Diseño de una base de datos multiinquilino con Azure Cosmos DB for PostgreSQL
SE APLICA A: ![]() Azure Cosmos DB for PostgreSQL (con tecnología de la extensión de base de datos de Citus en PostgreSQL)
Azure Cosmos DB for PostgreSQL (con tecnología de la extensión de base de datos de Citus en PostgreSQL)
En este tutorial, usará Azure Cosmos DB for PostgreSQL para aprender a:
- Crear un clúster
- Uso de la utilidad psql para crear un esquema
- Particiones de tablas entre nodos
- Ingesta de datos de ejemplo
- Consulta de datos de inquilino
- Datos compartidos entre los inquilinos
- Personalización de esquema por inquilino
Prerrequisitos
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Crear un clúster
Inicie sesión en Azure Portal y siga estos pasos para crear un clúster de Azure Cosmos DB for PostgreSQL:
Vaya a Crear un clúster de Azure Cosmos DB for PostgreSQL en Azure Portal.
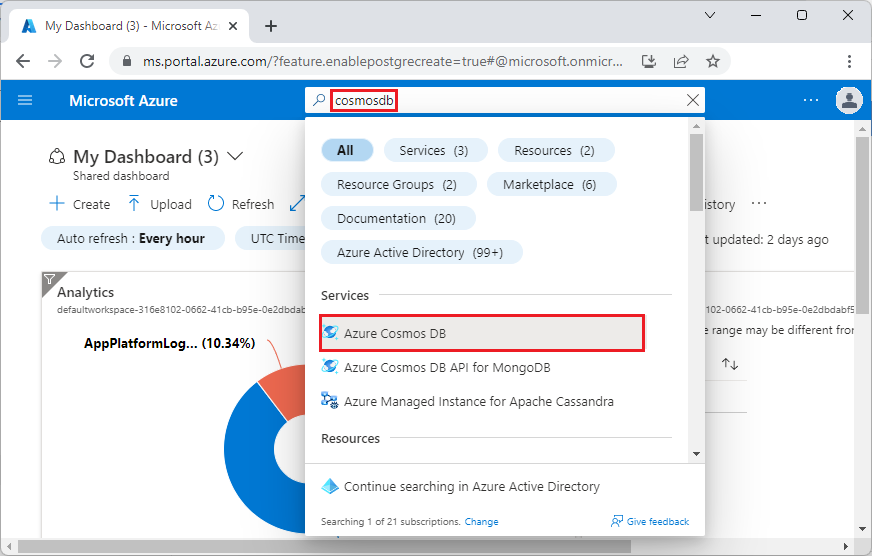
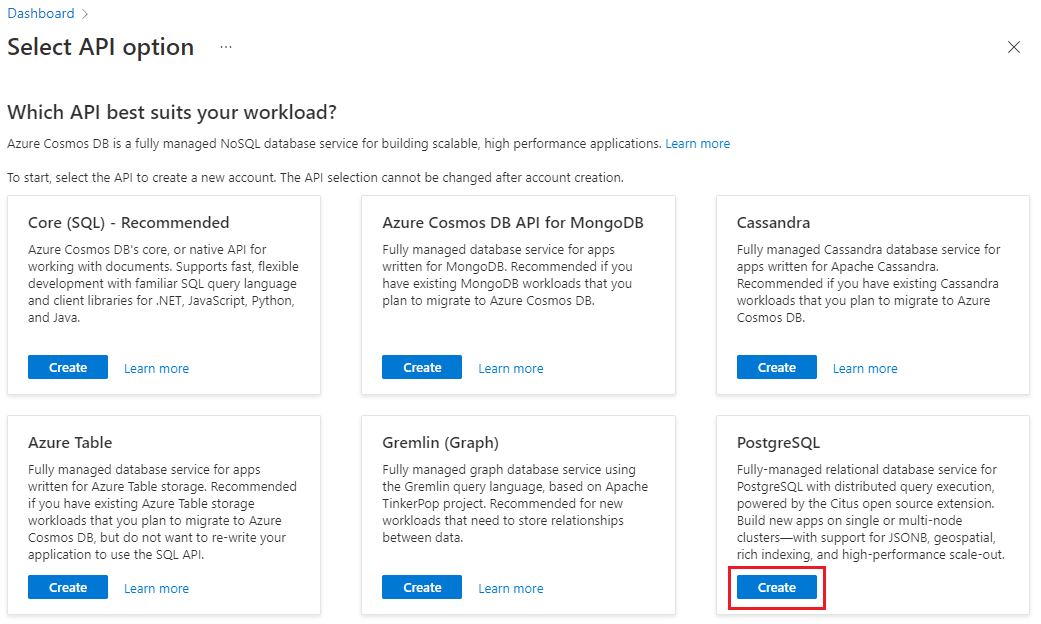
En el formulario Crear un clúster de Azure Cosmos DB for PostgreSQL:
Rellene la información de la pestaña Aspectos básicos.
