Escalado automático de clústeres de Azure HDInsight
La característica de escalabilidad automática gratuita de Azure HDInsight puede aumentar o disminuir automáticamente el número de nodos de trabajo del clúster en función de las métricas del clúster y la directiva de escalado que adopten los clientes. La característica de Escalabilidad automática funciona mediante el escalado del número de nodos dentro de los límites preestablecidos en función de las métricas de rendimiento o de una programación definida de las operaciones de escalado y reducción vertical.
Funcionamiento
La característica de escalabilidad automática emplea dos tipos de condiciones para desencadenar eventos de escalado: umbrales para varias métricas de rendimiento del clúster (lo que se conoce como escalado basado en la carga) y desencadenadores basados en el tiempo (lo que se conoce como escalado basado en la programación). El escalado basado en cargas cambia el número de nodos del clúster, dentro de un intervalo establecido, para garantizar el uso de CPU óptimo y minimizar el costo de ejecución. El escalado basado en programación cambia el número de nodos del clúster en función de una programación de operaciones de escalado y reducción vertical.
En el vídeo siguiente se proporciona información general sobre los desafíos que puede resolver la escalabilidad automática y cómo puede ayudarle a controlar los costos con HDInsight.
Elección del escalado basado en carga o basado en programación
Se puede usar el escalado basado en programaciones:
- Cuando se espera que los trabajos se ejecuten según programaciones fijas y durante una duración predecible o Cuando se prevé un uso bajo durante horas específicas del día. Por ejemplo, entornos de prueba y desarrollo en horario extralaboral, al final de la jornada laboral.
Se puede usar el escalado basado en cargas:
- Cuando los patrones de carga fluctúan de manera considerable e impredecible durante el día. Por ejemplo, ordene el procesamiento de datos con fluctuaciones aleatorias en los patrones de carga en función de varios factores.
Métricas del clúster
La escalabilidad automática supervisa continuamente el clúster y recopila las métricas siguientes:
| Métrica | Descripción |
|---|---|
| Total de CPU pendiente | El número total de núcleos necesarios para iniciar la ejecución de todos los contenedores pendientes. |
| Total de memoria pendiente | La memoria total (en MB) necesaria para iniciar la ejecución de todos los contenedores pendientes. |
| Total de CPU libre | La suma de todos los núcleos sin usar en los nodos de trabajo activos. |
| Total de memoria libre | La suma de la memoria sin usar (en MB) en los nodos de trabajo activos. |
| Memoria usada por nodo | La carga en un nodo de trabajo. Un nodo de trabajo donde se usan 10 GB de memoria se considera bajo más carga que un trabajo con 2 GB de memoria usada. |
| Número de patrones de aplicación por nodo | El número de contenedores de patrones de aplicación (AM) que se ejecutan en un nodo de trabajo. Un nodo de trabajo que hospeda dos contenedores de AM se considera más importante que un nodo de trabajo que no hospeda ninguno de estos contenedores. |
Las métricas anteriores se comprueban cada 60 segundos. La escalabilidad automática toma decisiones de escalar o reducir verticalmente según estas métricas.
Para obtener una lista completa de las métricas de clúster, consulte Métricas compatibles para Microsoft.HDInsight/clusters.
Condiciones de escalado basado en la carga
Cuando se detectan las condiciones siguientes, Escalabilidad automática emite una solicitud de escalado:
| Escalabilidad vertical | Reducción vertical |
|---|---|
| El total de CPU pendiente es mayor que el total de CPU libre durante más de 3 a 5 minutos. | El total de CPU pendiente es menor que el total de CPU libre durante más de 3-5 minutos. |
| El total de memoria pendiente es mayor que el total de memoria libre durante más de 3 a 5 minutos. | El total de memoria pendiente es menor que el total de memoria libre durante más de 3-5 minutos. |
En el caso del escalado vertical, la Escalabilidad automática emite una solicitud para agregar el número necesario de nodos. El escalado vertical se basa en el número de nodos de trabajo nuevos que son necesarios para satisfacer los requisitos de CPU y memoria actuales.
