Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
El motor de ejecución nativo es una mejora innovadora para las ejecuciones de trabajos de Apache Spark en Microsoft Fabric. Este motor vectorizado optimiza el rendimiento y la eficiencia de las consultas de Spark ejecutándolas directamente en la infraestructura de tu lakehouse. Gracias a la fácil integración del motor, no es necesario realizar modificaciones de código y puede evitar el bloqueo del proveedor. Admite las API de Apache Spark y es compatible con runtime 1.3 (Apache Spark 3.5) y Runtime 2.0 (Apache Spark 4.1) y funciona con formatos Parquet, Delta y CSV. Independientemente de la ubicación de los datos en OneLake, o si accede a los datos a través de accesos directos, el motor de ejecución nativo maximiza la eficiencia y el rendimiento.
El motor de ejecución nativo mejora significativamente el rendimiento de las consultas al tiempo que minimiza los costos operativos. Los resultados reales varían según las características y la configuración de la carga de trabajo. El motor es capaz de administrar una amplia gama de escenarios de procesamiento de datos, que van desde la ingesta de datos rutinaria, los trabajos por lotes y las tareas ETL (extracción, transformación y carga) hasta los análisis complejos de ciencia de datos y las consultas interactivas con capacidad de respuesta. Los usuarios pueden beneficiarse de tiempos de procesamiento acelerados, un mayor rendimiento y un uso optimizado de recursos.
El motor de ejecución nativo se basa en dos componentes clave del OSS: Velox, una biblioteca de aceleración de bases de datos de C++ introducida por Meta y Apache Gluten (incubación), una capa intermedia responsable de descargar la ejecución de motores SQL basados en JVM en motores nativos introducidos por Intel.
Los operadores admitidos se descargan de Spark basado en JVM a una ruta de ejecución vectorizada en C++, ofreciendo procesamiento en columnas acelerado por SIMD con soporte nativo para los formatos Parquet y Delta. El motor nativo conserva las optimizaciones clave de consultas de Fabric Spark, incluida la ejecución de consultas adaptativa (AQE), las reescrituras basadas en costos, el recorte de columnas y la colocación de impulso de predicado, por lo que estos comportamientos del optimizador permanecen totalmente activos cuando los operadores se derivan. El motor también admite la carga de instantáneas delta paralelas y acelera las operaciones que se benefician de la ordenación Z y la agrupación en clústeres líquidos en tablas Delta, lo que proporciona mejoras de rendimiento adicionales para los diseños de datos organizados.
Cuándo usar el motor de ejecución nativo
El motor de ejecución nativo le ofrece una solución para ejecutar consultas en conjuntos de datos a gran escala; optimiza el rendimiento mediante las funcionalidades nativas de los orígenes de datos subyacentes y minimiza la sobrecarga que normalmente se asocia con el movimiento y la serialización de datos en entornos tradicionales de Spark. El motor admite varios operadores y tipos de datos, incluidos el agregado de hash acumulativo, la combinación de bucle anidado de difusión (BNLJ) y formatos de marca de tiempo precisos. Sin embargo, para beneficiarse completamente de las funcionalidades del motor, debe tener en cuenta sus casos de uso óptimos:
- El motor es eficaz al trabajar con datos que estén en los formatos Parquet y Delta; puede procesar estos formatos de forma nativa y eficaz.
- Las consultas que implican transformaciones y agregaciones complejas se benefician significativamente de las funcionalidades de procesamiento de columnas y vectorización del motor.
- La mejora del rendimiento es más notable en escenarios en los que las consultas no desencadenan el mecanismo de reserva, ya que así se evitan características o expresiones no admitidas.
- El motor es adecuado para las consultas que requieren un uso intensivo de cálculos, en lugar de consultas simples o enlazadas a E/S.
Para obtener información sobre los operadores y funciones compatibles con el motor de ejecución nativo, consulte la documentación de Apache Gluten.
Habilitación del motor de ejecución nativo
Para usar las funcionalidades completas del motor de ejecución nativo durante la fase de versión preliminar, necesita configuraciones específicas. En los procedimientos siguientes se muestra cómo activar esta característica para cuadernos, definiciones de trabajos de Spark y entornos completos.
Importante
El motor de ejecución nativo admite Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2) y Runtime 2.0 (Apache Spark 4.1, Delta Lake 4.1) .
Habilitar a nivel de entorno
Para garantizar una mejora uniforme del rendimiento, habilite el motor de ejecución nativo en todos los trabajos y cuadernos asociados a su entorno:
Vaya al área de trabajo que contiene su entorno y seleccione el entorno. Si no tiene el entorno creado, consulte Creación, configuración y uso de un entorno en Fabric.
En Proceso de Spark , seleccione Aceleración.
Active la casilla denominada Habilitar motor de ejecución nativo.
Guarde y publique los cambios.
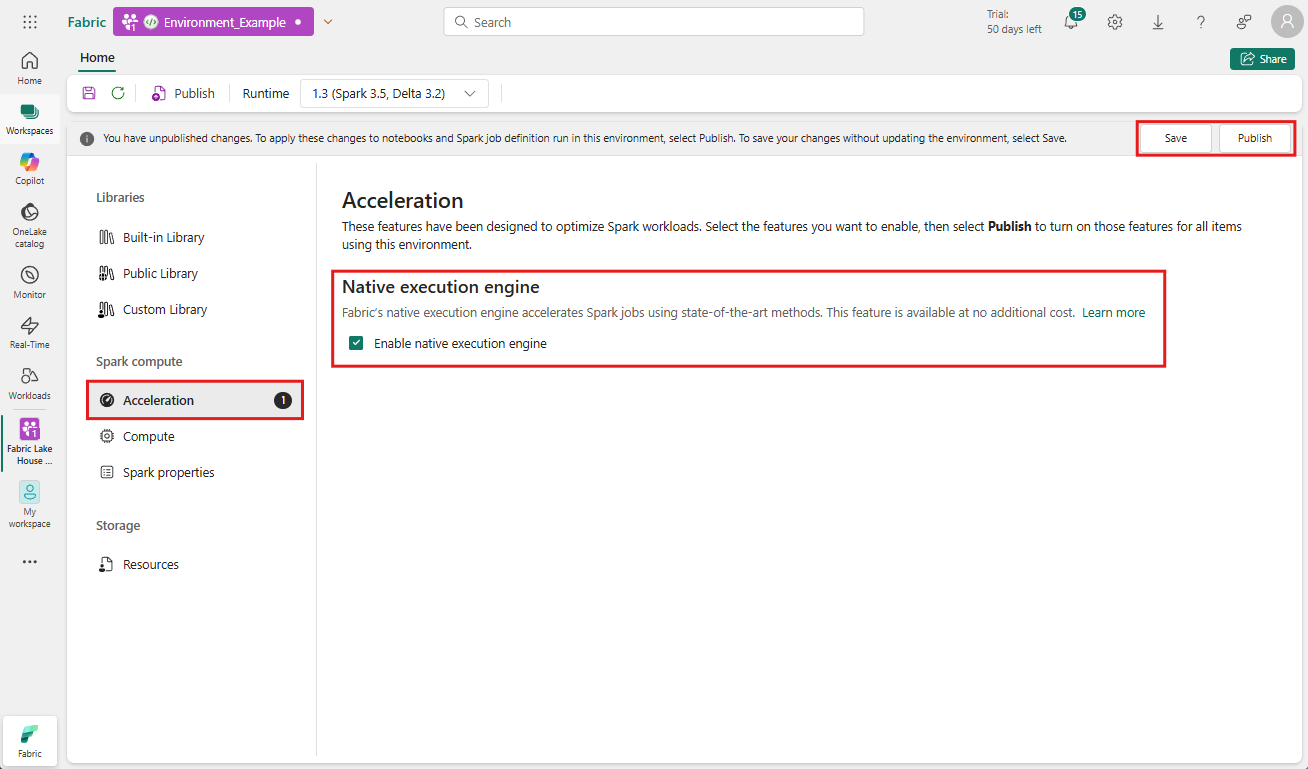

