CREATE TABLE AS SELECT
Applies to: ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
CREATE TABLE AS SELECT (CTAS) is one of the most important T-SQL features available. It's a fully parallelized operation that creates a new table based on the output of a SELECT statement. CTAS is the simplest and fastest way to create a copy of a table.
For example, use CTAS to:
- Re-create a table with a different hash distribution column.
- Re-create a table as replicated.
- Create a columnstore index on just some of the columns in the table.
- Query or import external data.
Note
Since CTAS adds to the capabilities of creating a table, this topic tries not to repeat the CREATE TABLE topic. Instead, it describes the differences between the CTAS and CREATE TABLE statements. For the CREATE TABLE details, see CREATE TABLE (Azure Synapse Analytics) statement.
- This syntax is not supported by serverless SQL pool in Azure Synapse Analytics.
- CTAS is supported in the Warehouse in Microsoft Fabric.
![]() Transact-SQL syntax conventions
Transact-SQL syntax conventions
Syntax
CREATE TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
[ ( column_name [ ,...n ] ) ]
WITH (
<distribution_option> -- required
[ , <table_option> [ ,...n ] ]
)
AS <select_statement>
OPTION <query_hint>
[;]
<distribution_option> ::=
{
DISTRIBUTION = HASH ( distribution_column_name )
| DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] )
| DISTRIBUTION = ROUND_ROBIN
| DISTRIBUTION = REPLICATE
}
<table_option> ::=
{
CLUSTERED COLUMNSTORE INDEX --default for Synapse Analytics
| CLUSTERED COLUMNSTORE INDEX ORDER (column[,...n])
| HEAP --default for Parallel Data Warehouse
| CLUSTERED INDEX ( { index_column_name [ ASC | DESC ] } [ ,...n ] ) --default is ASC
}
| PARTITION ( partition_column_name RANGE [ LEFT | RIGHT ] --default is LEFT
FOR VALUES ( [ boundary_value [,...n] ] ) )
<select_statement> ::=
[ WITH <common_table_expression> [ ,...n ] ]
SELECT select_criteria
<query_hint> ::=
{
MAXDOP
}
Arguments
For details, see the Arguments section in CREATE TABLE.
Column options
column_name [ ,...n ]
Column names don't allow the column options mentioned in CREATE TABLE. Instead, you can provide an optional list of one or more column names for the new table. The columns in the new table use the names you specify. When you specify column names, the number of columns in the column list must match the number of columns in the select results. If you don't specify any column names, the new target table uses the column names in the select statement results.
You can't specify any other column options such as data types, collation, or nullability. Each of these attributes is derived from the results of the SELECT statement. However, you can use the SELECT statement to change the attributes. For an example, see Use CTAS to change column attributes.
Table distribution options
For details and to understand how to choose the best distribution column, see the Table distribution options section in CREATE TABLE. For recommendations on which distribution to choose for a table based on actual usage or sample queries, see Distribution Advisor in Azure Synapse SQL.
DISTRIBUTION = HASH (distribution_column_name) | ROUND_ROBIN | REPLICATE
The CTAS statement requires a distribution option and doesn't have default values. This is different from CREATE TABLE, which has defaults.
DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] )
Distributes the rows based on the hash values of up to eight columns, allowing for more even distribution of the base table data, reducing the data skew over time and improving query performance.
Note
- To enable feature, change the database's compatibility level to 50 with this command. For more information on setting the database compatibility level, see ALTER DATABASE SCOPED CONFIGURATION. For example:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; - To disable the multi-column distribution (MCD) feature, run this command to change the database's compatibility level to AUTO. For example:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = AUTO;Existing MCD tables will stay but become unreadable. Queries over MCD tables will return this error:Related table/view is not readable because it distributes data on multiple columns and multi-column distribution is not supported by this product version or this feature is disabled.- To regain access to MCD tables, enable the feature again.
- To load data into a MCD table, use CTAS statement and the data source needs be Synapse SQL tables.
- CTAS on MCD HEAP target tables is not supported. Instead, use INSERT SELECT as a workaround to load data into MCD HEAP tables.
- Using SSMS for generating a script to create MCD tables is currently supported beyond SSMS version 19.
For details and to understand how to choose the best distribution column, see the Table distribution options section in CREATE TABLE.
