Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server
SQL Server
Un grupo de disponibilidad (AG) distribuido es un tipo especial de grupo de disponibilidad que abarca dos grupos de disponibilidad. Los grupos de disponibilidad distribuidos están disponibles a partir de SQL Server 2016.
En este artículo, se describe la característica de grupos de disponibilidad distribuidos. Para configurar un grupo de disponibilidad distribuido, vea Configure distributed availability groups (Configurar grupos de disponibilidad distribuidos).
Información general
Un grupo de disponibilidad distribuido es un tipo especial de grupo de disponibilidad que abarca dos tipos distintos de grupo de disponibilidad. No es necesario que los grupos de disponibilidad que participan en un grupo de disponibilidad distribuido estén en la misma ubicación. Pueden ser físicos, virtuales, hospedarse localmente, en la nube pública o en cualquier lugar donde se puedan implementar grupos de disponibilidad. Esto incluye grupos entre dominios y entre plataformas, como aquellos entre un grupo de disponibilidad hospedado en Linux y otro hospedado en Windows. Siempre que dos grupos de disponibilidad puedan comunicarse, se podrá configurar un grupo de disponibilidad distribuido con ellos.
Un grupo de disponibilidad tradicional tiene recursos configurados en un clúster de conmutación por error de Windows Server (WSFC) o, si está en Linux, Pacemaker. Un grupo de disponibilidad distribuido no configura nada en el clúster subyacente (ya sea WSFC o Pacemaker). todo se mantiene en SQL Server. Para más información sobre cómo consultar información relativa a un grupo de disponibilidad distribuido, vaya a Ver la información de grupo de disponibilidad distribuido.
Un grupo de disponibilidad distribuido requiere que los grupos de disponibilidad subyacentes tengan un agente de escucha. Al contrario de lo que haría en un grupo de disponibilidad tradicional, en vez de proporcionar el nombre de servidor subyacente de una instancia independiente (o, si se trata de una instancia de clúster de conmutación por error de SQL Server, el valor asociado al recurso de nombre de red), cuando se cree el grupo de disponibilidad distribuido hay que especificar el agente de escucha configurado por medio del parámetro ENDPOINT_URL. Aunque cada grupo de disponibilidad subyacente del grupo de disponibilidad distribuido tiene un agente de escucha, el grupo de disponibilidad distribuido carece de dicho agente.
En la imagen siguiente se muestra una vista general de un grupo de disponibilidad distribuido que abarca dos grupos de disponibilidad (AG 1 y AG 2), cada uno configurado en su propio WSFC. El grupo de disponibilidad distribuido tiene un total de cuatro réplicas, dos en cada grupo de disponibilidad. Cada grupo de disponibilidad puede admitir hasta el número máximo de réplicas, para que un grupo de disponibilidad distribuido pueda tener hasta 18 réplicas en total.

El movimiento de datos en los grupos de disponibilidad distribuidos se puede configurar como sincrónico o como asincrónico. Con todo, el movimiento de datos en el caso de los grupos de disponibilidad distribuidos es ligeramente distinto al de los grupos de disponibilidad tradicionales. A pesar de que cada grupo de disponibilidad tiene una réplica principal, solo hay una copia de las bases de datos que participan en un grupo de disponibilidad distribuido que puede aceptar inserciones, actualizaciones y eliminaciones. Como se aprecia en la siguiente imagen, AG 1 es el grupo de disponibilidad principal. Su réplica principal envía transacciones tanto a las réplicas secundarias de AG 1 como a la réplica principal de AG 2. La réplica principal de AG 2 también se denomina reenviador. Un reenviador es una réplica principal de un grupo de disponibilidad secundario en un grupo de disponibilidad distribuido. El reenviador recibe las transacciones de la réplica principal del grupo de disponibilidad principal y las reenvía a las réplicas secundarias de su propio grupo de disponibilidad. De esta forma, el reenviador mantiene actualizadas las réplicas secundarias de AG 2.
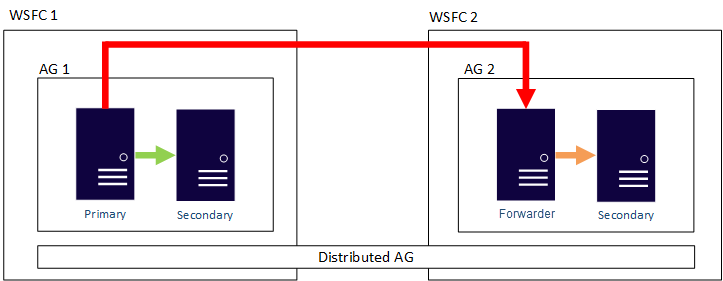
La única manera de que la réplica principal de AG 2 acepte inserciones, actualizaciones y eliminaciones es conmutar por error el grupo de disponibilidad distribuido de AG 1 manualmente. En la imagen anterior, como AG 1 contiene la copia de la base de datos de escritura, cuando se realiza una conmutación por error, AG 2 se convierte en el grupo de disponibilidad que puede controlar las inserciones, actualizaciones y eliminaciones. Para más información sobre cómo realizar una conmutación por error de un grupo de disponibilidad distribuido a otro, vea Conmutación por error a un grupo de disponibilidad secundario.
