Oharra
Baimena behar duzu orria atzitzeko. Direktorioetan saioa has dezakezu edo haiek alda ditzakezu.
Baimena behar duzu orria atzitzeko. Direktorioak alda ditzakezu.
Una tabla de streaming es una tabla Delta con compatibilidad adicional para el procesamiento de datos incremental o de streaming. Una tabla de streaming puede tener como destino uno o varios flujos de una canalización.
Las tablas de streaming son una buena opción para la ingesta de datos por los siguientes motivos:
- Cada fila de entrada solo se procesa una vez, lo que modela la gran mayoría de las cargas de trabajo de ingestión (es decir, añadiendo o actualizando filas dentro de una tabla).
- Pueden controlar grandes volúmenes de datos de solo anexión.
Las tablas de streaming también son una buena opción para las transformaciones de streaming de baja latencia, ya que pueden razonar sobre filas y ventanas de tiempo, controlar grandes volúmenes de datos y proporcionar procesamiento de baja latencia.
En el diagrama siguiente se muestra cómo los flujos se leen de orígenes de streaming y se escriben de forma incremental en una tabla de streaming dentro de una canalización.
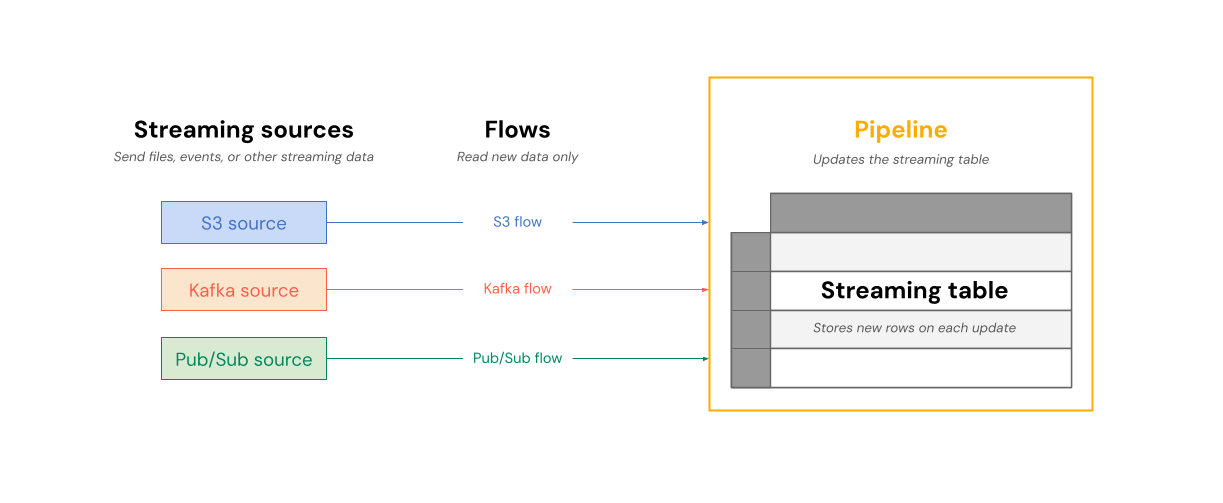
En cada actualización, los flujos asociados a una tabla streaming leen la información modificada en un origen de streaming y anexan nueva información a esa tabla.
Las tablas de streaming son propiedad y se actualizan mediante una sola canalización. Las tablas de streaming se definen explícitamente en el código fuente de la canalización. Las tablas definidas por una canalización no se pueden cambiar ni actualizar mediante ninguna otra canalización. Puede definir varios flujos para anexar a una sola tabla de streaming.
Azure Databricks crea tablas internas para admitir el procesamiento de tablas de streaming. Estas tablas aparecen en system.information_schema.tables pero no están visibles en el Explorador de catálogos u otras páginas de interfaz de usuario del área de trabajo.
Nota:
Al crear una tabla de streaming fuera de una canalización mediante Databricks SQL, Azure Databricks crea una canalización que se usa para actualizar la tabla. Para ver la canalización, seleccione Trabajos y canalizaciones en el panel de navegación izquierdo del área de trabajo. Puede agregar la columna Tipo de canalización a la vista. Las tablas de streaming definidas en una canalización tienen un tipo de ETL. Las tablas de streaming creadas en Databricks SQL tienen un tipo de MV/ST.
Para obtener más información sobre los flujos, consulte Carga y procesamiento de datos de forma incremental con flujos de canalizaciones declarativas de Spark de Lakeflow.
