Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server 2019 (15.x) y versiones posteriores
SQL Server 2019 (15.x) y versiones posteriores
El 28 de febrero de 2025, se retiraron los clústeres de macrodatos de SQL Server 2019. Para obtener más información, vea la entrada de blog del anuncio.
Cambios en la compatibilidad con PolyBase en SQL Server
En relación con la retirada de los Clústeres de Big Data SQL Server 2019, hay algunas características relacionadas con las consultas distribuidas.
Se ha retirado la característica de los grupos de escalado horizontal de PolyBase de Microsoft SQL Server. La funcionalidad de los grupos de escalado horizontal se ha eliminado del producto en SQL Server 2022 (16.x). Las versiones de SQL Server 2019, SQL Server 2017 y SQL Server 2016 que están en el mercado seguirán ofreciendo compatibilidad con esta funcionalidad hasta que termine el ciclo de vida de esos productos. La virtualización de datos de PolyBase sigue siendo totalmente compatible como una característica de escalado vertical en SQL Server.
Los orígenes de datos externos Cloudera (CDP) y Hadoop de Hortonworks (HDP) también se retirarán para todas las versiones de SQL Server que están en el mercado y no se incluyen en SQL Server 2022. La compatibilidad con orígenes de datos externos se limita a las versiones del producto que incluyan soporte estándar por parte del proveedor correspondiente. Se recomienda usar la nueva integración de almacenamiento de objetos disponible en SQL Server 2022 (16.x).
En SQL Server 2022 (16.x) y versiones posteriores, los usuarios deben configurar sus orígenes de datos externos para usar nuevos conectores al conectarse a Azure Storage. En la tabla siguiente se resumen los cambios:
| Origen de datos externo | From | To |
|---|---|---|
| Azure Blob Storage (Servicio de almacenamiento de blobs de Azure) | wasb[s] |
abs |
| ADLS Gen2 | abfs[s] |
adls |
Note
Azure Blob Storage (abs) requerirá el uso de la Shared Access Signature (SAS) para el SECRET en la base de datos con credenciales delimitadas. En SQL Server 2019 y versiones anteriores, el conector wasb[s] usaba la clave de cuenta de almacenamiento con credenciales con ámbito de la base de datos al autenticarse en la cuenta de Azure Storage.
Descripción de la arquitectura de Clústeres de macrodatos para opciones de sustitución y migración
Para crear su solución de reemplazo para un sistema de procesamiento y almacenamiento de macrodatos, es importante comprender lo que proporcionaban los clústeres de macrodatos de SQL Server 2019 y su arquitectura puede ayudar a informar sus decisiones. La arquitectura de un clúster de macrodatos era:

Esta arquitectura proporcionó la siguiente asignación de funcionalidad:
| Component | Benefit |
|---|---|
| Kubernetes | Orquestador de código abierto para implementar y administrar aplicaciones basadas en contenedores a gran escala. Proporciona un método declarativo para crear y controlar la resistencia, la redundancia y la portabilidad para todo el entorno con un escalado elástico. |
| Controlador de Clústeres de macrodatos | Proporciona seguridad y administración para el clúster. Contiene el servicio de control, el almacén de configuración y otros servicios en el nivel de clúster, como Kibana, Grafana y búsqueda elástica. |
| Grupo de procesamiento | Ofrece recursos computacionales para el clúster. Contiene nodos que ejecutan SQL Server en pods de Linux. Los pods del grupo de proceso se dividen en instancias de proceso de SQL para tareas de procesamiento específicas. Este componente también proporciona virtualización de datos mediante PolyBase para consultar orígenes de datos externos sin mover ni copiar los datos. |
| Grupo de datos | Proporciona persistencia de datos para el clúster. El grupo de datos consta de uno o varios pods que ejecutan SQL Server en Linux. Se usa para ingerir datos de consultas SQL o trabajos de Spark. |
| Bloque de almacenamiento | El grupo de almacenamiento consiste en módulos de almacenamiento que se componen de SQL Server en Linux, Spark y HDFS. Todos los nodos de almacenamiento de un clúster de macrodatos son miembros de un clúster de HDFS. |
| Grupo de aplicaciones | Permite la implementación de aplicaciones en un clúster de macrodatos al ofrecer interfaces para crear, administrar y ejecutar aplicaciones. |
Para más información sobre estas funciones, consulte Introducción a Clústeres de macrodatos de SQL Server.
