Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server
SQL Server
Para crear un grupo de disponibilidad distribuido, debe crear dos grupos de disponibilidad, cada uno con su propio cliente de escucha. Después, combine estos grupos de disponibilidad en un grupo de disponibilidad distribuido. En los pasos siguientes se proporciona un ejemplo básico de Transact-SQL. Este ejemplo no cubre todos los detalles relativos a cómo crear grupos de disponibilidad y agentes de escucha, sino que se centra en resaltar los requisitos clave.
Para ver una introducción técnica de los grupos de disponibilidad distribuidos, vea Distributed availability groups (Grupos de disponibilidad distribuidos).
Requisitos previos
Para configurar un grupo de disponibilidad distribuido, debe contar con lo siguiente:
- Una versión compatible de SQL Server.
Nota:
Si configuró su agente de escucha para su grupo de disponibilidad en la máquina virtual de SQL Server en Azure usando un nombre de red distribuido (DNN), entonces no se admite la configuración de un grupo de disponibilidad distribuido encima de su grupo de disponibilidad. Para más información, consulte Interoperabilidad de características de SQL Server en máquinas virtuales de Azure con el agente de escucha de grupo de disponibilidad y DNN.
Permisos
Requiere permisos de CREATE AVAILABILITY GROUP en el servidor para crear un grupo de disponibilidad y sysadmin para realizar la conmutación por error de un grupo de disponibilidad distribuido.
Establecer los puntos de conexión de reflejo de bases de datos para atender en todas las direcciones IP.
Asegúrese de que los puntos de conexión de creación de reflejo de la base de datos pueden comunicarse entre los diferentes grupos de disponibilidad del grupo de disponibilidad distribuido. Si un grupo de disponibilidad está configurado en una red específica en el punto de conexión de creación de reflejo de la base de datos, el grupo de disponibilidad distribuido no funcionará correctamente. En cada servidor que aloje una réplica en el grupo de disponibilidad distribuida, configura el punto final de duplicación de la base de datos para que escuche en todas las direcciones IP (LISTENER_IP = ALL).
Crear un punto de conexión de reflejo de bases de datos para atender en todas las direcciones IP.
Por ejemplo, con el siguiente script se crea un punto de conexión de creación de reflejo de la base de datos de agente de escucha en el puerto TCP 5022 que escucha en todas las direcciones IP.
CREATE ENDPOINT [aodns-hadr]
STATE = STARTED
AS TCP
(
LISTENER_PORT = 5022,
LISTENER_IP = ALL
)
FOR DATABASE_MIRRORING
(
ROLE = ALL,
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
Modificación de un punto de conexión de creación de reflejo de la base de datos existente para escuchar en todas las direcciones IP
Por ejemplo, el siguiente script modifica el punto de conexión de reflejo de la base de datos existente para escuchar en todas las direcciones IP.
ALTER ENDPOINT [aodns-hadr]
AS TCP
(
LISTENER_IP = ALL
);
GO
Crear el primer grupo de disponibilidad
Creación del grupo de disponibilidad principal en el primer clúster
Cree un grupo de disponibilidad en el primer clúster de conmutación por error de Windows Server (WSFC). En este ejemplo, el grupo de disponibilidad se denomina ag1 en la base de datos db1. La réplica principal del grupo de disponibilidad principal se conoce como principal global en un grupo de disponibilidad distribuido. Servidor1 es el principal global en este ejemplo.
CREATE AVAILABILITY GROUP [ag1]
FOR DATABASE db1
REPLICA ON N'server1' WITH (ENDPOINT_URL = N'TCP://server1.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server2' WITH (ENDPOINT_URL = N'TCP://server2.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
Nota:
En este ejemplo se emplea la propagación automática, donde el valor SEEDING_MODE se establece en AUTOMATIC para las réplicas y el grupo de disponibilidad distribuido. En esta configuración, las réplicas secundarias y el grupo de disponibilidad secundario se rellenarán automáticamente sin requerir una copia de seguridad manual y la restauración de la base de datos principal.
Unir las réplicas secundarias al grupo de disponibilidad principal
Cualquier réplica secundaria debe estar unida al grupo de disponibilidad mediante ALTER AVAILABILITY GROUP con la opción JOIN. Dado que en este ejemplo se usa la inicialización automática, también debe invocar ALTER AVAILABILITY GROUP con la opción GRANT CREATE ANY DATABASE. De esta forma, el grupo de disponibilidad puede crear la base de datos y comenzar la propagación automáticamente a partir de la réplica principal.
