Solución de problemas de un cuaderno de pyspark
Importante
El complemento Clústeres de macrodatos de Microsoft SQL Server 2019 se va a retirar. La compatibilidad con Clústeres de macrodatos de SQL Server 2019 finalizará el 28 de febrero de 2025. Todos los usuarios existentes de SQL Server 2019 con Software Assurance serán totalmente compatibles con la plataforma, y el software se seguirá conservando a través de actualizaciones acumulativas de SQL Server hasta ese momento. Para más información, consulte la entrada de blog sobre el anuncio y Opciones de macrodatos en la plataforma Microsoft SQL Server.
En este artículo se muestra cómo solucionar problemas de un cuaderno pyspark que produce un error.
Arquitectura de un trabajo de PySpark en Azure Data Studio
Azure Data Studio se comunica con el punto de conexión livy en Clústeres de macrodatos de SQL Server.
El punto de conexión livy emite comandos spark-submit dentro del clúster de macrodatos. Cada comando spark-submit tiene un parámetro que especifica YARN como administrador de recursos de clúster.
Para solucionar problemas relativos a la sesión de PySpark de forma eficaz, recopilará y revisará los registros en cada capa: Livy, YARN y Spark.
En los pasos de solución de problemas se requiere lo siguiente:
- CLI de datos de Azure (
azdata) instalado y con la configuración establecida correctamente en el clúster. - Familiaridad con la ejecución de comandos de Linux y algunas aptitudes de solución de problemas de registro.
Pasos para solucionar problemas
Revisar los mensajes de error y de pila en
pyspark.Obtenga el id. de la aplicación de la primera celda del cuaderno. Use este id. de la aplicación para investigar los registros de
livy, YARN y Spark.SparkContextutiliza el id. de la aplicación de YARN.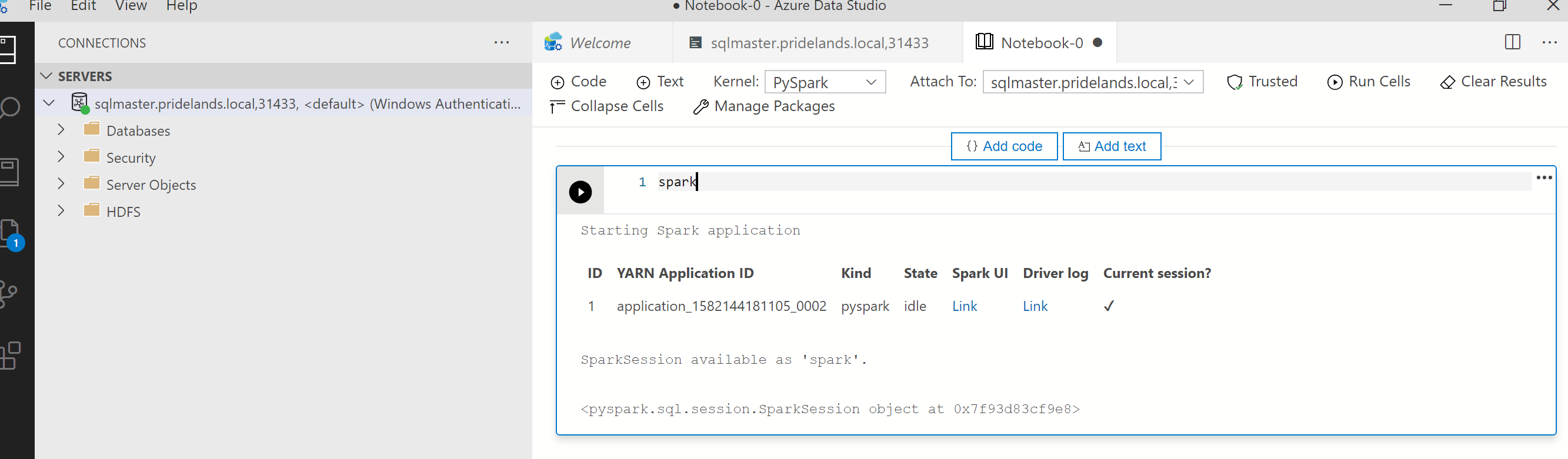
Obtener los registros.
Use
azdata bdc debug copy-logspara investigar.En el ejemplo siguiente se conecta un punto de conexión de clúster de macrodatos para copiar los registros. Actualice los valores siguientes en el ejemplo antes de ejecutar.
<ip_address>: el punto de conexión del clúster de macrodatos.<username>: el nombre de usuario del clúster de macrodatos.<namespace>: el espacio de nombres de Kubernetes para el clúster.<folder_to_copy_logs>: la ruta de acceso de la carpeta local donde quiere que se copien los registros.
azdata login --auth basic --username <username> --endpoint https://<ip_address>:30080 azdata bdc debug copy-logs -n <namespace> -d <folder_to_copy_logs>Salida de ejemplo
<user>@<server>:~$ azdata bdc debug copy-logs -n <namespace> -d copy_logs Collecting the logs for cluster '<namespace>'. Collecting logs for containers... Creating an archive from logs-tmp/<namespace>. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS-dumps.tar.gz. Collecting the logs for cluster 'kube-system'. Collecting logs for containers... Creating an archive from logs-tmp/kube-system. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS-dumps.tar.gz.Revisar los registros de Livy. Los registros de Livy se encuentran en
<namespace>\sparkhead-0\hadoop-livy-sparkhistory\supervisor\log.- Busque el id. de la aplicación de YARN en la primera celda del cuaderno Pyspark.
- Busque el estado
ERR.
Ejemplo de registro de Livy que tiene un estado
YARN ACCEPTED. Livy ha enviado la aplicación de YARN.HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO impl.YarnClientImpl: Submitted application application_<application_id> YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: Application report for application_<application_id> (state: ACCEPTED) YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: client token: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: diagnostics: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster host: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster RPC port: -1 YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: queue: default YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: start time: ############ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: final status: UNDEFINED YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: tracking URL: https://sparkhead-1.fnbm.corp:8090/proxy/application_<application_id>/ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: user: <account>Revisar la interfaz de usuario de YARN
Obtenga la dirección URL del punto de conexión de YARN del panel de administración del clúster de macrodatos de Azure Data Studio o ejecute
azdata bdc endpoint list –o table.Por ejemplo:
azdata bdc endpoint list -o tableDevuelve
Description Endpoint Name Protocol ------------------------------------------------------ ---------------------------------------------------------------- -------------------------- ---------- Gateway to access HDFS files, Spark https://knox.<namespace-value>.local:30443 gateway https Spark Jobs Management and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/sparkhistory spark-history https Spark Diagnostics and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/yarn yarn-ui https Application Proxy https://proxy.<namespace-value>.local:30778 app-proxy https Management Proxy https://bdcmon.<namespace-value>.local:30777 mgmtproxy https Log Search Dashboard https://bdcmon.<namespace-value>.local:30777/kibana logsui https Metrics Dashboard https://bdcmon.<namespace-value>.local:30777/grafana metricsui https Cluster Management Service https://bdcctl.<namespace-value>.local:30080 controller https SQL Server Master Instance Front-End sqlmaster.<namespace-value>.local,31433 sql-server-master tds SQL Server Master Readable Secondary Replicas sqlsecondary.<namespace-value>.local,31436 sql-server-master-readonly tds HDFS File System Proxy https://knox.<namespace-value>.local:30443/gateway/default/webhdfs/v1 webhdfs https Proxy for running Spark statements, jobs, applications https://knox.<namespace-value>.local:30443/gateway/default/livy/v1 livy httpsComprobar el id. de la aplicación y los registros de application_master individuales y de contenedor.
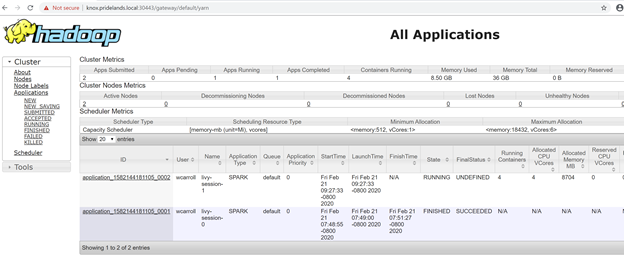
Revisar los registros de aplicaciones de YARN.
Obtenga el registro de aplicaciones para la aplicación. Use
kubectlpara conectarse al pod desparkhead-0, por ejemplo:kubectl exec -it sparkhead-0 -- /bin/bashDespués, ejecute este comando en ese Shell con el elemento
application_idcorrecto:yarn logs -applicationId application_<application_id>Buscar errores o pilas.
Un ejemplo de error de permiso en HDFS. En la pila de Java, busque
Caused by:.YYYY-MM-DD HH:MM:SS,MMM ERROR spark.SparkContext: Error initializing SparkContext. org.apache.hadoop.security.AccessControlException: Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-x at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:399) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:255) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:193) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1852) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1836) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1795) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.resolvePathForStartFile(FSDirWriteFileOp.java:324) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2504) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileChecked(FSNamesystem.java:2448) Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-xRevisar la interfaz de usuario de SPARK.
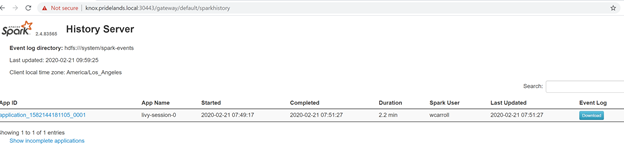
Explore en profundidad las tareas de las fases en busca de errores.
Pasos siguientes
Solución de problemas de integración de Active Directory de Clústeres de macrodatos de SQL Server
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de