Configuración de Azure Synapse Analytics en una actividad de copia
En este artículo se describe cómo usar la actividad de copia en la canalización de datos para copiar datos de y hacia Azure Synapse Analytics.
Configuración admitida
Para la configuración de cada pestaña en la actividad de copia, vaya a las secciones siguientes respectivamente.
General
Consulte las instruccionesgenerales para configurar la pestaña de parámetros General.
Source
Las siguientes propiedades son compatibles con Azure Synapse Analytics en la pestaña Origen de una actividad de copia.

Se requieren las siguientes propiedades:
Tipo de almacén de datos: seleccione Externo.
Conexión: seleccione una conexión de Azure Synapse Analytics de la lista de conexiones. Si la conexión no existe, cree una nueva conexión de Azure Synapse Analytics seleccionando Nuevo.
Tipo de conexión: seleccione Azure Synapse Analytics.
Usar consulta: puede elegir Tabla, Consulta o Procedimiento almacenado para leer los datos de origen. La siguiente lista describe la configuración de cada opción:
Tabla: lea los datos de la tabla especificada en la Tabla si selecciona este botón. Seleccione la tabla en la lista desplegable o seleccione Editar para escribir manualmente el esquema y el nombre de la tabla.

Consulta: especifique la consulta SQL personalizada para leer los datos. Un ejemplo es
select * from MyTable. O seleccione el icono del lápiz para editar en el editor de código.
Procedimiento almacenado: use el procedimiento almacenado que lee los datos de la tabla de origen. La última instrucción SQL debe ser una instrucción SELECT del procedimiento almacenado.
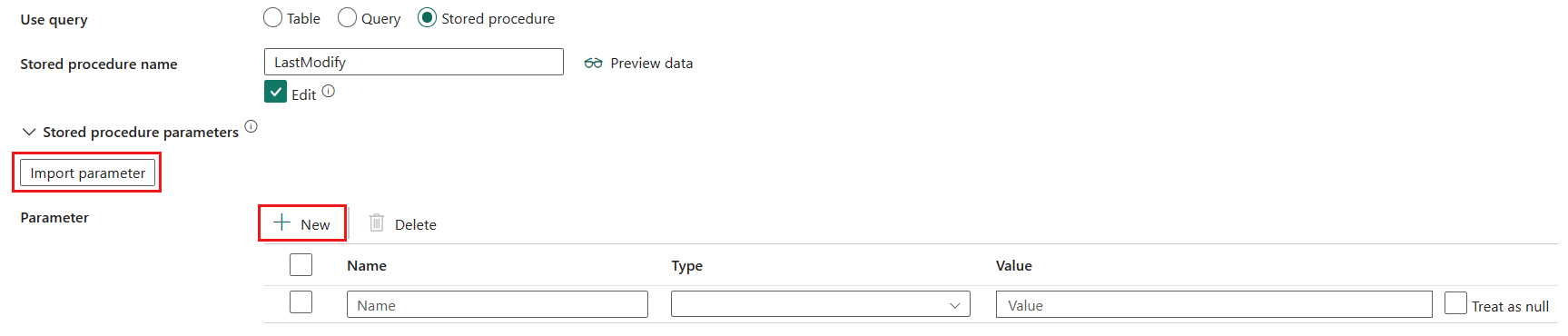
- Nombre del procedimiento almacenado: seleccione el procedimiento almacenado o especifique manualmente el nombre del procedimiento almacenado al seleccionar Editar.
- Parámetros de procedimiento almacenado: seleccione Importar parámetros para importar el parámetro en el procedimiento almacenado especificado o agregue parámetros al procedimiento almacenado seleccionando + Nuevo. Los valores permitidos son pares de nombre o valor. Los nombres y las mayúsculas y minúsculas de los parámetros deben coincidir con las mismas características de los parámetros de procedimiento almacenado.

En Avanzado, puede especificar los campos siguientes:
Tiempo de espera de consulta (minutos): especifique el tiempo de espera para la ejecución del comando de consulta; el valor predeterminado es de 120 minutos. Si se establece un parámetro para esta propiedad, los valores permitidos son intervalos de tiempo, como "02:00:00" (120 minutos).