En este ejemplo, se ejecutan los comandos siguientes en la réplica secundaria, server2, para unir el grupo de disponibilidad ag1 . Después, el grupo de disponibilidad puede crear bases de datos en la secundaria.
ALTER AVAILABILITY GROUP [ag1] JOIN
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE
GO
Nota:
Cuando el grupo de disponibilidad crea una base de datos en una réplica secundaria, establece como propietario de la base de datos la cuenta que ha ejecutado la instrucción ALTER AVAILABILITY GROUP para conceder permiso para crear una base de datos. Para obtener más información, consulte Grant create database permission on secondary replica to availability group (Permitir que un grupo de disponibilidad cree bases de datos en réplicas secundarias).
Crear un agente de escucha para el grupo de disponibilidad principal
Luego, agregue un agente de escucha para el grupo de disponibilidad principal del primer WSFC. En este ejemplo, el receptor se llama ag1-listener. Para obtener instrucciones detalladas sobre cómo crear un agente de escucha, consulte Crear o configurar un agente de escucha de grupo de disponibilidad (SQL Server).
ALTER AVAILABILITY GROUP [ag1]
ADD LISTENER 'ag1-listener' (
WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) ,
PORT = 60173);
GO
Crear un segundo grupo de disponibilidad
Después, en el segundo WSFC, cree un segundo grupo de disponibilidad, ag2. En este caso, no se especifica la base de datos, ya que se propaga automáticamente desde el grupo de disponibilidad principal. La réplica principal del grupo de disponibilidad secundario se conoce como reenviador en un grupo de disponibilidad distribuido. En este ejemplo, servidor3 es el reenviador.
CREATE AVAILABILITY GROUP [ag2]
FOR
REPLICA ON N'server3' WITH (ENDPOINT_URL = N'TCP://server3.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server4' WITH (ENDPOINT_URL = N'TCP://server4.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
Nota:
- El grupo de disponibilidad secundario debe usar el mismo punto de conexión de creación de reflejo de la base de datos (en este ejemplo, el puerto 5022). En caso contrario, se detendrá la replicación después de una conmutación por error local.
- Los grupos de disponibilidad subyacentes deben estar en el mismo modo de disponibilidad: ambos grupos de disponibilidad deben estar en modo de confirmación sincrónica o ambos deben estar en modo de confirmación asincrónica. Si no está seguro de cuál usar, establezca ambos en modo de confirmación asincrónica hasta que esté listo para realizar un failover.
Unión de las réplicas secundarias al grupo de disponibilidad secundario
En este ejemplo, se ejecutan los comandos siguientes en la réplica secundaria, server4, para unir el grupo de disponibilidad ag2 . Después, el grupo de disponibilidad puede crear bases de datos en la secundaria con el fin de admitir la propagación automática.
ALTER AVAILABILITY GROUP [ag2] JOIN
ALTER AVAILABILITY GROUP [ag2] GRANT CREATE ANY DATABASE
GO
Crear un agente de escucha para el grupo de disponibilidad secundario
Después, agregue un agente de escucha para el grupo de disponibilidad secundaria del segundo WSFC. En este ejemplo, el agente de escucha se denomina " ag2-listener". Para obtener instrucciones detalladas sobre cómo crear un agente de escucha, consulte Crear o configurar un agente de escucha del grupo de disponibilidad (SQL Server).
ALTER AVAILABILITY GROUP [ag2]
ADD LISTENER 'ag2-listener' ( WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) , PORT = 60173);
GO
Crear un grupo de disponibilidad distribuido en el primer clúster
En el primer WSFC, cree un grupo de disponibilidad distribuido (denominado " distributedAG " en este ejemplo). Use el CREATE AVAILABILITY GROUP comando con la opción DISTRIBUTED . El AVAILABILITY GROUP parámetro ON especifica los grupos ag1 de disponibilidad de miembros y ag2.
Para crear el grupo de disponibilidad distribuido mediante la propagación automática, utilice el siguiente código de Transact-SQL:
CREATE AVAILABILITY GROUP [distributedAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Nota:
LISTENER_URL especifica el agente de escucha de cada grupo de disponibilidad, con el punto de conexión de creación de reflejo de la base de datos del grupo de disponibilidad. En este ejemplo, es el puerto 5022 (no el puerto 60173 usado para crear el agente de escucha). Si usa un equilibrador de carga, por ejemplo, en Azure, agregue una regla de equilibrio de carga para el puerto del grupo de disponibilidad distribuido. Agregue la regla al puerto de escucha, además del puerto de la instancia de SQL Server.