For recommendations on the best distribution do to use based on your workloads, see the Synapse SQL Distribution Advisor (Preview).
Table partition options
The CTAS statement creates a nonpartitioned table by default, even if the source table is partitioned. To create a partitioned table with the CTAS statement, you must specify the partition option.
For details, see the Table partition options section in CREATE TABLE.
SELECT statement
The SELECT statement is the fundamental difference between CTAS and CREATE TABLE.
WITH common_table_expression
Specifies a temporary named result set, known as a common table expression (CTE). For more information, see WITH common_table_expression (Transact-SQL).
SELECT select_criteria
Populates the new table with the results from a SELECT statement. select_criteria is the body of the SELECT statement that determines which data to copy to the new table. For information about SELECT statements, see SELECT (Transact-SQL).
Query hint
Users can set MAXDOP to an integer value to control the maximum degree of parallelism. When MAXDOP is set to 1, the query is executed by a single thread.
Permissions
CTAS requires SELECT permission on any objects referenced in the select_criteria.
For permissions to create a table, see Permissions in CREATE TABLE.
Remarks
For details, see General Remarks in CREATE TABLE.
Limitations and restrictions
For more details on limitations and restrictions, see Limitations and Restrictions in CREATE TABLE.
An ordered clustered columnstore index can be created on columns of any data types supported in Azure Synapse Analytics except for string columns.
SET ROWCOUNT (Transact-SQL) has no effect on CTAS. To achieve a similar behavior, use TOP (Transact-SQL).
CTAS does not support the
OPENJSONfunction as part of theSELECTstatement. As an alternative, useINSERT INTO ... SELECT. For example:DECLARE @json NVARCHAR(MAX) = N' [ { "id": 1, "name": "Alice", "age": 30, "address": { "street": "123 Main St", "city": "Wonderland" } }, { "id": 2, "name": "Bob", "age": 25, "address": { "street": "456 Elm St", "city": "Gotham" } } ]'; INSERT INTO Users (id, name, age, street, city) SELECT id, name, age, JSON_VALUE(address, '$.street') AS street, JSON_VALUE(address, '$.city') AS city FROM OPENJSON(@json) WITH ( id INT, name NVARCHAR(50), age INT, address NVARCHAR(MAX) AS JSON );
Locking behavior
For details, see Locking Behavior in CREATE TABLE.
Performance
For a hash-distributed table, you can use CTAS to choose a different distribution column to achieve better performance for joins and aggregations. If choosing a different distribution column isn't your goal, you'll have the best CTAS performance if you specify the same distribution column since this will avoid redistributing the rows.
If you're using CTAS to create table and performance isn't a factor, you can specify ROUND_ROBIN to avoid having to decide on a distribution column.
To avoid data movement in subsequent queries, you can specify REPLICATE at the cost of increased storage for loading a full copy of the table on each Compute node.
Examples for copying a table
A. Use CTAS to copy a table
Applies to: Azure Synapse Analytics and Analytics Platform System (PDW)
Perhaps one of the most common uses of CTAS is creating a copy of a table so that you can change the DDL. If, for example, you originally created your table as ROUND_ROBIN and now want change it to a table distributed on a column, CTAS is how you would change the distribution column. CTAS can also be used to change partitioning, indexing, or column types.
Let's say you created this table by specifying HEAP and using the default distribution type of ROUND_ROBIN.
