Tutorial: Sincronización de datos desde SQL Edge a Azure Blob Storage mediante Azure Data Factory
Importante
Azure SQL Edge se retirará el 30 de septiembre de 2025. Para obtener más información y opciones de migración, consulte el aviso de retirada.
Nota:
Azure SQL Edge ya no admite la plataforma ARM64.
Este tutorial le muestra cómo usar Azure Data Factory para sincronizar de forma incremental los datos con el almacenamiento Azure Blob desde una tabla en una instancia de Azure SQL Edge.
Antes de empezar
Si no ha creado una base de datos o una tabla en la implementación de Azure SQL Edge, use uno de estos métodos para hacerlo:
Use SQL Server Management Studio o Azure Data Studio para conectarse a SQL Edge. Ejecute un script SQL para crear la base de datos y la tabla.
Cree una base de datos y una tabla mediante sqlcmd, para lo cual debe conectarse directamente al módulo de SQL Edge. Para más información, consulte el artículo en el que se explica cómo conectarse al motor de base de datos mediante sqlcmd.
Use SQLPackage.exe para implementar un archivo de paquete DAC en el contenedor de SQL Edge. Para automatizar este proceso es preciso especificar el identificador URI del archivo SqlPackage como parte de la configuración de las propiedades deseadas del módulo. También puede usar directamente la herramienta de cliente SqlPackage.exe para implementar un paquete DAC en SQL Edge.
Para obtener información sobre cómo descargar Sqlpackage.exe, consulte Descarga e instalación de sqlpackage. A continuación, encontrará algunos comandos de ejemplo de SqlPackage.exe. Para más información, consulte la documentación de SqlPackage.exe.
Creación de un paquete DAC
sqlpackage /Action:Extract /SourceConnectionString:"Data Source=<Server_Name>,<port>;Initial Catalog=<DB_name>;User ID=<user>;Password=<password>" /TargetFile:<dacpac_file_name>Aplicación de un paquete DAC
sqlpackage /Action:Publish /Sourcefile:<dacpac_file_name> /TargetServerName:<Server_Name>,<port> /TargetDatabaseName:<DB_Name> /TargetUser:<user> /TargetPassword:<password>
Creación de una tabla SQL y un procedimiento para almacenar y actualizar los niveles de marca de agua
Las tablas de marca de agua se usan para almacenar la última marca de tiempo en que los datos se han sincronizado con Azure Storage. Los procedimientos almacenados de Transact-SQL (T-SQL) se utilizan para actualizar la tabla de marca de agua después de cada sincronización.
Ejecute estos comandos en la instancia de SQL Edge:
CREATE TABLE [dbo].[watermarktable] (
TableName VARCHAR(255),
WatermarkValue DATETIME,
);
GO
CREATE PROCEDURE usp_write_watermark @timestamp DATETIME,
@TableName VARCHAR(50)
AS
BEGIN
UPDATE [dbo].[watermarktable]
SET [WatermarkValue] = @timestamp
WHERE [TableName] = @TableName;
END
GO
Creación de una canalización de Data Factory
En esta sección, creará una canalización de Azure Data Factory para sincronizar en Azure Blob Storage datos de una tabla de Azure SQL Edge.
Creación de una factoría de datos mediante la interfaz de usuario de Data Factory
Para crear una factoría de datos, siga las instrucciones que se proporcionan en este tutorial.
Creación de una canalización de Data Factory
En la página Empecemos de la interfaz de usuario de Data Factory, seleccione Crear canalización.

En la página General de la ventana Propiedades de la canalización, escriba el nombre PeriodicSync.
Agregue la actividad Búsqueda para recuperar el valor de marca de agua anterior. En el panel Actividades, expanda General y arrastre la actividad Búsqueda hasta la superficie del diseñador de canalizaciones. Cambie el nombre de la actividad a OldWatermark.

Cambie a la pestaña Configuración y seleccione Nuevo en Conjunto de datos de origen. Ahora va a crear un conjunto de datos que represente los datos de la tabla de marca de agua. Esta tabla contiene la marca de agua que se utilizó anteriormente en la operación de copia anterior.
En la ventana Nuevo conjunto de datos, seleccione Azure SQL Server y, después, Continuar.
En la ventana Establecer propiedades del conjunto de datos, en Nombre, escriba WatermarkDataset.
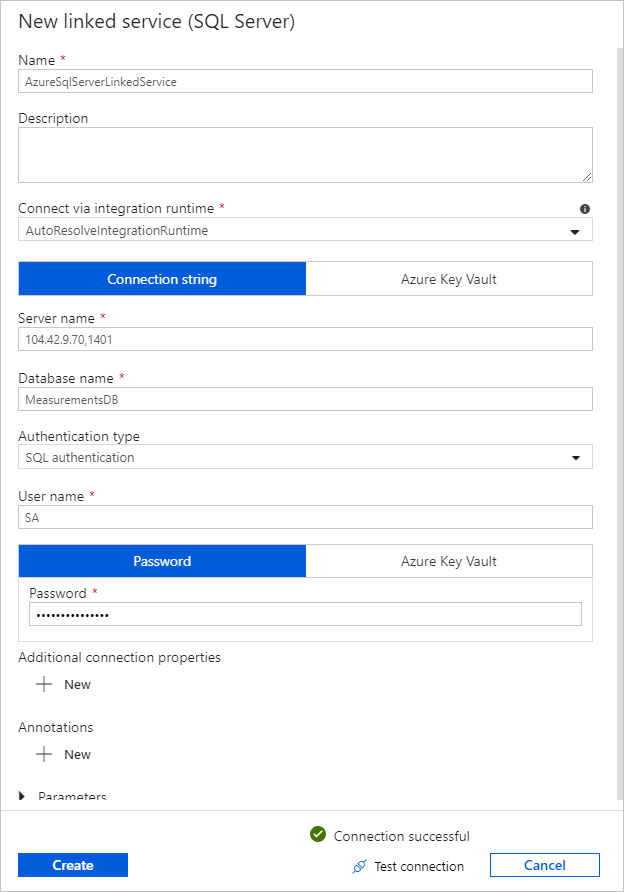
En Servicio vinculado, seleccione Nuevo y siga estos pasos:
En Nombre, escriba SQLDBEdgeLinkedService.
En Nombre del servidor, escriba los detalles del servidor de SQL Edge.
Seleccione el nombre de la base de datos en la lista.
Escriba su User name (Nombre de usuario) y Password (Contraseña).
Para probar la conexión a la instancia de SQL Edge, seleccione Prueba de conexión.
Seleccione Crear.
Seleccione Aceptar.
En la pestaña Configuración, seleccione Edición.
En la pestaña Conexión, seleccione
[dbo].[watermarktable]en Tabla. Si desea una vista previa de los datos de la tabla, seleccione Preview data (Vista previa de los datos).Cambie al editor de canalización; para ello, seleccione la pestaña de la canalización de la parte superior o el nombre de esta de la vista de árbol de la izquierda. En la ventana de actividades de la actividad Búsqueda, confirme que WatermarkDataset está seleccionado en la lista Conjunto de datos de origen.
En el panel Actividades, expanda General y arrastre otra actividad Búsqueda hasta la superficie del diseñador de canalizaciones. Seleccione el nombre NewWatermark en la pestaña General de la ventana de propiedades. Esta actividad de búsqueda obtiene el nuevo valor de marca de agua de la tabla que contiene los datos de origen, por lo que se puede copiar en el destino.
En la ventana de propiedades de la segunda actividad Búsqueda, cambie a la pestaña Configuración y seleccione Nuevo para crear un conjunto de datos que apunte a la tabla de origen que contenga el nuevo valor de marca de agua.
En la ventana Nuevo conjunto de datos, seleccione Instancia de SQL Edge y, después, Continuar.
En la ventana Establecer propiedades, en Nombre, escriba SourceDataset. En Servicio vinculado, seleccione SQLDBEdgeLinkedService como servicio vinculado.
En Tabla, seleccione la tabla que desea sincronizar. También puede especificar una consulta para este conjunto de datos, como se describe más adelante en este mismo tutorial. La consulta tiene prioridad sobre la tabla que se especifica en este paso.
Seleccione Aceptar.
Cambie al editor de canalización; para ello, seleccione la pestaña de la canalización de la parte superior o el nombre de esta de la vista de árbol de la izquierda. En la ventana de propiedades de la actividad Búsqueda, confirme que SourceDataset está seleccionado en la lista Conjunto de datos de origen.
Seleccione Consulta en Usar consulta. Actualice el nombre de la tabla en la siguiente consulta y escriba la consulta. Va a seleccionar solo el valor máximo de
timestampde la tabla. Asegúrese de seleccionar Solo la primera fila.SELECT MAX(timestamp) AS NewWatermarkValue FROM [TableName];
En el panel Actividades, expanda Mover y transformar, y arrastre la actividad Copia del panel Actividades a la superficie del diseñador. Asigne a la actividad el nombre IncrementalCopy.
Conecte las dos actividades Búsqueda con la actividad Copia; para ello, arrastre el botón verde de las actividades Búsqueda a la actividad Copia. Suelte el botón del mouse cuando vea el color del borde de la actividad de copia cambiar a azul.
Seleccione la actividad Copia y confirme que ve sus propiedades en la ventana Propiedades.
Cambie a la pestaña Origen de la ventana Propiedades y siga estos pasos:
En el cuadro Conjunto de datos de origen, seleccione SourceDataset.
En Usar consulta, seleccione Consulta.
Escriba la consulta SQL en el cuadro Consulta. Esta es una consulta de ejemplo:
SELECT * FROM TemperatureSensor WHERE timestamp > '@{activity(' OldWaterMark ').output.firstRow.WatermarkValue}' AND timestamp <= '@{activity(' NewWaterMark ').output.firstRow.NewWatermarkvalue}';En la pestaña Receptor, seleccione Nuevo en Conjunto de datos del receptor.
En este tutorial, el almacén de datos del receptor es de Azure Blob Storage. Seleccione Azure Blob Storage y Continuar en la ventana Nuevo conjunto de datos.
En la ventana Seleccionar formato, seleccione el formato de los datos y, después, seleccione Continuar.
En la ventana Establecer propiedades, en Nombre, escriba SinkDataset. En Servicio vinculado, seleccione Nuevo. Ahora va a crear una conexión (un servicio vinculado) a su instancia de Azure Blob Storage.
En la ventana New Linked Service (Azure Blob Storage) [Nuevo servicio vinculado (Azure Blob Storage)], siga estos pasos:
En el cuadro Nombre, escriba AzureStorageLinkedService.
En Nombre de la cuenta de Storage, seleccione la cuenta de Azure Storage de su suscripción a Azure.
Pruebe la conexión y seleccione Finalizar.
En la ventana Establecer propiedades, confirme que AzureStorageLinkedService está seleccionado en Servicio vinculado. Seleccione Crear y Aceptar.
En la pestaña Receptor, seleccione Edición.
Vaya a la pestaña Conexión de SinkDataset y siga estos pasos:
En Ruta de acceso del archivo, escriba
asdedatasync/incrementalcopy, dondeasdedatasynces el nombre del contenedor de blobs yincrementalcopyes el nombre de la carpeta. Cree el contenedor, en caso de que no exista, o use el nombre de uno existente. Si no existe, Azure Data Factory crea automáticamente la carpeta de salidaincrementalcopy. También puede usar el botón Browse (Examinar) para ir a una carpeta del contenedor de blobs mediante la ruta de acceso del archivo.En la parte Archivo del campo Ruta de acceso de archivo, seleccione Agregar contenido dinámico [ALT+P] y, después, escriba
@CONCAT('Incremental-', pipeline().RunId, '.txt')en la ventana abierta. Seleccione Finalizar. La expresión genera el nombre de archivo dinámicamente. Cada ejecución de canalización tiene un identificador único. La actividad de copia usa el identificador de ejecución para generar el nombre de archivo.
Cambie al editor de canalización; para ello, seleccione la pestaña de la canalización de la parte superior o el nombre de esta de la vista de árbol de la izquierda.
En el panel Actividades, expanda General, arrastre la actividad Procedimiento almacenado del panel Actividades para colocarla en la superficie del diseñador de canalizaciones. Conecte la salida verde (correcto) de la actividad Copia con la actividad Procedimiento almacenado.
Seleccione Actividad del procedimiento almacenada en el diseñador de canalizaciones y cambie su nombre a
SPtoUpdateWatermarkActivity.Cambie a la pestaña Cuenta de SQL y seleccione *QLDBEdgeLinkedService en Servicio vinculado.
Cambie a la pestaña Procedimiento almacenado y siga estos pasos:
En Nombre del procedimiento almacenado, seleccione
[dbo].[usp_write_watermark].Para especificar los valores de los parámetros del procedimiento almacenado, seleccione Parámetro de importación y escriba los valores siguientes para los parámetros:
Nombre Tipo Value LastModifiedTime DateTime @{activity('NewWaterMark').output.firstRow.NewWatermarkvalue}TableName String @{activity('OldWaterMark').output.firstRow.TableName}Para comprobar la configuración de la canalización, seleccione Validate (Comprobar) en la barra de herramientas. Confirme que no haya errores de comprobación. Para cerrar la ventana Informe de comprobación de canalización, seleccione >>.
Publique las entidades (servicios vinculados, conjuntos de datos y canalizaciones) en el servicio Azure Data Factory, para lo que debe seleccionar el botón Publicar todo. Espere hasta que vea un mensaje que confirme que la operación de publicación se ha realizado correctamente.
Desencadenamiento de canalizaciones según una programación
En la barra de herramientas de la canalización, seleccione Agregar desencadenador, después, Nuevo/Editar y, finalmente, + Nuevo.
Asigne al desencadenador el nombre HourlySync. En Tipo, seleccione Programar. En Periodicidad, seleccione cada 1 hora.
Seleccione Aceptar.
Seleccione Publish All (Publicar todo).
Seleccione Trigger Now (Desencadenar ahora).
Cambie a la pestaña Monitor (Supervisar) de la izquierda. Puede ver el estado de ejecución de la canalización activado por el desencadenador manual. Seleccione Refresh (Actualizar) para actualizar la lista.
Contenido relacionado de ##
- La canalización de Azure Data Factory de este tutorial copia los datos de una tabla de una instancia de SQL Edge en una ubicación de Azure Blob Storage cada hora. Para aprender a usar Data Factory en otros escenarios, consulte los siguientes tutoriales.