Introducción a la implementación de aplicaciones en Clústeres de macrodatos de SQL Server
Se aplica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
El complemento Clústeres de macrodatos de Microsoft SQL Server 2019 se va a retirar. La compatibilidad con Clústeres de macrodatos de SQL Server 2019 finalizará el 28 de febrero de 2025. Todos los usuarios existentes de SQL Server 2019 con Software Assurance serán totalmente compatibles con la plataforma, y el software se seguirá conservando a través de actualizaciones acumulativas de SQL Server hasta ese momento. Para más información, consulte la entrada de blog sobre el anuncio y Opciones de macrodatos en la plataforma Microsoft SQL Server.
La implementación de la aplicación permite la implementación de aplicaciones en Clústeres de macrodatos de SQL Server proporcionando interfaces para crear, administrar y ejecutar aplicaciones. Las aplicaciones implementadas en un clúster de macrodatos se benefician de la capacidad de cálculo del clúster y pueden tener acceso a los datos que están disponibles en el clúster. Esto aumenta la escalabilidad y el rendimiento de las aplicaciones, al tiempo que se administran las aplicaciones en las que residen los datos. Los tiempos de ejecución de aplicaciones compatibles en los Clústeres de macrodatos de SQL Server son R, Python, dtexec y MLeap.
En las secciones siguientes se describe la arquitectura y las funciones de la implementación de la aplicación.
Arquitectura de implementación de la aplicación
La implementación de la aplicación consta de un controlador y controladores de tiempo de ejecución de la aplicación. Al crear una aplicación, se proporciona un archivo de especificación (spec.yaml). Este archivo spec.yaml contiene todo lo que el controlador necesita saber para implementar correctamente la aplicación. A continuación se muestra un ejemplo del contenido de spec.yaml:
#spec.yaml
name: add-app #name of your python script
version: v1 #version of the app
runtime: Python #the language this app uses (R or Python)
src: ./add.py #full path to the location of the app
entrypoint: add #the function that will be called upon execution
replicas: 1 #number of replicas needed
poolsize: 1 #the pool size that you need your app to scale
inputs: #input parameters that the app expects and the type
x: int
y: int
output: #output parameter the app expects and the type
result: int
El controlador inspecciona el runtime especificado en el archivo spec.yaml y llama al controlador en tiempo de ejecución correspondiente. El controlador en tiempo de ejecución crea la aplicación. En primer lugar, se crea un conjunto ReplicaSet de Kubernetes que contiene uno o varios pods, cada uno de los cuales contiene la aplicación que se va a implementar. El número de pods se define mediante el parámetro replicas establecido en el archivo spec.yaml de la aplicación. Cada pod puede tener uno o más grupos. El número de grupos se define mediante el parámetro poolsize establecido en el archivo spec.yaml.
Esta configuración determina la cantidad de solicitudes que puede controlar la implementación en paralelo. El número máximo de solicitudes en un momento dado es igual a replicas veces poolsize. Si tiene 5 réplicas y 2 grupos por réplica, la implementación puede administrar 10 solicitudes en paralelo. Vea la imagen a continuación para obtener una representación gráfica de replicas y poolsize:
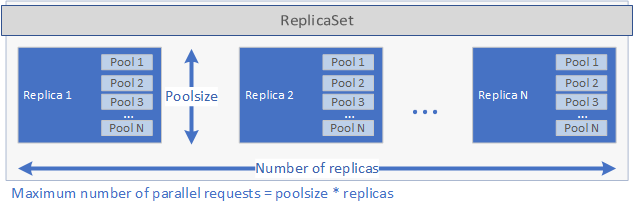
Una vez que se ha creado el conjunto ReplicaSet y se han iniciado los pods, se crea un trabajo cron si se ha establecido schedule en el archivo spec.yaml. Por último, se crea un servicio de Kubernetes que se puede usar para administrar y ejecutar la aplicación (consulte a continuación).
Cuando se ejecuta una aplicación, el servicio Kubernetes de la aplicación envía por proxy las solicitudes a una réplica y devuelve los resultados.
