Direct Lake
El modo Direct Lake es una funcionalidad de modelo semántico que se usa para analizar volúmenes de datos muy grandes en Power BI. Direct Lake se basa en la carga de archivos con formato Parquet directamente desde un almacén de lago sin tener que consultar un punto de conexión de almacén o lago y sin tener que importar o duplicar datos en un modelo de Power BI. Direct Lake es una ruta rápida para cargar los datos del lago directamente en el motor de Power BI, listos para su análisis. En el diagrama siguiente se muestra cómo los modos clásicos de importación y DirectQuery se comparan con el modo Direct Lake.
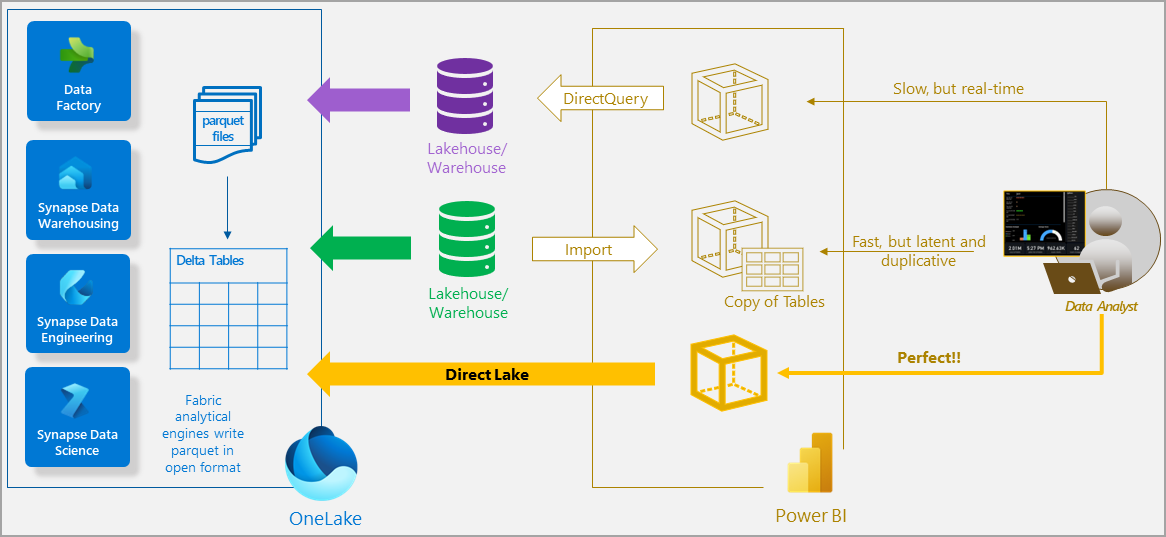
En el modo DirectQuery, el motor de Power BI consulta los datos en el origen, lo que puede ser lento, pero evita tener que copiar los datos como con el modo de importación. Los cambios en el origen de datos se reflejan inmediatamente en los resultados de la consulta.
Por otro lado, con el modo de importación, el rendimiento puede ser mejor porque los datos se almacenan en caché y se optimizan para las consultas de informes DAX y MDX sin tener que traducir y pasar SQL u otros tipos de consultas al origen de datos. Sin embargo, el motor de Power BI debe copiar primero todos los datos nuevos en el modelo durante la actualización. Los cambios en el origen solo se seleccionan con la próxima actualización del modelo.
El modo Direct Lake elimina el requisito de importación cargando los datos directamente desde OneLake. A diferencia de DirectQuery, no hay traducción desde DAX o MDX a otros lenguajes de consulta o ejecución de consultas en otros sistemas de base de datos, lo que produce un rendimiento similar al del modo de importación. Al no haber un proceso de importación explícito, es posible recoger los cambios en el origen de datos a medida que se producen, combinando las ventajas de los modos de importación y DirectQuery y evitando sus desventajas. El modo Direct Lake puede ser la opción ideal para analizar modelos muy grandes y modelos con actualizaciones frecuentes en el origen de datos.