Opciones de sustitución de funcionalidades para macrodatos y SQL Server
La funcionalidad de los datos operativos que ofrece SQL Server dentro de Clústeres de macrodatos se puede reemplazar por SQL Server local en una configuración híbrida o mediante la plataforma Microsoft Azure. Microsoft Azure ofrece una selección de bases de datos relacionales, NoSQL y en memoria totalmente administradas, que abarcan motores propietarios y de código abierto, para adaptarse a las necesidades de los desarrolladores de aplicaciones modernas. La administración de la infraestructura, incluida la escalabilidad, la disponibilidad y la seguridad, se automatiza, le ahorra tiempo y dinero, y le permite centrarse en la creación de aplicaciones, mientras que las bases de datos administradas por Azure le facilitan el trabajo al mostrar información de rendimiento a través de inteligencia insertada, escalado sin límites y administración de amenazas de seguridad. Para más información, consulte Bases de datos en Azure.
La siguiente decisión que hay que tomar son las ubicaciones de proceso y almacenamiento de datos para el análisis. Las dos opciones de arquitectura son las implementaciones híbridas y en la nube. La mayoría de las cargas de trabajo de análisis se pueden migrar a la plataforma Microsoft Azure. Los datos "nacidos en la nube" (originados en aplicaciones basadas en la nube) son candidatos ideales para estas tecnologías, y los servicios de movimiento de datos pueden migrar datos locales a gran escala de forma segura y rápida. Para más información sobre las opciones de movimiento de datos, consulte Soluciones para la transferencia de datos.
Microsoft Azure tiene sistemas y certificaciones que permiten proteger los datos y su procesamiento en diferentes herramientas. Para más información sobre estas certificaciones, consulte Centro de confianza.
Note
La plataforma Microsoft Azure proporciona un alto nivel de seguridad y varias certificaciones para diversos sectores y, además, respeta la soberanía de los datos para los requisitos gubernamentales. Microsoft Azure también tiene una plataforma en la nube dedicada para las cargas de trabajo gubernamentales. La seguridad por sí sola no debe ser la decisión principal para los sistemas locales. Debe evaluar detenidamente el nivel de seguridad proporcionado por Microsoft Azure antes de tomar la decisión de conservar las soluciones de macrodatos locales.
En la opción de la arquitectura en la nube, todos los componentes residen en Microsoft Azure. Es responsable de los datos y el código que cree para el almacenamiento y el procesamiento de las cargas de trabajo. Esas opciones se tratan con más detalle en este artículo.
- Esta opción es más conveniente para una amplia variedad de componentes para el almacenamiento y el procesamiento de los datos, y cuando desea centrarse en los datos y las construcciones de procesamiento en lugar de en la infraestructura.
En las opciones de arquitectura híbrida, algunos componentes se conservan de forma local y otros se hospedan en un proveedor de servicios en la nube. La conectividad entre los dos sistemas está diseñada para optimizar el procesamiento sobre los datos.
- Esta opción es más conveniente cuando tiene una inversión considerable en arquitecturas y tecnologías locales, pero quiere usar las ofertas de Microsoft Azure; cuando tiene destinos de procesamiento y aplicaciones que residen en el entorno local, o si la audiencia es mundial.
Para más información sobre la creación de arquitecturas escalables, consulte Creación de un sistema escalable para datos masivos.
In-cloud
Azure SQL más Azure Machine Learning
Puede reemplazar la funcionalidad de Clústeres de macrodatos de SQL Server mediante una o varias opciones de base de datos de Azure SQL para los datos operativos y también con Microsoft Azure Machine Learning para las cargas de trabajo predictivas.
Azure Machine Learning es un servicio basado en la nube que se puede usar para todos los tipos de aprendizaje automático, desde el ML clásico hasta el aprendizaje profundo, supervisado y no supervisado. Independientemente de si prefiere escribir código en Python o R con el SDK o trabajar con las opciones no-code/low-code en el entorno, puede crear, entrenar y realizar un seguimiento de modelos de aprendizaje automático y aprendizaje profundo en un área de trabajo de Azure Machine Learning. Con Azure Machine Learning, puede comenzar a entrenar en la máquina local y luego escalar horizontalmente a la nube. El servicio también interopera con herramientas aprendizaje profundo y de código abierto populares, como PyTorch, TensorFlow, scikit-learn y Ray RLlib.