En el caso de la reducción vertical, la Escalabilidad automática emite una solicitud para quitar algunos nodos. La reducción vertical se basa en el número de contenedores de patrones de aplicación (AM) por nodo. y en los requisitos actuales de CPU y memoria. El servicio detecta también qué nodos son candidatos para la eliminación en función de la ejecución del trabajo actual. En primer lugar, la operación de reducción vertical retira los nodos y, luego, los quita del clúster.
Consideraciones de ajuste de tamaño de la base de datos de Ambari para el escalado automático
Se recomienda que la base de datos de Ambari tenga el tamaño correcto para aprovechar las ventajas del escalado automático. Los clientes deben usar el nivel de base de datos correcto y usar la base de datos de Ambari personalizada para clústeres de gran tamaño. Lea las recomendaciones de ajuste de tamaño de base de datos y nodos principales.
Compatibilidad con el clúster
Importante
La característica de escalado automático de Azure HDInsight se lanzó con carácter general el 7 de noviembre de 2019 para los clústeres de Spark y Hadoop, e incluía mejoras que no están disponibles en la versión preliminar de la característica. Si creó un clúster de Spark antes del 7 de noviembre de 2019 y quiere usar la característica de Escalabilidad automática en el clúster, la ruta de acceso recomendada es crear un nuevo clúster y enable Autoscale en el nuevo clúster.
La escalabilidad automática de Interactive Query (LLAP) se publicó en disponibilidad general para HDI 4.0 el 27 de agosto de 2020. El escalado automático solo está disponible en clústeres de Spark, Hadoop e Interactive Query.
En la tabla siguiente se describen las versiones y los tipos de clúster que son compatibles con la característica de escalabilidad automática.
| Versión | Spark | Hive | Interactive Query | HBase | Kafka |
|---|---|---|---|---|---|
| HDInsight 4.0 sin ESP | Sí | Sí | Sí* | No | No |
| HDInsight 4.0 con ESP | Sí | Sí | Sí* | No | No |
| HDInsight 5.0 sin ESP | Sí | Sí | Sí* | No | No |
| HDInsight 5.0 con ESP | Sí | Sí | Sí* | No | No |
* Los clústeres de Interactive Query solo se pueden configurar para escalado basado en programaciones, no basado en cargas.
Introducción
Creación de un clúster con Escalabilidad automática basada en carga
Para habilitar la característica Escalabilidad automática con escalado basado en carga, complete estos pasos como parte del proceso de creación de clúster normal:
En la pestaña Configuración y precios, seleccione la casilla
Enable autoscale.Seleccione Load-based (Basada en carga) en Tipo de escalabilidad automática.
Escriba los valores previstos para estas propiedades:
- Número de nodos inicial para Nodo de trabajo.
- Número Mín. de nodos de trabajo.
- Número Máx. de nodos de trabajo.
