seleccione 1 (para trabajo).
- En Enter Host Failover Group for host 'hana-s1-db2' [default] (Escriba el grupo de conmutación por error de host para el host "hana-s1-db2" [predeterminado]), presione ENTRAR para aceptar el valor predeterminado.
- En Enter Storage Partition Number for host 'hana-s1-db2' [<<asignar automáticamente>>], presione Introducir para aceptar el valor predeterminado.
- En Enter Worker Group for host 'hana-s1-db2' [default] (Escriba el grupo de trabajo para el host "hana-s1-db2" [predeterminado]), presione ENTRAR para aceptar el valor predeterminado.
- En Select roles for host 'hana-s1-db3' [1] (Seleccione los roles para el host "hana-s1-db3" [1]), seleccione 1 (para trabajo).
- En Enter Host Failover Group for host 'hana-s1-db3' [default] (Escriba el grupo de conmutación por error de host para el host "hana-s1-db3" [predeterminado]), presione ENTRAR para aceptar el valor predeterminado.
- En Enter Storage Partition Number for host 'hana-s1-db3' [<<asignar automáticamente>>], presione Introducir para aceptar el valor predeterminado.
- En Enter Worker Group for host 'hana-s1-db3' [default] (Escriba el grupo de trabajo para el host "hana-s1-db3" [predeterminado]), presione ENTRAR para aceptar el valor predeterminado.
- En System Administrator (hn1adm) Password (Contraseña del administrador del sistema (hn1adm)), escriba la contraseña.
- En Enter SAP Host Agent User (sapadm) Password [Escriba la contraseña del usuario del agente de host de SAP (sapadm)], escriba la contraseña.
- En Confirm SAP Host Agent User (sapadm) Password [Confirmar contraseña de usuario del agente de host de SAP (sapadm)], escriba la contraseña.
- En Certificate Host Name For Host hana-s1-db2 (Nombre de host del certificado para el host hana-s1-db2) [hana-s1-db2], presione ENTRAR para aceptar el valor predeterminado.
- En Certificate Host Name For Host hana-s1-db3 (Nombre de host del certificado para el host hana-s1-db3) [hana-s1-db3], presione ENTRAR para aceptar el valor predeterminado.
- En Do you want to continue (y/n) (¿Desea continuar (sí/no)?), valide el resumen y, si todo es correcto, especifique y.
[2] Repita el paso anterior para instalar los nodos de SAP HANA secundarios en el sitio 2.
Configuración de la Replicación del sistema de SAP HANA 2.0
En los pasos siguientes se indica cómo configurar la replicación del sistema:
[1] Configure la replicación del sistema en el SITIO 1:
Haga una copia de seguridad de las bases de datos como hn1adm:
hdbsql -d SYSTEMDB -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')"Copie los archivos PKI de sistema en el sitio secundario:
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/Cree el sitio principal:
hdbnsutil -sr_enable --name=HANA_S1[2] Configure la replicación del sistema en el SITIO 2:
Registre el segundo sitio para iniciar la replicación del sistema. Ejecute el siguiente comando como <hanasid>adm:
sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 sapcontrol -nr 03 -function StartSystem[1] Compruebe el estado de replicación y espere hasta que todas las bases de datos estén sincronizadas.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" # | Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary | Secondary | Secondary | Secondary | Replication | Replication | Replication | # | | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | # | -------- | ------------- | ----- | ------------ | --------- | ------- | --------- | ------------- | --------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | # | HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 1 | HANA_S1 | hana-s2-db3 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 1 | HANA_S1 | hana-s2-db1 | 30301 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 1 | HANA_S1 | hana-s2-db1 | 30307 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 1 | HANA_S1 | hana-s2-db1 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 1 | HANA_S1 | hana-s2-db2 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # # status system replication site "2": ACTIVE # overall system replication status: ACTIVE # # Local System Replication State # # mode: PRIMARY # site id: 1 # site name: HANA_S1[1,2] Cambie la configuración de HANA para que la comunicación para la replicación del sistema HANA se direccione a través de las interfaces de red virtual de replicación del sistema HANA.