CREATE TABLE FactInternetSales
(
ProductKey INT NOT NULL,
OrderDateKey INT NOT NULL,
DueDateKey INT NOT NULL,
ShipDateKey INT NOT NULL,
CustomerKey INT NOT NULL,
PromotionKey INT NOT NULL,
CurrencyKey INT NOT NULL,
SalesTerritoryKey INT NOT NULL,
SalesOrderNumber NVARCHAR(20) NOT NULL,
SalesOrderLineNumber TINYINT NOT NULL,
RevisionNumber TINYINT NOT NULL,
OrderQuantity SMALLINT NOT NULL,
UnitPrice MONEY NOT NULL,
ExtendedAmount MONEY NOT NULL,
UnitPriceDiscountPct FLOAT NOT NULL,
DiscountAmount FLOAT NOT NULL,
ProductStandardCost MONEY NOT NULL,
TotalProductCost MONEY NOT NULL,
SalesAmount MONEY NOT NULL,
TaxAmt MONEY NOT NULL,
Freight MONEY NOT NULL,
CarrierTrackingNumber NVARCHAR(25),
CustomerPONumber NVARCHAR(25)
)
WITH(
HEAP,
DISTRIBUTION = ROUND_ROBIN
);
Now you want to create a new copy of this table with a clustered columnstore index so that you can take advantage of the performance of clustered columnstore tables. You also want to distribute this table on ProductKey since you're anticipating joins on this column and want to avoid data movement during joins on ProductKey. Lastly you also want to add partitioning on OrderDateKey so that you can quickly delete old data by dropping old partitions. Here's the CTAS statement that would copy your old table into a new table:
CREATE TABLE FactInternetSales_new
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(ProductKey),
PARTITION
(
OrderDateKey RANGE RIGHT FOR VALUES
(
20000101,20010101,20020101,20030101,20040101,20050101,20060101,20070101,20080101,20090101,
20100101,20110101,20120101,20130101,20140101,20150101,20160101,20170101,20180101,20190101,
20200101,20210101,20220101,20230101,20240101,20250101,20260101,20270101,20280101,20290101
)
)
)
AS SELECT * FROM FactInternetSales;
Finally you can rename your tables to swap in your new table and then drop your old table.
RENAME OBJECT FactInternetSales TO FactInternetSales_old;
RENAME OBJECT FactInternetSales_new TO FactInternetSales;
DROP TABLE FactInternetSales_old;
Examples for column options
B. Use CTAS to change column attributes
Applies to: Azure Synapse Analytics and Analytics Platform System (PDW)
This example uses CTAS to change data types, nullability, and collation for several columns in the DimCustomer2 table.
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] nvarchar(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL
)
WITH (CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH([CustomerKey]));
-- CTAS example to change data types, nullability, and column collations
CREATE TABLE test
WITH (HEAP, DISTRIBUTION = ROUND_ROBIN)
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
CustomerAlternateKey COLLATE Latin1_General_CS_AS_KS_WS AS CustomerAlternateKeyChangeCollation
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[CustomerAlternateKeyNullable] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[CustomerAlternateKeyChangeCollation] NVARCHAR(15) COLLATE Latin1_General_CS_AS_KS_WS NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN);
As a final step, you can use RENAME (Transact-SQL) to switch the table names. This makes DimCustomer2 be the new table.
RENAME OBJECT DimCustomer2 TO DimCustomer2_old;
RENAME OBJECT test TO DimCustomer2;
DROP TABLE DimCustomer2_old;
Examples for table distribution
C. Use CTAS to change the distribution method for a table
Applies to: Azure Synapse Analytics and Analytics Platform System (PDW)
This simple example shows how to change the distribution method for a table. To show the mechanics of how to do this, it changes a hash-distributed table to round-robin and then changes the round-robin table back to hash distributed. The final table matches the original table.
In most cases, you don't need to change a hash-distributed table to a round-robin table. More often, you might need to change a round-robin table to a hash distributed table. For example, you might initially load a new table as round-robin and then later move it to a hash-distributed table to get better join performance.
This example uses the AdventureWorksDW sample database. To load the Azure Synapse Analytics version, see Quickstart: Create and query a dedicated SQL pool (formerly SQL DW) in Azure Synapse Analytics using the Azure portal.
-- DimSalesTerritory is hash-distributed.
-- Copy it to a round-robin table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Next, change it back to a hash distributed table.
-- You just made DimSalesTerritory a round-robin table.
-- Change it back to the original hash-distributed table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(SalesTerritoryKey)
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
D. Use CTAS to convert a table to a replicated table
Applies to: Azure Synapse Analytics and Analytics Platform System (PDW)
This example applies for converting round-robin or hash-distributed tables to a replicated table. This particular example takes the previous method of changing the distribution type one step further. Since DimSalesTerritory is a dimension and likely a smaller table, you can choose to re-create the table as replicated to avoid data movement when joining to other tables.
-- DimSalesTerritory is hash-distributed.
-- Copy it to a replicated table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
E. Use CTAS to create a table with fewer columns
Applies to: Azure Synapse Analytics and Analytics Platform System (PDW)
The following example creates a round-robin distributed table named myTable (c, ln). The new table only has two columns. It uses the column aliases in the SELECT statement for the names of the columns.
CREATE TABLE myTable
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
Examples for query hints
F. Use a Query Hint with CREATE TABLE AS SELECT (CTAS)
Applies to: Azure Synapse Analytics and Analytics Platform System (PDW)
This query shows the basic syntax for using a query join hint with the CTAS statement. After the query is submitted, Azure Synapse Analytics applies the hash join strategy when it generates the query plan for each individual distribution. For more information on the hash join query hint, see OPTION Clause (Transact-SQL).
CREATE TABLE dbo.FactInternetSalesNew
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT T1.* FROM dbo.FactInternetSales T1 JOIN dbo.DimCustomer T2
ON ( T1.CustomerKey = T2.CustomerKey )
OPTION ( HASH JOIN );
Examples for external tables
G. Use CTAS to import data from Azure Blob storage
Applies to: Azure Synapse Analytics and Analytics Platform System (PDW)
To import data from an external table, use CREATE TABLE AS SELECT to select from the external table. The syntax to select data from an external table into Azure Synapse Analytics is the same as the syntax for selecting data from a regular table.
The following example defines an external table on data in an Azure Blob Storage account. It then uses CREATE TABLE AS SELECT to select from the external table. This imports the data from Azure Blob Storage text-delimited files and stores the data into a new Azure Synapse Analytics table.
--Use your own processes to create the text-delimited files on Azure Blob Storage.
--Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION='/logs/clickstream/2015/',
DATA_SOURCE = MyAzureStorage,
FILE_FORMAT = TextFileFormat)
;
--Use CREATE TABLE AS SELECT to import the Azure Blob Storage data into a new
--Synapse Analytics table called ClickStreamData
CREATE TABLE ClickStreamData
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
H. Use CTAS to import Hadoop data from an external table
Applies to: Analytics Platform System (PDW)
To import data from an external table, simply use CREATE TABLE AS SELECT to select from the external table. The syntax to select data from an external table into Analytics Platform System (PDW) is the same as the syntax for selecting data from a regular table.
The following example defines an external table on a Hadoop cluster. It then uses CREATE TABLE AS SELECT to select from the external table. This imports the data from Hadoop text-delimited files and stores the data into a new Analytics Platform System (PDW) table.
-- Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION = 'hdfs://MyHadoop:5000/tpch1GB/employee.tbl',
FORMAT_OPTIONS ( FIELD_TERMINATOR = '|')
)
;
-- Use your own processes to create the Hadoop text-delimited files
-- on the Hadoop Cluster.
-- Use CREATE TABLE AS SELECT to import the Hadoop data into a new
-- table called ClickStreamPDW
CREATE TABLE ClickStreamPDW
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
Examples using CTAS to replace SQL Server code
Use CTAS to work around some unsupported features. Besides being able to run your code on the data warehouse, rewriting existing code to use CTAS will usually improve performance. This is a result of its fully parallelized design.
Note
Try to think "CTAS first". If you think you can solve a problem using CTAS then that is generally the best way to approach it - even if you are writing more data as a result.
I. Use CTAS instead of SELECT..INTO
Applies to: Azure Synapse Analytics and Analytics Platform System (PDW)
SQL Server code typically uses SELECT..INTO to populate a table with the results of a SELECT statement. This is an example of a SQL Server SELECT..INTO statement.
SELECT *
INTO #tmp_fct
FROM [dbo].[FactInternetSales]
This syntax isn't supported in Azure Synapse Analytics and Parallel Data Warehouse. This example shows how to rewrite the previous SELECT..INTO statement as a CTAS statement. You can choose any of the DISTRIBUTION options described in the CTAS syntax. This example uses the ROUND_ROBIN distribution method.
CREATE TABLE #tmp_fct
WITH
(
DISTRIBUTION = ROUND_ROBIN
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
J. Use CTAS to simplify merge statements
Applies to: Azure Synapse Analytics and Analytics Platform System (PDW)
Merge statements can be replaced, at least in part, by using CTAS. You can consolidate the INSERT and the UPDATE into a single statement. Any deleted records would need to be closed off in a second statement.