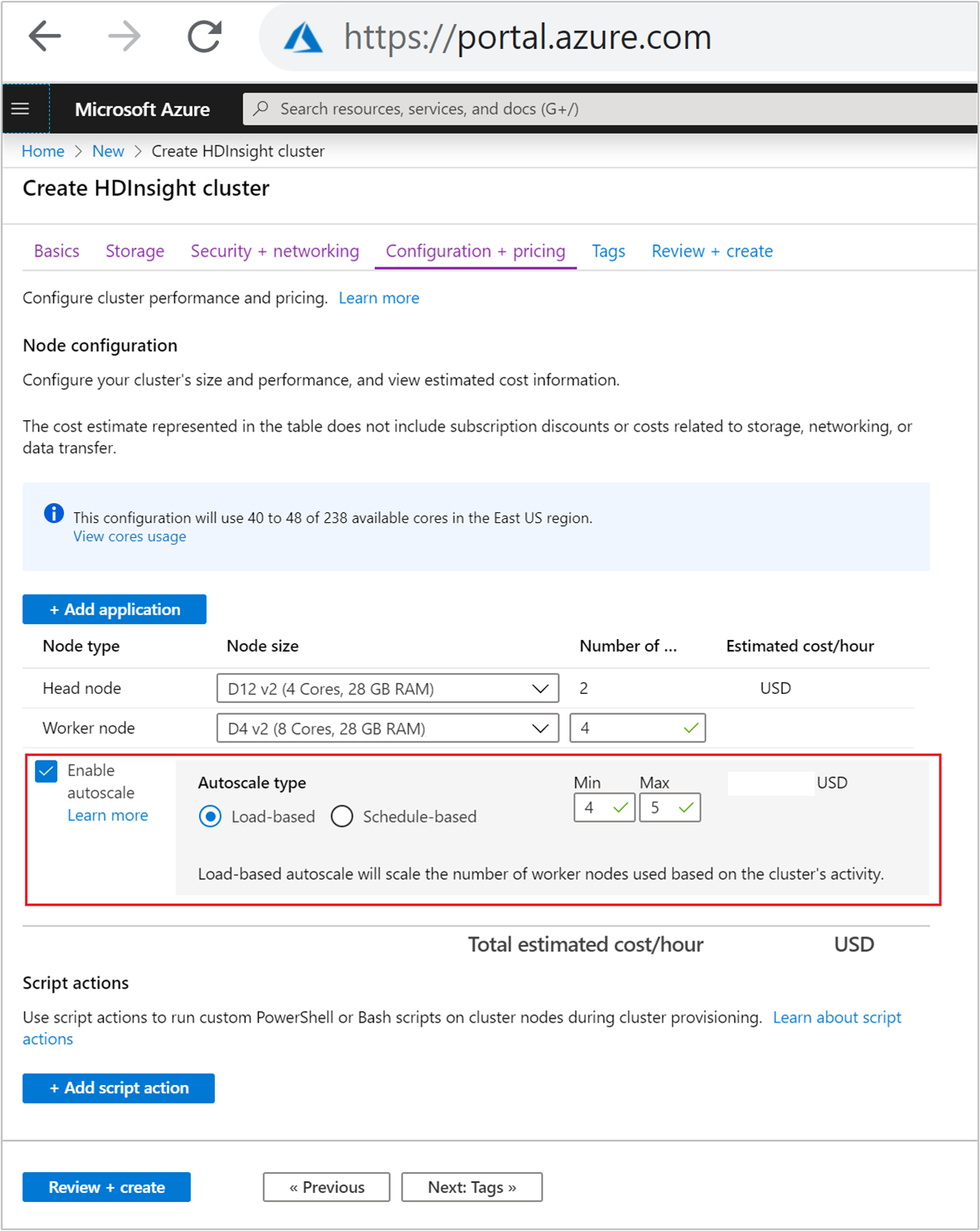
El número inicial de nodos de trabajo debe estar comprendido entre los valores mínimo y máximo, ambos inclusives. Este valor define el tamaño inicial del clúster durante su creación. El número mínimo de nodos de trabajo debe establecerse en tres o más. El escalado del clúster a menos de tres nodos puede hacer que se quede atascado en el modo seguro debido a una replicación de archivos insuficiente. Para obtener más información, consulte Bloqueo en modo seguro.
Creación de un clúster con Escalabilidad automática basada en programación
Para habilitar la característica Escalabilidad automática con escalado basado en programación, complete estos pasos como parte del proceso de creación de clúster normal:
En la pestaña Configuración y precios, active la casilla
Enable autoscale.Especifique el Número de nodos para Nodo de trabajo, que controla el límite para escalar verticalmente el clúster.
Seleccione la opción Schedule-based (Basada en programación) en Tipo de escalabilidad automática.
Seleccione Configurar para abrir la ventana Configuración de la escalabilidad automática.
Seleccione la zona horaria y haga clic en + Agregar condición.
Seleccione los días de la semana en que se deberá aplicar la condición nueva.
Edite la hora en que debería aplicarse la condición y el número de nodos a los que se debe escalar el clúster.