Direct Lake también admite seguridad de nivel de fila de Power BI y seguridad de nivel de objeto para que los usuarios solo vean los datos que tienen permiso para ver.
Requisitos previos
Direct Lake solo se admite en SKU Microsoft Premium (P) y Microsoft Fabric (F).
Importante
Para los clientes nuevos, Direct Lake solo se admite en SKU Microsoft Fabric (F). Los clientes existentes pueden seguir usando Direct Lake con SKU Premium (P), pero se recomienda realizar la transición a una SKU de capacidad de Fabric. Consulte el anuncio de licencias para obtener más información sobre las licencias de Power BI Premium.
Lakehouse
Antes de usar Direct Lake, debe aprovisionar un almacén de lago (o almacén) con una o varias tablas Delta en un área de trabajo hospedada en una capacidad compatible de Microsoft Fabric. El almacén de lago es necesario porque proporciona una ubicación de almacenamiento para los archivos con formato parquet en OneLake.
Para aprender a aprovisionar un almacén de lago, crear una tabla Delta en el lago y crear un modelo básico para el lago, consulte Creación de un almacén de lago para Direct Lake.
Punto de conexión de análisis y almacenamiento de datos SQL
Como parte del aprovisionamiento de un almacén de lago, se crea un punto de conexión análisis SQL para consultas SQL y se actualiza con cualquier tabla agregada al almacén de lago. Aunque el modo Direct Lake no consulta el punto de conexión de análisis SQL al cargar datos directamente desde OneLake, es necesario cuando un modelo de Direct Lake debe revertir sin problemas al modo DirectQuery, como cuando el origen de datos usa características específicas como la seguridad avanzada o las vistas que no se pueden leer a través de Direct Lake. Además, deben usar el punto de conexión de SQL. El modo Direct Lake también consulta de forma periódica el punto de conexión SQL para obtener información relacionada con el esquema y la seguridad.
Como alternativa a un almacén de lago con el punto de conexión de análisis SQL, también puede aprovisionar un almacén y agregar tablas mediante instrucciones SQL o canalizaciones de datos. El procedimiento para aprovisionar un almacenamiento de datos independiente es casi idéntico al procedimiento de un almacén de lago.
Modelo semántico predeterminado de Power BI
Los almacenes y los puntos de conexión de análisis de SQL también crean un modelo semántico de Power BI predeterminado en modo Direct Lake. Este modelo semántico predeterminado solo se puede editar dentro del almacén o el punto de conexión de SQL y tiene limitaciones adicionales. Consulte la documentación del modelo semántico predeterminado de Power BI. Esta documentación de Direct Lake es para modelos semánticos de Power BI no predeterminados en modo Direct Lake.
Creación de un nuevo modelo semántico de Power BI en modo Direct Lake
Los modelos semánticos de Power BI en el modo Direct Lake se crean en el almacén de lago o en el almacén.
En Lakehouse, haga clic en Nuevo modelo semántico de Power BI para crear un modelo semántico de Power BI en modo Direct Lake.
En el almacén o el punto de conexión de análisis SQL, seleccione la cinta Informes y, después, seleccione Nuevo modelo semántico de Power BI para crear un modelo semántico de Power BI en modo Direct Lake.
A continuación, puede agregar relaciones, medidas, grupos de cálculos, cadenas de formato, seguridad de nivel de fila, etc., y cambiar el nombre de tablas y columnas editando el modelo semántico en el explorador. Edite el modelo semántico más adelante mediante el menú contextual del área de trabajo para abrir el modelo de datos.
Compatibilidad con escritura de modelos con el punto de conexión XMLA
Los modelos de Direct Lake admiten operaciones de escritura a través del punto de conexión XMLA mediante herramientas como SQL Server Management Studio (19.1 y versiones posteriores) y las versiones más recientes de herramientas de BI externas, como Tabular Editor y DAX Studio. Las operaciones de escritura de modelos a través del punto de conexión XMLA admiten:
Personalización, combinación, scripting, depuración y pruebas de metadatos de modelos de Direct Lake.