An example of an UPSERT follows:
CREATE TABLE dbo.[DimProduct_upsert]
WITH
( DISTRIBUTION = HASH([ProductKey])
, CLUSTERED INDEX ([ProductKey])
)
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;
RENAME OBJECT dbo.[DimProduct] TO [DimProduct_old];
RENAME OBJECT dbo.[DimProduct_upsert] TO [DimProduct];
K. Explicitly state data type and nullability of output
Applies to: Azure Synapse Analytics and Analytics Platform System (PDW)
When migrating SQL Server code to Azure Synapse Analytics, you might find you run across this type of coding pattern:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE result
(result DECIMAL(7,2) NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN)
INSERT INTO result
SELECT @d*@f
;
Instinctively you might think you should migrate this code to a CTAS and you would be correct. However, there's a hidden issue here.
The following code does NOT yield the same result:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
;
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT @d*@f as result
;
Notice that the column "result" carries forward the data type and nullability values of the expression. This can lead to subtle variances in values if you aren't careful.
Try the following as an example:
SELECT result,result*@d
from result
;
SELECT result,result*@d
from ctas_r
;
The value stored for result is different. As the persisted value in the result column is used in other expressions the error becomes even more significant.
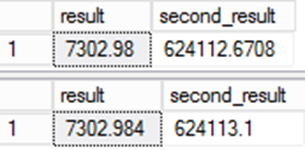
This is important for data migrations. Even though the second query is arguably more accurate there's a problem. The data would be different compared to the source system and that leads to questions of integrity in the migration. This is one of those rare cases where the "wrong" answer is actually the right one!
The reason we see this disparity between the two results is down to implicit type casting. In the first example, the table defines the column definition. When the row is inserted an implicit type conversion occurs. In the second example, there's no implicit type conversion as the expression defines data type of the column. Notice also that the column in the second example has been defined as a NULLable column whereas in the first example it hasn't. When the table was created in the first example column nullability was explicitly defined. In the second example, it was left to the expression and by default this would result in a NULL definition.
To resolve these issues, you must explicitly set the type conversion and nullability in the SELECT portion of the CTAS statement. You can't set these properties in the create table part.
This example demonstrates how to fix the code:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT ISNULL(CAST(@d*@f AS DECIMAL(7,2)),0) as result
Note the following in the example:
- CAST or CONVERT could have been used.
- ISNULL is used to force NULLability not COALESCE.
- ISNULL is the outermost function.
- The second part of the ISNULL is a constant,
0.
Note
For the nullability to be correctly set it is vital to use ISNULL and not COALESCE. COALESCE is not a deterministic function and so the result of the expression will always be NULLable. ISNULL is different. It is deterministic. Therefore when the second part of the ISNULL function is a constant or a literal then the resulting value will be NOT NULL.
This tip isn't just useful for ensuring the integrity of your calculations. It's also important for table partition switching. Imagine you have this table defined as your fact:
CREATE TABLE [dbo].[Sales]
(
[date] INT NOT NULL
, [product] INT NOT NULL
, [store] INT NOT NULL
, [quantity] INT NOT NULL
, [price] MONEY NOT NULL
, [amount] MONEY NOT NULL
)
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101,20020101
,20030101,20040101,20050101
)
)
)
;
However, the value field is a calculated expression it isn't part of the source data.
To create your partitioned dataset, consider the following example:
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, [quantity]*[price] AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create')
;
The query would run perfectly fine. The problem comes when you try to perform the partition switch. The table definitions don't match. To make the table definitions, match the CTAS needs to be modified.
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, ISNULL(CAST([quantity]*[price] AS MONEY),0) AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create');
You can see therefore that type consistency and maintaining nullability properties on a CTAS is a good engineering best practice. It helps to maintain integrity in your calculations and also ensures that partition switching is possible.