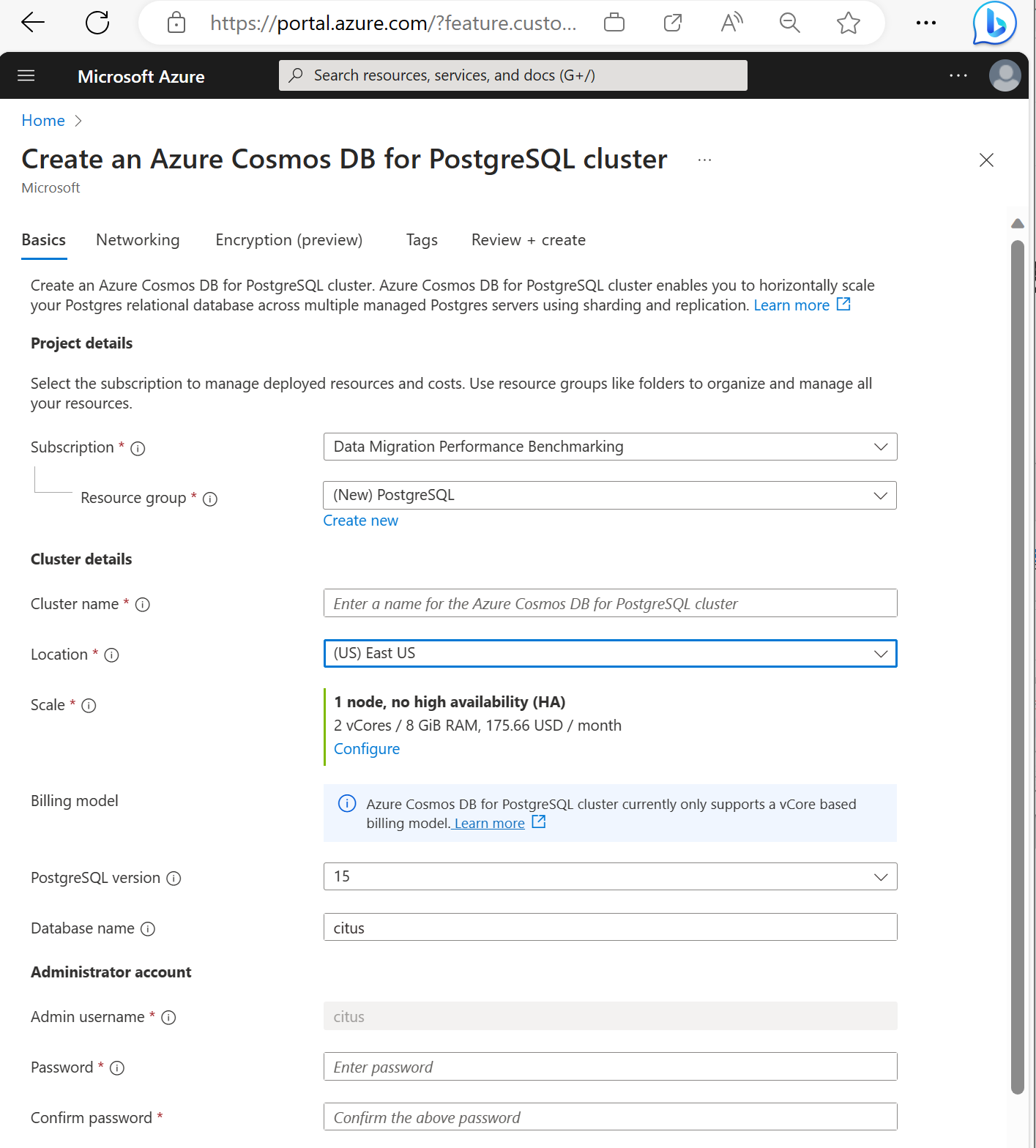
La mayoría de las opciones son autoexplicativas, pero tenga en cuenta lo siguiente:
- El nombre del clúster determina el nombre DNS que usan las aplicaciones para conectarse, con el formato
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Puede elegir una versión principal de PostgreSQL, como la 15. Azure Cosmos DB for PostgreSQL siempre admite la versión más reciente de Citus para la versión principal de Postgres seleccionada.
- Es necesario que el nombre de usuario administrador sea el valor
citus. - Puede dejar el nombre de la base de datos en su valor predeterminado "citus" o definir el único nombre de la base de datos. No se puede cambiar el nombre de la base de datos después del aprovisionamiento del clúster.
- El nombre del clúster determina el nombre DNS que usan las aplicaciones para conectarse, con el formato
Seleccione Siguiente: Redes en la parte inferior de la pantalla.
En la pantalla Redes, seleccione Permitir el acceso público desde los servicios y recursos de Azure dentro de Azure a este clúster.
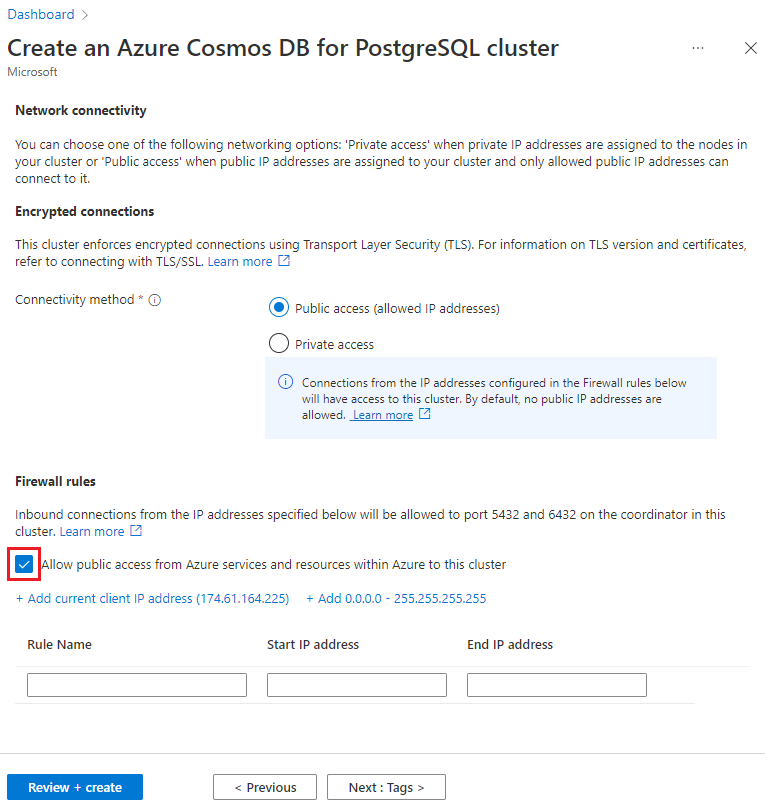
Seleccione Revisar y crear y, cuando se supere la validación, elija Crear para crear el clúster.
El aprovisionamiento tarda unos minutos. La página redirige a la implementación de supervisión. Cuando el estado cambie de Implementación en curso a Se completó la implementación, seleccione Ir al recurso.
Uso de la utilidad psql para crear un esquema
Una vez conectado a Azure Cosmos DB for PostgreSQL mediante psql, puede completar algunas tareas básicas. Este tutorial explica cómo crear una aplicación web que permite a los anunciantes realizar un seguimiento de sus campañas.
Varias empresas pueden usar la aplicación, así que crearemos una tabla que contenga las empresas y otra para sus campañas. En la consola de psql, ejecute estos comandos:
CREATE TABLE companies (
id bigserial PRIMARY KEY,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE campaigns (
id bigserial,
company_id bigint REFERENCES companies (id),
name text NOT NULL,
cost_model text NOT NULL,
state text NOT NULL,
monthly_budget bigint,
blocked_site_urls text[],
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id)
);
Cada campaña pagará por anunciarse. Agregue también una tabla para anuncios, ejecutando el siguiente código en psql después del código anterior:
CREATE TABLE ads (
id bigserial,
company_id bigint,
campaign_id bigint,
name text NOT NULL,
image_url text,
target_url text,
impressions_count bigint DEFAULT 0,
clicks_count bigint DEFAULT 0,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, campaign_id)
REFERENCES campaigns (company_id, id)
);
Por último, realizaremos un seguimiento de las estadísticas de clics e impresiones por cada anuncio:
CREATE TABLE clicks (
id bigserial,
company_id bigint,
ad_id bigint,
clicked_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_click_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
CREATE TABLE impressions (
id bigserial,
company_id bigint,
ad_id bigint,
seen_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_impression_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
Ahora puede ver las tablas recién creadas en la lista de tablas con este comando de psql:
\dt
Las aplicaciones multiinquilino pueden exigir exclusividad solo por inquilino, por lo que todas las claves principales y externas incluyen el identificador de la empresa.
Particiones de tablas entre nodos
Una implementación de Azure Cosmos DB for PostgreSQL almacena filas de tablas en distintos nodos en función del valor de una columna designada por el usuario. Esta "columna de distribución" indica qué filas pertenecen a qué inquilino.
Vamos a establecer la columna de distribución como company_id, el identificador del inquilino. En psql, ejecute estas funciones:
SELECT create_distributed_table('companies', 'id');
SELECT create_distributed_table('campaigns', 'company_id');
SELECT create_distributed_table('ads', 'company_id');
SELECT create_distributed_table('clicks', 'company_id');
SELECT create_distributed_table('impressions', 'company_id');
Importante
La distribución de tablas o el uso de particionamiento basado en esquemas es necesario para aprovechar las características de rendimiento de Azure Cosmos DB for PostgreSQL. Si no distribuye tablas o esquemas, los nodos de trabajo no pueden ayudar a ejecutar las consultas que impliquen sus datos.
Ingesta de datos de ejemplo
Ahora, fuera de psql, en la línea de comandos normal, descargue conjuntos de datos de ejemplo:
for dataset in companies campaigns ads clicks impressions geo_ips; do
curl -O https://examples.citusdata.com/mt_ref_arch/${dataset}.csv
done
De vuelta en psql, realice una carga masiva de los datos. No olvide ejecutar psql en el mismo directorio donde descargó los archivos de datos.
SET client_encoding TO 'UTF8';
\copy companies from 'companies.csv' with csv
\copy campaigns from 'campaigns.csv' with csv
\copy ads from 'ads.csv' with csv
\copy clicks from 'clicks.csv' with csv
\copy impressions from 'impressions.csv' with csv
Estos datos ahora se distribuirán entre nodos de trabajo.
Consulta de datos de inquilino
Cuando la aplicación solicita datos de un único inquilino, la base de datos puede ejecutar la consulta en un único nodo de trabajo. Las consultas de un único inquilino filtran por un único identificador de inquilino. Por ejemplo, la siguiente consulta filtra company_id = 5 para anuncios e impresiones. Intente ejecutarla en psql y observe los resultados.