Si es necesario, agregue más condiciones.

El número de nodos debe estar entre 3 y el número máximo de nodos de trabajo especificado antes de agregar condiciones.
Pasos finales de creación
Seleccione el tipo de máquina virtual de los nodos de trabajo; para ello, seleccione una máquina virtual en la lista desplegable de Tamaño del nodo. Después de elegir el tipo de máquina virtual para cada tipo de nodo, puede ver el intervalo de costo estimado para todo el clúster. Ajuste los tipos de máquina virtual que se ajusten a su presupuesto.

La suscripción tiene una cuota de capacidad para cada región. El número total de núcleos de los nodos principales y el máximo de nodos de trabajo no puede superar la cuota de capacidad. Sin embargo, esta cuota tiene un límite flexible; sencillamente puede crear una incidencia de soporte técnico en cualquier momento para que la aumenten.
Nota
Si se supera el límite de cuota de núcleos total, recibirá un mensaje de error que dice "the maximum node exceeded the available cores in this region, please choose another region or contact the support to increase the quota" (El nodo máximo superó los núcleos disponibles en esta región, elija otra región o póngase en contacto con soporte técnico para aumentar la cuota).
Para obtener más información sobre la creación de clústeres de HDInsight con Azure Portal, consulte Crear clústeres basados en Linux en HDInsight con Azure Portal.
Creación de un clúster con una plantilla del Administrador de recursos
Escalado automático basado en carga
Para crear un clúster de HDInsight con el escalado automático basado en carga de una plantilla de Azure Resource Manager, agregue un nodo autoscale a la sección computeProfile>workernode con las propiedades minInstanceCount y maxInstanceCount, tal como se muestra en el fragmento de código JSON. Para obtener una plantilla de Resource Manager completa, consulte Plantilla de inicio rápido: Implementación de un clúster de Spark con la escalabilidad automática basada en carga habilitada.
{
"name": "workernode",
"targetInstanceCount": 4,
"autoscale": {
"capacity": {
"minInstanceCount": 3,
"maxInstanceCount": 10
}
},
"hardwareProfile": {
"vmSize": "Standard_D13_V2"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
},
"virtualNetworkProfile": null,
"scriptActions": []
}
Escalado automático basado en programación
Para crear un clúster de HDInsight con el escalado automático basado en programación de una plantilla de Azure Resource Manager, agregue un nodo autoscale a la sección computeProfile>workernode. El nodo autoscale contiene un recurrence que tiene un timezone y schedule que describe cuándo tiene lugar el cambio. Para obtener una plantilla de Resource Manager completa, consulte Implementación de un clúster de Spark con la escalabilidad automática basada en programación habilitada.
{
"autoscale": {
"recurrence": {
"timeZone": "Pacific Standard Time",
"schedule": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"timeAndCapacity": {
"time": "11:00",
"minInstanceCount": 10,
"maxInstanceCount": 10
}
}
]
}
},
"name": "workernode",
"targetInstanceCount": 4
}
Habilitación y deshabilitación de escalabilidad automática para un clúster en ejecución
Uso de Azure Portal
Para habilitar la escalabilidad automática en un clúster en ejecución, seleccione Tamaño del clúster en Configuración. Después, seleccione Enable autoscale. Seleccione el tipo de escalabilidad automática que quiere y especifique las opciones de escalado basado en carga o basado en programación. Por último, seleccione Guardar.

Uso de la API de REST
Para habilitar o deshabilitar la Escalabilidad automática en un clúster en ejecución mediante la API REST, realice una solicitud POST al punto de conexión de escalado automático:
https://management.azure.com/subscriptions/{subscription Id}/resourceGroups/{resourceGroup Name}/providers/Microsoft.HDInsight/clusters/{CLUSTERNAME}/roles/workernode/autoscale?api-version=2018-06-01-preview
Use los parámetros adecuados en la carga de solicitud. Se podría usar la siguiente carga json para enable Autoscale. Use la carga {autoscale: null} para deshabilitar el escalado automático.