L. Create an ordered clustered columnstore index with MAXDOP 1
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Next steps
- CREATE EXTERNAL DATA SOURCE (Transact-SQL)
- CREATE EXTERNAL FILE FORMAT (Transact-SQL)
- CREATE EXTERNAL TABLE (Transact-SQL)
- CREATE EXTERNAL TABLE AS SELECT (Transact-SQL)
- CREATE TABLE (Azure Synapse Analytics)
- DROP TABLE (Transact-SQL)
- DROP EXTERNAL TABLE (Transact-SQL)
- ALTER TABLE (Transact-SQL)
- ALTER EXTERNAL TABLE (Transact-SQL)
Applies to: ![]() Warehouse in Microsoft Fabric
Warehouse in Microsoft Fabric
CREATE TABLE AS SELECT (CTAS) is one of the most important T-SQL features available. It's a fully parallelized operation that creates a new table based on the output of a SELECT statement. CTAS is the simplest and fastest way to create a copy of a table.
For example, use CTAS in Warehouse in Microsoft Fabric to:
- Create a copy of a table with some of the columns of the source table.
- Create a table that is the result of a query that joins other tables.
For more information on using CTAS on your Warehouse in Microsoft Fabric, see Ingest data into your Warehouse using Transact-SQL.
Note
Since CTAS adds to the capabilities of creating a table, this topic tries not to repeat the CREATE TABLE topic. Instead, it describes the differences between the CTAS and CREATE TABLE statements. For the CREATE TABLE details, see CREATE TABLE statement.
![]() Transact-SQL syntax conventions
Transact-SQL syntax conventions
Syntax
CREATE TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
AS <select_statement>
[;]
<select_statement> ::=
SELECT select_criteria
Arguments
For details, see the Arguments in CREATE TABLE for Microsoft Fabric.
Column options
column_name [ ,...n ]
Column names don't allow the column options mentioned in CREATE TABLE. Instead, you can provide an optional list of one or more column names for the new table. The columns in the new table use the names you specify. When you specify column names, the number of columns in the column list must match the number of columns in the select results. If you don't specify any column names, the new target table uses the column names in the select statement results.
You can't specify any other column options such as data types, collation, or nullability. Each of these attributes is derived from the results of the SELECT statement. However, you can use the SELECT statement to change the attributes.
SELECT statement
The SELECT statement is the fundamental difference between CTAS and CREATE TABLE.
SELECT select_criteria
Populates the new table with the results from a SELECT statement. select_criteria is the body of the SELECT statement that determines which data to copy to the new table. For information about SELECT statements, see SELECT (Transact-SQL).
Note
In Microsoft Fabric, the use of variables in CTAS is not allowed.
Permissions
CTAS requires SELECT permission on any objects referenced in the select_criteria.
For permissions to create a table, see Permissions in CREATE TABLE.
Remarks
For details, see General Remarks in CREATE TABLE.
Limitations and restrictions
SET ROWCOUNT (Transact-SQL) has no effect on CTAS. To achieve a similar behavior, use TOP (Transact-SQL).
For details, see Limitations and Restrictions in CREATE TABLE.
Locking behavior
For details, see Locking Behavior in CREATE TABLE.
Examples for copying a table
For more information on using CTAS on your Warehouse in Microsoft Fabric, see Ingest data into your Warehouse using Transact-SQL.
A. Use CTAS to change column attributes
This example uses CTAS to change data types and nullability for several columns in the DimCustomer2 table.
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] VARCHAR(15)NOT NULL
)
-- CTAS example to change data types and nullability of columns
CREATE TABLE test
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] VARCHAR(15) NOT NULL,
[CustomerAlternateKeyNullable] VARCHAR(15) NULL,
NOT NULL
)
B. Use CTAS to create a table with fewer columns
The following example creates a table named myTable (c, ln). The new table only has two columns. It uses the column aliases in the SELECT statement for the names of the columns.
CREATE TABLE myTable
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
C. Use CTAS instead of SELECT..INTO
SQL Server code typically uses SELECT..INTO to populate a table with the results of a SELECT statement. This is an example of a SQL Server SELECT..INTO statement.
SELECT *
INTO NewFactTable
FROM [dbo].[FactInternetSales]
This example shows how to rewrite the previous SELECT..INTO statement as a CTAS statement.
CREATE TABLE NewFactTable
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
D. Use CTAS to simplify merge statements
Merge statements can be replaced, at least in part, by using CTAS. You can consolidate the INSERT and the UPDATE into a single statement. Any deleted records would need to be closed off in a second statement.
An example of an UPSERT follows:
CREATE TABLE dbo.[DimProduct_upsert]
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;