Cancelar la distribución automática al servidor de reenvío
Si, por cualquier motivo, es necesario cancelar la inicialización del reenviador antes de que se sincronicen los dos grupos de disponibilidad, modifique el grupo de disponibilidad distribuido estableciendo el parámetro SEEDING_MODE del reenviador en MANUAL y cancele inmediatamente la propagación. Ejecute el comando en el nodo primario global:
-- Cancel automatic seeding. Connect to global primary but specify DAG AG2
ALTER AVAILABILITY GROUP [distributedAG]
MODIFY
AVAILABILITY GROUP ON
'ag2' WITH
( SEEDING_MODE = MANUAL );
Unirse al grupo de disponibilidad distribuido en el segundo clúster
Después, únase al grupo de disponibilidad distribuido del segundo WSFC.
Para unirse al grupo de disponibilidad distribuido mediante la propagación automática, utilice el siguiente código de Transact-SQL:
ALTER AVAILABILITY GROUP [distributedAG]
JOIN
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Unión a la base de datos de la réplica secundaria del segundo grupo de disponibilidad
Si el segundo grupo de disponibilidad se configuró para usar la propagación automática, vaya al paso 2.
Si el segundo grupo de disponibilidad usa la propagación manual, restaure la copia de seguridad que realizó en el principal global en el secundario del segundo grupo de disponibilidad:
RESTORE DATABASE [db1] FROM DISK = '<full backup location>' WITH NORECOVERY; RESTORE LOG [db1] FROM DISK = '<log backup location>' WITH NORECOVERY;Una vez que la base de datos de la réplica secundaria del segundo grupo de disponibilidad se encuentre en un estado de restauración, deberá unirla manualmente al grupo de disponibilidad.
ALTER DATABASE [db1] SET HADR AVAILABILITY GROUP = [ag2];
Conmutar por error un grupo de disponibilidad distribuido
Dado que SQL Server 2022 (16.x) introdujo soporte para grupos de disponibilidad distribuidos para la configuración REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT, las instrucciones para realizar la conmutación por error de un grupo de disponibilidad distribuido son distintas en SQL Server 2022 y versiones posteriores de las de SQL Server 2019 y versiones anteriores.
Para un grupo de disponibilidad distribuido, el único tipo de FORCE_FAILOVER_ALLOW_DATA_LOSS compatible es la conmutación por error manual iniciada por el usuario. Por lo tanto, para evitar la pérdida de datos, debe tomar medidas adicionales (descritas en detalle en esta sección) para asegurarse de que los datos estén sincronizados entre las dos réplicas antes de iniciar la conmutación por error.
En caso de emergencia en la que la pérdida de datos sea aceptable, puede iniciar una conmutación por error sin asegurarse de la sincronización de los datos ejecutando:
ALTER AVAILABILITY GROUP distributedAG FORCE_FAILOVER_ALLOW_DATA_LOSS;
Puede usar el mismo comando para realizar la conmutación por error al reenviador, así como para revertirla al primario global.
En SQL Server 2022 (16.x) y versiones posteriores, puede configurar el parámetro REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT de un grupo de disponibilidad distribuido, que está diseñado para garantizar que no se pierdan datos cuando un grupo de disponibilidad distribuido conmuta por error. Si este parámetro está configurado, siga los pasos de esta sección para conmutar por error el grupo de disponibilidad distribuido. Si no desea usar el parámetro REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT, siga las instrucciones para conmutar por error un grupo de disponibilidad distribuido en SQL Server 2019 y versiones anteriores.
Nota:
Si se establece REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT en 1, la réplica principal espera a que las transacciones se confirmen en la réplica secundaria antes de que se confirmen en la réplica principal, lo que puede degradar el rendimiento. Aunque no es necesario limitar o detener transacciones en la base de datos principal global para que el grupo de disponibilidad distribuido se sincronice en SQL Server 2022 (16.x), esto puede mejorar el rendimiento de las transacciones de usuario y la sincronización de grupos de disponibilidad distribuido con REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT establecido en 1.
Pasos para asegurarse de que no hay pérdida de datos
Para asegurarse de que no hay pérdida de datos, primero debe configurar el grupo de disponibilidad distribuido para que no admita ninguna pérdida de datos siguiendo estos pasos:
- Para prepararse para la conmutación por error, verifique que el principal global y el reenviador global estén en modo
SYNCHRONOUS_COMMIT. Si no es así, configúrelos deSYNCHRONOUS_COMMITa ALTER AVAILABILITY GROUP. - Establezca el grupo de disponibilidad distribuido en confirmación sincrónica en el primario global Y en el reenviador.
- Espere hasta que se sincronice el grupo de disponibilidad distribuido.
- En la principal global, establezca la configuración
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITdel grupo de disponibilidad distribuido en 1 mediante ALTER AVAILABILITY GROUP. - Compruebe que todas las réplicas de los grupos de disponibilidad locales y del grupo de disponibilidad distribuido están saludables y que el grupo de disponibilidad distribuido está SINCRONIZADO.
- En la réplica principal global, establezca el rol de grupo de disponibilidad distribuido como
SECONDARY, lo que hace que el grupo de disponibilidad distribuido no esté disponible. - En el reenviador (el nuevo principal previsto), conmute por error el grupo de disponibilidad distribuido mediante ALTER AVAILABILITY GROUP con
FORCE_FAILOVER_ALLOW_DATA_LOSS. - En la nueva secundaria (la réplica principal global anterior), establezca el grupo
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITde disponibilidad distribuido en 0. - Opcional: si los grupos de disponibilidad están a través de una distancia geográfica que provoca latencia, cambie el modo de disponibilidad a
ASYNCHRONOUS_COMMIT. Esto revierte el cambio del primer paso, si es necesario.
Ejemplo de T-SQL
En esta sección se proporcionan los pasos de un ejemplo detallado para hacer failover al grupo de disponibilidad distribuido denominado distributedAG mediante Transact-SQL. El entorno de ejemplo tiene un total de 4 nodos para el grupo de disponibilidad distribuido. La disponibilidad global de los grupos de hosts principales N1 y N2ag1 mientras que la disponibilidad de los grupos de hosts del reenviadorag2N3 y N4
. El grupo de disponibilidad distribuida distributedAG transfiere los cambios de ag1 a ag2.
Consulta para verificar
SYNCHRONOUS_COMMITen los primarios de los grupos de disponibilidad locales que forman el grupo de disponibilidad distribuido. Ejecute el siguiente T-SQL directamente en el reenviador y en el primario global:SELECT DISTINCT ag.name AS [Availability Group], ar.replica_server_name AS [Replica], ar.availability_mode_desc AS [Availability Mode] FROM sys.availability_replicas AS ar INNER JOIN sys.availability_groups AS ag ON ar.group_id = ag.group_id INNER JOIN sys.dm_hadr_database_replica_states AS rs ON ar.group_id = rs.group_id AND ar.replica_id = rs.replica_id WHERE ag.name IN ('ag1', 'ag2') AND rs.is_primary_replica = 1 ORDER BY [Availability Group]; --if needed, to set a given replica to SYNCHRONOUS for node N1, default instance. If named, change from N1 to something like N1\SQL22 ALTER AVAILABILITY GROUP [testag] MODIFY REPLICA ON N'N1\SQL22' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Establezca el grupo de disponibilidad distribuido en confirmación sincrónica ejecutando el siguiente código tanto en el principal global como en el reenviador.
-- sets the distributed availability group to synchronous commit ALTER AVAILABILITY GROUP [distributedAG] MODIFY AVAILABILITY GROUP ON 'ag1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT), 'ag2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Nota:
En un grupo de disponibilidad distribuido, el estado de sincronización entre los dos grupos de disponibilidad depende del modo de disponibilidad de ambas réplicas. Para el modo de confirmación sincrónica, tanto el grupo de disponibilidad principal actual como el grupo de disponibilidad secundario actual deben estar configurados en modo de disponibilidad
SYNCHRONOUS_COMMIT. Por este motivo, debe ejecutar este script tanto en la réplica principal global como en el reenviador.Espere hasta que el estado del grupo de disponibilidad distribuido cambie a
SYNCHRONIZED. Ejecute la consulta siguiente en la principal global:-- Run this query on the Global Primary -- Check the results to see if synchronization_state_desc is SYNCHRONIZED SELECT ag.name, drs.database_id AS [Availability Group], db_name(drs.database_id) AS database_name, drs.synchronization_state_desc, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states AS drs INNER JOIN sys.availability_groups AS ag ON drs.group_id = ag.group_id WHERE ag.name = 'distributedAG' ORDER BY [Availability Group];Continúe después de que el grupo de disponibilidad synchronization_state_desc sea
SYNCHRONIZED.Para SQL Server 2022 (16.x) y versiones posteriores, en la principal global, establezca
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITen 1 mediante el siguiente T-SQL:ALTER AVAILABILITY GROUP distributedAG SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Compruebe que los grupos de disponibilidad están en buen estado en todas las réplicas consultando la principal global y el reenviador:
SELECT ag.name AS [AG Name], db_name(drs.database_id) AS database_name, ar.replica_server_name AS [replica], drs.synchronization_state_desc, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states AS drs INNER JOIN sys.availability_groups AS ag ON drs.group_id = ag.group_id INNER JOIN sys.availability_replicas AS ar ON drs.replica_id = ar.replica_id AND drs.replica_id = ar.replica_id WHERE ag.name IN ('ag1', 'ag2', 'distributedAG');En el principal global, establezca el rol del grupo de disponibilidad distribuido en
SECONDARY. En este punto, el grupo de disponibilidad distribuido no estará disponible. Una vez completado este paso, no podrás revertir el proceso hasta que se realicen el resto de los pasos.ALTER AVAILABILITY GROUP distributedAG SET (ROLE = SECONDARY);Conmutar por error desde la principal global mediante la ejecución de la siguiente consulta en el reenviador para realizar la transición de los grupos de disponibilidad y volver a poner el grupo de disponibilidad distribuido en línea:
-- Run the following command on the forwarder, the SQL Server instance that hosts the primary replica of the secondary availability group. ALTER AVAILABILITY GROUP distributedAG FORCE_FAILOVER_ALLOW_DATA_LOSS;Después de este paso:
- La transición principal global de
N1aN3. - El reenviador pasa de
N3aN1. - El grupo de disponibilidad distribuido está disponible.