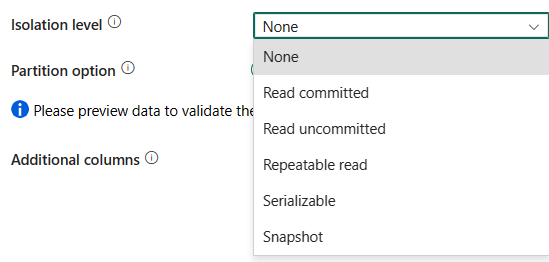
Nivel de aislamiento: especifica el comportamiento de bloqueo de transacciones para el origen de SQL. Los valores permitidos son: Ninguno, Lectura confirmada, Lectura no confirmada, Lectura repetible, Serializable o Captura de pantalla. Si no se especifica, se usa el nivel de aislamiento None. Consulte IsolationLevel Enum para obtener más detalles.
Opción de partición: especifique las opciones de partición de datos usadas para cargar datos de Azure Synapse Analytics. Los valores permitidos son: Ninguno (predeterminado), Particiones físicas de la tabla, y Rango dinámico. Cuando se habilita una opción de partición (es decir, que no es Ninguno), el grado de simultaneidad para cargar datos de una base de datos Azure Synapse Analytics se controla mediante la configuración copia en paralelo de la actividad de copia.
Ninguno: elija esta opción de configuración para no usar una partición.
Particiones físicas de la tabla: elija esta configuración si desea usar una partición física. La columna de partición y el mecanismo se determinan automáticamente en función de la definición de tabla física.
Rango dinámico: elija esta opción si desea usar la partición de rango dinámico. Cuando se usa la consulta con la opción paralela habilitada, se necesita el parámetro de partición por rangos (
?DfDynamicRangePartitionCondition). Consulta de ejemplo:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.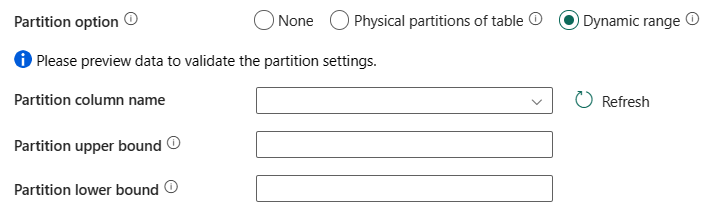
- Nombre de la columna de origen: especifique el nombre de la columna de origen de tipo entero o fecha/hora (
int,smallint,bigint,date,smalldatetime,datetime,datetime2odatetimeoffset) que usa la partición de rangos para la copia paralela. Si no se especifica, el índice o la clave primaria de la tabla se detectan automáticamente y se usan como columna de partición. - Límite superior de la partición: especifique el valor máximo de la columna de partición para la división del rango de partición. Este valor se usa para decidir el intervalo de particiones, no para filtrar las filas de la tabla. Se crean particiones de todas las filas de la tabla o el resultado de la consulta y se copian.
- Límite inferior de la partición: especifique el valor mínimo de la columna de partición para la división del rango de partición. Este valor se usa para decidir el intervalo de particiones, no para filtrar las filas de la tabla. Se crean particiones de todas las filas de la tabla o el resultado de la consulta y se copian.
- Nombre de la columna de origen: especifique el nombre de la columna de origen de tipo entero o fecha/hora (
Columnas adicionales: agregue columnas de datos adicionales a la ruta de acceso relativa o al valor estático de los archivos de origen. La expresión se admite para este último. Para más información, vaya a Agregar columnas adicionales durante la copia.
Destination
Las siguientes propiedades son compatibles con Azure Synapse Analytics en la pestaña Destino de una actividad de copia.