Control de código fuente y versiones, integración continua e implementación continua (CI/CD) con Azure DevOps y GitHub.
Tareas de automatización como la actualización y la aplicación de cambios en modelos de Direct Lake mediante PowerShell y las API de REST.
Tenga en cuenta que las tablas de Direct Lake creadas mediante aplicaciones XMLA estarán inicialmente en un estado no procesado hasta que la aplicación emita un comando de actualización. Las tablas no procesadas vuelven al modo DirectQuery. Al crear un nuevo modelo semántico, asegúrese de actualizarlo para procesar las tablas.
Habilitación de lectura y escritura de XMLA
Antes de realizar operaciones de escritura en modelos de Direct Lake a través del punto de conexión XMLA, la lectura y escritura de XMLA debe estar habilitada para la capacidad.
En el caso de las capacidades de prueba de Fabric, el usuario de prueba tiene los privilegios de administrador necesarios para habilitar XMLA de lectura y escritura.
En el portal de administración, seleccione Configuración de capacidad.
Seleccione la pestaña Prueba.
Seleccione la capacidad con Prueba y el nombre de usuario en el nombre de la capacidad.
Expanda Cargas de trabajo de Power BI y, a continuación, en la configuración Punto de conexión XMLA, seleccione Lectura y escritura.
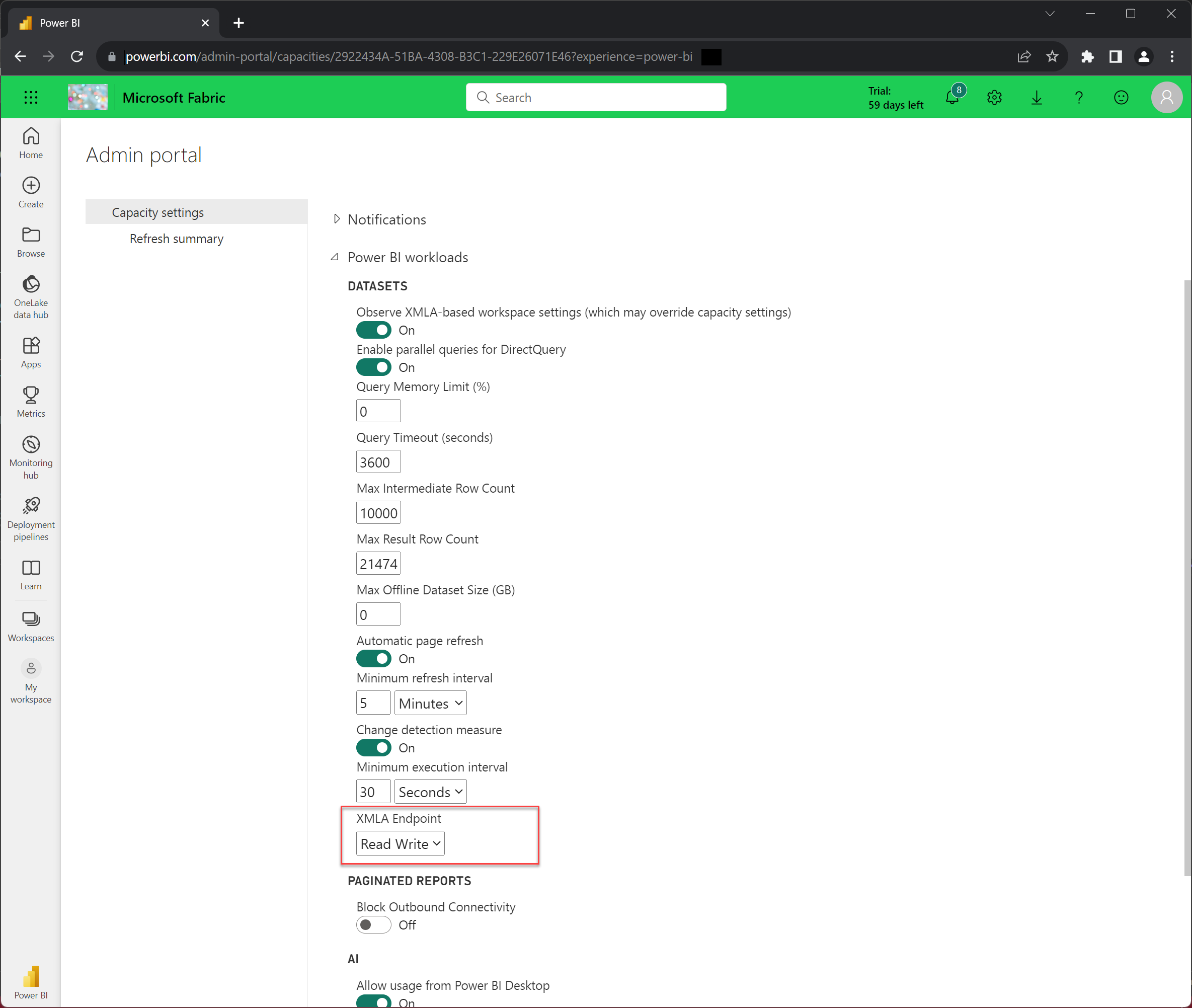
Tenga en cuenta que el parámetro de la propiedad del punto de conexión de XMLA se aplica a todas las áreas de trabajo y modelos asignados a la capacidad.
Metadatos del modelo de Direct Lake
Al conectarse a un modelo de Direct Lake independiente a través del punto de conexión XMLA, los metadatos son similares a cualquier otro modelo. Sin embargo, los conjuntos de datos de Direct Lake muestran las siguientes diferencias:
La propiedad
compatibilityLeveldel objeto de base de datos es 1604 o superior.La propiedad
