Copia y transformación de datos en Azure Database for MySQL mediante Azure Data Factory o Synapse Analytics
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. ¡Obtenga más información sobre cómo iniciar una nueva evaluación gratuita!
En este artículo se explica el uso de la actividad de copia en las canalizaciones de Azure Data Factory y Synapse Analytics para copiar datos desde y hacia Azure Database for MySQL, y cómo usar Data Flow para transformarlos en datos de Azure Database for MySQL. Para obtener más información, lea los artículos de introducción para Azure Data Factory y Synapse Analytics.
Este conector es especialmente adecuado para
Para copiar datos desde una base de datos MySQL genérica ubicada en el entorno local o en la nube, use el conector MySQL.
Requisitos previos
En este inicio rápido se necesitan los siguientes recursos y la configuración que se mencionan a continuación como punto de partida:
- Una base de datos de Azure existente para un servidor único de MySQL o un servidor flexible de MySQL con acceso público o punto de conexión privado.
- Habilite Permitir el acceso público desde cualquier servicio de Azure dentro de Azure a este servidor en la página de redes del servidor MySQL. Esto le permitirá usar Data Factory Studio.
Funcionalidades admitidas
Este conector de Azure Database for MySQL es compatible con las capacidades siguientes:
| Funcionalidades admitidas | IR | Puntos de conexión privados administrados de Synapse (versión preliminar) |
|---|---|---|
| Actividad de copia (origen/receptor) | ① ② | ✓ |
| Flujo de datos de asignación (origen/receptor) | ① | ✓ |
| Actividad de búsqueda | ① ② | ✓ |
① Azure Integration Runtime ② Entorno de ejecución de integración autohospedado
Introducción
Para realizar la actividad de copia con una canalización, puede usar una de los siguientes herramientas o SDK:
- La herramienta Copiar datos
- Azure Portal
- El SDK de .NET
- El SDK de Python
- Azure PowerShell
- API REST
- La plantilla de Azure Resource Manager
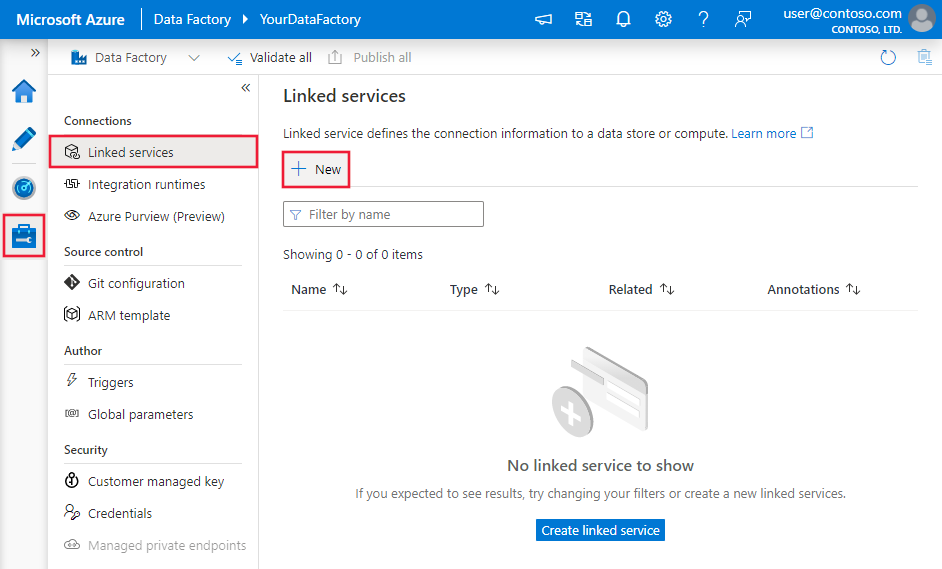
Creación de un servicio vinculado en Azure Database for MySQL mediante la interfaz de usuario
Siga estos pasos para crear un servicio vinculado en Azure Database for MySQL en la interfaz de usuario de Azure Portal.
Vaya a la pestaña Administrar del área de trabajo de Azure Data Factory o Synapse y seleccione Servicios vinculados; luego haga clic en Nuevo:
Busque MySQL y seleccione el conector de Azure Database for MySQL.

Configure los detalles del servicio, pruebe la conexión y cree el nuevo servicio vinculado.

Detalles de configuración del conector
En las secciones siguientes se proporcionan detalles sobre las propiedades que se usan para definir entidades de Data Factory específicas para el conector de Azure Database for MySQL.
Propiedades del servicio vinculado
Las siguientes propiedades son compatibles con el servicio vinculado de Azure Database for MySQL:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en: AzureMySql | Sí |
| connectionString | Especifique la información necesaria para conectarse a la instancia de Azure Database for MySQL. También puede colocar la contraseña en Azure Key Vault y extraer la configuración de password de la cadena de conexión. Consulte los siguientes ejemplos y el artículo Almacenamiento de credenciales en Azure Key Vault con información detallada. |
Sí |
| connectVia | El entorno Integration Runtime que se usará para conectarse al almacén de datos. Puede usar los entornos Integration Runtime (autohospedado) (si el almacén de datos se encuentra en una red privada) o Azure Integration Runtime. Si no se especifica, se usará Azure Integration Runtime. | No |
Una cadena de conexión típica es Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;PWD=<password>. Más propiedades que puede establecer para su caso:
| Propiedad | Descripción | Opciones | Obligatorio |
|---|---|---|---|
| SSLMode | Esta opción especifica si el controlador utiliza cifrado TLS y comprobación durante la conexión a MySQL. Por ejemplo SSLMode=<0/1/2/3/4> |
DISABLED (0) / PREFERRED (1) (valor predeterminado) / REQUIRED (2) / VERIFY_CA (3) / VERIFY_IDENTITY (4) | No |
| UseSystemTrustStore | Esta opción concreta si se usa un certificado de entidad de certificación del almacén de confianza del sistema o de un archivo PEM especificado. Por ejemplo UseSystemTrustStore=<0/1>; |
Habilitado (1) / Deshabilitado (0) (valor predeterminado) | No |
Ejemplo:
{
"name": "AzureDatabaseForMySQLLinkedService",
"properties": {
"type": "AzureMySql",
"typeProperties": {
"connectionString": "Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;PWD=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ejemplo: Almacenamiento de la contraseña en Azure Key Vault
{
"name": "AzureDatabaseForMySQLLinkedService",
"properties": {
"type": "AzureMySql",
"typeProperties": {
"connectionString": "Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propiedades del conjunto de datos
Si desea ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte el artículo sobre conjuntos de datos. En esta sección se proporciona una lista de las propiedades que admite el conjunto de datos de Azure Database for MySQL.
Para copiar datos desde Azure Database for MySQL, establezca la propiedad type del conjunto de datos en AzureMySqlTable. Se admiten las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del conjunto de datos debe establecerse en: AzureMySqlTable | Sí |
| tableName | Nombre de la tabla de la base de datos MySQL. | No (si se especifica "query" en el origen de la actividad) |
Ejemplo
{
"name": "AzureMySQLDataset",
"properties": {
"type": "AzureMySqlTable",
"linkedServiceName": {
"referenceName": "<Azure MySQL linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "<table name>"
}
}
}
Propiedades de la actividad de copia
Si desea ver una lista completa de las secciones y propiedades disponibles para definir actividades, consulte el artículo sobre canalizaciones. En esta sección se proporciona una lista de las propiedades que admite Azure Database for MySQL como origen y receptor.