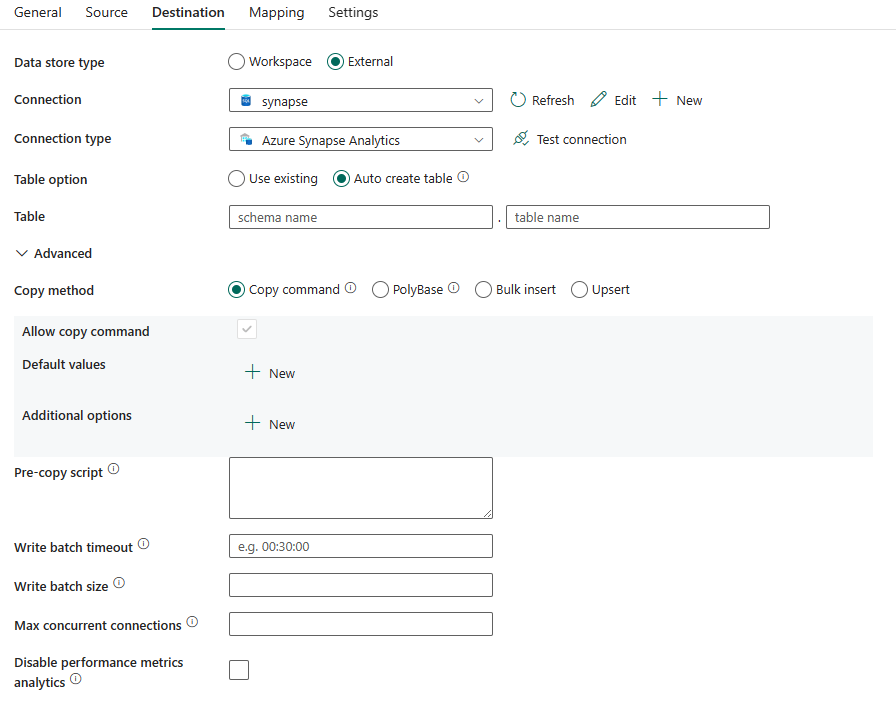
Se requieren las siguientes propiedades:
- Tipo de almacén de datos: seleccione Externo.
- Conexión: seleccione una conexión de Azure Synapse Analytics de la lista de conexiones. Si la conexión no existe, cree una nueva conexión de Azure Synapse Analytics seleccionando Nuevo.
- Tipo de conexión: seleccione Azure Synapse Analytics.
- Opción tabla: puede elegir Usar existente y Crear tabla automáticamente. La siguiente lista describe la configuración de cada opción:
- Usar existente: seleccione la tabla de la base de datos en la lista desplegable. O bien, active Editar para escribir el nombre de la tabla manualmente.
- Crear tabla automáticamente: crea automáticamente la tabla (si no existe) en el esquema de origen.
En Avanzado, puede especificar los campos siguientes:
Método copia: elija el método que desea usar para copiar datos. Puede elegir Copiar comando, PolyBase, Inserción masiva o Upsert. La siguiente lista describe la configuración de cada opción:
Copiar comando: Use la instrucción COPY para cargar datos de Azure Storage en Azure Synapse Analytics o en un grupo de SQL.
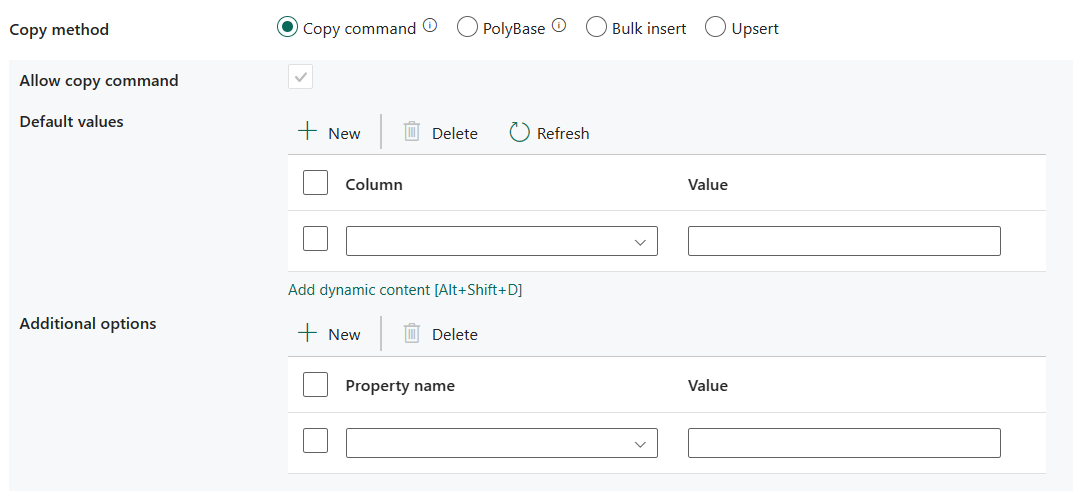
- Permitir comando de copia: es obligatorio seleccionarlo al elegir Copiar comando.
- Valores predeterminados: especifica los valores predeterminados para cada columna de destino en Azure Synapse Analytics. Los valores predeterminados de la propiedad sobrescriben el conjunto de restricciones predeterminado en el almacenamiento de datos, y la columna de identidad no puede tener un valor predeterminado.