Nota
- Los grupos de disponibilidad distribuidos en SQL Server 2016 solo admiten la conmutación por error de un grupo de disponibilidad a otro usando la opción
FORCE_FAILOVER_ALLOW_DATA_LOSS. - Al usar la replicación transaccional con grupos de disponibilidad distribuidos, la réplica del reenviador no puede configurarse como publicador.
Cambios de SQL Server 2025
SQL Server 2025 (17.x) presenta los siguientes cambios:
Mejora en la sincronización de AG distribuidos
SQL Server 2025 (17.x) presenta un cambio en el mecanismo de sincronización interno para los grupos de disponibilidad distribuidos para mejorar el rendimiento de sincronización al reducir la saturación de red cuando la réplica del reenviador está en modo de confirmación asincrónica. Este cambio está habilitado de forma predeterminada y no requiere ninguna configuración.
Nota
No se recomienda configurar el grupo de disponibilidad distribuido con un error de coincidencia entre los modos de disponibilidad de los dos grupos de disponibilidad subyacentes y puede introducir latencia de sincronización. Ambos grupos de disponibilidad deben configurarse con el mismo modo de disponibilidad (sincrónico o asincrónico) para garantizar un rendimiento y una sincronización óptimos.
Compatibilidad con grupos de disponibilidad contenidos
SQL Server 2025 (17.x) presenta compatibilidad con un grupo de disponibilidad independiente distribuido. Si piensa usar un grupo de disponibilidad contenido como reenviador en un grupo de disponibilidad distribuido, debe crear el grupo de disponibilidad contenido mediante la cláusula AUTOSEEDING_SYSTEM_DATABASES para la opción WITH | CONTAINED del comando CREATE AVAILABILITY GROUP.
Requisitos de versión y edición
Los grupos de disponibilidad distribuidos de SQL Server 2017 o una versión posterior pueden mezclar versiones principales de SQL Server en el mismo grupo de disponibilidad distribuido. El grupo de disponibilidad que contiene el principal de lectura y escritura puede tener la misma versión (o una inferior) que los demás grupos de disponibilidad que participan en el grupo de disponibilidad distribuido. Los otros grupos de disponibilidad pueden tener la misma versión o versiones posteriores. Este escenario está dirigido a escenarios de actualización y migración. Por ejemplo, si el grupo de disponibilidad que contiene la réplica principal de lectura y escritura es SQL Server 2016, pero quiere actualizar o migrar a SQL Server 2017 o versiones posteriores, el otro grupo de disponibilidad que participa en el grupo de disponibilidad distribuido se puede configurar con SQL Server 2017.
Dado que la característica de grupos de disponibilidad distribuidos no existía en SQL Server 2012 ni en 2014, los grupos de disponibilidad que se crearon con esas versiones no pueden participar en grupos de disponibilidad distribuidos.
Nota
En función de la versión de SQL Server, al conectarse a servicios de Azure (como el vínculo de Managed Instance), es posible configurar un grupo de disponibilidad distribuido con la edición Standard o una combinación de las ediciones Standard y Enterprise. Para obtener más información, revise KB5016729.
Dado que hay dos grupos de disponibilidad diferentes, el proceso para instalar un Service Pack o una actualización acumulativa en una réplica que participa en un grupo de disponibilidad distribuido es ligeramente diferente del de un grupo de disponibilidad tradicional:
Empiece actualizando las réplicas del segundo grupo de disponibilidad del grupo de disponibilidad distribuido.
Aplique revisiones a las réplicas del grupo de disponibilidad principal del grupo de disponibilidad distribuido.
Como haría con un grupo de disponibilidad estándar, conmute por error el grupo de disponibilidad principal a una de sus propias réplicas (y no a la réplica principal del segundo grupo de disponibilidad) y aplíquele las revisiones pertinentes. Si no hay ninguna réplica aparte de la principal, será necesario realizar una conmutación por error manual al segundo grupo de disponibilidad.
Grupos de disponibilidad distribuidos y versiones de Windows Server
Un grupo de disponibilidad distribuido abarca varios grupos de disponibilidad, cada uno en su propio WSFC subyacente, y es una construcción exclusiva de SQL Server. Esto significa que los WSFC en los que se hospedan grupos de disponibilidad individuales pueden tener versiones principales de Windows Server distintas. Las versiones principales de SQL Server deben ser la misma, como se ha indicado en la sección anterior. De forma similar a la imagen inicial, en la siguiente se muestran los grupos AG 1 y AG 2 que participan en un grupo de disponibilidad distribuido, pero cada WSFC pertenece a una versión de Windows Server distinta.