Consideraciones de seguridad para las implementaciones de aplicaciones en OpenShift
SQL Server 2019 CU5 permite implementar BDC en Red Hat OpenShift y un modelo de seguridad actualizado para BDC, de modo que ya no se necesiten contenedores con privilegios. Además de que ya no necesiten privilegios, los contenedores se ejecutan como un usuario que no es de raíz de manera predeterminada para todas las implementaciones nuevas mediante SQL Server 2019 CU5.
En el momento del lanzamiento de la versión CU5, el paso de instalación de las aplicaciones implementadas con las interfaces de implementación de la aplicación se seguirá ejecutando como usuario raíz. Esto es necesario, ya que durante la configuración se instalan paquetes adicionales que usará la aplicación. Otro código de usuario implementado como parte de la aplicación se ejecutará como usuario con pocos privilegios.
Además, CAP_AUDIT_WRITE es una capacidad opcional necesaria para permitir la programación de aplicaciones de SQL Server Integration Services (SSIS) mediante trabajos cron. Cuando el archivo de especificación YAML de la aplicación especifica una programación, la aplicación se desencadena mediante un trabajo cron, que necesita la capacidad adicional. Como alternativa, la aplicación se puede desencadenar a petición con azdata app run mediante una llamada de servicio web, que no requiere la capacidad CAP_AUDIT_WRITE. Tenga en cuenta que la capacidad CAP_AUDIT_WRITE no es necesaria para cronjob a partir de la versión SQL Server 2019 CU8.
Nota:
El SCC personalizado en el artículo de implementación de OpenShift no incluye esta capacidad, ya que no es necesaria para una implementación predeterminada de BDC. Para habilitar esta capacidad, primero debe actualizar el archivo YAML de SCC personalizado para que incluya CAP_AUDIT_WRITE.
...
allowedCapabilities:
- SETUID
- SETGID
- CHOWN
- SYS_PTRACE
- AUDIT_WRITE
...
Cómo trabajar con la implementación de aplicaciones en clústeres de macrodatos
Las dos interfaces principales de la implementación de la aplicación son las siguientes:
- Interfaz de la línea de comandos - CLI de Azure Data (
azdata) - Extensión de Visual Studio Code y Azure Data Studio
También es posible ejecutar una aplicación mediante un servicio web de RESTful. Para más información, consulte Consumo de aplicaciones en clústeres de macrodatos.
Escenarios de implementación de aplicaciones
La implementación de aplicaciones permite proporcionar interfaces para crear, administrar y ejecutar aplicaciones, de modo que se puedan implementar aplicaciones en un BDC de SQL Server.
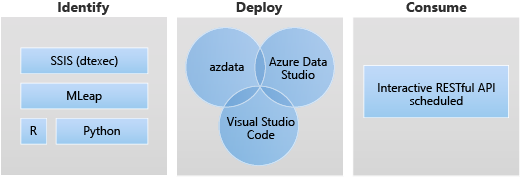
Los escenarios de destino para la implementación de aplicaciones son los siguientes:
- Implementación de servicios web de Python o R en el clúster de macrodatos para abordar diversos casos de uso, como la inferencia de aprendizaje automático, el servicio de API, etc.
- Creación de un punto de conexión de inferencia de aprendizaje automático mediante el motor de MLeap.
- Programación y ejecución de paquetes desde archivos DTSX mediante la utilidad dtexec para transformar y mover datos.
Uso del entorno de ejecución de Python de implementación de aplicaciones
En la implementación de aplicaciones, el entorno de ejecución de Python para BDC permite el acceso de la aplicación Python al clúster de macrodatos a fin de abordar diversos casos de uso, como la inferencia de aprendizaje automático o el servicio de API, entre otros.
El entorno de ejecución de Python de implementación de aplicaciones usa Python 3.8 en SQL Server Big Data Clusters CU10 y versiones posteriores.