- Opciones adicionales: opciones adicionales que se pasarán directamente a la instrucción COPY de Azure Synapse Analytics en la cláusula "With" de la instrucción COPY. Incluye el valor entre comillas si es necesario para ajustarlo a los requisitos de la instrucción COPY.
PolyBase: PolyBase es un mecanismo de alto rendimiento. Úselo para cargar grandes cantidades de datos en Azure Synapse Analytics o un grupo de SQL.
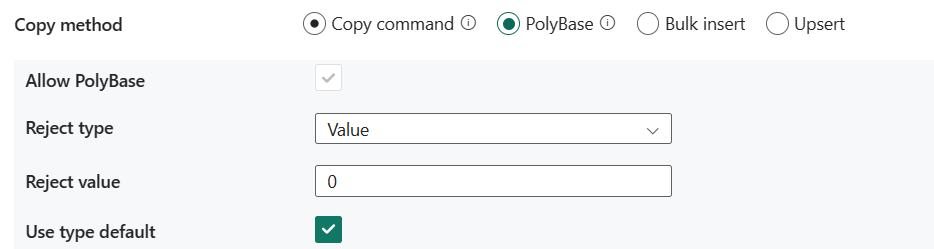
- Permitir PolyBase: es obligatorio seleccionarlo al elegir PolyBase.
- Tipo de rechazo: especifica si la opción rejectValue es un valor literal o un porcentaje. Los valores permitidos son Value (valor predeterminado) y Percentage.
- Valor de rechazo: especifica el número o porcentaje de filas que se pueden rechazar antes de que se produzca un error en la consulta. Más información sobre las opciones de rechazo de PolyBase en la sección Argumentos de CREATE EXTERNAL TABLE (Transact-SQL). Los valores permitidos son 0 (valor predeterminado), 1, 2, etc.
- Valor de rechazo de muestra: determina el número de filas que se van a recuperar antes de que PolyBase vuelva a calcular el porcentaje de filas rechazadas. Los valores permitidos son 1, 2, etc. Si elige Porcentaje como tipo de rechazo, se requiere esta propiedad.
- Tipo de uso predeterminado: especifica cómo administrar los valores que faltan en archivos de texto delimitado cuando PolyBase recupera datos del archivo de texto. Más información sobre esta propiedad en la sección de argumentos de CREATE EXTERNAL FILE FORMAT (Transact-SQL). Los valores permitidos están seleccionados (valor predeterminado) o no.
Inserción masiva: use inserción masiva para insertar datos en el destino de forma masiva.

- Bloqueo de tabla de la inserción masiva: úselo para mejorar el rendimiento de la copia durante la operación de inserción masiva en una tabla sin índice de varios clientes. Obtenga más información en INSERCIÓN MASIVA (Transact-SQL).
Upsert: especifique el grupo de la configuración para el comportamiento de escritura cuando desee actualizar los datos al destino.
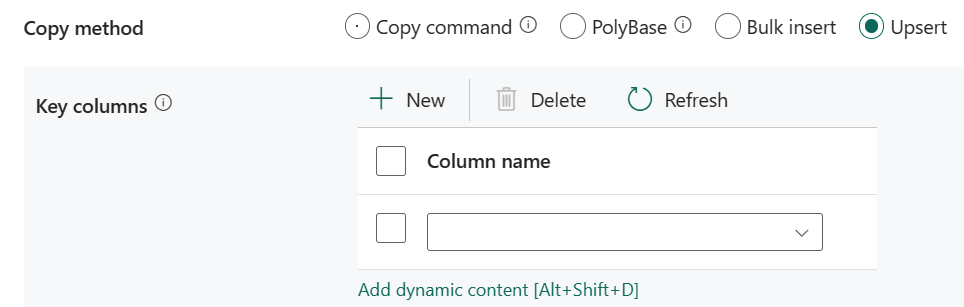
Columnas clave: elija qué columna se usa para determinar si una fila del origen coincide con una fila del destino.
Bloqueo de tabla de la inserción masiva: úselo para mejorar el rendimiento de la copia durante la operación de inserción masiva en una tabla sin índice de varios clientes. Obtenga más información en INSERCIÓN MASIVA (Transact-SQL).
Script de copia previa: especifique un script para que la actividad de copia se ejecute antes de escribir datos en una tabla de destino en cada ejecución. Puede usar esta propiedad para limpiar los datos cargados previamente.
Tiempo de espera de escritura por lotes: especifique el tiempo que se concede a la operación de inserción por lotes para que finalice antes de que se agote el tiempo de espera. El valor permitido es timespan. El valor predeterminado es "00:30:00" (30 minutos).