Cuando se habilita en el nivel de entorno, todos los trabajos y cuadernos posteriores heredan la configuración. Esta herencia garantiza que las nuevas sesiones o recursos creados en el entorno se beneficien automáticamente de las funcionalidades de ejecución mejoradas.
Importante
Anteriormente, el motor de ejecución nativo se habilitaba a través de la configuración de Spark dentro de la configuración del entorno. El motor de ejecución nativo ahora se puede habilitar más fácilmente mediante un interruptor en la pestaña Aceleración de la configuración del entorno. Para seguir usándolo, diríjase a la pestaña Aceleración y active el interruptor. También puede habilitarla a través de las propiedades de Spark si lo prefiere.
Habilitación de un cuaderno o definición de trabajo de Spark
También puede habilitar el motor de ejecución nativo para un único cuaderno o definición de trabajo de Spark, debe incorporar las configuraciones necesarias al principio del script de ejecución:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
En el caso de los cuadernos, inserte los comandos de configuración necesarios en la primera celda. En el caso de las definiciones de trabajo de Spark, incluya las configuraciones en la primera línea de la definición del trabajo de Spark. El motor de ejecución nativo se integra con los grupos activos, por lo que, una vez habilitada la característica, surte efecto inmediatamente sin necesidad de iniciar una nueva sesión.
Control en el nivel de consulta
Los mecanismos para habilitar el motor de ejecución nativo a nivel de inquilino, de área de trabajo y de entorno, integrados sin problemas con la interfaz de usuario, están en desarrollo activo. Mientras tanto, puede deshabilitar el motor de ejecución nativo para consultas específicas, especialmente si implican operadores que no se admiten actualmente (consulte limitaciones). Para deshabilitarlo, establezca la configuración de Spark spark.native.enabled en false en la celda específica que contiene la consulta.
%%sql
SET spark.native.enabled=FALSE;