En la implementación de aplicaciones, es en spec.yaml donde se proporciona la información que el controlador debe saber para implementar la aplicación. Los campos que se pueden especificar son los siguientes:
name: el nombre de la aplicación.version: la versión de la aplicación, por ejemplo,v1.runtime: el entorno de ejecución de implementación de la aplicación, debe especificarse comoPython.src: la ruta de acceso a la aplicación Python.entry point: la función de punto de entrada en el script src se va a ejecutar para esta aplicación Python.
Además de lo anterior, se debe especificar la entrada y salida de la aplicación Python. Esto genera un archivo spec.yaml similar al siguiente:
#spec.yaml
name: add-app
version: v1
runtime: Python
src: ./add.py
entrypoint: add
replicas: 1
poolsize: 1
inputs:
x: int
y: int
output:
result: int
Puede crear la estructura básica de carpetas y archivos necesaria para implementar una aplicación Python que se ejecute en Clústeres de macrodatos:
azdata app init --template python --name hello-py --version v1
Para los siguientes pasos, vea Cómo implementar una aplicación en Clústeres de macrodatos de SQL Server .
Limitaciones del entorno de ejecución de Python para la implementación de aplicaciones
El entorno de ejecución de Python para la implementación de aplicaciones no admite el escenario de programación. Una vez que la aplicación de Python esté implementada y en funcionamiento en el clúster de macrodatos, se configura un punto de conexión RESTful para escuchar las solicitudes entrantes.
Uso del entorno de ejecución de R de implementación de aplicaciones
En la implementación de aplicaciones, el entorno de ejecución Python de BDC permite el acceso de la aplicación de R al clúster de macrodatos para abordar diversos casos de uso, como la inferencia de aprendizaje automático o el servicio de API, entre otros.
El entorno de ejecución de R de implementación de aplicaciones usa Microsoft R Open (MRO) versión 3.5.2 en SQL Server Big Data Clusters CU10 y versiones posteriores.
Cómo usarlo
En la implementación de aplicaciones, es en spec.yaml donde se proporciona la información que el controlador debe saber para implementar la aplicación. Los campos que se pueden especificar son los siguientes:
name: el nombre de la aplicación.version: la versión de la aplicación, por ejemplo,v1.runtime: el entorno de ejecución de implementación de la aplicación, debe especificarse comoR.src: la ruta de acceso a la aplicación R.entry point: el punto de entrada para ejecutar esta aplicación R.
Además de lo anterior, debe especificar la entrada y salida de la aplicación R. Esto genera un archivo spec.yaml similar al siguiente:
#spec.yaml
name: roll-dice
version: v1
runtime: R
src: ./roll-dice.R
entrypoint: rollEm
replicas: 1
poolsize: 1
inputs:
x: integer
output:
result: data.fram
Puede crear la carpeta básica y la estructura de archivos necesarias para implementar una nueva aplicación R mediante el siguiente comando:
azdata app init --template r --name hello-r --version v1
Para los siguientes pasos, vea Cómo implementar una aplicación en Clústeres de macrodatos de SQL Server.
Limitaciones del entorno de ejecución de R
Estas limitaciones se alinean con Microsoft R Application Network, que se retiró el 1 de julio de 2023. Para obtener más información y soluciones alternativas, consulte Retirada de Microsoft R Application Network.
Uso del entorno de ejecución dtexec de implementación de aplicaciones
En la implementación de aplicaciones, el entorno de ejecución del clúster de macrodatos integraba la utilidad dtexec, que es de SSIS en Linux (mssql-server-is). La implementación de aplicaciones usa la utilidad dtexec para cargar paquetes desde archivos *.dtsx. Admite la ejecución de paquetes SSIS en programación de estilo cron o a petición mediante solicitudes de servicio web.
Esta característica usa /opt/ssis/bin/dtexec /FILE de SQL Server 2019 Integration Service en Linux. Admite el formato dtsx para SQL Server 2019 Integration Service en Linux (mssql-server-is 15.0.2). Para obtener más información sobre la utilidad dtexec, vea dtexec (utilidad).
