Envío de trabajos de Spark en un clúster de macrodatos de SQL Server en Visual Studio Code
Importante
El complemento Clústeres de macrodatos de Microsoft SQL Server 2019 se va a retirar. La compatibilidad con Clústeres de macrodatos de SQL Server 2019 finalizará el 28 de febrero de 2025. Todos los usuarios existentes de SQL Server 2019 con Software Assurance serán totalmente compatibles con la plataforma, y el software se seguirá conservando a través de actualizaciones acumulativas de SQL Server hasta ese momento. Para más información, consulte la entrada de blog sobre el anuncio y Opciones de macrodatos en la plataforma Microsoft SQL Server.
Obtenga información sobre cómo usar Spark & Hive Tools para Visual Studio Code para crear y enviar scripts de PySpark para Apache Spark; primero, describiremos cómo instalar Spark & Hive Tools en Visual Studio Code y, después, explicaremos cómo enviar trabajos a Spark.
Spark & Hive Tools se puede instalar en las plataformas compatibles con Visual Studio Code, que son Windows, Linux y macOS. A continuación, encontrará los requisitos previos para las diferentes plataformas.
Prerrequisitos
Los elementos siguientes son necesarios para completar los pasos indicados en este artículo:
- Un clúster de macrodatos de SQL Server. Vea Clústeres de macrodatos de SQL Server.
- Visual Studio Code.
- Python y extensión para Python en Visual Studio Code.
- Mono. Mono solo es necesario para Linux y macOS.
- Configure el entorno de PySpark interactivo para Visual Studio Code.
- Un directorio local llamado SQLBDCexample. En este artículo se usa C:\SQLBDC\SQLBDCexample.
Instalar Spark & Hive Tools
Después de completar los requisitos previos, puede instalar Spark & Hive Tools para Visual Studio Code. Siga este procedimiento para instalar Spark & Hive Tools:
Abra Visual Studio Code.
En la barra de menús, vaya a Ver>Extensiones.
En el cuadro de búsqueda, escriba Spark & Hive.
Seleccione Spark & Hive Tools, publicado por Microsoft, en los resultados de búsqueda y seleccione Instalar.
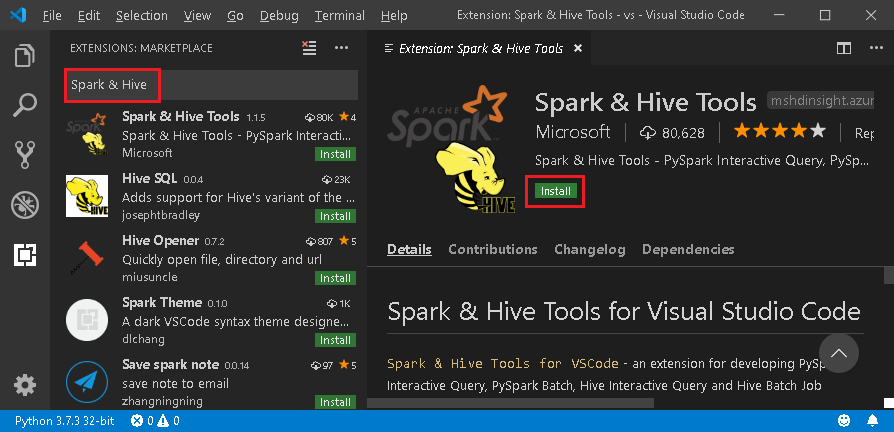
Si es necesario, vuelva a cargar la aplicación.
Abrir la carpeta de trabajo
Siga este procedimiento para abrir una carpeta de trabajo y crear un archivo en Visual Studio Code:
En la barra de menús, vaya a Archivo>Abrir carpeta…>C:\SQLBDC\SQLBDCexample y, después, haga clic en el botón Seleccionar carpeta. La carpeta se mostrará en la vista Explorador de la parte izquierda.
En la vista Explorador, seleccione la carpeta SQLBDCexample y, después, haga clic en el icono de Nuevo archivo junto a la carpeta de trabajo.
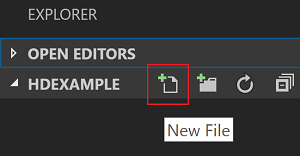
Asigne un nombre al nuevo archivo con la extensión de archivo
.py(script de Spark). En este ejemplo, se usa HelloWorld.py.Copie y pegue el código siguiente en el archivo de script:
import sys from operator import add from pyspark.sql import SparkSession, Row spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() data = [Row(col1='pyspark and spark', col2=1), Row(col1='pyspark', col2=2), Row(col1='spark vs hadoop', col2=2), Row(col1='spark', col2=2), Row(col1='hadoop', col2=2)] df = spark.createDataFrame(data) lines = df.rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) output = counters.collect() sortedCollection = sorted(output, key = lambda r: r[1], reverse = True) for (word, count) in sortedCollection: print("%s: %i" % (word, count))
Vincular un clúster de macrodatos de SQL Server
Antes de enviar scripts a los clústeres desde Visual Studio Code, necesita vincular un clúster de macrodatos de SQL Server.