Use Microsoft Azure Machine Learning para reemplazar a Clústeres de macrodatos de SQL Server 2019 cuando necesite:
- Un entorno web basado en diseño para Machine Learning: módulos de arrastrar y soltar para construir los experimentos e implementar canalizaciones en un entorno de bajo código.
- Cuadernos de Jupyter: use nuestros cuadernos de ejemplo o cree los suyos propios para usar los ejemplos del SDK para Python para el aprendizaje automático.
- Scripts o cuadernos de R en los que usa el SDK para R para escribir su propio código, o use los módulos de R en el diseñador.
- El acelerador de soluciones Many Models se basa en Azure Machine Learning y permite entrenar, usar y administrar cientos o incluso miles de modelos de Machine Learning.
- Las extensiones de Machine Learning para Visual Studio Code (versión preliminar) proporcionan un entorno de desarrollo completo para crear y administrar proyectos de aprendizaje automático.
- La interfaz de la línea de comandos (CLI) de Machine Learning, Azure Machine Learning, es una extensión de la CLI de Azure que proporciona comandos para administrarlos con los recursos de Azure Machine Learning desde la línea de comandos.
- Integración con marcos de código abierto como PyTorch, TensorFlow y scikit-learn, entre muchos otros, para entrenar, implementar y administrar el proceso de aprendizaje automático de un extremo a otro.
- Aprendizaje de refuerzo con Ray RLlib.
- MLflow para realizar un seguimiento de las métricas e implementar modelos o Kubeflow para crear canalizaciones de flujos de trabajo de un extremo a otro.
La arquitectura de una implementación de Microsoft Azure Machine Learning es la siguiente:

Para obtener más información sobre Microsoft Azure Machine Learning, vea Funcionamiento de Azure Machine Learning.
Azure SQL en Databricks
Puede reemplazar la funcionalidad de Clústeres de macrodatos de SQL Server mediante una o varias opciones de base de datos de Azure SQL para los datos operativos y también con Microsoft Azure Databricks para las cargas de trabajo de análisis.
Azure Databricks es una plataforma de análisis de datos optimizada para la plataforma de servicios en la nube de Microsoft Azure. Azure Databricks ofrece dos entornos para desarrollar aplicaciones con un uso intensivo de datos: Azure Databricks SQL Analytics y Azure Databricks Workspace.
Azure Databricks SQL Analytics proporciona una plataforma fácil de usar para analistas que desean ejecutar consultas SQL en su lago de datos, crear varios tipos de visualización para explorar los resultados de las consultas desde distintas perspectivas y crear y compartir paneles.
Azure Databricks Workspace proporciona un área de trabajo interactiva que permite la colaboración entre ingenieros de datos, científicos de datos e ingenieros de aprendizaje automático. Para una canalización de macrodatos, los datos (estructurados o sin formato) se ingieren en Azure mediante Azure Data Factory en lotes o transmitidos casi en tiempo real con Apache Kafka, Event Hubs o IoT Hub. Estos datos llegan a un lago de datos para un almacenamiento persistente a largo plazo en Azure Blob Storage o Azure Data Lake Storage. Como parte del flujo de trabajo de análisis, use Azure Databricks para leer datos de varios orígenes de datos y convertirlos en información importante mediante Spark.
Use Microsoft Azure Databricks para reemplazar a Clústeres de macrodatos de SQL Server 2019 cuando necesite:
- Clústeres de Spark totalmente administrados con Spark SQL y DataFrames.
- Streaming para el procesamiento y análisis de datos en tiempo real para aplicaciones analíticas e interactivas, integración con HDFS, Flume y Kafka.
- Acceder a la biblioteca MLlib, que consta de algoritmos y utilidades de aprendizaje comunes, como la clasificación, la regresión, la agrupación en clústeres, el filtrado colaborativo, la reducción de dimensionalidad y las primitivas de optimización subyacentes.
- Documentar el progreso en cuadernos en R, Python, Scala o SQL.
- Visualizar datos en unos pocos pasos, mediante herramientas conocidas como Matplotlib, ggplot o d3.