En la implementación de aplicaciones, es en spec.yaml donde se proporciona la información que el controlador debe saber para implementar la aplicación. Los campos que se pueden especificar son los siguientes:
name:namede la aplicación.version: la versión de la aplicación, por ejemplo,v1.runtime: el entorno de ejecución de implementación de la aplicación, para ejecutar la utilidad dtexec debe especificarse comoSSIS.entrypoint: especifique un punto de entrada, en nuestro caso suele ser el archivo .dtsx.options: especifique opciones adicionales para/opt/ssis/bin/dtexec /FILE, por ejemplo, para conectarse a una base de datos con cadena de conexión, seguiría este patrón:/REP V /CONN "sqldatabasename"\;"\"Data Source=xx;User ID=xx;Password=xx\""Para obtener más información sobre la sintaxis, vea dtexec (utilidad).
schedule: especifique la frecuencia con la que se debe ejecutar el trabajo, por ejemplo, al usar la expresión cron para especificar este valor se especifica como "*/1 * * * *", lo que significa que el trabajo se ejecuta por minuto.
Puede crear la carpeta básica y la estructura de archivos necesarias para implementar una nueva aplicación de SSIS mediante el siguiente comando:
azdata app init --name hello-is –version v1 --template ssis
Esto genera un archivo spec.yaml para lo siguiente:
#spec.yaml
entrypoint: ./hello.dtsx
name: hello-is
options: /REP V
poolsize: 2
replicas: 2
runtime: SSIS
schedule: '*/2 * * * *'
version: v1
Con el ejemplo también se crea un paquete hello.dtsx de muestra.
Todos los archivos de la aplicación están en el mismo directorio que spec.yaml. El archivo spec.yaml debe estar en el nivel de raíz del directorio del código fuente de la aplicación, junto al archivo dtsx.
Para los siguientes pasos, vea Cómo implementar una aplicación en Clústeres de macrodatos de SQL Server.
Limitaciones del entorno de ejecución de la utilidad dtexec
Todas las limitaciones y los problemas conocidos de SQL Server Integration Services (SSIS) en Linux se aplican en clústeres de macrodatos de SQL Server. Puede encontrar más información en Limitaciones y problemas conocidos de SSIS en Linux.
Uso del entorno de ejecución de MLeap de implementación de aplicaciones
El entorno de ejecución de MLeap de implementación de aplicaciones admite MLeap Serving v0.13.0.
En la implementación de aplicaciones, es en spec.yaml donde se proporciona la información que el controlador debe saber para implementar la aplicación. Los campos que se pueden especificar son los siguientes:
name: el nombre de la aplicación.version: la versión de la aplicación, por ejemplo,v1.runtime: el entorno de ejecución de implementación de la aplicación, debe especificarse comoMleap.
Además de lo anterior, debe especificar el valor bundleFileName de la aplicación MLeap. Esto genera un archivo spec.yaml similar al siguiente:
#spec.yaml
name: mleap-census
version: v1
runtime: Mleap
bundleFileName: census-bundle.zip
replicas: 1
Puede crear la carpeta básica y la estructura de archivos necesarias para implementar una nueva aplicación MLeap mediante el siguiente comando:
azdata app init --template mleap --name hello-mleap --version v1
Para los siguientes pasos, vea Cómo implementar una aplicación en Clústeres de macrodatos de SQL Server.
Limitaciones del entorno de ejecución de MLeap
Las limitaciones se alinean con la visión del proyecto de código abierto de MLeap Combust en GitHub.
Pasos siguientes
Para obtener más información sobre cómo crear y ejecutar aplicaciones en clústeres de macrodatos de SQL Server, vea lo siguiente:
- Implementar aplicaciones con azdata
- Implementación de aplicaciones con la extensión de implementación de aplicaciones
- Consumo de aplicaciones en clústeres de macrodatos
Para obtener más información sobre Clústeres de macrodatos de SQL Server, vea la siguiente introducción: