Configuración del grupo de conmutación por error: CLI
En este artículo se explica cómo configurar la recuperación ante desastres para SQL Managed Instance habilitada por Azure Arc con la CLI. Antes de continuar, revise la información y los requisitos previos de SQL Managed Instance habilitados por Azure Arc: recuperación ante desastres.
Requisitos previos
Se deben cumplir los siguientes requisitos previos antes de configurar grupos de conmutación por error entre dos instancias de SQL Managed Instance habilitadas por Azure Arc:
- Un controlador de datos de Azure Arc y una instancia administrada de SQL habilitada por Arc aprovisionadas en el sitio primario con
--license-typecomo una deBasePriceoLicenseIncluded. - Un controlador de datos de Azure Arc y una instancia administrada de SQL habilitada por Arc aprovisionada en el sitio secundario con una configuración idéntica como principal en términos de:
- CPU
- Memoria
- Storage
- Nivel de servicio
- Intercalación
- Otras opciones de configuración de instancia
- La instancia del sitio secundario requiere
--license-typecomoDisasterRecovery. Esta instancia debe ser nueva, sin ningún objeto de usuario.
Nota:
- Es importante especificar el
--license-typedurante la creación de la instancia administrada. Esto permitirá que la instancia de recuperación ante desastres se inicialice desde la instancia principal del centro de datos principal. La actualización de esta propiedad después de la implementación no tendrá el mismo efecto.
Proceso de implementación
Para configurar un grupo de conmutación por error de Azure entre dos instancias, complete los pasos siguientes:
- Cree un recurso personalizado para un grupo de disponibilidad distribuido en el sitio principal.
- Cree un recurso personalizado para un grupo de disponibilidad distribuido en el sitio secundario.
- Copia de los datos binarios de los certificados de creación de reflejo
- Configurar el grupo de disponibilidad distribuido entre los sitios primarios y secundarios, ya sea en modo
synco en modoasync
En la imagen siguiente se muestra un grupo de disponibilidad distribuido configurado correctamente:
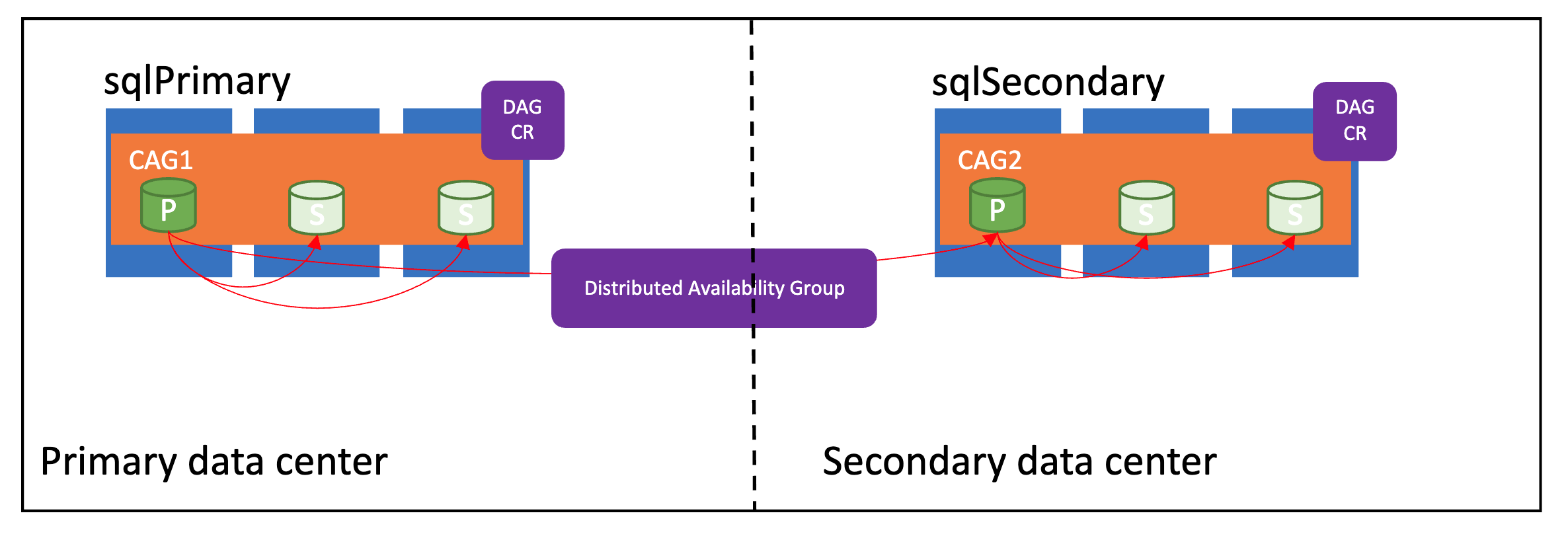
Modos de sincronización
Los grupos de conmutación por error de los servicios de datos de Azure Arc admiten dos modos de sincronización: sync y async. El modo de sincronización afecta directamente la forma en que los datos se sincronizan entre las instancias, y potencialmente el rendimiento en la instancia principal administrada.
Si los sitios primarios y secundarios están dentro de unos pocos kilómetros entre sí, use el modo sync. De lo contrario, use el modo async para evitar cualquier impacto en el rendimiento en el sitio primario.
Configuración del grupo de conmutación por error de Azure: modo directo
Siga los pasos siguientes si los servicios de datos de Azure Arc se implementan en modo conectado directly.
Una vez cumplidos los requisitos previos, ejecute el siguiente comando para configurar el grupo de conmutación por error de Azure entre las dos instancias:
az sql instance-failover-group-arc create --name <name of failover group> --mi <primary SQL MI> --partner-mi <Partner MI> --resource-group <name of RG> --partner-resource-group <name of partner MI RG>
Ejemplo:
az sql instance-failover-group-arc create --name sql-fog --mi sql1 --partner-mi sql2 --resource-group rg-name --partner-resource-group rg-name
El comando anterior:
- Cree los recursos personalizados necesarios en sitios primarios y secundarios
- Copia los certificados de creación de reflejo y configura el grupo de conmutación por error entre las instancias
Configuración del grupo de conmutación por error de Azure: modo indirecto
Siga los pasos siguientes si los servicios de datos de Azure Arc se implementan en modo conectado indirectly.
Aprovisione la instancia administrada en el sitio principal.
az sql mi-arc create --name <primaryinstance> --tier bc --replicas 3 --k8s-namespace <namespace> --use-k8sCambie el contexto al clúster secundario mediante la ejecución de
kubectl config use-context <secondarycluster>y aprovisione la instancia administrada en el sitio secundario que será la instancia de recuperación ante desastres. En este momento, las bases de datos del sistema no forman parte del grupo de disponibilidad contenido.Nota:
Es importante especificar
--license-type DisasterRecoverydurante la instancia administrada. Esto permitirá que la instancia de recuperación ante desastres se inicialice desde la instancia principal del centro de datos principal. La actualización de esta propiedad después de la implementación no tendrá el mismo efecto.az sql mi-arc create --name <secondaryinstance> --tier bc --replicas 3 --license-type DisasterRecovery --k8s-namespace <namespace> --use-k8sCertificados de creación de reflejo - Los datos binarios dentro de la propiedad Certificado de creación de reflejo de la instancia administrada son necesarios para la creación del CR (Recurso personalizado) del grupo de conmutación por error de instancia.