Detenga HANA en ambos sitios.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem HDBEdite global.ini para agregar la asignación de host para la replicación del sistema HANA. Use las direcciones IP de la subred
hsr.sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini #Add the section [system_replication_hostname_resolution] 10.23.1.202 = hana-s1-db1 10.23.1.203 = hana-s1-db2 10.23.1.204 = hana-s1-db3 10.23.1.205 = hana-s2-db1 10.23.1.206 = hana-s2-db2 10.23.1.207 = hana-s2-db3Inicie HANA en ambos sitios.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem HDB
Para más información, vea Resolución del nombre de host para la replicación del sistema.
[AH] Vuelva a habilitar el firewall y abra los puertos necesarios.
Vuelva a habilitar el firewall.
# Execute as root systemctl start firewalld systemctl enable firewalldAbra los puertos de firewall necesarios. Tendrá que ajustar los puertos para el número de instancia de HANA.
Importante
Cree reglas de firewall para permitir la comunicación entre nodos de HANA y el tráfico del cliente. Los puertos necesarios se enumeran en TCP/IP Ports of All SAP Products (Puertos TCP/IP de todos los productos de SAP). Los siguientes comandos son solo un ejemplo. En este escenario, se usa el número de sistema 03.
# Execute as root sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp --permanent sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp
Creación de un clúster de Pacemaker
Para crear un clúster de Pacemaker básico, siga los pasos de Configuración de Pacemaker en Red Hat Enterprise Linux en Azure. Incluya todas las máquinas virtuales, inclusive la que sirve para obtener la mayoría en el clúster.
Importante
No establezca quorum expected-votes en 2. No se trata de un clúster de dos nodos. Asegúrese de que la propiedad de clúster concurrent-fencing esté habilitada, de modo que se deserialicen las barreras de nodo.
Creación de recursos del sistema de archivos
Para la siguiente parte de este proceso, debe crear recursos del sistema de archivos. A continuación se muestra cómo hacerlo:
[1,2] Detenga SAP HANA en ambos sitios de replicación. Ejecute como <sid>adm.
sapcontrol -nr 03 -function StopSystem[AH] Desmonte el sistema de archivos
/hana/shared, que se montó temporalmente para la instalación en todas las máquinas virtuales de base de datos HANA. Para poder desmontarlo, tendrá que detener los procesos y las sesiones que usen el sistema de archivos.umount /hana/shared[1] Cree los recursos de clúster del sistema de archivos para
/hana/shareden estado deshabilitado. Se usa--disabled, porque debe definir las restricciones de ubicación antes de habilitar los montajes.
Eligió implementar “/hana/shared” en el recursos compartido de NFS en Azure Files o el volumen NFS en Azure NetApp Files.En este ejemplo, el sistema de archivos “/hana/shared” se implementa en Azure NetApp Files y se monta en NFSv4.1. Siga los pasos de esta sección solo si usa NFS en Azure NetApp Files.
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=true
Los valores de tiempo de espera sugeridos permiten que los recursos del clúster resistan la pausa específica del protocolo, relacionadas con las renovaciones de concesión de NFSv4.1 en Azure NetApp Files. Para más información, consulte NFS en el procedimiento recomendado de NetApp.
En este ejemplo, el sistema de archivos “/hana/shared” se implementa en NFS de Azure Files. Siga los pasos de esta sección solo si usa NFS en Azure Files.
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=trueEl atributo
OCF_CHECK_LEVEL=20se agrega a la operación de supervisión, de modo que las operaciones de supervisión realicen una prueba de lectura/escritura en el sistema de archivos. Sin este atributo, la operación de supervisión solo comprueba que el sistema de archivos esté montado. Esto puede ser un problema porque, cuando se pierde la conectividad, el sistema de archivos puede permanecer montado, a pesar de que no se pueda acceder.El atributo
on-fail=fencetambién se agrega a la operación de supervisión. Con esta opción, si se produce un error en la operación de supervisión en un nodo, ese nodo se delimita inmediatamente. Sin esta opción, el comportamiento predeterminado es detener todos los recursos que dependen del recurso con errores, reiniciar el recurso con errores y, después, iniciar todos los recursos que dependen del recurso con errores. Este comportamiento no solo puede tardar mucho tiempo cuando un recurso de SAP HANA depende del recurso con errores, sino que también se puede producir un error general. El recurso de SAP HANA no se puede detener correctamente si el recurso compartido NFS que contiene los binarios de HANA es inaccesible.Es posible que los tiempos de espera de las configuraciones anteriores deban adaptarse a la configuración específica de SAP.