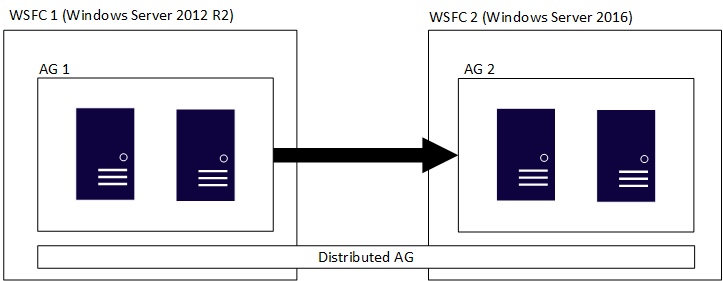
Los WSFC individuales y sus correspondientes grupos de disponibilidad siguen las reglas tradicionales; es decir, pueden estar o no unidos a un dominio (Windows Server 2016 o posterior). Cuando dos grupos de disponibilidad diferentes se combinan en un único grupo de disponibilidad distribuido, hay cuatro escenarios posibles:
- Los dos WSFC están unidos al mismo dominio.
- Cada WSFC está unido a un dominio distinto.
- Un WSFC está unido a un dominio y el otro no.
- Ninguno de los WSFC está unido a un dominio.
Cuando los dos WSFC están unidos al mismo dominio (dominios que no son de confianza) no es necesario hacer nada especial al crear el grupo de disponibilidad distribuido. En el caso de los grupos de disponibilidad y WSFC que no están unidos al mismo dominio, use certificados para que el grupo de disponibilidad distribuido funcione, como haría en gran medida al crear un grupo de disponibilidad para un grupo de disponibilidad independiente del dominio. Para saber cómo configurar certificados para un grupo de disponibilidad distribuido, siga los pasos 3-13 de Create a domain-independent availability group (Crear un grupo de disponibilidad independiente del dominio).
En un grupo de disponibilidad distribuido, las réplicas principales de cada grupo de disponibilidad subyacente deben tener los certificados de todas las demás. Si ya tiene puntos de conexión que no usan certificados, reconfigure esos puntos de conexión con ALTER ENDPOINT para reflejar el uso de certificados.
Escenarios de uso
Estos son los tres escenarios más importantes de uso de un grupo de disponibilidad distribuido:
- Recuperación ante desastres y configuraciones de varios sitios más sencillas
- Migración a un nuevo hardware o nuevas configuraciones, lo que puede conllevar el uso de hardware nuevo o el cambio de los sistemas operativos subyacentes
- Expansión de varios grupos de disponibilidad para aumentar el número de réplicas legibles a más de ocho en un mismo grupo de disponibilidad
Escenarios de recuperación ante desastres y configuraciones de varios sitios
En un grupo de disponibilidad tradicional es necesario que todos los servidores formen parte del mismo WSFC, de modo que la expansión de varios centros de datos puede suponer un desafío. En la siguiente imagen se muestra cómo es una arquitectura de grupo de disponibilidad tradicional de varios sitios, incluido el flujo de datos. No hay una réplica principal que envíe transacciones a todas las réplicas secundarias. Esta configuración es menos flexible en cierto modo que la de un grupo de disponibilidad distribuido. Por ejemplo, tendrá que implementar elementos como Active Directory (si procede) y el testigo de un cuórum en el WSFC. También es posible que deba tener en cuenta otros aspectos de un WSFC, como la modificación de los votos de nodos.

Los grupos de disponibilidad distribuidos ofrecen un escenario de implementación más flexible para los grupos de disponibilidad que abarcan varios centros de datos. Se pueden usar grupos de disponibilidad distribuidos donde antes se usaban características como el trasvase de registros para escenarios como la recuperación ante desastres. Pero, a diferencia del trasvase de registros, los grupos de disponibilidad distribuidos no pueden retrasar la aplicación de transacciones. Esto significa que estos grupos no son de ayuda en caso de que se cometa un error humano por el cual se actualizan o eliminan datos incorrectamente.
El acoplamiento de los grupos de disponibilidad distribuidos es flexible, lo que en este caso significa que no necesitan un único WSFC y que SQL Server los mantiene. Como los WSFC se mantienen de forma individual y la sincronización es básicamente asincrónica entre los dos grupos de disponibilidad, es más fácil configurar la recuperación ante desastres en otro sitio. Las réplicas principales de cada grupo de disponibilidad sincronizan sus propias réplicas secundarias.
- Los grupos de disponibilidad distribuidos solo admiten la conmutación por error manual. En una situación de recuperación ante desastres donde se intercambian centros de datos, conviene no configurar la conmutación automática por error (salvo raras excepciones).