Después de ejecutar la consulta en la que está deshabilitado el motor de ejecución nativo, debe volver a habilitarlo para las celdas posteriores estableciendo spark.native.enabled en true. Este paso es necesario porque Spark ejecuta celdas de código de manera secuencial.
%%sql
SET spark.native.enabled=TRUE;
Identificación de las operaciones ejecutadas por el motor
Hay varios métodos para determinar si un operador en tu tarea de Apache Spark se procesó mediante el motor de ejecución nativo.
Interfaz de usuario de Spark y servidor de historial de Spark
Acceda a la interfaz de usuario de Spark o al servidor de historial de Spark para buscar la consulta que quiere inspeccionar. Para acceder a la interfaz de usuario web de Spark, vaya a la definición del trabajo de Spark y ejecútelo. En la pestaña Ejecuciones, seleccione ... junto a Nombre de la aplicación y seleccione Abrir interfaz de usuario web de Spark. También puede acceder a la interfaz de usuario de Spark desde la pestaña Monitor del área de trabajo. Seleccione el cuaderno o la canalización, desde la página de monitorización, hay un enlace directo a la interfaz de usuario de Spark para los trabajos activos.

En el plan de consulta que se muestra en la interfaz de usuario de Spark, busque los nombres de nodo que terminan con el sufijo Transformer, *NativeFileScan o VeloxColumnarToRowExec. Este sufijo indica que el motor de ejecución nativo ejecutó la operación. Por ejemplo, los nodos pueden etiquetarse como RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer o BroadcastNestedLoopJoinExecTransformer. En el caso de los orígenes de datos CSV, los escaneos nativos pueden aparecer como nodos nativos de escaneo de archivos o nodos transformadores en Spark UI, de forma similar a los nodos de escaneo de Parquet y Delta.

Explicación de DataFrame
Como alternativa, puede ejecutar el comando df.explain() en el cuaderno para ver el plan de ejecución. En la salida, busque los mismos sufijos Transformer, *NativeFileScan o VeloxColumnarToRowExec. Este método proporciona una manera rápida de confirmar si el motor de ejecución nativo administra operaciones específicas.

Alertas de Fabric Spark Advisor
Fabric Spark Advisor proporciona visibilidad en tiempo real de reversiones durante la ejecución de celdas en el notebook. Cuando un operador o segmento del plan vuelve a Spark basado en JVM en lugar de la ruta de acceso nativa, Advisor muestra una alerta directamente en la salida de la celda del cuaderno de notas, lo que le ayuda a identificar rápidamente operadores o configuraciones no admitidos sin abandonar el cuaderno. Puede usar estas alertas para diagnosticar cuándo no se aplica la descarga nativa y decidir si se debe ajustar la consulta o la configuración.
Mecanismo de respaldo
En algunos casos, es posible que el motor de ejecución nativo no pueda ejecutar una consulta debido a motivos como características no admitidas. En estos casos, la operación vuelve al motor de Spark tradicional. Este mecanismo automático de respaldo garantiza que no haya interrupción en el proceso de trabajo.


Supervisión de consultas y operaciones de DataFrame ejecutadas por el motor
Para comprender mejor cómo se aplica el motor de ejecución nativa a las consultas SQL y a las operaciones de DataFrame, así como para explorar en profundidad los niveles de fase y operador, puede consultar la interfaz de usuario de Spark y el servidor de historial de Spark para obtener información más detallada sobre la ejecución del motor nativo.
Pestaña del motor de ejecución nativo
Puede ir a la nueva pestaña "Gluten SQL / DataFrame" para ver la información de compilación de Gluten y consultar los detalles de ejecución. La tabla de Consultas proporciona información sobre el número de nodos que se ejecutan en el motor Nativo y aquellos que recurren a la JVM para cada consulta.

Gráfico de ejecución de consultas
También puede seleccionar en la descripción de la consulta para la visualización del plan de ejecución de consultas de Apache Spark. El gráfico de ejecución proporciona detalles de la ejecución nativa en las distintas fases y sus respectivas operaciones. Los colores de fondo permiten distinguir los motores de ejecución: el verde representa el motor de ejecución nativo, mientras que el azul claro indica que la operación se está ejecutando en el motor de JVM predeterminado.