{ "autoscale": { "capacity": { "minInstanceCount": 3, "maxInstanceCount": 5 } } }
Vea la sección anterior sobre cómo habilitar el escalado automático basado en la carga para obtener una descripción completa de todos los parámetros de carga. No se recomienda deshabilitar el servicio de escalabilidad automática de forma forzada en un clúster en ejecución.
Supervisión de actividades de escalabilidad automática
Estado del clúster
El estado del clúster que aparece en Azure Portal puede ayudarlo a supervisar las actividades de escalabilidad automática.

Todos los mensajes de estado del clúster que podría ver se explican en la lista siguiente.
| Estado del clúster | Descripción |
|---|---|
| En ejecución | El clúster funciona normalmente. Todas las actividades de Escalabilidad automática anteriores se completaron correctamente. |
| Actualizando | La configuración de Escalabilidad automática del clúster se está actualizando. |
| Configuración de HDInsight | Una operación de escalado o de reducción verticales de un clúster está en curso. |
| Error de actualización | HDInsight experimentó problemas durante la actualización de la configuración de Escalabilidad automática. Los clientes pueden elegir si reintentan la actualización o deshabilitan la escalabilidad automática. |
| Error | Error en el clúster, que no se puede usar. Elimine este clúster y cree uno nuevo. |
Para ver el número actual de nodos en el clúster, vaya al gráfico Tamaño del clúster en la página de información general del clúster. O bien, seleccione Tamaño del clúster en Configuración.
Historial de operaciones
Puede ver el historial de escalado y reducción verticales del clúster como parte de las métricas del clúster. También puede enumerar todas las acciones de escalado durante el último día, semana u otro período de tiempo.
Seleccione Métricas en Supervisión. Luego, seleccione en Agregar métrica y Número de trabajos activos en la lista desplegable Métrica. Seleccione el botón que se encuentra en la esquina superior derecha para cambiar el intervalo de tiempo.

procedimientos recomendados
Consideración de la latencia de las operaciones de escalado y reducción verticales
Toda una operación de escalabilidad puede tardar entre 10 y 20 minutos en completarse. Cuando configure una programación personalizada, planee esta demora. Por ejemplo, si necesita que el tamaño del clúster sea 20 a las 9:00 a. m., establezca el desencadenador de programación más temprano, a eso de las 8:30 a. m. o antes, para que la operación de escalado se complete antes de las 9:00 a. m.
Preparación para la reducción vertical
Durante el proceso de reducción vertical de un clúster, la característica Escalabilidad automática retira los nodos para cumplir con el tamaño de destino. En el escalado automático basado en cargas, si las tareas están en ejecución en esos nodos, la escalabilidad automática espera hasta que se completan las tareas para clústeres Spark y Hadoop. Como cada nodo de trabajo también tiene un rol en HDFS, los datos temporales se desplazan a los nodos de trabajo restantes. Asegúrese de que haya espacio suficiente en los nodos restantes para hospedar todos los datos temporales.
Nota:
En el caso de la reducción vertical automática basada en programaciones, no se admite la retirada correcta. Esto puede provocar errores de trabajo durante una operación de reducción vertical y se recomienda planear programaciones basadas en los patrones previstos de programación de trabajos para incluir tiempo suficiente para que los trabajos en curso finalicen. Para establecer las programaciones, observe la duración histórica de los tiempos de finalización para evitar errores en los trabajos.
Configuración de la escalabilidad automática basada en programación en función del patrón de uso
Debe comprender el patrón de uso del clúster al configurar la escalabilidad automática basada en programación. El panel de Grafana puede ayudarle a comprender las ranuras de carga y ejecución de consultas. Puede obtener las ranuras de ejecutor disponibles y el total de ranuras de ejecutor desde el panel.
Esta es una manera de calcular el número de nodos de trabajo necesarios. Se recomienda proporcionar otro 10 % de búfer para controlar la variación de la carga de trabajo.
Número de ranuras de ejecutor usadas = Total de ranuras de ejecutor – Total de ranuras de ejecutor disponibles.