Modede las particiones de Direct Lake se establece endirectLake.Las particiones de Direct Lake usan expresiones compartidas para definir orígenes de datos. La expresión apunta al punto de conexión SQL de una instancia de almacén de lago o almacén. Direct Lake usa el punto de conexión de SQL para detectar información de esquemas y seguridad, pero carga los datos directamente desde las tablas Delta (a menos que Direct Lake deba recurrir al modo DirectQuery por cualquier motivo).
Esta es una consulta XMLA de ejemplo en SSMS:
Para obtener más información sobre la compatibilidad con herramientas a través del punto de conexión XMLA, consulte Conectividad del modelo semántico con el punto de conexión XMLA.
Tema alternativo
Los modelos semánticos de Power BI en el modo Direct Lake leen tablas Delta directamente desde OneLake. Sin embargo, si una consulta DAX en un modelo de Direct Lake supera los límites de la SKU o usa características que no admiten el modo Direct Lake, como las vistas SQL de un almacén, la consulta puede revertir al modo DirectQuery. En el modo DirectQuery, las consultas usan SQL para recuperar los resultados del punto de conexión SQL del lago o almacén, lo que puede afectar al rendimiento de las consultas. Puede deshabilitar la reserva en modo DirectQuery si desea procesar consultas DAX solo en modo Direct Lake puro. Se recomienda deshabilitar la reserva si no necesita reserva en DirectQuery. También puede resultar útil al analizar el procesamiento de consultas de un modelo de Direct Lake para identificar si se producen reservas y con qué frecuencia. Para obtener más información sobre el modo DirectQuery, consulte Modos de modelo semántico en Power BI.
Los límites de protección definen los límites de recursos para el modo Direct Lake más allá del cual es necesaria una reserva al modo DirectQuery para procesar consultas DAX. Para obtener más información sobre cómo determinar el número de archivos Parquet y grupos de filas de una tabla Delta, consulte la referencia de propiedades de la tabla Delta.