- Paneles interactivos para crear informes dinámicos.
- GraphX, para gráficos y cálculo gráfico para una amplia gama de casos de uso, desde los análisis cognitivos hasta la exploración de datos.
- Creación de clústeres en segundos, con clústeres de escalado automático dinámico, que se comparten entre equipos.
- Acceder al clúster de programación mediante las API de REST.
- Acceder inmediatamente a las últimas características de Apache Spark con cada versión.
- Spark Core API: incluye compatibilidad con R, SQL, Python, Scala y Java.
- Un área de trabajo interactiva de exploración y visualización.
- Puntos de conexión SQL totalmente administrados en la nube.
- Consultas SQL que se ejecutan en puntos de conexión SQL totalmente administrados con un tamaño acorde a la latencia de la consulta y el número de usuarios simultáneos.
- Integración con Microsoft Entra ID (anteriormente llamado Azure Active Directory).
- Acceso basado en rol para tener permisos de usuario específicos para los cuadernos, los clústeres, los trabajos y los datos.
- Acuerdos de Nivel de Servicio de nivel empresarial.
- Paneles para compartir información, donde se combinan visualizaciones y texto para compartir la información que se obtiene de las consultas.
- Alertas que le ayudan a supervisar e integrar y a recibir notificaciones cuando un campo devuelto por una consulta alcanza un umbral. Úselas para supervisar su empresa o intégrelas en herramientas para iniciar flujos de trabajo, como la incorporación de usuarios o las incidencias de soporte técnico.
- Seguridad empresarial, incluida la integración de Microsoft Entra ID, controles basados en roles y Acuerdos de Nivel de Servicio que protegen los datos y la empresa.
- Integración con los servicios de Azure y los almacenes y las bases de datos de Azure, incluidos Synapse Analytics, Cosmos DB, Data Lake Store y Blob Storage.
- Integración con Power BI y otras herramientas de BI, como Tableau Software.
La arquitectura de una implementación de Microsoft Azure Databricks es la siguiente:
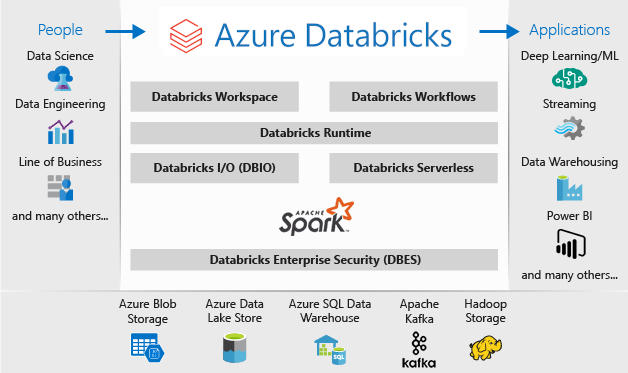
Para más información sobre Microsoft Azure Databricks, consulte ¿En qué consisten la ingeniería y la ciencia de datos de Databricks?
Hybrid
Creación de reflejo en Microsoft Fabric
Como experiencia de replicación de datos, el Reflejo de base de datos en Fabric es una solución de bajo costo y baja latencia para reunir datos de varios sistemas en una plataforma de análisis única. Puede replicar continuamente el patrimonio de datos existente directamente en OneLake de Fabric, incluidos los datos de SQL Server 2016+, Azure SQL Database, Azure SQL Managed Instance, Oracle, Snowflake, Cosmos DB, etc.
Con los datos completamente actualizados en un formato consultable en OneLake, ahora puedes usar todos los servicios de Fabric, como la ejecución de análisis con Spark, la ejecución de cuadernos, la ingeniería de datos, la visualización a través de informes de Power BI, etc.
Reflejo en Fabric proporciona una experiencia sencilla para acelerar el tiempo-valía para obtener información y tomar decisiones, y para eliminar los silos de datos entre soluciones tecnológicas, sin necesidad de desarrollar procesos costosos de extracción, transformación y carga (ETL) para mover datos.
Con Reflejo en Fabric, no necesitas integrar diferentes servicios de varios proveedores. En su lugar, puedes disfrutar de un producto altamente integrado, de un extremo a otro y fácil de usar, que ha sido diseñado para simplificar las necesidades de análisis y creado para la apertura y colaboración entre soluciones tecnológicas que pueden leer el formato de tabla de Delta Lake de código abierto.