[1] Configure y compruebe los atributos de nodo. A todos los nodos de base de datos SAP HANA del sitio 1 de replicación se les asigna el atributo
S1y todos los nodos de base de datos SAP HANA del sitio 2 de replicación tienen asignados el atributoS2.# HANA replication site 1 pcs node attribute hana-s1-db1 NFS_SID_SITE=S1 pcs node attribute hana-s1-db2 NFS_SID_SITE=S1 pcs node attribute hana-s1-db3 NFS_SID_SITE=S1 # HANA replication site 2 pcs node attribute hana-s2-db1 NFS_SID_SITE=S2 pcs node attribute hana-s2-db2 NFS_SID_SITE=S2 pcs node attribute hana-s2-db3 NFS_SID_SITE=S2 # To verify the attribute assignment to nodes execute pcs node attribute[1] Configure las restricciones, que determinan dónde se montarán los sistemas de archivos NFS y habilitan los recursos del sistema de archivos.
# Configure the constraints pcs constraint location fs_hana_shared_s1-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S1 pcs constraint location fs_hana_shared_s2-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S2 # Enable the file system resources pcs resource enable fs_hana_shared_s1 pcs resource enable fs_hana_shared_s2Al habilitar los recursos del sistema de archivos, el clúster montará los sistemas de archivos
/hana/shared.[AH] Compruebe que los volúmenes de Azure NetApp Files están montados en
/hana/shareden todas las máquinas virtuales de base de datos de HANA en ambos sitios.Ejemplo, si usa Azure NetApp Files:
sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7Ejemplo, si usa NFS de Azure Files:
sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
[1] Configure y clone los recursos de atributo y configure las restricciones, como se muestra a continuación:
# Configure the attribute resources pcs resource create hana_nfs_s1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s1_active pcs resource create hana_nfs_s2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s2_active # Clone the attribute resources pcs resource clone hana_nfs_s1_active meta clone-node-max=1 interleave=true pcs resource clone hana_nfs_s2_active meta clone-node-max=1 interleave=true # Configure the constraints, which will set the attribute values pcs constraint order fs_hana_shared_s1-clone then hana_nfs_s1_active-clone pcs constraint order fs_hana_shared_s2-clone then hana_nfs_s2_active-cloneSugerencia
Si la configuración incluye sistemas de archivos distintos de /
hana/sharedy estos sistemas de archivos están montados en NFS, incluya la opciónsequential=false. Esta opción garantiza que no haya dependencias de ordenación entre los sistemas de archivos. Todos los sistemas de archivos montados en NFS deben iniciarse antes del recurso de atributo correspondiente, pero no tienen que iniciarse en ningún orden en relación con los demás. Para más información, consulte Configuración de HSR de escalabilidad horizontal de SAP HANA en un clúster de Pacemaker cuando los sistemas de archivos de HANA están en recursos compartidos de NFS.[1] Coloque Pacemaker en modo de mantenimiento, como preparación para la creación de los recursos de clúster de HANA.
pcs property set maintenance-mode=true
Creación de recursos de clúster de SAP HANA
Ahora está listo para crear los recursos de clúster:
[A] Instale el agente de recursos de escalabilidad horizontal de HANA en todos los nodos del clúster, incluido el que sirve para obtener la mayoría.
yum install -y resource-agents-sap-hana-scaleoutNota
Para conocer la versión mínima admitida del paquete
resource-agents-sap-hana-scaleoutpara su versión de sistema operativo, consulte Directivas de soporte técnico para los clústeres de alta disponibilidad de RHEL: administración de SAP HANA en un clúster.[1,2] Instale el enlace de replicación del sistema HANA en un nodo de base de datos de HANA en cada sitio de replicación del sistema. SAP HANA debe seguir estando inactivo.
Prepare el enlace como
root.mkdir -p /hana/shared/myHooks cp /usr/share/SAPHanaSR-ScaleOut/SAPHanaSR.py /hana/shared/myHooks chown -R hn1adm:sapsys /hana/shared/myHooksAjuste
global.ini.# add to global.ini [ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /hana/shared/myHooks execution_order = 1 [trace] ha_dr_saphanasr = info
[AH] El clúster requiere la configuración de sudoers en el nodo de clúster para <sid>adm. En este ejemplo, esto se consigue mediante la creación de un nuevo archivo. Ejecute los comandos como
root.sudo visudo -f /etc/sudoers.d/20-saphana # Insert the following lines and then save Cmnd_Alias SOK = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SFAIL -t crm_config -s SAPHanaSR hn1adm ALL=(ALL) NOPASSWD: SOK, SFAIL Defaults!SOK, SFAIL !requiretty[1,2] Inicie SAP HANA en ambos sitios de replicación. Ejecute como <sid>adm.
sapcontrol -nr 03 -function StartSystem[1] Compruebe la instalación del enlace. Ejecute como <sid>adm en el sitio activo de replicación del sistema HANA.
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example entries # 2020-07-21 22:04:32.364379 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:46.905661 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:52.092016 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:52.782774 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:53.117492 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:06:35.599324 ha_dr_SAPHanaSR SOK[1] Cree recursos de clúster de HANA. Ejecute los comandos siguientes como
root.Asegúrese de que el clúster ya esté en modo de mantenimiento.
A continuación, cree el recurso de topología de HANA.
Si va a compilar un clúster de RHEL 7.x, use los comandos siguientes:pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopologyScaleOut \ SID=HN1 InstanceNumber=03 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=trueSi va a compilar un clúster de RHEL >= 8.x, use los comandos siguientes:
pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopology \ SID=HN1 InstanceNumber=03 meta clone-node-max=1 interleave=true \ op methods interval=0s timeout=5 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=trueCree el recurso de instancia de HANA.
Nota:
Este artículo contiene referencias a un término que Microsoft ya no utiliza. Cuando se quite el término del software, se quitará también del artículo.
Si va a compilar un clúster de RHEL 7.x, use los comandos siguientes:
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource master msl_SAPHana_HN1_HDB03 SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=trueSi va a compilar un clúster de RHEL >= 8.x, use los comandos siguientes:
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op demote interval=0s timeout=320 op methods interval=0s timeout=5 \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource promotable SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=trueImportante
Es una buena idea establecer
AUTOMATED_REGISTERenfalse, mientras se realizan pruebas de conmutación por error, para evitar que una instancia principal con errores se registre automáticamente como secundaria. Después de las pruebas, como procedimiento recomendado, establezcaAUTOMATED_REGISTERentruepara que, después de la adquisición, la replicación del sistema pueda reanudarse automáticamente.Cree la dirección IP virtual y los recursos asociados.
pcs resource create vip_HN1_03 ocf:heartbeat:IPaddr2 ip=10.23.0.18 op monitor interval="10s" timeout="20s" sudo pcs resource create nc_HN1_03 azure-lb port=62503 sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03Cree las restricciones de clúster.
Si va a compilar un clúster de RHEL 7.x, use los comandos siguientes:
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then msl_SAPHana_HN1_HDB03 pcs constraint colocation add g_ip_HN1_03 with master msl_SAPHana_HN1_HDB03 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne trueSi va a compilar un clúster de RHEL >= 8.x, use los comandos siguientes:
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then SAPHana_HN1_HDB03-clone pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_HDB03-clone 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne true
[1] Coloque el clúster fuera del modo de mantenimiento. Asegúrese de que el estado del clúster sea
oky que todos los recursos se hayan iniciado.sudo pcs property set maintenance-mode=false #If there are failed cluster resources, you may need to run the next command pcs resource cleanupNota
Los tiempos de espera de la configuración anterior son solo ejemplos y puede ser necesario adaptarlos a la configuración específica de HANA. Por ejemplo, puede que necesite aumentar el tiempo de espera de inicio si la base de datos de SAP HANA tarda más en iniciarse.