En el caso de los modelos semánticos de Direct Lake, MaxMemory representa el límite superior de recursos de memoria para la cantidad de datos que se pueden paginar. En efecto, no es un límite de protección porque superarlo no causa una reserva a DirectQuery; sin embargo, puede tener un impacto en el rendimiento si la cantidad de datos es lo suficientemente grande como para provocar la paginación y salida de los datos del modelo de los datos de OneLake.
En la tabla siguiente se enumeran los límites de protección de recursos y memoria máxima:
| SKU de Fabric | Archivos Parquet por tabla | Grupos de filas por tabla | Filas por tabla (millones) | Tamaño máximo del modelo en disco/OneLake1 (GB) | Memoria máxima (GB) |
|---|---|---|---|---|---|
| F2 | 1,000 | 1,000 | 300 | 10 | 3 |
| F4 | 1,000 | 1,000 | 300 | 10 | 3 |
| F8 | 1,000 | 1,000 | 300 | 10 | 3 |
| F16 | 1,000 | 1,000 | 300 | 20 | 5 |
| F32 | 1,000 | 1,000 | 300 | 40 | 10 |
| F64/FT1/P1 | 5\.000 | 5\.000 | 1500 | Sin límite | 25 |
| F128/P2 | 5\.000 | 5\.000 | 3,000 | Sin límite | 50 |
| F256/P3 | 5\.000 | 5\.000 | 6,000 | Sin límite | 100 |
| F512/P4 | 10 000 | 10,000 | 12,000 | Sin límite | 200 |
| F1024/P5 | 10 000 | 10 000 | 24,000 | Sin límite | 400 |
| F2048 | 10 000 | 10 000 | 24,000 | Sin límite | 400 |
1: si se supera, el tamaño máximo del modelo en el disco o Onelake hará que todas las consultas al modelo se reserven en DirectQuery, a diferencia de otros límites de protección que se evalúan por consulta.
En función de la SKU de Fabric, también se aplican límites adicionales de unidad de capacidad y memoria máxima por consulta a los modelos de Direct Lake. Para más información, consulte Capacidades y SKU.
Comportamiento de reserva
Los modelos de Direct Lake incluyen la propiedad DirectLakeBehavior, que tiene tres opciones:
Automático: (valor predeterminado) especifica que las consultas se revierten al modo DirectQuery si los datos no se pueden cargar eficazmente en la memoria.
DirectLakeOnly: especifica que todas las consultas solo usan el modo Direct Lake. La reserva en modo DirectQuery está deshabilitada. Si los datos no se pueden cargar en la memoria, se devolverá un error. Use esta configuración para determinar si las consultas DAX no pueden cargar los datos en la memoria, lo que obliga a devolver un error.
DirectQueryOnly: especifica que todas las consultas solo usan el modo DirectQuery. Use esta configuración para probar el rendimiento de reserva.
La propiedad DirectLakeBehavior se puede configurar mediante el modelo de objetos tabulares (TOM) o el lenguaje de scripting de modelos tabulares (TMSL).
En el ejemplo siguiente se especifica que todas las consultas solo usan el modo Direct Lake:
// Disable fallback to DirectQuery mode.
//
database.Model.DirectLakeBehavior = DirectLakeBehavior.DirectLakeOnly = 1;
database.Model.SaveChanges();
Esto también se puede establecer al editar el modelo semántico en el explorador en las propiedades del modelo semántico. Seleccione Modelo semántico en la pestaña Modelo del panel Datos.

Análisis del procesamiento de consultas
Para determinar si las consultas DAX de un objeto visual de informe en el origen de datos proporcionan el mejor rendimiento mediante el modo Direct Lake o recurriendo al modo DirectQuery, puede usar el analizador de rendimiento en Power BI Desktop, SQL Server Profiler u otras herramientas de terceros para analizar las consultas. Para más información, consulte Analizar el procesamiento de consultas para modelos de Direct Lake.