SELECT a.campaign_id,
RANK() OVER (
PARTITION BY a.campaign_id
ORDER BY a.campaign_id, count(*) desc
), count(*) as n_impressions, a.id
FROM ads as a
JOIN impressions as i
ON i.company_id = a.company_id
AND i.ad_id = a.id
WHERE a.company_id = 5
GROUP BY a.campaign_id, a.id
ORDER BY a.campaign_id, n_impressions desc;
Datos compartidos entre los inquilinos
Hasta ahora company_id ha distribuido todas las tablas. Pero algunos datos no "pertenecen" de manera natural a ningún inquilino en particular y se pueden compartir. Por ejemplo, es posible que todas las empresas de la plataforma de anuncios del ejemplo deseen obtener información geográfica sobre su audiencia según las direcciones IP.
Cree una tabla que contenga información geográfica compartida. Ejecute los siguientes comandos en psql:
CREATE TABLE geo_ips (
addrs cidr NOT NULL PRIMARY KEY,
latlon point NOT NULL
CHECK (-90 <= latlon[0] AND latlon[0] <= 90 AND
-180 <= latlon[1] AND latlon[1] <= 180)
);
CREATE INDEX ON geo_ips USING gist (addrs inet_ops);
A continuación convierta geo_ips en una "tabla de referencia" para almacenar una copia de la tabla en cada nodo de trabajo.
SELECT create_reference_table('geo_ips');
Cargue en ella datos de ejemplo. No olvide ejecutar este comando en psql desde dentro del directorio donde descargó el conjunto de datos.
\copy geo_ips from 'geo_ips.csv' with csv
La combinación de la tabla de clics con geo_ips es eficaz en todos los nodos. Esta es una combinación para buscar las ubicaciones de todos los usuarios que han hecho clic en ad 290. Intente ejecutar la consulta en psql.
SELECT c.id, clicked_at, latlon
FROM geo_ips, clicks c
WHERE addrs >> c.user_ip
AND c.company_id = 5
AND c.ad_id = 290;
Personalización de esquema por inquilino
Cada inquilino puede necesitar almacenar información especial que otros no necesitan. Sin embargo, todos los inquilinos comparten una infraestructura común con un esquema de base de datos idéntico. ¿Dónde pueden ubicarse los datos adicionales?
Un truco consiste en usar un tipo de columna abierto, como JSONB de PostgreSQL. Nuestro esquema tiene un campo JSONB en clicks llamado user_data.
Una empresa (por ejemplo, la número cinco) puede usar la columna para realizar un seguimiento que determine si el usuario utiliza un dispositivo móvil.
Esta es una consulta para determinar qué usuarios hacen más clics: los visitantes tradicionales o los usuarios de dispositivos móviles.
SELECT
user_data->>'is_mobile' AS is_mobile,
count(*) AS count
FROM clicks
WHERE company_id = 5
GROUP BY user_data->>'is_mobile'
ORDER BY count DESC;
Podemos optimizar esta consulta para una empresa mediante la creación de un índice parcial.
CREATE INDEX click_user_data_is_mobile
ON clicks ((user_data->>'is_mobile'))
WHERE company_id = 5;
Por lo general, podemos crear un índices GIN en cada clave y valor de la columna.
CREATE INDEX click_user_data
ON clicks USING gin (user_data);
-- this speeds up queries like, "which clicks have
-- the is_mobile key present in user_data?"
SELECT id
FROM clicks
WHERE user_data ? 'is_mobile'
AND company_id = 5;
Limpieza de recursos
En los pasos anteriores, creó recursos de Azure en un clúster. Si no cree que vaya a necesitar estos recursos en un futuro, elimine el clúster. Seleccione el botón Eliminar en la página Información general del clúster. Cuando aparezca una página emergente en la que se le pida hacerlo, confirme el nombre del clúster y seleccione el botón Eliminar final.
Pasos siguientes
En este tutorial, ha aprendido a aprovisionar un clúster. Se conectó a él con psql, creó un esquema y distribuyó datos. Ha aprendido a consultar los datos dentro de los inquilinos y entre ellos, así como a personalizar el esquema por inquilino.
- Más información sobre los tipos de nodo de clúster
- Determinación del mejor tamaño inicial para el clúster