Andmete importimis- ja eksportimistööde ülevaade
Andmete importimise ja eksportimise tööde loomiseks ja haldamiseks kasutage andmehaldus tööruumi. Vaikimisi loob andmeimpordi ja -ekspordi protsess igale sihtandmebaasi üksusele koondamistabeli. Vahetatabelid lasevad teil andmeid enne teisaldamist kontrollida, puhastada või teisendada.
Paberraha
See artikkel eeldab, et olete andmeüksustega tutvunud.
Andmete importimis-/eksportimisprotsess
Siin on toimingud andmete importimiseks või eksportimiseks.
Looge impordi- või eksporditöö, kus tuleb teha järgmised toimingud.
- Määratlege projekti kategooria.
- Näidake ära imporditavad või eksporditavad üksused.
- Määrake töö andmevorming.
- Järjesta üksused nii, et neid töödeldakse loogilistes gruppides ja järjekorras, mis on loogilised.
- Määrale, kas kasutada koondamistabeleid.
Kontrollige, kas lähte- ja sihtandmed on õigesti vastendatud.
Kontrollige impordi- või eksporditöö turvalisust.
Käivitage impordi- või eksporditöö.
Kontrollige, et töö toimus õigesti, vaadates üle töö ajaloo.
Puhastage koondamistabelid.
Selle artikli ülejäänud jaotistest leiate lisateavet iga samm kohta.
Paberraha
Andmete importimise/eksportimise vormi värskendamiseks ja uusima edenemise kuvamiseks kasutage vormi värskendamise ikooni. Brauseri taseme värskendus pole soovitatav, kuna see katkestab mis tahes impordi-/eksporditööd, mida partiina ei käitata.
Impordi- või eksporditöö loomine
Andmete impordi- või eksporditöö saab käitada ühe korra või palju kordi.
Projekti kategooria määratlemine
Soovitame võtta aega, et valida impordi- või eksporditööle sobiv projektikategooria. Projektikategooriate abil saate seotud töid hallata.
Imporditavate või eksporditavate üksuste tähistamine
Saate lisada impordi- või eksporditööle konkreetseid üksusi või valida rakendamiseks malli. Mallid täidavad töö üksuste loendiga. Valik Malli rakendamine on saadaval pärast sellele tööle nime andmist ja töö salvestamist.
Töö andmevormingu määramine
Kui valite üksuse, peate valima eksporditud või imporditud andmete vormingu. Vormingud saate määratleda andmeallikate häälestuse paani abil. Lähteandmete vorming on kombinatsioon tüübist, failivormingust , reaeraldajast ja veerueraldajast . On olemas teisi, kuid need atribuudid on põhiatribuudid, mida mõista. Järgmises tabelis on toodud kehtivad kombinatsioonid.
| Failivorming | Rea-/veerueraldaja | XML-i laad |
|---|---|---|
| Excel | Excel | -NA- |
| XML | -NA- | XML-element XML-atribuut |
| Eraldatud, fikseeritud laius | Koma, semikoolon, vahekaart, vertikaalriba, koolon | -NA- |
Paberraha
Kui suvand Failivorming on seatud valikule Eraldatud, on oluline valida reaeraldaja, veerueraldaja ja teksti täpifikaatori jaoks õige väärtus. Kontrollige, et teie andmed ei sisaldaks eraldajana või täpindina kasutatavat märki, kuna see võib importimise ja eksportimise ajal põhjustada tõrkeid.
Paberraha
XML-põhiste failivormingute puhul kasutage kindlasti ainult õigusmärke. Lisateavet kehtivate märkide kohta vt XML 1.0 kehtiv märgist. XML 1.0 ei luba juhtmärke peale vahekaartide, tagastuste ja rea söötmete. Lubamatute märkide näited on nurksulud, curly sulgud ja kaldkriipsud.
Andmete importimiseks või eksportimiseks kasutage kindla koodilehe asemel Unicode’i vormingut. See aitab anda kõige ühtsemaid tulemusi ja eemaldada andmehaldus nurjumise, kuna need sisaldavad Unicode’i märke. Süsteemi määratletud lähteandmete vormingutes, mis kasutavad Unicode’i vorminguid, on lähtenimes Unicode’i vormingus. Unicode-vormingu valite vahekaardil Regional settings (Piirkonnasätted) koodilehena Unicode’i kodeerimise ANSI koodilehe. Valige Unicode’i jaoks üks järgmistest koodilehtedest:
| Koodileht | Kuvatav nimi |
|---|---|
| 1200 | Unicode |
| 12000 | Unicode (UTF-32) |
| 12001 | Unicode (UTF-32 Big-Endian) |
| 1201 | Unicode (Big-Endian) |
| 65000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |
Lisateavet koodilehtede kohta vt Koodilehe ID-dest.
Üksuste järjestamine
Üksusi saab järjestada andmemallis või impordi- ja eksporditöödes. Kui käivitate mitut andmeüksust sisaldava töö, peate veenduma, et andmeüksused oleksid õiges järjestuses. Üksused järjestatakse peamiselt nii, et saaksite käsitleda funktsionaalseid sõltuvusi üksuste vahel. Kui üksustel pole ühtegi funktsionaalset sõltuvust, saab need plaanida paralleelseks impordiks või ekspordiks.
Käivitamise ühikud, tasemed ja järjestused
Üksuse käivitamise ühik, tase käivitamise ühikus ja järjekord aitavad juhtida andmete eksportimise või importimise järjekorda.
- Erinevate käivitamise ühikute üksusi töödeldakse paralleelselt.
- Igas käivitamise ühikus töödeldakse üksusi paralleelselt, kui neil on sama tase.
- Igal tasemel töödeldakse üksusi nende järjekorranumbri alusel sellel tasemel.
- Pärast ühe taseme töötlemist töödeldakse järgmist taset.
Ümberjärjestamine
Üksusi võib olla vaja ümber järjestada järgmistes olukordades.
- Kui kõigi muudatuste jaoks kasutatakse ainult ühte andmetööd, võite kasutada ümberjärjestamise valikuid terve töö läbiviimise aja optimeerimiseks. Nendel juhtudel võite kasutada käivitamise ühikut mooduli tähistamiseks, taset mooduli funktsiooniala tähistamiseks ja järjekorda üksuse tähistamiseks. Selle lähenemisega saate töötada moodulite lõikes paralleelselt, kuid mooduli sees ikka järjekorras. Tagamaks, et paralleelsed toimingud õnnestuksid, tuleb arvestada kõiki sõltuvusi.
- Kui kasutatakse mitut andmetööd (näiteks ühte tööd iga mooduli jaoks), võite optimaalseks läbiviimiseks kasutada järjestust, mis mõjutab üksuste taset ja järjekorda.
- Kui sõltuvusi polegi, võite maksimaalseks optimeerimiseks järjestada üksused erinevatel käivitamise ühikutel.
Järjestusmenüü on saadaval , kui on valitud mitu olemit. Ümber saab järjestada käivitamise ühiku, taseme või järjekorravalikute alusel. Saate seadistada juurdekasvu valitud üksuste vaheldamiseks. Igale üksusele valitud ühik, tase ja/või seerianumber värskendatakse määratud juurdekasvu järgi.
Sorteerimine
Üksuseloendi kuvamiseks jadajärjestuses saate kasutada suvandit Sortimisjärjestus.
Kärpimine
Saate projektide importimisel enne importimist üksuste kirjeid kärpida. Kärpimine on kasulik, kui teie kirjed tuleb importida tabelite puhastuskomplekti. Vaikimisi on see säte välja lülitatud.
Kontrollimine, kas lähte- ja sihtandmed on õigesti vastendatud
Vastendamine on funktsioon, mida rakendatakse nii impordi- kui ka eksporditööde puhul.
- Imporditöö kontekstis kirjeldab vastendus, millistest lähtefaili veergudest saavad koondamistabeli veerud. Seetõttu saab süsteem määratleda, millised lähtefaili veeruandmed tuleb kopeerida millisesse koondamistabeli veergu.
- Eksporditöö kontekstis kirjeldab vastendus, millistest koondamistabeli (st allika) veergudest saavad sihtfaili veerud.
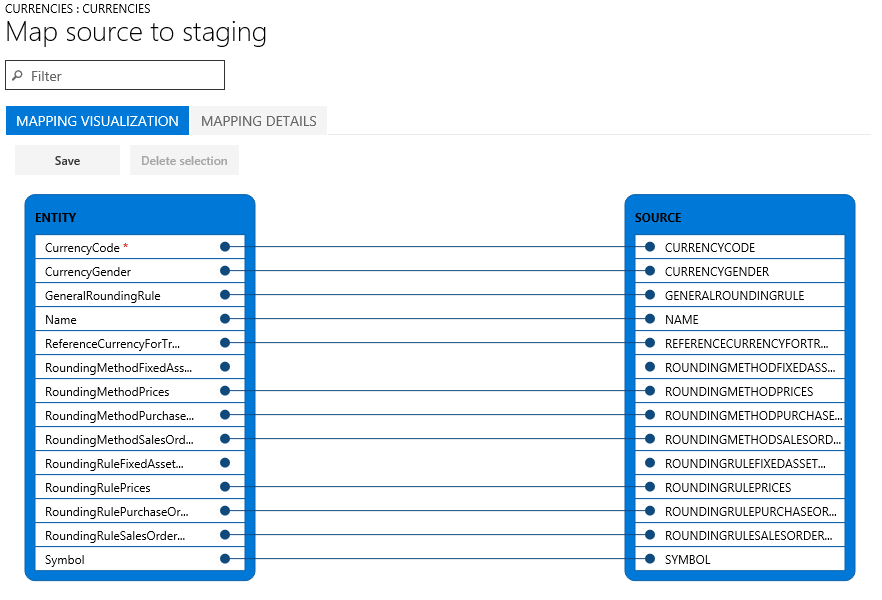
Kui koondamistabeli ja faili veergude nimed ühtivad, loob süsteem nimede põhjal automaatselt vastenduse. Kuid kui nimed erinevad, ei vastendata veerge automaatselt. Sellisel juhul peate lõpule vastendamine, valides andmetöö üksusel suvandi Kuva kaart.
Vaateid vastendamine on kaks: vastendamine, mis on vaikevaade, ja vastendamine üksikasju. Punane tärn (*) tuvastab üksuses nõutavad väljad. Need väljad tuleb vastendada, enne kui saate üksusega töötada. Teiste väljade vastendusi saab üksusega töötades soovi kohaselt tühistada. Väljade kustutamiseks valige väli veerus Üksus või Lähteüksusja seejärel valige suvand Kustuta . Muudatuste salvestamiseks klõpsake nuppu Salvesta ja sulgege projekti naasmiseks lehekülg. Saate kasutada sama protsessi, et redigeerida välja vastendamine allikast ajastamisse pärast importimist.
Lehel saate luua vastendamine loo uus kirje, valides käsu Loo vastendamine. Loodud vastendus toimib nagu automaatne vastendus. Seega tuleb vastendamata väljad käsitsi vastendada.
Impordi- või eksporditöö turvalisuse kontrollimine
Juurdepääsu tööruumile andmehaldus piirata, nii et mitteadministraatorkasutajad pääsevad juurde ainult konkreetsetele andmetöödele. Juurdepääs andmetööle tähendab täielikku juurdepääsu selle töö läbiviimise ajaloole ja juurdepääsu koondamistabelitele. Seetõttu tuleb veenduda, et andmetöö loomisel oleksid paigas sobivad juurdepääsu kontrollimismehhanismid.
Töö kaitsmine rollide ja kasutajatega
Kasutage menüüd Kohaldatavad rollid, et piirata töö ühe või mitme turberolliga. Juurdepääs tööle on ainult nende rollide kasutajatel.
Samuti saab töö teha kättesaadavaks ainult konkreetsetele kasutajatele. Kui turvate tööd rollide asemel kasutajate poolt, on kontrollim rohkem, kas rollile on määratud mitu kasutajat.
Töö turve juriidilise isiku alusel
Andmetööd on olemuselt globaalsed. Seega, kui andmetöö loodi ja seda kasutatakse juriidilises isikus, on töö nähtav süsteemi teistes juriidilistes isikutes. Mõnes rakenduse stsenaariumis võib see vaikekäitumine eelistatud olla. Näiteks organisatsioonis, kus arveid imporditakse andmeüksuste abil, võib olla tsentraalne arveid töötlev töörühm, mis vastutab kõigi organisatsiooni divisjonide arvetel olevate vigade eest. Selles stsenaariumis on abiks, kui tsentraalne arveid töötlev töörühm pääseb juurde kõigi juriidiliste isikute arvete imporditöödele. Seetõttu vastab vaikekäitumine juriidilise isiku vaatepunktist vajadustele.
Kuid organisatsioon võib soovida, et arvete töötlemise töörühmad oleksid juriidilise isiku põhised. Sel juhul peaks juriidilise isiku töörühmal olema juurdepääs ainult oma juriidilise isiku arve imporditööle. Selle nõude täitmiseks saate konfigureerida andmetöödele juurdepääsu kontrolli juriidilise isiku alusel, kasutades andmetöös sisemist rakendatavate juriidiliste isikute menüüd. Pärast konfiguratsiooni loomist saavad kasutajad näha ainult töid, mis on saadaval juriidilises isikus, kus nad on hetkel sisse logitud. Teise juriidilise isiku tööde vaatamiseks peavad kasutajad minema sellesse juriidilisse isikusse.
Töö saab kaitsta korraga rollide, kasutajate ja juriidiliste isikute kaudu.
Impordi- või eksporditöö käivitamine
Tööd saate käitada üks kord, kui pärast töö määratlemist valite nupu Impordi või Ekspordi. Korduva töö häälestamiseks valige suvand Loo korduvad andmed.
Paberraha
Importimist või eksporditööd saab käitada, klõpsates nuppu Impordi või Ekspordi . Selle toiminguga planeeritakse pakett-töö käitamine ainult ühe korra. Töö ei pruugi kohe käivituda, kui partii teenus on partii teenuse koorma tõttu ahendatud. Töid saab käitada ka sünkroonselt, valides suvandi Impordi kohe või Ekspordi kohe. See käivitab töö kohe ja on kasulik siis, kui pakett ahendamise tõttu kohe ei käivitu. Tööde käivitamine on võimalik ajastada ka hilisemaks. Seda saab teha, valides suvandi Käivita partiis . Paketiressursid kuuluvad ahendamisele, seega pakett-töö ei tarvitse kohe käivituda. Partii kasutamine on soovitatav valik, kuna aitab kaasa suurte andmemahtude korral, mis tuleb importida või eksportida. Pakett-töid saab planeerida käivituma kindlate paketigruppide korral, mis koormuse ühtlustamise seisukohast võimaldab suuremat kontrolli.
Kontrollimine, et töö toimus õigesti
Töö ajalugu on tõrkeotsinguks ja uurimiseks saadaval nii impordi- kui ka eksporditööde puhul. Varasemad töötsüklid on korraldatud ajavahemike alusel.
Iga töötsükli puhul kuvatakse järgmised andmed.
- Käivitamise üksikasjad
- Käivituslogi
Käivitamise üksikasjad näitavad iga töös töödeldud andmeüksuse olekut. Seetõttu leiate kiiresti järgmise teabe.
- Milliseid üksusi töödeldi
- Üksuse puhul – mitu kirjet töödeldi edukalt ja mitu ebaõnnestus
- Iga üksuse koondamiskirjed
Koondamisandmed saab laadida eksporditööde puhul alla failina või impordi- ja eksporditööde puhul paketina.
Käivitamise üksikasjadest saab avada ka käivituslogi.
Paralleelne importimine
Andmete importimise kiirendamiseks saab lubada faili importimise paralleelse töötlemise, kui üksus toetab paralleelset importimist. Üksuse paralleelse importimise konfigureerimiseks tuleb järgida järgmisi samme.
Minge jaotisse Süsteemihaldus > Tööruumid > Andmehaldus.
Jaotises Import /Eksport valige raamistiku parameetrite paani, et avada lehte Andmete importimise/eksportimise raamistiku parameetrid .
Vahekaardil Üksuse sätted valige suvand Konfigureeri üksuse käivitamise parameetrid, et avada lehte Üksuse importimise käivitamise parameetrid .
Üksuse paralleelse importimise konfigureerimiseks määrake järgmised väljad.
- Valige üksus väljal Üksus. Kui üksuse väli on tühi, kasutatakse kõigi järgnevate importide vaikesätteks tühja väärtust, kui üksus toetab paralleeli importi.
- Sisestage lävekirjete loenduse väljale Impordi lävekirjete arv importimiseks. See määratleb kirjete arvu, mida lõim töötlema hakkab. Kui failis on 10 K-kirjet, loetakse 2500 kirjet ülesandeloendusega neljaks tähendab, et iga lõime töötleb 2500 kirjet.
- Sisestage impordiülesande loenduse väljale Impordiülesanded. Arv ei tohi ületada system administration Serveri konfiguratsioonis pakktöötluseks eraldatud maksimaalset partii lõime >.
Tööajaloo puhastus
Vaikimisi kustutatakse automaatselt töö ajaloo kirjed ja seotud ajatabeli andmed, mis on vanemad kui 90 päeva. Tööajaloo puhastamisfunktsiooni saab andmehaldus kasutada käivitamisajaloo perioodilise puhastamise konfigureerimiseks, mille puhul on vaikimisi perioodiline kinnipidamisperiood väiksem. See funktsioon asendab eelmise vahetamistabeli puhastusfunktsiooni, mis on nüüd taunitav. Puhastusprotsess puhastab järgmised tabelid.
Kõik koondamistabelid
DMFSTAGINGVALIDATIONLOG
DMFSTAGINGEXECUTIONERRORS
DMFSTAGINGLOGDETAIL
(DMFSTAGINGLOG)
DMFDEFINITIONGROUPEXECUTIONHISTORY
DMFEXECUTION
DMFDEFINITIONGROUPEXECUTION
Käivitamisajaloo puhastamisfunktsioonile pääseb juurde andmehaldus Tööajaloo puhastamisest > .
Parameetrite planeerimine
Puhastusprotsessi plaanimisel peavad puhastuskriteeriumi määratlemiseks olema määratud järgmised parameetrid.
Ajaloo säilitamise päevade arv – seda sätet kasutatakse säilitatava täitmisajaloo summa katteks. Ajalugu määratakse päevade arvuna. Kui puhastustöö on planeeritud korduva pakett-tööna, toimib see säte nagu pidev teisaldamise aken, jättes seega määratud arvu päevade ajaloo kustutamata. Vaikeseadeks on 7 päeva.
Töö teostamise tundide arv – sõltuvalt puhastatava ajaloo kogusest võib puhastustöö kogu täitmisaeg olla mõne minuti kuni mõne tunni vahel. Selle parameetri väärtuseks peab olema seatud töö täitmistundide arv. Pärast seda, kui puhastustöö on määratud arvu tundide jooksul teostatud, on töö olemas ja puhastamist jätkatakse järgmisel korral, kui see kordumise graafiku alusel käivitatakse.
Maksimaalse käivitusaja saab määrata, sätestades maksimumpiirangu tundide arvule, mille jooksul töö peab selle sätte abil käivitama. Puhastusloogika peab läbima ühe töö käivitamise ID ajal kronoloogiliselt korraldatud järjekorras. Vanim on seotud täitmisajaloo puhastamiseks. See peatab puhastamiseks uute käivitamise ID-de komplekteerimise, kui järelejäänud käivitamise kestus jääb määratud kestuse viimasesse 10% piiresse. Mõnel juhul jätkub puhastustöö pärast määratud maksimumaega. See kestus sõltub kirjete arvust, mis kustutatakse praeguse käivitamise ID kohta, mis käivitati enne 10% läveni jõudmist. Andmete terviklikkuse tagamiseks tuleb käivitatav puhastus lõpule viia, mis tähendab, et puhastamine jätkub vaatamata määratud piiri ületamisele. Kui see on lõpule viidud, siis uusi käivitamise ID-sid ei komplekteeritud ja puhastustöö on lõpetatud. Järelejääv käivitamisajalugu, mida ei puhastatud piisava täitmisaja puudumise tõttu, komplekttakse peale järgmisel puhastamistöö plaanimise korral. Selle sätte vaikeväärtus ja miinimumväärtus on seatud 2 tunniks.
Korduv pakett - puhastustööd saab käitada ühekordsena, käsitsi käivitades või saab seda ka korduvaks käivitamiseks pakett-tööna. Partii saab planeerida, kasutades taustaseadistust , mis on standardne partiiseadistus.
Paberraha
Kui tööajaloo puhastamise funktsiooni ei kasutata, kustutatakse automaatselt ka 90-päevast vanemat täitmisajalugu. Lisaks automaatsele kustutamisele saab tööajaloo puhastamist käivitada. Veenduge, et puhastustöö oleks planeeritud kordumises. Nagu ülaltoodud on kirjeldatud, puhastab töö igas puhastustöös ainult nii palju käivitamise ID-sid, kui võimalik antud maksimaalse tundide jooksul.
Tööajaloo puhastamine ja arhiivimine
Tööajaloo puhastamine ja arhiivifunktsioonid asendavad puhastusfunktsiooni eelmised versioonid. See jaotis selgitab neid uusi võimalusi.
Üks põhilistest puhastamise funktsiooni muudatustest on ajaloo puhastamiseks süsteemi pakett-töö kasutamine. Süsteemi pakett-töö kasutamine võimaldab finants- ja äritoimingute rakendused, et puhastuse pakett-töö planeeritakse automaatselt ja käivitub niipea, kui süsteem on valmis. Pakett-tööd ei ole enam vaja käsitsi planeerida. Selles vaikekäivitamisrežiimis käivitab pakett-töö iga tunni, alustades keskööst, ja säilitab käivitusajalugu viimased 7 päeva. Likvideeritud ajalugu arhiveeritakse tulevikus toomiseks. Alates versioonist 10.0.20 on see funktsioon alati sees.
Teine muudatus puhastusprotsessis on likvideeritud täitmisajaloo arhiivimisprotsess. Puhastustöö arhiveerib kustutatud kirjed bloobisalvestusse, mida DIXF kasutab regulaarseks integratsiooniks. Arhiveeritud fail on DIXF-paketi vormingus ja on saadaval 7 päevaks bloobis, mille jooksul saab selle alla laadida. Arhiveeritud faili 7 päeva vaikimisi pikaealisust saab parameetrites muuta maksimaalselt 90 päevaks.
Vaikesätete muutmine
See funktsioon on praegu eelvaates ja see tuleb selgesõnaliselt sisse lülitada, lubades eelväljaande DMFEnableExecutionHistoryCleanupSystemJob. Samuti tuleb funktsioonihalduses sisse lülitada ka aegumispuhastusfunktsioon.
Arhiveeritud faili pikaeasuse vaikesätte muutmiseks minge tööruumi andmehaldus ja valige tööajaloo puhastamine. Seadke päevad, et säilitada pakett bloobis väärtuseni 7 kuni 90 (k.a). See muudatus jõustub arhiivides, mis luuakse pärast seda muudatust.
Arhiveeritud paketi allalaadimine
See funktsioon on praegu eelvaates ja see tuleb selgesõnaliselt sisse lülitada, lubades eelväljaande DMFEnableExecutionHistoryCleanupSystemJob. Samuti tuleb funktsioonihalduses sisse lülitada ka aegumispuhastusfunktsioon.
Arhiveeritud käivitusajalugu alla laadimiseks minge andmehaldus ja valige tööajaloo puhastamine. Valige paketi varundusajalugu ajaloo vormi avamiseks. Sellel vormil kuvatakse kõigi arhiveeritud pakettide loend. Arhiivi saab valida ja alla laadida valides paketi Allalaadimine. Allalaaditud pakett on DIXF-pakendi vormingus ja sisaldab järgmisi faile:
- Üksuse koondtabeli fail
- DMFDEFINITIONGROUPEXECUTION
- DMFDEFINITIONGROUPEXECUTIONHISTORY
- DMFEXECUTION
- DMFSTAGINGEXECUTIONERRORS
- (DMFSTAGINGLOG)
- DMFSTAGINGLOGDETAILS
- DMFSTAGINGVALIDATIONLOG
Liitüksuse andmete sortimine xslt abil
See funktsioon võimaldab teil eksportida liitüksuse ja rakendada xslt-faili, et sortida andmeid XML-failis.
Liitüksuse andmete sortimiseks xslt abil järgige neid samme.
- Looge xslt-fail andmete sortimiseks XML-vormingus. Näiteks kui teil on XSLT-fail boksist väljas üksuse jaoks Ostutellimused liit V3, saate sortida XML-atribuudi vormingu andmeid, et arveldada INVOICEVENDORACCOUNTNUMBER PURCHPURCHASEORDERHEADERV2ENTITY ja order by LINENUMBER PURCHPURCHASEORDERLINEV2ENTITY.
<xsl:stylesheet version='1.0' xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/*">
<xsl:copy>
<xsl:apply-templates select="@*" />
<xsl:apply-templates>
<xsl:sort select="@INVOICEVENDORACCOUNTNUMBER" data-type="text" order="ascending" />
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="PURCHPURCHASEORDERHEADERV2ENTITY">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="*">
<xsl:sort select="@LINENUMBER" data-type="number" order="descending"/>
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
- Minge andmehalduse tööruumi .
- Valige andmeekspordiprojektide loendist XML-andmeallikaga projekt ja valige suvand Kuva vastendus.
- Valige mis tahes üksuse jaoks kuva kaart.
- Mine vahekaardile Teisendused
- Valige Uus ja laadige üles sammus 1 loodud xslt-fail.
Tagasiside
Varsti tulekul: 2024. aasta jooksul tühistame GitHubi probleemide funktsiooni sisutagasiside mehhanismina ja asendame selle uue tagasisidesüsteemiga. Lisateabe saamiseks vt https://aka.ms/ContentUserFeedback.
Esita ja vaata tagasisidet