Tamaño del lote de escritura: especifique el número de filas a insertar en la tabla SQL por lote. El valor que se permite es un entero (número de filas). De manera predeterminada, el servicio determina dinámicamente el tamaño adecuado del lote en función del tamaño de fila.
Máximo de conexiones simultáneas: especifique el límite superior de conexiones simultáneas establecidas con el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas.
Deshabilitar el análisis de métricas de rendimiento: esta configuración se usa para recopilar métricas, como DTU, DWU, RU, etc., para la optimización del rendimiento de la copia y las recomendaciones. Si le preocupa este comportamiento, active esta casilla. No está seleccionado de forma predeterminada.
Copia directa mediante el comando COPY
El comando COPY de Azure Synapse Analytics admite directamente Azure Blob Storage y Azure Data Lake Storage Gen2 como almacenes de datos de origen. Si los datos de origen cumplen los criterios descritos en esta sección, use el comando COPY para copiar directamente desde el almacén de datos de origen a Azure Synapse Analytics.
Los datos de origen y el formato contienen los siguientes tipos y métodos de autenticación:
Tipo de almacén de datos de origen admitido Formato admitido Tipo de autenticación de origen admitido Azure Blob Storage Texto delimitado
ParquetAutenticación anónima
Autenticación de clave de cuenta
Autenticación con firma de acceso compartidoAzure Data Lake Storage Gen2 Texto delimitado
ParquetAutenticación de clave de cuenta
Autenticación con firma de acceso compartidoSe puede establecer la siguiente configuración de formato:
- Para Parquet: el tipo de compresión puede ser Ninguno, snappy o gzip.
- Para DelimitedText:
- Delimitador de fila: al copiar texto delimitado en Azure Synapse Analytics mediante el comando COPY, especifique el delimitador de fila explícitamente (\r; \n; o \r\n). Solo cuando el delimitador de filas del archivo de origen es \r\n, el valor predeterminado (\r, \n o \r\n) funciona. De lo contrario, habilite el almacenamiento provisional para su escenario.
- El valor null se deja como valor predeterminado o se establece en cadena vacía ("").
- La codificación se deja como valor predeterminado o se establece en UTF-8 o UTF-16.
- El número de líneas ignoradas se deja como predeterminado o se establece en 0.
- El tipo de compresión puede ser Ninguno o gzip.
Si el origen es una carpeta, debe activar la casilla Recursivamente.
La Hora de inicio (UTC) y la Hora de finalización (UTC) en Filtrar por última modificación, Prefijo, Habilitar detección de particiones y Columnas adicionales no se especifican.
Para obtener información sobre cómo ingerir datos en el Azure Synapse Analytics mediante el comando COPY, consulte este artículo.
Si el formato y el almacén de datos de origen no es compatible originalmente con el comando COPY, use en su lugar la característica Copia almacenada provisionalmente mediante el comando COPY. Convierte automáticamente los datos en un formato compatible con el comando COPY y, a continuación, llama a un comando COPY para cargar datos en Azure Synapse Analytics.
Asignación
Para la configuración de la pestaña Asignación, si no aplica Azure Synapse Analytics con tabla de creación automática como destino, vaya a Asignación.
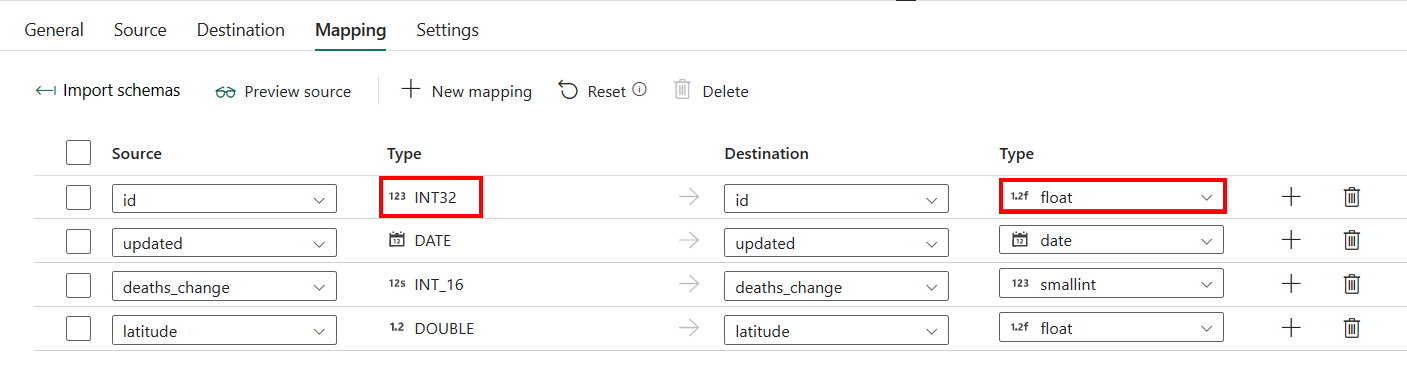
Si aplica Azure Synapse Analytics con auto crear tabla como su destino, excepto la configuración en Asignación, puede editar el tipo para sus columnas de destino. Después de seleccionar Importar esquemas, puede especificar el tipo de columna en el destino.