En la barra de menús, vaya a Ver>Paleta de comandos... y escriba Spark / Hive: Link a Cluster (vincular un clúster).

Seleccione el tipo de clúster vinculado Macrodatos de SQL Server.
Especifique el punto de conexión de macrodatos de SQL Server.
Especifique el nombre de usuario del clúster de macrodatos de SQL Server.
Escriba la contraseña del administrador de usuarios.
Establezca el nombre para mostrar del clúster de macrodatos (opcional).
Muestre una lista de los clústeres y revise la vista SALIDA.
Lista de clústeres
En la barra de menús, vaya a Ver>Paleta de comandos... y escriba Spark / Hive: List Cluster (lista de clústeres).
Revise la ventana de SALIDA. En la vista, se muestran los clústeres vinculados.

Establecer un clúster predeterminado
Vuelva a abrir la carpeta SQLBDCexample creada anteriormente (si está cerrada).
Seleccione el archivo HelloWorld.py que ha creado anteriormente para abrirlo en el editor de scripts.
Si aún no lo ha hecho, vincule un clúster.
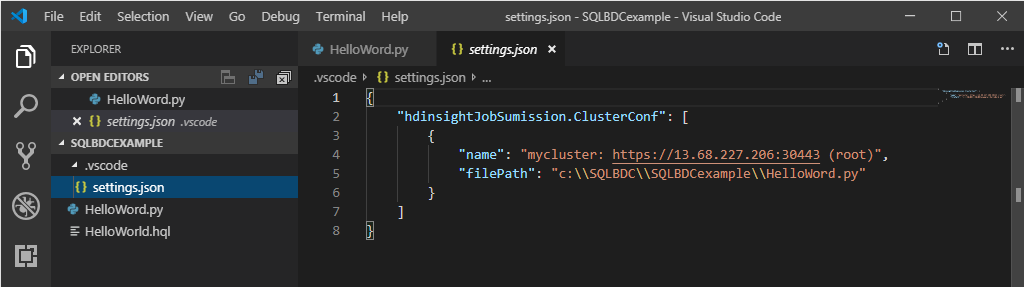
Haga clic con el botón derecho en el editor de scripts y seleccione Spark / Hive: Set Default Cluster (Establecer clúster predeterminado).
Seleccione un clúster como el clúster predeterminado para el archivo de script actual. Las herramientas actualizan automáticamente el archivo de configuración .VSCode\settings.json.
Enviar consultas de PySpark interactivas
Para enviar consultas de PySpark interactivas, siga este procedimiento:
Vuelva a abrir la carpeta SQLBDCexample creada anteriormente (si está cerrada).
Seleccione el archivo HelloWorld.py que ha creado anteriormente para abrirlo en el editor de scripts.
Si aún no lo ha hecho, vincule un clúster.
Elija todo el código y haga clic con el botón derecho en el editor de scripts, seleccione Spark: PySpark Interactive para enviar la consulta, o bien use el método abreviado de teclado Ctrl + Alt + I.
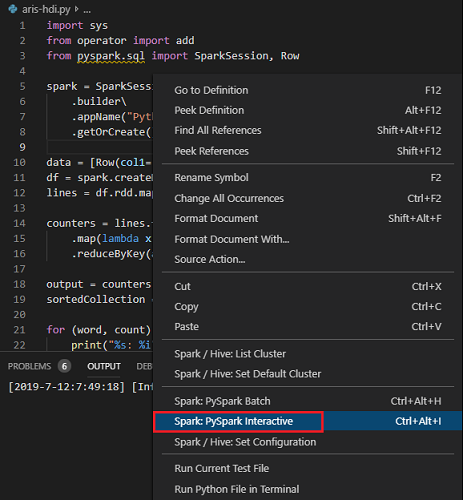
Si aún no ha especificado un clúster predeterminado, seleccione el clúster. Transcurridos unos instantes, los resultados de Python Interactive aparecen en una nueva pestaña. Las herramientas también permiten enviar un bloque de código en lugar de todo el archivo de script mediante el menú contextual.