Configuración de la replicación del sistema HANA activo/habilitado para lectura
A partir de SAP HANA 2.0 SPS 01, SAP permite configuraciones activas o habilitadas para lectura para la replicación del sistema SAP HANA. Con esta funcionalidad, puede usar los sistemas secundarios de la replicación del sistema SAP HANA activamente para cargas de trabajo de lectura intensiva. Para admitir esta configuración en un clúster, se requiere una segunda dirección IP virtual que permita a los clientes tener acceso a la base de datos secundaria de SAP HANA habilitada para lectura. Para garantizar que todavía se puede tener acceso al sitio de replicación secundario tras una adquisición, el clúster debe mover la dirección IP virtual con el sistema secundario del recurso de SAP HANA.
En esta sección se describen los pasos adicionales que debe seguir para administrar este tipo de replicación del sistema en un clúster de alta disponibilidad de Red Hat, con una segunda dirección IP virtual.
Antes de continuar, asegúrese de que ha configurado completamente el clúster de Red Hat de alta disponibilidad que administra la base de datos de SAP HANA, tal como se describe en las secciones anteriores de este artículo.
Configuración adicional en Azure Load Balancer para la configuración activa/habilitada para lectura
Para continuar con el aprovisionamiento de la segunda IP virtual, asegúrese de que ha configurado Azure Load Balancer como se describe en Configuración de Azure Load Balancer.
Para el equilibrador de carga estándar, siga los pasos adicionales que se indican a continuación en el mismo equilibrador de carga que creó en la sección anterior.
Crear un segundo grupo de direcciones IP de front-end:
- Abra el equilibrador de carga, seleccione frontend IP pool (Grupo de direcciones IP de front-end) y haga clic en Agregar.
- Escriba el nombre del segundo grupo de direcciones IP de front-end (por ejemplo, hana-secondaryIP).
- Establezca Asignación en Estática y escriba la dirección IP (por ejemplo, 10.23.0.19).
- Seleccione Aceptar.
- Una vez creado el nuevo grupo de direcciones IP de front-end, anote la dirección IP del grupo.
A continuación, cree un sondeo de estado:
- Abra el equilibrador de carga, seleccione Sondeos de estado y haga clic en Agregar.
- Escriba el nombre del sondeo de estado nuevo (por ejemplo hana-secondaryhp).
- Seleccione TCP como el protocolo y el puerto 62603. Mantenga el valor de Intervalo en 5 y el valor de Umbral incorrecto en 2.
- Seleccione Aceptar.
Luego cree las reglas de equilibrio de carga:
- Abra el equilibrador de carga, seleccione Reglas de equilibrio de carga y haga clic en Agregar.
- Escriba el nombre de la nueva regla del equilibrador de carga (por ejemplo, hana-secondarylb).
- Seleccione la dirección IP de front-end, el grupo de back-end y el sondeo de estado que creó anteriormente (por ejemplo, hana-secondaryIP, hana-backend y hana-secondaryhp).
- Seleccione Puertos HA.
- Asegúrese de habilitar la dirección IP flotante.
- Seleccione Aceptar.