- Probablemente no necesitará establecer algunos de los elementos o parámetros tradicionales de los WSFC de varios sitios o subred (como CrossSubnetThreshold), pero sí sigue siendo necesario tener presente la latencia de red en otra capa para el transporte de datos. La diferencia es que cada WSFC mantiene su propia disponibilidad; el clúster no es una gran entidad de cuatro nodos. Tiene dos WSFC de dos nodos independientes, como se muestra en la imagen anterior.
- Recomendamos el movimiento de datos asincrónico, porque con este método la recuperación ante desastres sería viable.
- Si configura un movimiento de datos sincrónico entre la réplica principal y, al menos, una réplica secundaria del segundo grupo de disponibilidad y un movimiento sincrónico en el grupo de disponibilidad distribuido, el grupo de disponibilidad distribuido esperará hasta que todas las copias sincrónicas confirmen que tienen los datos. Si varios grupos de disponibilidad distribuidos están encadenados (AG1 -> AG2 -> AG3) y se establecen como sincrónicos, un grupo de disponibilidad distribuido esperará hasta que se actualice la última réplica del último grupo de disponibilidad.
Migrar
Los grupos de disponibilidad distribuidos admiten dos configuraciones de grupo de disponibilidad completamente diferentes, lo que permite no solo escenarios de varios sitios y de recuperación ante desastres más sencillos, sino también escenarios de migración. Tanto si va a migrar a un nuevo hardware o máquinas virtuales (locales o IaaS en la nube pública), la configuración de un grupo de disponibilidad distribuido facilita una migración cuando, anteriormente, había que recurrir a trabajos de copia de seguridad, copia y restauración o al trasvase de registros.
La capacidad de migrar es especialmente útil en escenarios donde el sistema operativo subyacente se va a cambiar o a actualizar mientras se mantiene la misma versión de SQL Server. Si bien Windows Server 2016 permite una actualización gradual desde Windows Server 2012 R2 en el mismo hardware, la mayoría de los usuarios opta por implementar nuevo hardware o máquinas virtuales.
Para completar la migración a la nueva configuración, cuando el proceso llegue a su fin, detenga todo el tráfico de datos al grupo de disponibilidad original y cambie el grupo de disponibilidad distribuido al movimiento de datos sincrónico. Con ello, se garantiza que la réplica principal del segundo grupo de disponibilidad va a estar completamente sincronizada, sin perder ningún dato. Tras comprobar la sincronización, conmute por error el grupo de disponibilidad distribuido al grupo de disponibilidad secundario. Para obtener más información, consulte Fail over to a secondary availability group (Conmutación por error de un grupo de disponibilidad secundario).
Después de la migración, cuando el segundo grupo de disponibilidad es ya el nuevo grupo de disponibilidad principal, es posible que tenga que seguir uno de los siguientes pasos:
- Cambiar el nombre del agente de escucha del grupo de disponibilidad secundario (y, posiblemente, eliminar el agente anterior del grupo de disponibilidad principal original o cambiarlo de nombre) o volver a crearlo con el agente de escucha del grupo de disponibilidad principal original, de forma que las aplicaciones y los usuarios puedan acceder a la nueva configuración.
- Si no puede volver a crearlo ni cambiarlo de nombre, dirija las aplicaciones y los usuarios al agente de escucha del segundo grupo de disponibilidad.
Migración a versiones superiores de SQL Server
Durante un escenario de migración, aunque se puede configurar un grupo de disponibilidad distribuido para migrar bases de datos a una instancia de SQL Server de destino que sea de una versión superior a la del origen, hay algunas limitaciones.
Al configurar el grupo de disponibilidad distribuido con una instancia de SQL Server como destino de la migración que es de una versión superior a la del origen, no se admite la propagación automática, por lo que el modo de propagación debe establecerse en MANUAL. Si no deshabilita AUTO-SEEDING, se producirá un error en la migración y verá el error 946 "No se puede abrir la base de datos "DistributionAG" versión xxx. Actualice la base de datos a la versión más reciente" en el registro de errores. Debe establecer el modo de propagación en MANUAL y realizar manualmente una copia de seguridad completa y del registro de transacciones de la base de datos de origen desde el grupo de disponibilidad principal. A continuación, restaure manualmente, junto con el registro de transacciones, en el grupo de disponibilidad secundario. Para obtener más información, revise los pasos de la propagación manual para configurar el grupo de disponibilidad distribuido, así como los scripts para realizar copias de seguridad y restaurar la base de datos del grupo de disponibilidad principal en el grupo de disponibilidad secundario.
Suponiendo que el grupo de disponibilidad secundario (AG2) es el destino de la migración y su versión es superior a la del grupo de disponibilidad principal (AG1), tenga en cuenta las siguientes limitaciones:
- No tendrá acceso de lectura a ninguna de las bases de datos de réplica del grupo de disponibilidad secundario, siempre y cuando el grupo de disponibilidad principal esté en una versión anterior.