Para más información, vea:
- Bases de datos reflejadas de Microsoft Fabric
- Supervisión de bases de datos reflejadas de Microsoft Fabric
- Explora datos en tu base de datos reflejada usando Microsoft Fabric
- ¿Qué es Microsoft Fabric?
- Datos de modelo en el modelo semántico de Power BI predeterminado en Microsoft Fabric
- ¿Cuál es el endpoint de análisis de SQL para un Lakehouse?
- Direct Lake
Microsoft SQL Server en Windows, Apache Spark y almacenamiento de objeto local
Puede instalar SQL Server en Windows o Linux y escalar verticalmente la arquitectura de hardware, mediante la funcionalidad de consulta object-storage de SQL Server 2022 (16.x) y la característica PolyBase para habilitar consultas en todos los datos del sistema.
La instalación y configuración de una plataforma de escalabilidad horizontal como Apache Hadoop o Apache Spark permite consultar datos no relacionales a gran escala. El uso de un conjunto central de sistemas Object-Storage compatibles con S3-API permite que tanto SQL Server 2022 (16.x) como Spark accedan al mismo conjunto de datos en todos los sistemas.
También puede usar el sistema de orquestación de contenedores de Kubernetes para la implementación. Esto habilita una arquitectura declarativa que se puede ejecutar de forma local o en cualquier nube que admita Kubernetes o la plataforma Red Hat OpenShift. Para más información sobre la implementación de SQL Server en un entorno de Kubernetes, consulte Implementación de un clúster de contenedor de SQL Server en Azure o vea Implementación de SQL Server 2019 en Kubernetes.
Use SQL Server y el entorno local de Hadoop o Spark para reemplazar a Clústeres de macrodatos de SQL Server 2019 cuando necesite:
- Conservar toda la solución a nivel local.
- Usar hardware dedicado para todas las partes de la solución.
- Acceder a datos relacionales y no relacionales desde la misma arquitectura, en ambas direcciones.
- Compartir un único conjunto de datos no relacionales entre SQL Server y el sistema no relacional de escalabilidad horizontal.
Realización de la migración
Una vez que elija una ubicación (en la nube o híbrida) para la migración, debe sopesar el tiempo de inactividad y los vectores de costo para determinar si ejecuta un nuevo sistema y mueve los datos del sistema anterior al nuevo en tiempo real (migración en paralelo), una copia de seguridad y restauración, o un nuevo inicio del sistema desde orígenes de datos existentes (migración en contexto).
La siguiente decisión es reescribir la funcionalidad actual en el sistema mediante la nueva opción de arquitectura o mover la mayor parte del código posible al nuevo sistema. Aunque la elección anterior puede tardar más, le permite usar los métodos, conceptos y ventajas nuevos que proporciona la arquitectura nueva. En ese caso, el acceso a los datos y los mapas de funcionalidad son las principales tareas de planeamiento en las que debe centrarse.
Si tiene previsto migrar el sistema actual con el mínimo cambio de código posible, la compatibilidad de lenguajes es en lo que debe centrarse principalmente para el planeamiento.
Migración de código
El siguiente paso consiste en auditar el código que usa el sistema actual y los cambios que necesita para ejecutarse en el nuevo entorno.
Hay dos vectores principales que se deben tener en cuenta para la migración del código:
- Orígenes y sumideros
- Migración de funcionalidades
Orígenes y sumideros
La primera tarea de la migración del código consiste en identificar los métodos, las cadenas o las API de conexión del origen de datos que usa el código para acceder a los datos que se importan, su ruta de acceso y su destino final. Documente esos orígenes y cree un mapa para las ubicaciones de la nueva arquitectura.
- Si la solución actual usa un sistema de canalización para mover los datos a través del sistema, asigne los nuevos orígenes de arquitectura, pasos y receptores a los componentes de la canalización.
- Si la nueva solución también reemplaza la arquitectura de canalización, trate el sistema como una nueva instalación con fines de planeamiento, incluso si va a volver a usar el hardware o la plataforma en la nube como una opción alternativa.
Migración de funcionalidades
El trabajo más complejo necesario en una migración es actualizar o crear la documentación de la funcionalidad del sistema actual o hacer referencia a ella. Si planea una actualización local e intenta reducir la cantidad de reescritura de código tanto como sea posible, este paso lleva más tiempo.
Sin embargo, una migración a partir de una tecnología anterior suele ser un momento óptimo para actualizarse con los últimos avances tecnológicos y beneficiarse de las construcciones que esto proporciona. Una reescritura del sistema actual suele proporcionar más seguridad, rendimiento e incluso opciones de características, e incluso optimizaciones de costos.
En cualquier caso, hay dos factores principales implicados en la migración: el código y los lenguajes que admite el nuevo sistema y las opciones en torno al movimiento de datos. Normalmente, debería poder cambiar las cadenas de conexión del clúster de macrodatos actual a la instancia de SQL Server y el entorno de Spark. La información sobre la conexión de datos y la transferencia de código deben ser mínimas.
Si pretende realizar una reescritura de la funcionalidad actual, asigne las nuevas bibliotecas, paquetes y DLL a la arquitectura que eligió para la migración. Encontrará una lista de cada una de las bibliotecas, lenguajes y funciones que ofrece cada solución en la documentación de referencia que se muestra en las secciones anteriores. Asigne los lenguajes sospechosos o no admitidos y planee la sustitución por la arquitectura elegida.
Opciones para la migración de datos
Hay dos enfoques comunes para el movimiento de datos en un sistema analítico a gran escala. El primero consiste en crear un proceso de "transferencia" en el que el sistema original continúe procesando los datos, de tal forma que esos datos se acumulen en un conjunto más pequeño de orígenes de datos de informes agregados. A continuación, el nuevo sistema comienza con datos nuevos y se usa a partir de la fecha de migración.
En algunos casos, todos los datos deben transferirse del sistema heredado al nuevo. En este caso, puede montar los almacenes de archivos originales desde Clústeres de macrodatos de SQL Server si el nuevo sistema lo admite y, a continuación, copiar los datos en el nuevo sistema, o bien puede crear una transferencia física.
La migración de los datos actuales de Clústeres de macrodatos de SQL Server 2019 a otro sistema depende en gran medida de dos factores: la ubicación de los datos actuales y que el destino sea local o en la nube.
Migración de datos locales
Para las migraciones entre entornos locales, puede migrar los datos de SQL Server con una estrategia de copia de seguridad y restauración, o bien puede configurar la replicación para mover algunos o todos los datos relacionales. También se puede usar SQL Server Integration Services para copiar datos de SQL Server a otra ubicación. Para obtener más información sobre cómo mover datos con SSIS, consulte SQL Server Integration Services.
Para los datos de HDFS del entorno actual de los clústeres de macrodatos de SQL Server, el enfoque estándar es montar los datos en un clúster de Spark independiente y usar el proceso de Object Storage para mover los datos para que una instancia de SQL Server 2022 (16.x) pueda acceder a ellos o dejarlos tal y como están y continuar procesándolos con trabajos de Spark.
Migración de datos a la nube
Para los datos ubicados en un almacenamiento en la nube o en un entorno local, puede usar Azure Data Factory, que tiene más de 90 conectores para una canalización completa de transferencia, con programación, supervisión, alertas y otros servicios. Para obtener más información sobre Azure Data Factory, consulte ¿Qué es Azure Data Factory?
Si desea mover grandes cantidades de datos de forma segura y rápida desde el almacenamiento de datos local a Microsoft Azure, puede usar el servicio Azure Import/Export. El servicio Azure Import/Export se usa para importar de forma segura grandes cantidades de datos a Azure Blob Storage y Azure Files mediante el envío de unidades de disco a un centro de datos de Azure. También se puede usar este servicio para transferir datos desde Azure Blob Storage hasta las unidades de disco y enviarlas al sitio local. Se pueden importar los datos de una o varias unidades a Azure Blob Storage o Azure Files. Para volúmenes de datos muy grandes, el uso de este servicio puede ser la ruta de acceso más rápida.
Si desea transferir datos con los discos proporcionados por Microsoft, puede usar Azure Data Box Disk para importar datos en Azure. Para obtener más información, vaya a ¿Qué es el servicio Azure Import/Export?
Para más información sobre estas opciones y las decisiones relacionadas, consulte Uso de Azure Data Lake Storage Gen1 para requisitos de macrodatos.