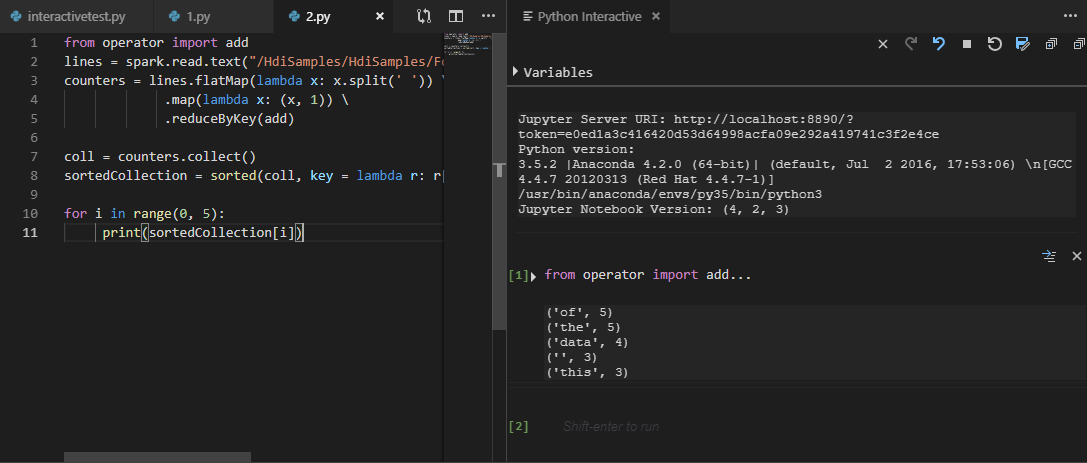
Escriba “%%info” y, después, presione Mayús + Entrar para ver la información del trabajo. (Opcional)
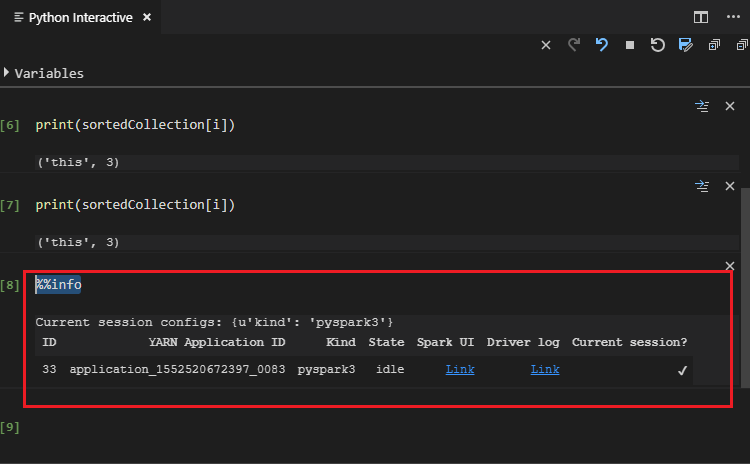
Nota:
Si la opción Python Extension Enabled (Extensión de Python habilitada) está desactivada en la configuración (de forma predeterminada, esta opción está activada), los resultados de la interacción de PySpark enviados se mostrarán en la ventana anterior.
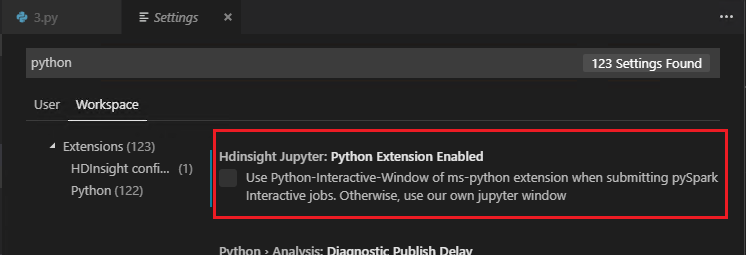
Enviar trabajo por lotes de PySpark
Vuelva a abrir la carpeta SQLBDCexample creada anteriormente (si está cerrada).
Seleccione el archivo HelloWorld.py que ha creado anteriormente para abrirlo en el editor de scripts.
Si aún no lo ha hecho, vincule un clúster.
Haga clic con el botón derecho en el editor de scripts y seleccione Spark: PySpark Batch (Lote de PySpark), o bien use el método abreviado de teclado Ctrl + Alt + H.
Si aún no ha especificado un clúster predeterminado, seleccione el clúster. Después de enviar trabajo de Python, los registros de envío se muestran en la ventana de SALIDA en Visual Studio Code. También se muestran la URL de la interfaz de usuario de Spark y la URL de la interfaz de usuario de Yarn. Para realizar un seguimiento del estado del trabajo, puede abrir la URL en un explorador web.