Refresh
De forma predeterminada, los cambios de datos en OneLake se reflejan automáticamente en un modelo de Direct Lake. Para cambiar este comportamiento, deshabilite Mantener actualizados los datos de Direct Lake en la configuración del modelo.

Podría querer deshabilitar si, por ejemplo, debería permitir la finalización de trabajos de preparación de datos antes de exponer cualquier nuevo dato a los consumidores del modelo. Cuando está deshabilitado, puede invocar la actualización manualmente o mediante las API de actualización. Invocar una actualización para un modelo de Direct Lake es una operación de bajo coste donde el modelo analiza los metadatos de la versión más reciente de la tabla de Delta Lake y se actualiza para hacer referencia a los archivos más recientes de OneLake.
Tenga en cuenta que Power BI puede pausar las actualizaciones automáticas de tablas de Direct Lake si encuentra un error no recuperable durante la actualización, por lo que debe asegurarse de que el modelo semántico se pueda actualizar correctamente. Power BI reanudará automáticamente las actualizaciones automáticas cuando se complete sin errores una actualización posterior invocada por el usuario.
Inicio de sesión único (SSO) habilitado de manera predeterminada
De manera predeterminada, los modelos de Direct Lake dependen del inicio de sesión único (SSO) de Microsoft Entra para acceder a los orígenes de datos del almacén de lago de Fabric y del almacén y usar la identidad del usuario que interactúa actualmente con el modelo. Para comprobar la configuración en la configuración del modelo de Direct Lake, expanda la sección Conexiones de puerta de enlace y nube que se muestra en la captura de pantalla siguiente. El modelo de Direct Lake no requiere una conexión de datos explícita, ya que el almacén de lago o el almacén es accesible de forma directa, y el inicio de sesión único (SSO) elimina la necesidad de tener credenciales de conexión almacenadas.
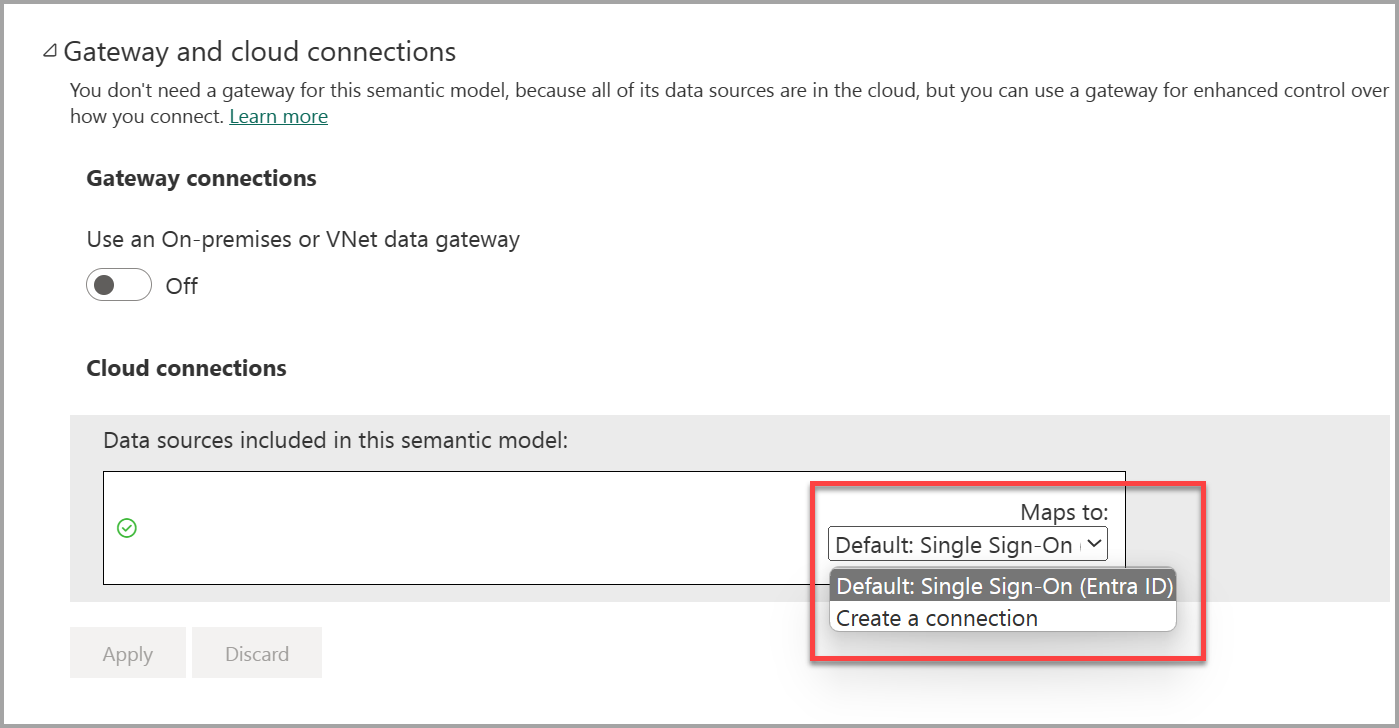
Si quiere usar las credenciales almacenadas y, por tanto, deshabilitar el inicio de sesión único de la conexión del origen de datos, también puede enlazar explícitamente ese origen de datos del almacén de lago o del almacén a una conexión en la nube (SCC) que se pueda compartir. Para enlazar explícitamente el origen de datos, seleccione una SCC del cuadro de lista Asignar