Azure Database for MySQL como origen
Para copiar datos desde Azure Database for MySQL, se admiten las siguientes propiedades en la sección de origen de la actividad de copia:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en: AzureMySqlSource | Sí |
| Query | Use la consulta SQL personalizada para leer los datos. Por ejemplo: "SELECT * FROM MyTable". |
No (si se especifica "tableName" en el conjunto de datos) |
| queryCommandTimeout | El tiempo de espera antes de que se agote el tiempo de espera de la solicitud de consulta. El valor predeterminado es 120 minutos (02:00:00). | No |
Ejemplo:
"activities":[
{
"name": "CopyFromAzureDatabaseForMySQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure MySQL input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureMySqlSource",
"query": "<custom query e.g. SELECT * FROM MyTable>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Database for MySQL como receptor
Para copiar datos en Azure Database for MySQL, se admiten las siguientes propiedades en la sección de receptor de la actividad de copia:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del receptor de la actividad de copia debe establecerse en: AzureMySqlSink | Sí |
| preCopyScript | Especifique una consulta SQL para que la actividad de copia se ejecute antes de escribir datos en Azure Database for MySQL en cada ejecución. Puede usar esta propiedad para limpiar los datos cargados previamente. | No |
| writeBatchSize | Inserta datos en la tabla de Azure Database for MySQL cuando el tamaño de búfer alcanza el valor de writeBatchSize. El valor permitido es un entero que representa el número de filas. |
No (el valor predeterminado es 10 000) |
| writeBatchTimeout | Tiempo de espera para que la operación de inserción por lotes se complete antes de que se agote el tiempo de espera. Los valores permitidos son intervalos de tiempo. Un ejemplo es 00:30:00 (30 minutos). |
No (el valor predeterminado es 00:00:30) |
Ejemplo:
"activities":[
{
"name": "CopyToAzureDatabaseForMySQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure MySQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureMySqlSink",
"preCopyScript": "<custom SQL script>",
"writeBatchSize": 100000
}
}
}
]
Propiedades de Asignación de instancias de Data Flow
Al transformar datos en el flujo de datos de asignación, puede leer tablas y escribir en ellas desde Azure Database for MySQL. Para más información, vea la transformación de origen y la transformación de receptor en los flujos de datos de asignación. Puede optar por usar un conjunto de datos de Azure Database for MySQL o un conjunto de datos insertado como tipo de origen y receptor.
Transformación de origen
En la tabla siguiente se enumeran las propiedades compatibles con el origen de Azure Database for MySQL. Puede editar estas propiedades en la pestaña Source options (Opciones del origen).
| Nombre | Descripción | Obligatorio | Valores permitidos | Propiedad de script de flujo de datos |
|---|---|---|---|---|
| Tabla | Si selecciona Tabla como entrada, el flujo de datos captura todos los datos de la tabla especificada en el conjunto de datos. | No | - | (solo para conjunto de datos en línea) tableName |
| Consultar | Si selecciona Consultar como entrada, especifique una consulta SQL para capturar datos del origen, lo que invalida cualquier tabla que especifique en el conjunto de datos. El uso de consultas es una excelente manera de reducir las filas para pruebas o búsquedas. La cláusula Ordenar por no se admite, pero puede establecer una instrucción SELECT FROM completa. También puede usar las funciones de tabla definidas por el usuario. select * from udfGetData() es un UDF in SQL que devuelve una tabla que puede utilizar en el flujo de datos. Ejemplo de consulta: select * from mytable where customerId > 1000 and customerId < 2000 o select * from "MyTable". |
No | String | Query |
| Procedimiento almacenado | Si selecciona "Procedimiento almacenado" como entrada, especifique el nombre del procedimiento almacenado para leer datos de la tabla de origen o seleccione "Actualizar" para pedir al servicio que detecte los nombres de procedimiento. | Sí (si selecciona "Procedimiento almacenado" como entrada) | String | procedureName |
| Parámetros de procedimiento | Si selecciona "Procedimiento almacenado" como entrada, especifique los parámetros de entrada del procedimiento almacenado en el orden establecido en el procedimiento o seleccione "Importar" para importar todos los parámetros de procedimiento mediante el formulario @paraName. |
No | Array | inputs |
| Tamaño de lote | Especifique un tamaño de lote para fragmentar datos de gran tamaño en lotes. | No | Entero | batchSize |
| Nivel de aislamiento | Elija uno de los siguientes niveles de aislamiento: - Read Committed - Read Uncommitted (predeterminado) - Repeatable Read - Serializable - None (ignorar el nivel de aislamiento) |
No | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE NONE |
isolationLevel |
Ejemplo de script de origen de Azure Database for MySQL
Cuando se usa Azure Database for MySQL como tipo de origen, el script de flujo de datos asociado es:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzureMySQLSource
Transformación de receptor
En la tabla siguiente se enumeran las propiedades compatibles con el receptor de Azure Database for MySQL. Puede editar estas propiedades en la pestaña Opciones del receptor.