- La transición principal global de
En el nuevo reenviador (anterior principal global,
N1), borre la propiedad del grupo de disponibilidad distribuidoREQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITestableciéndola en 0.ALTER AVAILABILITY GROUP distributedAG SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0);OPCIONAL: Si los grupos de disponibilidad se encuentran a través de una distancia geográfica que provoca latencia, considere la posibilidad de volver a cambiar el modo de disponibilidad a
ASYNCHRONOUS_COMMITen ambos, la principal global y el reenviador. Esto revierte el cambio realizado en el primer paso, si es necesario.-- If applicable: sets the distributed availability group to asynchronous commit: ALTER AVAILABILITY GROUP distributedAG MODIFY AVAILABILITY GROUP ON 'ag1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT), 'ag2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT);
Eliminación de un grupo de disponibilidad distribuido
La siguiente instrucción Transact-SQL quita un grupo de disponibilidad distribuido denominado " distributedAG":
DROP AVAILABILITY GROUP distributedAG;
Crear un grupo de disponibilidad distribuido en instancias del clúster de conmutación por error
Puede crear un grupo de disponibilidad distribuido mediante un grupo de disponibilidad en una instancia de clúster de conmutación por error (FCI). En este caso, no necesita un agente de escucha del grupo de disponibilidad. Use el nombre de red virtual (VNN) para la réplica principal de la instancia FCI. El ejemplo siguiente muestra un grupo de disponibilidad distribuido llamado SQLFCIDAG. Uno de los grupos de disponibilidad es SQLFCIAG. SQLFCIAG tiene dos réplicas FCI. El VNN para la réplica FCI principal es SQLFCIAG-1 y el VNN para la réplica FCI secundaria es SQLFCIAG-2. El grupo de disponibilidad distribuido también incluye SQLAG-DR, para recuperación ante desastres.
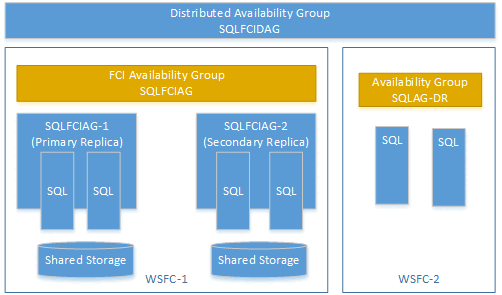
El siguiente DDL crea este grupo de disponibilidad distribuido:
CREATE AVAILABILITY GROUP [SQLFCIDAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-1.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'SQLAG-DR' WITH
(
LISTENER_URL = 'tcp://SQLAG-DR.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
La dirección URL del agente de escucha es el VNN de la instancia de FCI principal.
Conmutar por error el FCI manualmente en el grupo de disponibilidad distribuido
Para conmutar por error manualmente el grupo de disponibilidad FCI, actualice el grupo de disponibilidad distribuido para reflejar el cambio de dirección URL del agente de escucha. Por ejemplo, ejecute el siguiente archivo DDL en la instancia principal global del grupo de disponibilidad distribuido y en el reenviador del grupo de disponibilidad distribuido de SQLFCIDAG:
ALTER AVAILABILITY GROUP [SQLFCIDAG]
MODIFY AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-2.contoso.com:5022'
)