a: en la sección Conexiones de puerta de enlace y nube. Si quiere crear una nueva conexión, seleccione Crear una conexión y, a continuación, siga los pasos para proporcionar un nombre de conexión. A continuación, seleccione OAuth 2.0 como método de autenticación de la nueva conexión, escriba las credenciales deseadas y desactive la casilla Inicio de sesión único; a continuación, enlace el origen de datos del almacén de lago o del almacén a la nueva conexión SCC que acaba de crear.
La configuración de conexión Predeterminada: Inicio de sesión único (Entra ID) simplifica la configuración del modelo de Direct Lake; sin embargo, si ya tiene una conexión personal en la nube (PCC) al origen de datos del almacén de datos o del almacén, el modelo de Direct Lake se enlaza automáticamente a la PCC coincidente para que la configuración de conexión que ya haya definido en el origen de datos se aplique inmediatamente. Debe confirmar la configuración de conexión de los modelos de Direct Lake para asegurarse de que estos acceden a sus orígenes de datos de Fabric con la configuración correcta.
Los modelos semánticos pueden usar la configuración de conexión Predeterminada: Inicio de sesión único (Entra ID) en almacenes de lago y almacenes de Fabric en el modo Direct Lake, Import y DirectQuery. Debe definir conexiones de datos explícitas en el resto de orígenes de datos.
Seguridad de acceso a datos en capas
Los modelos de Direct Lake creados sobre almacenes de lago y almacenamientos se adhieren al modelo de seguridad en capas que admiten almacenes de lago y almacenamientos mediante la realización de comprobaciones de permisos a través del punto de conexión de T-SQL para determinar si la identidad que intenta acceder a los datos tiene los permisos de acceso necesarios a los datos. De forma predeterminada, los modelos de Direct Lake usan el inicio de sesión único (SSO), por lo que los permisos efectivos del usuario interactivo determinan si se permite o se deniega el acceso al usuario a los datos. Si el modelo de Direct Lake está configurado para usar una identidad fija, el permiso efectivo de la identidad fija determina si los usuarios que interactúan con el modelo semántico pueden acceder a los datos. El punto de conexión de T-SQL devuelve Permitido o Denegado al modelo de Direct Lake en función de la combinación de seguridad de OneLake y permisos SQL.