Esto se puede lograr de varias maneras:
(a) Si usa la CLI
az, genere primero el archivo de certificado de creación de reflejo y, luego, apunte a ese archivo al configurar el grupo de conmutación por error de instancia para que los datos binarios se lean del archivo y se copien en el CR. Los archivos de certificado no son necesarios después de la creación del grupo de conmutación por error.(b) Si usa
kubectl, copie y pegue directamente los datos binarios de la CR de la instancia administrada en el archivo yaml que se usará para crear el grupo de conmutación por error de instancia.Con los pasos indicados en la sección (a):
Cree el archivo de certificado de creación de reflejo para la instancia principal:
az sql mi-arc get-mirroring-cert --name <primaryinstance> --cert-file </path/name>.pem --k8s-namespace <namespace> --use-k8sEjemplo:
az sql mi-arc get-mirroring-cert --name sqlprimary --cert-file $HOME/sqlcerts/sqlprimary.pem --k8s-namespace my-namespace --use-k8sConéctese al clúster secundario y cree el archivo de certificado de creación de reflejo para la instancia secundaria:
az sql mi-arc get-mirroring-cert --name <secondaryinstance> --cert-file </path/name>.pem --k8s-namespace <namespace> --use-k8sEjemplo:
az sql mi-arc get-mirroring-cert --name sqlsecondary --cert-file $HOME/sqlcerts/sqlsecondary.pem --k8s-namespace my-namespace --use-k8sUna vez creados los archivos de certificado de creación de reflejo, copie el certificado de la instancia secundaria en una ruta de acceso compartida o local en el clúster de instancia principal y viceversa.
Cree el recurso de grupo de conmutación por error en ambos sitios.
Nota:
Asegúrese de que las instancias de SQL tienen nombres diferentes para los sitios primarios y secundarios, y el valor
shared-namedebe ser idéntico en ambos sitios.az sql instance-failover-group-arc create --shared-name <name of failover group> --name <name for primary failover group resource> --mi <local SQL managed instance name> --role primary --partner-mi <partner SQL managed instance name> --partner-mirroring-url tcp://<secondary IP> --partner-mirroring-cert-file <secondary.pem> --k8s-namespace <namespace> --use-k8sEjemplo:
az sql instance-failover-group-arc create --shared-name myfog --name primarycr --mi sqlinstance1 --role primary --partner-mi sqlinstance2 --partner-mirroring-url tcp://10.20.5.20:970 --partner-mirroring-cert-file $HOME/sqlcerts/sqlinstance2.pem --k8s-namespace my-namespace --use-k8sEn la instancia secundaria, ejecute el siguiente comando para configurar el recurso personalizado del grupo de conmutación por error. En este caso,
--partner-mirroring-cert-filedebe apuntar a una ruta de acceso que tenga el archivo de certificado de creación de reflejo generado a partir de la instancia principal, como se describe en la sección 3(a) anterior.az sql instance-failover-group-arc create --shared-name <name of failover group> --name <name for secondary failover group resource> --mi <local SQL managed instance name> --role secondary --partner-mi <partner SQL managed instance name> --partner-mirroring-url tcp://<primary IP> --partner-mirroring-cert-file <primary.pem> --k8s-namespace <namespace> --use-k8sEjemplo:
az sql instance-failover-group-arc create --shared-name myfog --name secondarycr --mi sqlinstance2 --role secondary --partner-mi sqlinstance1 --partner-mirroring-url tcp://10.10.5.20:970 --partner-mirroring-cert-file $HOME/sqlcerts/sqlinstance1.pem --k8s-namespace my-namespace --use-k8s
Recuperación del estado de mantenimiento del grupo de conmutación por error de Azure
La información sobre el grupo de conmutación por error, como el rol principal, el rol secundario y el estado de mantenimiento actual se pueden ver en el recurso personalizado en el sitio primario o secundario.
Ejecute el siguiente comando en el sitio principal o secundario para enumerar el recurso personalizado de grupos de conmutación por error:
kubectl get fog -n <namespace>
Describa el recurso personalizado para recuperar el estado del grupo de conmutación por error, como se indica a continuación:
kubectl describe fog <failover group cr name> -n <namespace>
Operaciones de grupo de conmutación por error
Una vez configurado el grupo de conmutación por error entre las instancias administradas, se pueden realizar diferentes operaciones de conmutación por error en función de las circunstancias.
Los posibles escenarios de conmutación por error son:
Las instancias de ambos sitios están en estado correcto y es necesario realizar una conmutación por error:
- realice una conmutación por error manual de principal a secundaria sin pérdida de datos estableciendo
role=secondaryen la mi de SQL principal.