Por ejemplo, el tipo de la columna ID de origen es int y puede cambiarlo a tipo float al asignarlo a la columna de destino.
Configuración
Para la configuración de la pestañaConfiguración, vaya a Configurar los otros parámetros en la ficha Configuración .
Copia en paralelo desde Azure Synapse Analytics
En la actividad de copia, el conector de Azure Synapse Analytics proporciona creación de particiones de datos integrada para copiar los datos en paralelo. Puede encontrar las opciones de creación de particiones de datos en la pestaña Origen de la actividad de copia.
Al habilitar la copia con particiones, la actividad de copia ejecuta consultas en paralelo en el origen de Azure Synapse Analytics para cargar los datos por particiones. El grado paralelo se controla mediante el grado de paralelismo de copia en la pestaña configuración de la actividad de copia. Por ejemplo, si establece grado de paralelismo de copia en cuatro, el servicio genera y ejecuta simultáneamente cuatro consultas basadas en la configuración y la opción de partición especificadas, y cada consulta recupera una parte de los datos de su Azure Synapse Analytics.
Es recomendable habilitar la copia en paralelo con creación de particiones de datos, especialmente si se cargan grandes cantidades de datos de Azure Synapse Analytics. Estas son algunas configuraciones sugeridas para diferentes escenarios. Cuando se copian datos en un almacén de datos basado en archivos, se recomienda escribirlos en una carpeta como varios archivos (solo especifique el nombre de la carpeta), en cuyo caso el rendimiento es mejor que escribirlos en un único archivo.
| Escenario | Configuración sugerida |
|---|---|
| Carga completa de una tabla grande con particiones físicas. | Opción de partición: particiones físicas de la tabla. Durante la ejecución, el servicio detecta automáticamente las particiones físicas y copia los datos por particiones. Para comprobar si la tabla tiene una partición física o no, puede hacer referencia a esta consulta. |
| Carga completa de una tabla grande, sin particiones físicas, aunque con una columna de tipo entero o datetime para la creación de particiones de datos. | Opciones de partición: partición por rangos dinámica. Columna de partición (opcional): especifique la columna usada para crear la partición de datos. Si no se especifica, se usa la columna de índice o clave principal. Límite de partición superior y límite de partición inferior (opcional): especifique si quiere determinar el intervalo de la partición. No es para filtrar las filas de la tabla, se crean particiones de todas las filas de la tabla y se copian. Si no se especifica, la actividad de copia detecta automáticamente los valores. Por ejemplo, si la columna de partición "ID" tiene valores que van de 1 a 100 y establece el límite inferior en 20 y el superior en 80, con la copia en paralelo establecida en 4, el servicio recupera los datos en 4 particiones: identificadores del rango <=20, del rango [21, 50], del rango [51, 80] y del rango >=81, respectivamente. |
| Carga de grandes cantidades de datos mediante una consulta personalizada, sin particiones físicas, aunque con una columna de tipo entero o date/datetime para la creación de particiones de datos. | Opciones de partición: partición por rangos dinámica. Consulta: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Columna de partición: especifique la columna usada para crear la partición de datos. Límite de partición superior y límite de partición inferior (opcional): especifique si quiere determinar el intervalo de la partición. No es para filtrar las filas de la tabla, se crean particiones de todas las filas del resultado de la consulta y se copian. Si no se especifica, la actividad de copia detecta automáticamente el valor. Por ejemplo, si la columna de partición "ID" tiene valores que van de 1 a 100 y establece el límite inferior en 20 y el superior en 80, con la copia en paralelo establecida en 4, el servicio recupera los datos en 4 particiones: identificadores del rango <=20, del rango [21, 50], del rango [51, 80] y del rango >=81, respectivamente. A continuación se muestran más consultas de ejemplo para distintos escenarios: • Consulta de la tabla completa: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Consulta de una tabla con selección de columnas y filtros adicionales de la cláusula where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Consulta con subconsultas: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Consulta con partición en subconsulta: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Procedimientos recomendados para cargar datos con la opción de partición:
- Seleccione una columna distintiva como columna de partición (como clave principal o clave única) para evitar la asimetría de datos.