Configuración de la replicación del sistema HANA activo/habilitado para lectura
Los pasos para configurar la replicación del sistema de HANA se describen en la sección Configuración de la replicación del sistema SAP HANA 2.0. Si va a implementar un escenario secundario habilitado para lectura, mientras configura la replicación del sistema en el segundo nodo, ejecute el siguiente comando como hanasidadm:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 --operationMode=logreplay_readaccess
Adición de un recurso de dirección IP virtual secundaria para una configuración activa/habilitada para lectura
Puede configurar la segunda IP virtual y las restricciones adicionales con los comandos siguientes. Si la instancia secundaria está fuera de servicio, la IP virtual secundaria se cambiará a la principal.
pcs property set maintenance-mode=true
pcs resource create secvip_HN1_03 ocf:heartbeat:IPaddr2 ip="10.23.0.19"
pcs resource create secnc_HN1_03 ocf:heartbeat:azure-lb port=62603
pcs resource group add g_secip_HN1_03 secnc_HN1_03 secvip_HN1_03
# RHEL 8.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote SAPHana_HN1_HDB03-clone then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave SAPHana_HN1_HDB03-clone 5
# RHEL 7.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote msl_SAPHana_HN1_HDB03 then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave msl_SAPHana_HN1_HDB03 5
pcs property set maintenance-mode=false
Asegúrese de que el estado del clúster sea ok y que todos los recursos se hayan iniciado. La segunda dirección IP virtual se ejecutará en el sitio secundario junto con el recurso secundario SAP HANA.
# Example output from crm_mon
#Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#
#Active resources:
#
#rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm
#Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1]
# Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03]
# Masters: [ hana-s1-db1 ]
# Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Resource Group: g_ip_HN1_03
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1
#Resource Group: g_secip_HN1_03
# secnc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1
# secvip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1
En la siguiente sección puede encontrar el conjunto típico de pruebas de conmutación por error que se va a ejecutar.
Al probar un clúster de HANA configurado con una secundaria habilitada para lectura, tenga en cuenta el comportamiento siguiente de la segunda dirección IP virtual:
Cuando el recurso de clúster SAPHana_HN1_HDB03 se mueve al sitio secundario (S2), la segunda IP virtual pasará al otro sitio, hana-s1-db1. Si ha configurado
AUTOMATED_REGISTER="false"y la replicación del sistema de HANA no se registra automáticamente, la segunda dirección IP virtual se ejecutará en hana-s2-db1.Al probar el bloqueo del servidor, los recursos de la segunda IP virtual (secvip_HN1_03) y el recurso de puerto de Azure Load Balancer (secnc_HN1_03) se ejecutarán en el servidor principal junto con los recursos de la IP virtual principal. Mientras el servidor secundario está inactivo, las aplicaciones que están conectadas a la base de datos de HANA habilitada para lectura se conectarán a la base de datos de HANA principal. Este comportamiento es normal. Permite que funcionen las aplicaciones conectadas a la base de datos HANA habilitada para la lectura mientras que un servidor secundario no está disponible.
Durante la conmutación por error y la reserva, se pueden interrumpir las conexiones existentes de las aplicaciones mediante la conexión de la segunda dirección IP virtual a la base de datos de HANA.
Prueba de la conmutación por error de SAP HANA
Antes de iniciar una prueba, compruebe el estado del clúster y de la replicación del sistema SAP HANA.
Compruebe que no haya acciones de clúster con errores.
#Verify that there are no failed cluster actions pcs status # Example #Stack: corosync #Current DC: hana-s-mm (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum #Last updated: Thu Sep 24 06:00:20 2020 #Last change: Thu Sep 24 05:59:17 2020 by root via crm_attribute on hana-s1-db1 # #7 nodes configured #45 resources configured # #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: # #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm #Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1Compruebe que la replicación del sistema SAP HANA esté sincronizada.