Limitaciones
Aunque el motor de ejecución nativo (NEE) de Microsoft Fabric aumenta significativamente el rendimiento de los trabajos de Apache Spark, actualmente tiene las siguientes limitaciones:
Limitaciones existentes
Características incompatibles de Spark: el motor de ejecución nativo no admite actualmente el streaming estructurado. Si las características no admitidas se usan directamente o a través de bibliotecas importadas, Spark vuelve a su motor predeterminado. Ahora se admiten las UDF de Python, las UDF de Scala y los tipos de datos complejos (arrays, mapas y estructuras). Para obtener más información, consulte UDF de Python, UDF de Scala y tipos de datos complejos en el motor de ejecución nativo.
Formatos de archivo no admitidos: Las consultas con
JSONyXMLformatos no son aceleradas por el motor de ejecución nativo. Estos valores predeterminados vuelven al motor JVM estándar de Spark para la ejecución. CSV ahora se admite a través del analizador CSV vectorizado.Modo ANSI no compatible: el motor de ejecución nativo no admite el modo SQL ANSI. Si está habilitada, la ejecución vuelve al motor Spark estándar.
Discordancia de tipos en el filtro de fecha: para beneficiarse de la aceleración del motor nativo de ejecución, asegúrese de que ambos lados de una comparación de fechas coincidan en el tipo de datos. Por ejemplo, en lugar de comparar una
DATETIMEcolumna con un literal de cadena, conviertala explícitamente como se muestra:CAST(order_date AS DATE) = '2024-05-20'
Otras consideraciones y limitaciones
Error de coincidencia de conversión decimal a float: Cuando se realiza la conversión de
DECIMALaFLOAT, Spark conserva la precisión mediante la conversión en una cadena y analizándola. NEE (a través de Velox) realiza una conversión directa desde la representación internaint128_t, lo que puede producir discrepancias de redondeo.Errores de configuración de zona horaria: si se establece una zona horaria no reconocida en Spark, se produce un error en el trabajo en NEE, mientras que Spark JVM lo controla correctamente. Por ejemplo:
"spark.sql.session.timeZone": "-08:00" // May cause failure under NEEComportamiento de redondeo incoherente: la
round()función se comporta de forma diferente en NEE debido a la dependencia destd::round, que no replica la lógica de redondeo de Spark. Esto puede provocar incoherencias numéricas en los resultados de redondeo.Falta la función de comprobación de claves duplicadas en la función
map(): Cuandospark.sql.mapKeyDedupPolicyse establece en EXCEPCIÓN, Spark produce un error para las claves duplicadas. NeE omite actualmente esta comprobación y permite que la consulta se realice incorrectamente.
Ejemplo:SELECT map(1, 'a', 1, 'b'); -- Should fail, but returns {1: 'b'}Varianza de orden en
collect_list()con ordenación: cuando se usaDISTRIBUTE BYySORT BY, Spark conserva el orden de los elementos encollect_list(). NEE puede devolver valores en un orden diferente debido a diferencias en el reordenamiento, lo que puede dar lugar a incompatibilidades con la lógica sensible al orden.Error de coincidencia de tipos intermedios para
collect_list()/collect_set(): Spark usaBINARYcomo tipo intermedio para estas agregaciones, mientras que NEE usa .ARRAYEsta falta de coincidencia puede provocar problemas de compatibilidad durante el planeamiento o la ejecución de consultas.Puntos de conexión privados administrados necesarios para el acceso al almacenamiento: cuando el motor de ejecución nativo (NEE) está habilitado y, si los trabajos de Spark intentan acceder a una cuenta de almacenamiento mediante un punto de conexión privado administrado, los usuarios deben configurar puntos de conexión privados administrados independientes para los puntos de conexión de Blob (blob.core.windows.net) y DFS /File System (dfs.core.windows.net), incluso si apuntan a la misma cuenta de almacenamiento. No se puede reutilizar un único punto de conexión para ambos. Se trata de una limitación actual y puede requerir una configuración de red adicional al habilitar el motor de ejecución nativo en un área de trabajo que tenga puntos de conexión privados administrados en cuentas de almacenamiento.
Contenido relacionado
- Introducción a Delta Lake en Microsoft Fabric
- UDF de Python, UDF de Scala y tipos de datos complejos en el motor de ejecución nativo
- Reducción de escala eficiente y gestor de shuffle remoto
- Runtimes de Apache Spark en Fabric
- ¿Qué es el ajuste automático para las configuraciones de Apache Spark en Fabric?