- realice una conmutación por error manual de principal a secundaria sin pérdida de datos estableciendo
El sitio primario es incorrecto o inaccesible y es necesario realizar una conmutación por error:
- La instancia administrada de SQL principal habilitada por Azure Arc está inactiva, incorrecta o inaccesible
- La instancia administrada de SQL secundaria habilitada por Azure Arc debe promoverse a principal con posible pérdida de datos
- cuando la instancia administrada de SQL principal original habilitada por Azure Arc vuelve a estar en línea, se notificará como rol
Primaryy estado incorrecto y debe forzarse a un rolsecondarypara que pueda unirse al grupo de conmutación por error y los datos se pueden sincronizar.
Conmutación por error manual (sin pérdida de datos)
Use el grupo de comandos az sql instance-failover-group-arc update ... para iniciar una conmutación por error de principal a secundaria. Todas las transacciones pendientes de la instancia geográfica principal se replican en la instancia geográfica secundaria antes de la conmutación por error.
Modo de conexión directa
Ejecute el siguiente comando para iniciar una conmutación por error manual, en modo conectado direct mediante las API de ARM:
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <primary instance> --role secondary --resource-group <resource group>
Ejemplo:
az sql instance-failover-group-arc update --name myfog --mi sqlmi1 --role secondary --resource-group myresourcegroup
Modo de conexión indirecta
Ejecute el siguiente comando para iniciar una conmutación por error manual, en modo conectado indirect mediante las API de Kubernetes:
az sql instance-failover-group-arc update --name <name of failover group resource> --role secondary --k8s-namespace <namespace> --use-k8s
Ejemplo:
az sql instance-failover-group-arc update --name myfog --role secondary --k8s-namespace my-namespace --use-k8s
Conmutación por error forzada con pérdida de datos
En caso de que la instancia geográfica principal deje de estar disponible, se pueden ejecutar los siguientes comandos en la instancia geográfica secundaria de recuperación ante desastres para promoverla a la principal con una conmutación por error forzada que conlleva una posible pérdida de datos.
En la instancia geográfica secundaria de recuperación ante desastres, ejecute el siguiente comando para promoverla al rol principal, con pérdida de datos.
Nota:
Si el --partner-sync-mode se ha configurado como sync, debe restablecerse a async cuando la base de datos secundaria se promueve a la principal.
Modo de conexión directa
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <instance> --role force-primary-allow-data-loss --resource-group <resource group> --partner-sync-mode async
Ejemplo:
az sql instance-failover-group-arc update --name myfog --mi sqlmi2 --role force-primary-allow-data-loss --resource-group myresourcegroup --partner-sync-mode async
Modo de conexión indirecta
az sql instance-failover-group-arc update --k8s-namespace my-namespace --name secondarycr --use-k8s --role force-primary-allow-data-loss --partner-sync-mode async
Cuando la instancia principal geográfica esté disponible, ejecute el siguiente comando para incluirla en el grupo de conmutación por error y sincronizar los datos:
Modo de conexión indirecta
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <old primary instance> --role force-secondary --resource-group <resource group>
Modo de conexión indirecta
az sql instance-failover-group-arc update --k8s-namespace my-namespace --name secondarycr --use-k8s --role force-secondary
Opcionalmente, --partner-sync-mode se puede volver a configurar en modo sync si lo desea.
Operaciones posteriores a la conmutación por error
Una vez que realice una conmutación por error del sitio primario al sitio secundario, ya sea con o sin pérdida de datos, es posible que tenga que hacer lo siguiente:
- Actualice la cadena de conexión para que las aplicaciones se conecten a la instancia administrada de Arc SQL principal recién promocionada
- Si tiene previsto seguir ejecutando la carga de trabajo de producción fuera del sitio secundario, actualice
--license-typeaBasePriceoLicenseIncludedpara iniciar la facturación de los núcleos virtuales consumidos.