Número de nodos de trabajo necesarios = número de ranuras ejecutoras usadas realmente / (hive.llap.daemon.num.executors + hive.llap.daemon.task.scheduler.wait.queue.size).
*hive.llap.daemon.num.executors es configurable y el valor predeterminado es 4.
*hive.llap.daemon.task.scheduler.wait.queue.size es configurable y el valor predeterminado es 10.
Acciones de script personalizadas
Las acciones de script personalizados se usan principalmente para personalizar los nodos (HeadNode/WorkerNodes) que permiten a nuestros clientes configurar determinadas bibliotecas y herramientas que las usan. Un caso de uso común es que los trabajos que se ejecutan en el clúster puedan tener algunas dependencias en la biblioteca de terceros que es propiedad del cliente, y debe estar disponible en los nodos para que el trabajo se ejecute correctamente. En el caso del escalado automático, actualmente se admiten acciones de scripts personalizados que se conservan, por lo que, cada vez que se agregan los nuevos nodos al clúster como parte de la operación de escalado vertical, se ejecutarían estas acciones de scripts persistentes, y publicarían que los contenedores o trabajos estarían asignados en ellas. Aunque las acciones de scripts personalizados ayudan a arrancar los nuevos nodos, es aconsejable que se mantengan al mínimo, ya que se sumaría a la latencia de escalado vertical general, lo que puede afectar a los trabajos programados.
Consideración del tamaño mínimo del clúster
No reduzca verticalmente el clúster a menos de tres nodos. El escalado del clúster a menos de tres nodos puede hacer que se quede atascado en el modo seguro debido a una replicación de archivos insuficiente. Para más información, vea Bloqueo en modo seguro.
Microsoft Entra Domain Services y operaciones de escalado
Si usa un clúster de HDInsight con Enterprise Security Package (ESP) unido a un dominio administrado de Microsoft Entra Domain Services, se recomienda limitar la carga en Microsoft Entra Domain Services. En la sincronización con ámbito de estructuras de directorio complejas, se recomienda evitar el impacto en las operaciones de escalado.
Establecimiento del número máximo de consultas simultáneas totales de configuración de Hive para el escenario de uso máximo
Los eventos de escalabilidad automática no cambian la configuración de Hive de Número máximo total de consultas simultáneas en Ambari. Esto significa que el servicio interactivo del servidor de Hive 2 solo puede controlar el número dado de consultas simultáneas en cualquier momento, incluso si el número de demonios de cola interactiva se escala y reduce verticalmente en función de la carga y programación. La recomendación general es establecer esta configuración para el escenario de uso máximo para evitar la intervención manual.
Sin embargo, es posible que experimente un error de reinicio del servidor de Hive 2 si solo hay unos pocos nodos de trabajo y el valor configurado del máximo de consultas simultáneas totales es demasiado alto. Como mínimo, necesita el número mínimo de nodos de trabajo que pueden acomodar el número determinado de Tez Ams (igual a la configuración del Máximo total de consultas simultáneas).
Limitaciones
Recuento de demonios de Interactive Query
En los clústeres de Interactive Query habilitados para la escalabilidad automática, el evento de escalar o reducir verticalmente también escala vertical u horizontalmente el número de demonios de Interactive Query al número de nodos de trabajo activos. El cambio en el número de demonios no se conserva en la configuración de num_llap_nodes en Ambari. Si los servicios de Hive se reinician manualmente, el número de demonios de Interactive Query se restablece según la configuración de Ambari.
Si el servicio Interactive Query se reinicia manualmente, es necesario cambiar manualmente la configuración num_llap_node (el número de nodos necesarios para ejecutar el demonio de Interactive Query de Hive) en Advanced hive-interactive-env para que coincida con el número actual de nodos de trabajo activos. El clúster de Interactive Query solo admite la escalabilidad automática basada en programación.
Pasos siguientes
Obtenga información sobre las directrices para escalar clústeres manualmente en Directrices de escalado.