- Si la tabla tiene una partición integrada, use la opción de partición Particiones físicas de tabla para obtener un mejor rendimiento.
- Azure Synapse Analytics puede ejecutar un máximo de 32 consultas en un momento dado; si el Grado de paralelismo de copia se establece en un número demasiado grande, puede producirse un problema de límite de Synapse.
Consulta de ejemplo para comprobar la partición física
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Si la tabla tiene una partición física, verá "HasPartition" como "yes".
Resumen de tabla
Las tablas siguientes contienen más información sobre la actividad de copia en Azure Synapse Analytics.
Source
| Nombre | Descripción | Value | Obligatorio | Propiedad de script JSON |
|---|---|---|---|---|
| Tipo de almacén de datos | El tipo de almacén de datos. | Externo | Sí | / |
| Connection | La conexión al almacén de datos de origen. | < su conexión > | Sí | conexión |
| Tipo de conexión | El tipo de conexión de origen. | Azure Synapse Analytics | Sí | / |
| Usar consulta | La manera de leer datos. | • Tabla • Consulta • Procedimiento almacenado |
Sí | • typeProperties (en typeProperties ->source)- esquema - tabla • sqlReaderQuery • sqlReaderStoredProcedureName storedProcedureParameters - nombre - valor |
| Tiempo de espera de la consulta | El tiempo de espera para la ejecución del comando de consulta, el valor predeterminado es de 120 minutos. | timespan | No | queryTimeout |
| Nivel de aislamiento | El comportamiento de bloqueo de transacción para el origen de SQL. | • Ninguno • Lectura confirmada • Lectura no confirmada • Lectura repetible • Serializable • Snapshot |
No | isolationLevel: • ReadCommitted • ReadUncommitted • RepeatableRead • Serializable • Snapshot |
| Opción de partición | Las opciones de creación de particiones de datos que se usan para cargar datos desde Azure SQL Database. | • None • Particiones físicas de la tabla • Intervalo dinámico - Nombre de columna de partición - Límite superior de partición - Límite inferior de partición |
No | partitionOption: • PhysicalPartitionsOfTable • DynamicRange partitionSettings: - partitionColumnName - partitionUpperBound - partitionLowerBound |
| Columnas adicionales | Agregue columnas de datos adicionales para almacenar la ruta de acceso relativa o el valor estático de los archivos de origen. La expresión se admite para este último. | • Name • Valor |
No | additionalColumns: • nombre • value |
Destination
| Nombre | Descripción | Value | Obligatorio | Propiedad de script JSON |
|---|---|---|---|---|
| Tipo de almacén de datos | El tipo de almacén de datos. | Externo | Sí | / |
| Connection | La conexión al almacén de datos de destino. | < su conexión > | Sí | conexión |
| Tipo de conexión | Tipo de conexión de destino. | Azure Synapse Analytics | Sí | / |
| Opción de tabla | Opción de tabla de datos de destino. | • Usar existente • Crear tabla automáticamente |
Sí | • typeProperties (en typeProperties ->sink)- esquema - tabla • tableOption: - autoCreate typeProperties (en typeProperties ->sink)- esquema - tabla |
| Método de copia | Método utilizado para copiar datos. | • Comando COPY • PolyBase • Inserción masiva • Upsert |
No | / |
| Al seleccionar el comando copy | Use el comando COPY para cargar datos de Azure Storage en Azure Synapse Analytics o en un grupo de SQL. | / | No. Se aplica cuando se usa COPY. |
allowCopyCommand: sí copyCommandSettings |
| Valores predeterminados | Especifica los valores predeterminados para cada columna de destino en Azure Synapse Analytics. Los valores predeterminados de la propiedad sobrescriben el conjunto de restricciones predeterminado en el almacenamiento de datos, y la columna de identidad no puede tener un valor predeterminado. | < valores predeterminados > | No | defaultValues: • columnName • defaultValue |
| Opciones adicionales | Opciones adicionales que se pasarán directamente a la instrucción COPY de Azure Synapse Analytics en la cláusula "With" de la instrucción COPY. Incluye el valor entre comillas si es necesario para ajustarlo a los requisitos de la instrucción COPY. | < opciones adicionales > | No | additionalOptions: - <nombre de propiedad>: <valor> |