- Durante este tiempo, las actualizaciones seguirán fluyendo desde el grupo de disponibilidad principal (AG1) al grupo de disponibilidad secundario (AG2), pero el estado del AG secundario se mostrará como Parcialmente correcto y las bases de datos de las réplicas secundarias del grupo de disponibilidad secundario (AG2) se mostrarán como Sincronizando/En recuperación (incluso si el grupo de disponibilidad está sincronizado con confirmación).
- Una vez que el grupo de disponibilidad distribuido haya conmutado por error a la versión posterior (AG2), el estado de AG2 debe ser Correcto.
- Durante este tiempo, la conmutación por recuperación a AG1 no será posible, ya que se encuentra en una versión anterior.
- Dado que AG1 es de una versión anterior, las actualizaciones de AG2 después de la conmutación por error a AG2 no se replicarán en AG1.
- A partir de aquí, elija si desea retirar el grupo de disponibilidad original (principal) o si desea actualizar AG1 y mantener el grupo de disponibilidad distribuido.
- Si decide retirar AG1, quite el grupo de disponibilidad principal original del grupo de disponibilidad distribuido y el proceso se completará.
- Si decide mantener el grupo de disponibilidad distribuido, actualice la versión de SQL Server de AG1 para que coincida con la de AG2. Una vez actualizado AG1, su estado pasa a ser correcto, el grupo de disponibilidad distribuido pasa a ser correcto también, las réplicas se actualizan para sincronizarse y es posible la conmutación por recuperación.
Escalado horizontal de réplicas legibles
Un solo grupo de disponibilidad distribuido puede tener hasta 16 réplicas secundarias legibles. Esto significa que puede tener hasta 18 copias de lectura, si incluimos las dos réplicas principales de los diferentes grupos de disponibilidad. Este método permite que más de un sitio pueda tener acceso casi en tiempo real para notificar a diversas aplicaciones.
Con los grupos de disponibilidad distribuidos, el escalado horizontal de una granja de servidores de solo lectura es más fácil que con simplemente un único grupo de disponibilidad. Un grupo de disponibilidad distribuido puede escalar réplicas legibles horizontalmente de dos maneras:
- Se puede usar la réplica principal del segundo grupo de disponibilidad de un grupo de disponibilidad distribuido para crear otro grupo de disponibilidad distribuido, aun cuando la base de datos no esté en estado RECOVERY.
- También puede usar la réplica principal del primer grupo de disponibilidad para crear otro grupo de disponibilidad distribuido.
Dicho de otro modo, una réplica principal puede participar en grupos de disponibilidad distribuidos diferentes. En la siguiente imagen se muestran dos grupos, AG 1 y AG 2, y ambos participan en el grupo distribuido AG 1, mientras que AG 2 y AG 3 participan en el grupo distribuido AG 2. La réplica principal (o reenviador) de AG 2 es al mismo tiempo una réplica secundaria del grupo Distributed AG 1 y una réplica principal del grupo Distributed AG 2.
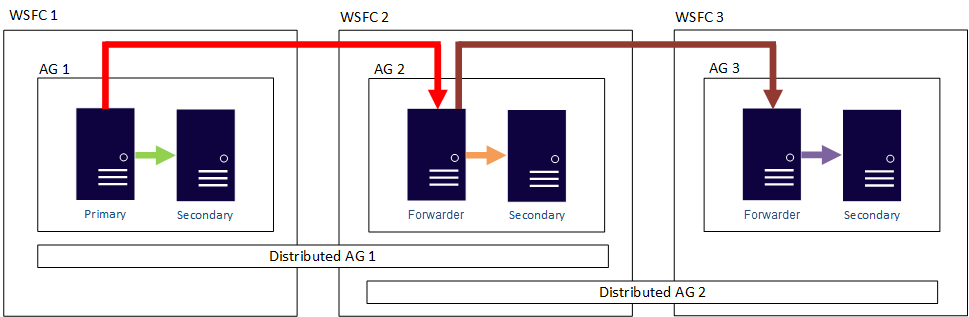
En la siguiente imagen, AG 1 es la réplica principal de dos grupos de disponibilidad distribuidos diferentes: Distributed AG 1 (compuesto por AG 1 y AG 2) y Distributed AG 2 (compuesto por AG 1 y AG 3).