Por ejemplo, un administrador de almacenamiento puede conceder a un usuario permisos SELECT en una tabla para que pueda leerla incluso si no tiene permisos de seguridad de OneLake. El usuario se autorizó en el nivel de almacén de lago o almacenamiento. Por el contrario, un administrador de almacenamiento también puede DENEGAR el acceso de lectura de un usuario a una tabla. A continuación, el usuario no podrá leer esa tabla incluso si el usuario tiene permisos de lectura de seguridad de OneLake. La instrucción DENY invalida los permisos de seguridad o SQL de OneLake concedidos. Consulte la siguiente tabla para obtener los permisos efectivos que un usuario puede haber proporcionado cualquier combinación de permisos de seguridad y SQL de OneLake.
| Permisos de seguridad de OneLake | Permisos de SQL | Permisos efectivos |
|---|---|---|
| Permitir | None | Permitir |
| None | Permitir | Allow |
| Permitir | Denegar | Denegar |
| None | Denegar | Denegar |
Problemas y limitaciones conocidos
Por diseño, solo las tablas del modelo semántico derivadas de las tablas de una instancia de almacén de lago o de almacén admiten el modo Direct Lake. Aunque las tablas del modelo se pueden derivar de vistas SQL en el almacén de lago o en el almacén, las consultas que usan esas tablas volverán al modo DirectQuery.
Las tablas del modelo semántico de Direct Lake solo se pueden derivar de tablas y vistas de una sola instancia de almacén de lago o de almacén. Una sola instancia de Lakehouse puede incluir accesos directos agregados desde otros Lakehouses.
Las consultas que usan la seguridad de nivel de fila en las tablas del almacenamiento (incluido el punto de conexión de análisis SQL de Lakehouse) se revertirán al modo DirectQuery.
Las tablas de Direct Lake no se pueden mezclar actualmente con otros tipos de tabla, como Import, DirectQuery o Dual, en el mismo modelo. Los modelos compuestos en modelos semánticos de Power BI pueden usar modelos semánticos de Power BI en el modo de almacenamiento de Direct Lake como origen.
Las relaciones DateTime no se admiten en modelos de Direct Lake. Se admiten las relaciones de fecha.
No se admiten columnas calculadas ni tablas calculadas. Se admiten grupos de cálculo y parámetros de campo.
Es posible que algunos tipos de datos no se admitan, como los decimales de alta precisión y algunos tipos de dinero.
Las tablas de Direct Lake no admiten tipos de columnas de tabla Delta complejas. Los tipos semánticos binarios y guid tampoco se admiten. Debe convertir estos tipos de datos en cadenas u otros tipos de datos admitidos.
Las relaciones de tabla requieren que los tipos de datos de sus columnas de clave coincidan. Las columnas de clave principal deben contener valores únicos. Se producirá un error en las consultas DAX si se detectan valores de clave principal duplicados.
La longitud de los valores de columna de cadena está limitada a 32 764 caracteres Unicode.
El valor de punto flotante "NaN" (no un número) no se admite en los modelos de Direct Lake.
Todavía no se admiten escenarios de Power BI Embedded que se basan en entidades integradas.
La validación está limitada a los modelos de Direct Lake. Se supone que las selecciones del usuario son correctas y ninguna consulta validará la cardinalidad y las selecciones de filtro cruzado para las relaciones, o para la columna de fecha seleccionada en una tabla de fechas.
La pestaña Direct Lake del historial de actualizaciones solo enumera los errores de actualización relacionados con Direct Lake. Las actualizaciones correctas se omiten actualmente.
Introducción
La mejor manera de empezar a trabajar con una solución de Direct Lake en su organización es crear una instancia de almacén de lago, crear una tabla Delta en ella y, a continuación, crear un modelo semántico básico para un almacén de lago en el área de trabajo de Microsoft Fabric. Para obtener más información, consulte Creación de un almacén de lago para Direct Lake.
Contenido relacionado
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de