| Nombre | Descripción | Obligatorio | Valores permitidos | Propiedad de script de flujo de datos |
|---|---|---|---|---|
| Método de actualización | Especifique qué operaciones se permiten en el destino de la base de datos. El valor predeterminado es permitir solamente las inserciones. Para actualizar, upsert o eliminar filas, se requiere una transformación de alteración de fila a fin de etiquetar filas para esas acciones. |
Sí | true o false |
deletable insertable updateable upsertable |
| Columnas de clave | En el caso de las actualizaciones, upserts y eliminaciones, se deben establecer columnas de clave para determinar la fila que se va a modificar. El nombre de columna que elija como clave se usará como parte de las operaciones posteriores de actualización, upsert y eliminación. Por lo tanto, debe seleccionar una columna que exista en la asignación del receptor. |
No | Array | claves |
| Omitir escritura de columnas de clave | Si no quiere escribir el valor en la columna de clave, seleccione "Skip writing key columns" (Omitir escritura de columnas de clave). | No | true o false |
skipKeyWrites |
| Acción Table | determina si se deben volver a crear o quitar todas las filas de la tabla de destino antes de escribir. - Ninguno: no se realizará ninguna acción en la tabla. - Volver a crear: se quitará la tabla y se volverá a crear. Obligatorio si se crea una nueva tabla dinámicamente. - Truncar: se quitarán todas las filas de la tabla de destino. |
No | true o false |
recreate truncate |
| Tamaño de lote | Especifique el número de filas que se escriben en cada lote. Los tamaños de lote más grandes mejoran la compresión y la optimización de memoria, pero se arriesgan a obtener excepciones de memoria al almacenar datos en caché. | No | Entero | batchSize |
| Scripts SQL anteriores y posteriores | Especifique scripts de SQL de varias líneas que se ejecutarán antes (preprocesamiento) y después (procesamiento posterior) de que los datos se escriban en la base de datos del receptor. | No | String | preSQLs postSQLs |
Sugerencia
- Se recomienda dividir los scripts por lotes únicos con varios comandos en varios lotes.
- Tan solo las instrucciones de lenguaje de definición de datos (DDL) y lenguaje de manipulación de datos (DML) que devuelven un recuento de actualizaciones sencillo se pueden ejecutar como parte de un lote. Obtenga más información en Realización de operaciones por lotes
Habilitar extracción incremental: use esta opción para indicar a ADF que procese solo las filas que hayan cambiado desde la última vez que se ejecutó la canalización.
Columna incremental: si se usa la característica de extracción incremental, es preciso elegir la columna numérica o de fecha y hora que desea se usar como marca de agua en la tabla de origen.
Empezar a leer desde el principio: si se establece esta opción con extracción incremental, se indicará a ADF que lea todas las filas en la primera ejecución de una canalización con la extracción incremental activada.
Ejemplo de script de receptor de Azure Database for MySQL
Cuando se usa Azure Database for MySQL como tipo de receptor, el script de flujo de datos asociado es:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureMySQLSink
Propiedades de la actividad de búsqueda
Para obtener información detallada sobre las propiedades, consulte Actividad de búsqueda.
Asignación de tipos de datos para Azure Database for MySQL
Al copiar datos desde Azure Database for MySQL, se utilizan las siguientes asignaciones de tipos de datos de MySQL en los tipos de datos provisionales usados internamente dentro del servicio. Consulte el artículo sobre asignaciones de tipos de datos y esquema para información sobre cómo la actividad de copia asigna el tipo de datos y el esquema de origen al receptor.
| Tipo de datos de Azure Database for MySQL | Tipo de datos de servicio provisional |
|---|---|
bigint |
Int64 |
bigint unsigned |
Decimal |
bit |
Boolean |
bit(M), M>1 |
Byte[] |
blob |
Byte[] |
bool |
Int16 |
char |
String |
date |
Datetime |
datetime |
Datetime |
decimal |
Decimal, String |
double |
Double |
double precision |
Double |
enum |
String |
float |
Single |
int |
Int32 |
int unsigned |
Int64 |
integer |
Int32 |
integer unsigned |
Int64 |
long varbinary |
Byte[] |
long varchar |
String |
longblob |
Byte[] |
longtext |
String |
mediumblob |
Byte[] |
mediumint |
Int32 |
mediumint unsigned |
Int64 |
mediumtext |
String |
numeric |
Decimal |
real |
Double |
set |
String |
smallint |
Int16 |
smallint unsigned |
Int32 |
text |
String |
time |
TimeSpan |
timestamp |
Datetime |
tinyblob |
Byte[] |
tinyint |
Int16 |
tinyint unsigned |
Int16 |
tinytext |
String |
varchar |
String |
year |
Int32 |
Contenido relacionado
Para obtener una lista de almacenes de datos que la actividad de copia admite como orígenes y receptores, vea Almacenes de datos que se admiten.