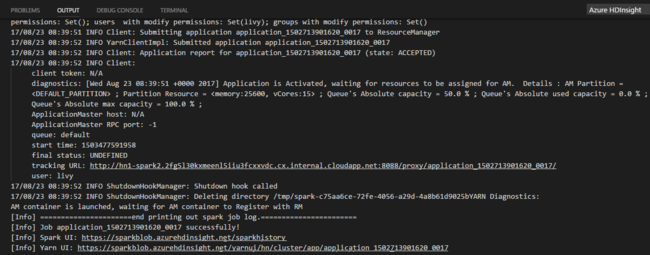
Configuración de Apache Livy
Se admite la configuración de Apache Livy, que puede configurarse en el archivo .VSCode\settings.json de la carpeta del área de trabajo. En la actualidad, la configuración de Livy solo admite el script de Python. Para obtener más información, vea Livy README (LÉAME de Livy).
Cómo activar la configuración de Livy
Método 1
- En la barra de menús, vaya a Archivo>Preferencias>Configuración.
- En el cuadro de texto Configuración de búsqueda, escriba Envío de trabajo de HDInsight: Livy Conf.
- Seleccione Editar en settings.json para el resultado de la búsqueda relevante.
Método 2
Envíe un archivo; la carpeta .vscode se agregará automáticamente a la carpeta de trabajo. Para encontrar la configuración de Livy, seleccione settings.json, en .vscode.
Configuración del proyecto:

Nota:
En el caso de las opciones driverMemory y executorMemory, establezca el valor con una unidad (por ejemplo, "1gb" o "1024mb").
Configuraciones de Livy admitidas
POST /batches
Cuerpo de la solicitud
| name | description | type |
|---|---|---|
| archivo | Archivo que contiene la aplicación que se ejecutará | ruta (obligatorio) |
| proxyUser | Usuario que se suplantará al ejecutar el trabajo | string |
| className | Clase principal de Java/Spark de la aplicación | string |
| args | Argumentos de la línea de comandos para la aplicación | lista de cadenas |
| jars | Archivos jar que se usarán en esta sesión | Lista de cadenas |
| pyFiles | Archivos de Python que se usarán en esta sesión | Lista de cadenas |
| files | Archivos que se usarán en esta sesión | Lista de cadenas |
| driverMemory | Cantidad de memoria que se usará para el proceso del controlador | string |
| driverCores | Número de núcleos que se usarán para el proceso del controlador | int |
| executorMemory | Cantidad de memoria que se usará por proceso de ejecutor | string |
| executorCores | Número de núcleos que se usará para cada ejecutor | int |
| numExecutors | Número de ejecutores que se iniciarán para esta sesión | int |
| archives | Archivos que se usarán en esta sesión | Lista de cadenas |
| cola | Nombre de la cola de YARN al que se realizará el envío | string |
| name | Nombre de esta sesión | string |
| conf | Propiedades de configuración de Spark | Mapa de clave=valor |
| :- | :- | :- |
Cuerpo de la respuesta
Objeto por lotes creado.
| name | description | type |
|---|---|---|
| id | Identificador de la sesión | int |
| appId | Identificador de aplicación de esta sesión | String |
| appInfo | Información detallada sobre la aplicación | Mapa de clave=valor |
| log | Líneas de registro | lista de cadenas |
| state | Estado del lote | string |
| :- | :- | :- |
Nota
La configuración de Livy asignada se mostrará en el panel de resultados al enviar el script.
Características adicionales
Spark & Hive para Visual Studio Code admite las características siguientes:
Autocompletar de IntelliSense. Se muestran sugerencias emergentes de palabras clave, métodos, variables, etc. Se representan diferentes tipos de objetos con distintos iconos.
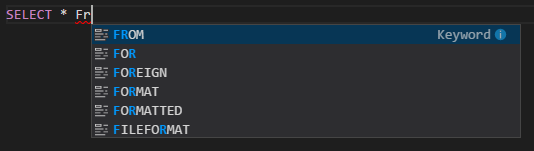
Marcador de error de IntelliSense. El servicio de lenguaje subraya los errores de edición en el script de Hive.
Sintaxis resaltada. El servicio de lenguaje usa distintos colores para diferenciar variables, palabras clave, tipos de datos, funciones, etc.
Desvincular clúster
En la barra de menús, vaya a Vista>Paleta de comandos y escriba Spark / Hive: desvincular un clúster.
Seleccione el clúster que quiera desvincular.
Revise la vista SALIDA.
Pasos siguientes
Para obtener más información sobre los clústeres de macrodatos de SQL Server y los escenarios relacionados, vea Clústeres de macrodatos de SQL Server.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de