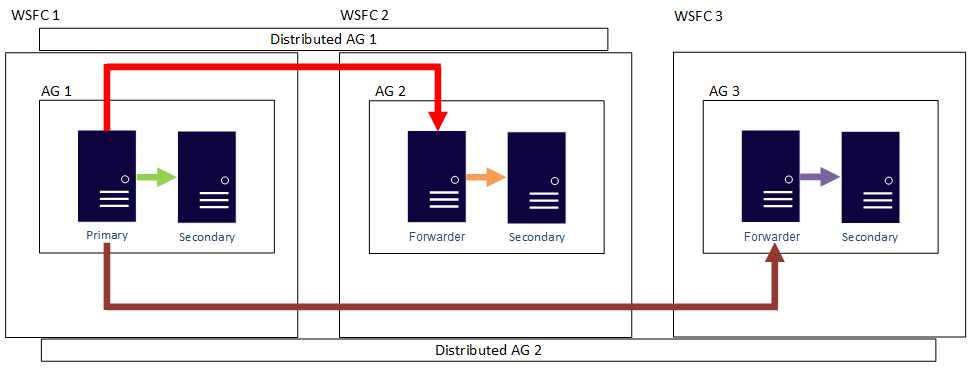
En los dos ejemplos anteriores, puede haber hasta 27 réplicas en total entre los tres grupos de disponibilidad, y todas ellas se pueden usar para consultas de solo lectura.
El enrutamiento de solo lectura no funciona completamente con los grupos de disponibilidad distribuidos. Más concretamente:
- El enrutamiento de solo lectura se puede configurar, y funcionará con el grupo de disponibilidad principal del grupo de disponibilidad distribuido.
- El enrutamiento de solo lectura se puede configurar, pero no funcionará con el grupo de disponibilidad secundario del grupo de disponibilidad distribuido. Todas las consultas, si usan el agente de escucha para conectarse al grupo de disponibilidad secundario, irán a la réplica principal del grupo de disponibilidad secundario. Si no, tendrá que configurar cada réplica para permitir todas las conexiones como una réplica secundaria y tener acceso a ellas directamente. A pesar de ello, el enrutamiento de solo lectura funcionará si el grupo de disponibilidad secundario se convierte en principal tras una conmutación por error. Este comportamiento podría cambiar en una actualización de SQL Server 2016 o en una versión futura de SQL Server.
Inicialización de grupos de disponibilidad secundarios
Los grupos de disponibilidad distribuidos están diseñados con la propagación automática como método principal para inicializar la réplica principal en el segundo grupo de disponibilidad. Si hace lo siguiente, realizará una restauración de base de datos completa en la réplica principal del segundo grupo de disponibilidad:
- Restaure las copias de seguridad de las bases de datos con WITH NORECOVERY.
- Si procede, restaure las copias de seguridad de registro de transacciones apropiadas con WITH NORECOVERY.
- Cree el segundo grupo de disponibilidad sin especificar un nombre de base de datos y con SEEDING_MODE establecido en AUTOMATIC.
- Cree el grupo de disponibilidad distribuido por medio de la propagación automática.
Cuando la réplica principal del segundo grupo de disponibilidad se agrega al grupo de disponibilidad distribuido, dicha réplica se compara con las bases de datos principales del primer grupo de disponibilidad y la propagación automática detecta la base de datos hasta el origen. Existen varios inconvenientes:
El resultado que consta en
sys.dm_hadr_automatic_seedingen la réplica principal del segundo grupo de disponibilidad mostrarácurrent_statecomo FAILED con el motivo "Seeding Check Message Timeout" (se agotó el tiempo de espera del mensaje de comprobación de propagación).El registro de errores de SQL Server actual de la réplica principal del segundo grupo de disponibilidad reflejará que la propagación automática ha funcionado y que los LSN se sincronizaron.
El resultado que consta en
sys.dm_hadr_automatic_seedingen la réplica principal del primer grupo de disponibilidad mostrará current_state como COMPLETED.La propagación automática tiene un comportamiento distinto también con los grupos de disponibilidad distribuidos. Para que la propagación automática comience en la segunda réplica, hay que emitir el comando
ALTER AVAILABILITY GROUP [AGName] GRANT CREATE ANY DATABASEen la réplica. Aunque esto sigue siendo así en cualquier réplica secundaria que participa en el grupo de disponibilidad subyacente, la réplica principal del segundo grupo de disponibilidad ya tiene los permisos adecuados para permitir que la propagación automática se inicie después de que se haya agregado al grupo de disponibilidad distribuido.
Nota
- El grupo de disponibilidad secundario debe usar el mismo punto de conexión de reflejo de bases de datos. De lo contrario, la replicación se detiene después de una conmutación por error local.
- Los grupos de disponibilidad subyacentes deben estar en el mismo modo de disponibilidad: ambos grupos de disponibilidad deben estar en modo de confirmación sincrónica o ambos deben estar en modo de confirmación asincrónica. Si no está seguro de cuál usar, establezca ambos en modo de confirmación asincrónica hasta que esté listo para realizar un failover.
Supervisión del mantenimiento
Un grupo de disponibilidad distribuido es una construcción solo de SQL Server y no se ve en el WSFC subyacente. En el siguiente ejemplo de código aparecen dos WSFC distintos (CLUSTER_A y CLUSTER_B), cada uno con sus propios grupos de disponibilidad. Aquí solo nos centraremos en AG1 en CLUSTER_A y en AG2 en CLUSTER_B.