# Verify HANA HSR is in sync sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" #| Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary| Secondary | Secondary | Secondary | Replication | Replication | Replication | #| | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | #| -------- | ----------- | ----- | ------------ | --------- | ------- | --------- | ------------- | -------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | #| HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 2 | HANA_S1 | hana-s2-db3 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 2 | HANA_S1 | hana-s2-db2 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 2 | HANA_S1 | hana-s2-db1 | 30301 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 2 | HANA_S1 | hana-s2-db1 | 30307 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 2 | HANA_S1 | hana-s2-db1 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #status system replication site "1": ACTIVE #overall system replication status: ACTIVE #Local System Replication State #~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ #mode: PRIMARY #site id: 1 #site name: HANA_S1
Compruebe la configuración del clúster para un escenario de error, cuando un nodo pierde el acceso al recurso compartido de NFS (
/hana/shared).Los agentes de recursos de SAP HANA dependen de los archivos binarios, almacenados en
/hana/shared, para realizar operaciones durante la conmutación por error. El sistema de archivos/hana/sharedse monta en NFS en la configuración presentada. Una prueba que puede realizar, es crear una regla de firewall temporal para bloquear el acceso al sistema de archivos montado en NFS/hana/shareden una de las VM del sitio principal. Este enfoque valida que el clúster va a poder realizar la conmutación por error, si se pierde el acceso a/hana/shareden el sitio de replicación del sistema activo.Resultado esperado: al bloquear el acceso al sistema de archivos
/hana/sharedmontado en NFS en una de las VM del sitio principal, se producirá un error en la operación de supervisión que realiza la operación de lectura y escritura en el sistema de archivos, ya que no puede acceder al sistema de archivos y desencadenará la conmutación por error de recursos de HANA. Se espera el mismo resultado cuando el nodo de HANA pierde el acceso al recurso compartido de NFS.Para comprobar el estado de los recursos del clúster, ejecute
crm_monopcs status. Estado del recurso antes de iniciar la prueba:# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1Para simular un error para
/hana/shared:- Si usa NFS en ANF, confirme primero la dirección IP del volumen ANF
/hana/shareden el sitio primario. Para hacerlo, ejecutedf -kh|grep /hana/shared. - Si usa NFS en Azure Files, determine primero la dirección IP del punto de conexión privado de la cuenta de almacenamiento.
A continuación, configure una regla de firewall temporal para bloquear el acceso a la dirección IP del sistema de archivos NFS
/hana/sharedmediante la ejecución del siguiente comando en una de las VM del sitio de replicación del sistema principal de HANA.En este ejemplo, el comando se ejecutó en hana-s1-db1 para el volumen
/hana/sharedde ANF.iptables -A INPUT -s 10.23.1.7 -j DROP; iptables -A OUTPUT -d 10.23.1.7 -j DROPLa máquina virtual de HANA que perdió el acceso a
/hana/shareddebe reiniciarse o detenerse, en función de la configuración del clúster. Los recursos del clúster se migran al otro sitio de replicación del sistema HANA.Si el clúster no se ha iniciado en la máquina virtual, que se ha reiniciado, inicie el clúster mediante la ejecución de:
# Start the cluster pcs cluster startCuando se inicia el clúster, el sistema de archivos
/hana/sharedse montará automáticamente. Si estableceAUTOMATED_REGISTER="false", tendrá que configurar la replicación del sistema SAP HANA en el sitio secundario. En este caso, puede ejecutar estos comandos para volver a configurar SAP HANA como secundario.# Execute on the secondary su - hn1adm # Make sure HANA is not running on the secondary site. If it is started, stop HANA sapcontrol -nr 03 -function StopWait 600 10 # Register the HANA secondary site hdbnsutil -sr_register --name=HANA_S1 --remoteHost=hana-s2-db1 --remoteInstance=03 --replicationMode=sync # Switch back to root and clean up failed resources pcs resource cleanup SAPHana_HN1_HDB03El estado de los recursos, después de la prueba:
# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s2-db1 ] # Slaves: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1- Si usa NFS en ANF, confirme primero la dirección IP del volumen ANF
Se recomienda probar exhaustivamente la configuración del clúster de SAP HANA, también mediante la realización de pruebas, documentadas en Alta disponibilidad para SAP HANA en máquinas virtuales de Azure en RHEL.
Pasos siguientes
- Planeamiento e implementación de Azure Virtual Machines para SAP
- Implementación de Azure Virtual Machines para SAP
- Implementación de DBMS de Azure Virtual Machines para SAP
- Volúmenes NFS v4.1 en Azure NetApp Files para SAP HANA
- Para más información sobre cómo establecer la alta disponibilidad y planear la recuperación ante desastres de SAP HANA en VM de Azure, consulte Alta disponibilidad de SAP HANA en VM de Azure.