| Al seleccionar PolyBase | PolyBase es un mecanismo de alto rendimiento. Úselo para cargar grandes cantidades de datos en Azure Synapse Analytics o un grupo de SQL. | / | No. Se aplica cuando se usa PolyBase. |
allowPolyBase: sí polyBaseSettings |
| Tipo de rechazo | Tipo del valor de rechazo. | • Valor • Porcentaje |
No | rejectType: - valor - Porcentaje |
| Valor de rechazo | Especifica el número o porcentaje de filas que se pueden rechazar antes de que se produzca un error en la consulta. | 0 (predeterminado), 1, 2, etc. | No | rejectValue |
| Valor de muestra de rechazo | Determina el número de filas que se van a recuperar antes de que PolyBase vuelva a calcular el porcentaje de filas rechazadas. | 1, 2, etc. | Sí cuando se especifica Porcentaje como tipo de rechazo | rejectSampleValue |
| Usar tipo predeterminado | Especifica cómo administrar valores que faltan en archivos de texto delimitado cuando PolyBase recupera los datos del archivo de texto. Más información sobre esta propiedad en la sección de argumentos de CREAR FORMATO DE ARCHIVO EXTERNO (Transact-SQL) | Seleccionado (valor predeterminado) o no seleccionado. | No | useTypeDefault: true (valor predeterminado) o false |
| Al seleccionar Inserción masiva | Inserte datos en el destino de forma masiva. | / | No | writeBehavior: Insertar |
| Bloqueo de tabla de inserción masiva | Úselo para mejorar el rendimiento de la copia durante la operación de inserción masiva en una tabla sin índice de varios clientes. Obtenga más información en INSERCIÓN MASIVA (Transact-SQL). | seleccionado o no seleccionado (valor predeterminado) | No | sqlWriterUseTableLock: true o false (valor predeterminado) |
| Al seleccionar Upsert | Especifica el grupo de la configuración para el comportamiento de escritura cuando desee actualizar los datos al destino. | / | No | writeBehavior: upsert |
| Columnas de clave | Indica qué columna se usa para determinar si una fila del origen coincide con una fila del destino. | <nombre de la columna> | No | upsertSettings: - claves: < nombre de columna > - interimSchemaName |
| Bloqueo de tabla de inserción masiva | Úselo para mejorar el rendimiento de la copia durante la operación de inserción masiva en una tabla sin índice de varios clientes. Obtenga más información en INSERCIÓN MASIVA (Transact-SQL). | seleccionado o no seleccionado (valor predeterminado) | No | sqlWriterUseTableLock: true o false (valor predeterminado) |
| Pre-copy script (Script anterior a la copia) | Un script para que la actividad de copia se ejecute antes de escribir datos en una tabla de destino en cada ejecución. Puede usar esta propiedad para limpiar los datos cargados previamente. | < script anterior a la copia > (string) |
No | preCopyScript |
| Tiempo de espera de escritura por lotes | Tiempo que se concede a la operación de inserción por lotes para que finalice antes de que se agote el tiempo de espera. El valor permitido es TimeSpan. El valor predeterminado es "00:30:00" (30 minutos). | timespan | No | writeBatchTimeout |
| Tamaño del lote de escritura | Número de filas que se va a insertar en la tabla SQL por lote. De manera predeterminada, el servicio determina dinámicamente el tamaño adecuado del lote en función del tamaño de fila. | < número de filas > (entero) |
No | writeBatchSize |
| Número máximo de conexiones simultáneas | Número máximo de conexiones simultáneas establecidas en el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas. | < límite superior de conexiones simultáneas > (entero) |
No | maxConcurrentConnections |
| Desactivar análisis de métricas de rendimiento | Esta configuración se usa para recopilar métricas, como DTU, DWU, RU, etc., para la optimización del rendimiento de la copia y las recomendaciones. Si le preocupa este comportamiento, active esta casilla. | seleccionar o anular la selección (valor predeterminado) | No | disableMetricsCollection: true o false (valor predeterminado) |
Contenido relacionado
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de