PS C:\> Get-ClusterGroup -Cluster CLUSTER_A
Name OwnerNode State
---- --------- -----
AG1 DENNIS Online
Available Storage GLEN Offline
Cluster Group JY Online
New_RoR DENNIS Online
Old_RoR DENNIS Online
SeedingAG DENNIS Online
PS C:\> Get-ClusterGroup -Cluster CLUSTER_B
Name OwnerNode State
---- --------- -----
AG2 TOMMY Online
Available Storage JC Offline
Cluster Group JC Online
Toda la información detallada sobre un grupo de disponibilidad distribuido está en SQL Server, concretamente en las vistas de administración dinámica de grupos de disponibilidad. Actualmente, la única información que se muestra en SQL Server Management Studio sobre un grupo de disponibilidad distribuido está disponible en la réplica principal de los grupos de disponibilidad. Tal como se muestra en la figura siguiente, en la carpeta Grupos de disponibilidad, SQL Server Management Studio muestra que hay un grupo de disponibilidad distribuido. La figura muestra GD1 como una réplica principal de un grupo de disponibilidad específico que se encuentra en la instancia en lugar de un grupo de disponibilidad distribuido.
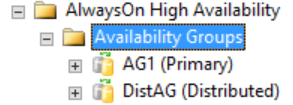
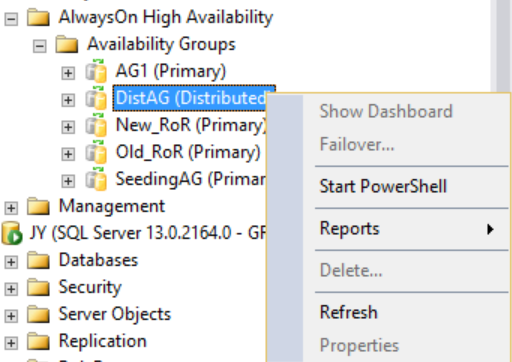
En cambio, si hace clic con el botón derecho en el grupo de disponibilidad distribuido, no se mostrará ninguna opción (consulte la figura siguiente), mientras que las carpetas expandidas Bases de datos de disponibilidad, Agentes de escucha de grupos de disponibilidad y Réplicas de disponibilidad estarán vacías. SQL Server Management Studio 16 muestra este resultado, pero puede cambiar en una versión futura de la herramienta.
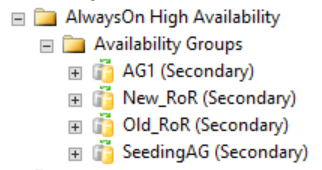
Tal como se muestra en la figura siguiente, las réplicas secundarias no muestran ningún elemento relacionado con el grupo de disponibilidad distribuido en SQL Server Management Studio. Estos nombres de grupo de disponibilidad se ajustan a los roles que se muestran en la imagen del WSFC CLUSTER_A anterior.
DMV para enumerar todos los nombres de réplica de disponibilidad
Al usar las vistas de administración dinámica, se aplican los mismos conceptos. Mediante el uso de la consulta siguiente, puede ver todos los grupos de disponibilidad (normales y distribuidos), así como los nodos implicados. Este resultado se muestra solo si realiza una consulta a la réplica principal en uno de los WSFC que forman parte del grupo de disponibilidad distribuido. Hay una nueva columna en la vista de administración dinámica sys.availability_groups denominada is_distributed, que es 1 cuando el grupo de disponibilidad es del tipo distribuido. Para ver esta columna:
-- shows replicas associated with availability groups
SELECT
ag.[name] AS [AG Name],
ag.Is_Distributed,
ar.replica_server_name AS [Replica Name]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id;
GO
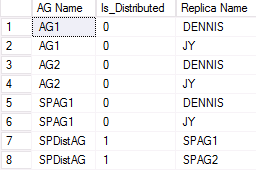
En la figura siguiente se muestra un ejemplo de salida desde el segundo WSFC que participa en un grupo de disponibilidad distribuido. SPAG1 se compone de dos réplicas: DENNIS y JY. En cambio, el grupo de disponibilidad distribuido denominado SPDistAG contiene los nombres de los dos grupos de disponibilidad implicados (SPAG1 y SPAG2) en lugar de los nombres de las instancias, al igual que sucede con un grupo de disponibilidad tradicional.