Tablas de streaming para la ingestión
Las tablas de streaming están diseñadas para orígenes de datos de solo anexión y procesan entradas solo una vez. Esto hace que sean adecuados para cargas de trabajo de ingesta en las que los datos llegan continuamente y deben capturarse de forma confiable sin volver a procesar los registros existentes. Azure Databricks admite la ingesta de datos desde el almacenamiento en la nube y los buses de mensajes de streaming.
Ingesta de archivos desde el almacenamiento en la nube
Puede usar una tabla streaming para ingerir archivos nuevos desde el almacenamiento en la nube. En estos ejemplos se usa Auto Loader para procesar incrementalmente nuevos archivos a medida que llegan.
Pitón
from pyspark import pipelines as dp
# Create a streaming table
@dp.table
def customers_bronze():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load("/Volumes/path/to/files")
)
Para crear una tabla de streaming, la definición del conjunto de datos debe ser un tipo de flujo. Cuando se usa la spark.readStream función en una definición de conjunto de datos, devuelve un conjunto de datos de streaming.
SQL
-- Create a streaming table
CREATE OR REFRESH STREAMING TABLE customers_bronze
AS SELECT * FROM STREAM read_files(
"/volumes/path/to/files",
format => "json"
);
Las tablas de streaming requieren conjuntos de datos de streaming. La STREAM palabra clave antes read_files indica a la consulta que trate el conjunto de datos como una secuencia.
Ingesta de mensajes de streaming
También puede usar tablas de streaming para ingerir datos de buses de mensajes. En el ejemplo siguiente se muestra cómo crear una tabla de streaming que lee de un tema Pub/Sub.
Pitón
@dp.table
def pubsub_raw():
auth_options = {
"clientId": client_id,
"clientEmail": client_email,
"privateKey": private_key,
"privateKeyId": private_key_id
}
return (
spark.readStream
.format("pubsub")
.option("subscriptionId", "my-subscription")
.option("topicId", "my-topic")
.option("projectId", "my-project")
.options(auth_options)
.load()
)
SQL
CREATE OR REFRESH STREAMING TABLE pubsub_raw
AS SELECT * FROM STREAM read_pubsub(
subscriptionId => 'my-subscription',
projectId => 'my-project',
topicId => 'my-topic',
clientEmail => secret('pubsub-scope', 'clientEmail'),
clientId => secret('pubsub-scope', 'clientId'),
privateKeyId => secret('pubsub-scope', 'privateKeyId'),
privateKey => secret('pubsub-scope', 'privateKey')
);
Databricks recomienda usar secretos al proporcionar opciones de autorización. Consulte Configuración del acceso a Pub/Sub para todas las opciones de autenticación.
Para más información sobre cómo cargar datos en la tabla de streaming, consulte Carga de datos en canalizaciones.
En el diagrama siguiente se muestra cómo funcionan las tablas de flujo de datos que solo se anexan.
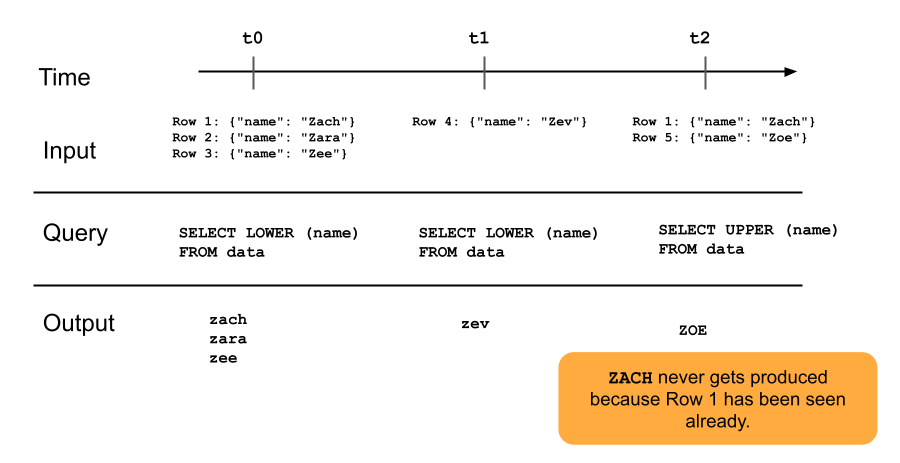
Una fila que ya se ha anexado a una tabla de transmisión no se volverá a consultar con las actualizaciones posteriores de la canalización. Si modifica la consulta (por ejemplo, de SELECT LOWER (name) a SELECT UPPER (name)), las filas existentes no se actualizarán para que estén en mayúsculas, pero las filas nuevas serán mayúsculas. Puede iniciar una actualización completa para realizar una nueva consulta de todos los datos anteriores de la tabla de origen y actualizar todas las filas de la tabla Streaming.
Tablas de streaming y streaming de baja latencia
Las tablas de streaming están diseñadas para el streaming de baja latencia a través del estado limitado. Las tablas de streaming usan la administración de puntos de control, lo que hace que sean adecuadas para el streaming de baja latencia. Sin embargo, esperan secuencias que están naturalmente limitadas o limitadas con una marca de agua.
Un flujo naturalmente delimitado se genera mediante un origen de datos de streaming que tiene un inicio y un final bien definidos. Un ejemplo de un flujo delimitado naturalmente es la lectura de datos desde un directorio de archivos donde no se añaden nuevos archivos después de colocar un lote inicial de archivos. El flujo se considera acotado porque el número de archivos es finito y el flujo finaliza después de que se hayan procesado todos los archivos.
También puede usar una marca de agua para enlazar una secuencia. Una marca de agua en Structured Streaming es un mecanismo que ayuda a manejar los datos tardíos especificando cuánto tiempo debe esperar el sistema para los eventos retrasados antes de considerar la ventana temporal como finalizada. Un flujo sin límites que no tiene una marca de agua puede causar un fallo en una tubería debido a la presión de memoria.
Para obtener más información sobre el procesamiento de flujos con estado, consulte Optimización del procesamiento con estado utilizando marcas de agua.
Combinaciones de instantáneas y secuencias
Las combinaciones de instantáneas de secuencia conectan un conjunto de datos de streaming a una tabla de dimensiones que se instantánea en el inicio de la secuencia. Dado que la tabla de dimensiones se considera como fija en ese momento dado, los cambios realizados en ella después de que se inicie el flujo no se reflejan en la unión. Esto es aceptable cuando no importan pequeñas discrepancias; por ejemplo, cuando el número de transacciones es muchas órdenes de magnitud mayor que el número de clientes.
En el ejemplo de código siguiente se combina una tabla de dimensiones con dos filas llamadas customers con un conjunto de datos cada vez mayor, transactions. Materializa una combinación entre estos dos conjuntos de datos en una tabla denominada sales_report. Si un proceso externo actualiza la tabla de clientes agregando una nueva fila (customer_id=3, name=Zoya), esta nueva fila no estará presente en el join porque la tabla de dimensiones estáticas se ha capturado al iniciarse las secuencias.
from pyspark import pipelines as dp
@dp.temporary_view
# assume this table contains an append-only stream of rows about transactions
# (customer_id=1, value=100)
# (customer_id=2, value=150)
# (customer_id=3, value=299)
# ... <and so on> ...
def v_transactions():
return spark.readStream.table("transactions")
# assume this table contains only these two rows about customers
# (customer_id=1, name=Bilal)
# (customer_id=2, name=Olga)
@dp.temporary_view
def v_customers():
return spark.read.table("customers")
@dp.table
def sales_report():
facts = spark.readStream.table("v_transactions")
dims = spark.read.table("v_customers")
return facts.join(dims, on="customer_id", how="inner")
Limitaciones de la tabla de streaming
Las tablas de streaming tienen las siguientes limitaciones:
-
Evolución limitada: Puede cambiar la consulta sin volver a calcular todo el conjunto de datos. Sin una actualización completa, una tabla de streaming solo ve cada fila una vez, por lo que las consultas diferentes habrán procesado filas diferentes. Por ejemplo, si agrega
UPPER()a un campo de la consulta, solo las filas procesadas después del cambio estarán en mayúsculas. Esto significa que debe tener en cuenta todas las versiones anteriores de la consulta que se ejecutan en el conjunto de datos. Para volver a procesar las filas existentes que se procesaron antes del cambio, se requiere una actualización completa. - Administración de estados: Las tablas de streaming son de baja latencia y requieren flujos de datos que están naturalmente limitados o delimitados con una marca de agua. Para obtener más información, consulte Optimice el procesamiento con estado usando marcas de agua.
- Las combinaciones no se vuelven a calcular: Las combinaciones en tablas de streaming no se vuelven a calcular cuando cambian las dimensiones. Esta característica puede ser buena para escenarios "rápidos pero incorrectos". Si desea que la vista sea siempre correcta, es posible que quiera usar una vista materializada. Las vistas materializadas siempre son correctas porque vuelven a calcular automáticamente las combinaciones cuando cambian las dimensiones. Para obtener más información, vea Vistas materializadas.