DMV para enumerar el estado del grupo de disponibilidad distribuido
En SQL Server Management Studio, cualquier tipo de estado que se muestra en el panel y en otras áreas está diseñado para la sincronización local solo dentro del grupo de disponibilidad. Para mostrar el estado de un grupo de disponibilidad distribuido, consulte las vistas de administración dinámica. La consulta de ejemplo siguiente amplía y mejora la consulta anterior:
-- shows sync status of distributed AG
SELECT
ag.[name] AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [Underlying AG],
ars.role_desc AS [Role],
ars.synchronization_health_desc AS [Sync Status]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

DMV para ver el rendimiento subyacente
Para ampliar aún más la consulta anterior, también puede ver el rendimiento subyacente mediante las vistas de administración dinámica agregando sys.dm_hadr_database_replicas_states. La vista de administración dinámica actualmente solo almacena información sobre el segundo grupo de disponibilidad. La consulta de ejemplo siguiente, al ejecutarse en el grupo de disponibilidad principal, genera el resultado de ejemplo que se muestra a continuación:
-- shows underlying performance of distributed AG
SELECT
ag.[name] AS [Distributed AG Name],
ar.replica_server_name AS [Underlying AG],
dbs.[name] AS [Database],
ars.role_desc AS [Role],
drs.synchronization_health_desc AS [Sync Status],
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate
FROM sys.databases AS dbs
INNER JOIN sys.dm_hadr_database_replica_states AS drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups AS ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

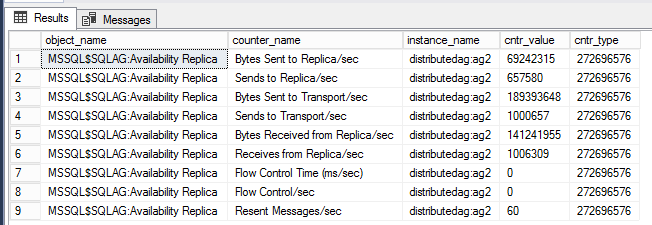
DMV para ver los contadores de rendimiento para el grupo de disponibilidad distribuido
En la siguiente consulta se muestran contadores de rendimiento asociados con el grupo de disponibilidad distribuido específico.
-- displays OS performance counters related to the distributed ag named 'distributedag'
SELECT * FROM sys.dm_os_performance_counters WHERE instance_name LIKE '%distributed%'
Nota
El filtro LIKE debería tener el nombre del grupo de disponibilidad distribuido. En este ejemplo, el nombre del grupo de disponibilidad distribuido es "distributedag". Cambie el modificador LIKE para que refleje el nombre del grupo de disponibilidad distribuido.
DMV para mostrar el estado tanto del grupo de disponibilidad como del grupo de disponibilidad distribuido
En la siguiente consulta se muestra una gran cantidad de información sobre el estado tanto del grupo de disponibilidad como del grupo de disponibilidad distribuido. (Reproducido con permiso de Tracy Boggiano).
-- displays sync status, send rate, and redo rate of availability groups,
-- including distributed AG
SELECT ag.name AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [AG],
dbs.name AS [Database],
ars.role_desc,
drs.synchronization_health_desc,
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate,
drs.suspend_reason_desc,
drs.last_sent_time,
drs.last_received_time,
drs.last_hardened_time,
drs.last_redone_time,
drs.last_commit_time,
drs.secondary_lag_seconds
FROM sys.databases dbs
INNER JOIN sys.dm_hadr_database_replica_states drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas ar
ON ar.replica_id = ars.replica_id
--WHERE ag.is_distributed = 1
GO

DMV para ver los metadatos del grupo de disponibilidad distribuido
En las consultas siguientes se mostrará información sobre las direcciones URL de punto de conexión utilizadas por los grupos de disponibilidad, incluido el grupo de disponibilidad distribuido. (Reproducido con permiso de David Barbarin).
-- shows endpoint url and sync state for ag, and dag
SELECT
ag.name AS group_name,
ag.is_distributed,
ar.replica_server_name AS replica_name,
ar.endpoint_url,
ar.availability_mode_desc,
ar.failover_mode_desc,
ar.primary_role_allow_connections_desc AS allow_connections_primary,
ar.secondary_role_allow_connections_desc AS allow_connections_secondary,
ar.seeding_mode_desc AS seeding_mode
FROM sys.availability_replicas AS ar
JOIN sys.availability_groups AS ag
ON ar.group_id = ag.group_id;
GO

DMV para mostrar el estado actual de la propagación
En la siguiente consulta se muestra información sobre el estado actual de la propagación. Esto es útil para solucionar errores de sincronización entre réplicas. (Reproducido con permiso de David Barbarin).
-- shows current_state of seeding
SELECT ag.name AS aag_name,
ar.replica_server_name,
d.name AS database_name,
has.current_state,
has.failure_state_desc AS failure_state,
has.error_code,
has.performed_seeding,
has.start_time,
has.completion_time,
has.number_of_attempts
FROM sys.dm_hadr_automatic_seeding AS has
INNER JOIN sys.availability_groups AS ag
ON ag.group_id = has.ag_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = has.ag_remote_replica_id
INNER JOIN sys.databases AS d
ON d.group_database_id = has.ag_db_id;
GO
