Búsqueda de texto completo en Azure AI Search
La búsqueda de texto completo es un enfoque en la recuperación de información que coincide con el texto sin formato almacenado en un índice. Por ejemplo, dada una cadena de consulta «hoteles en San Diego en la playa», el motor de búsqueda busca cadenas tokenizadas basadas en esos términos. Para que los exámenes sean más eficaces, las cadenas de consulta se someten a un análisis léxico: minúsculas de todos los términos, quitando palabras irrelevantes como los artículos y reduciendo términos a formularios raíz primitivos. Cuando se encuentran términos coincidentes, el motor de búsqueda recupera documentos, los clasifica en orden de relevancia y devuelve los resultados principales.
La ejecución de consultas puede ser compleja. Este artículo es para desarrolladores que necesitan comprender mejor cómo funciona la búsqueda de texto completo en Azure AI Search. En el caso de las consultas de texto, Azure AI Search proporciona sin problemas resultados esperados en la mayoría de los escenarios, pero en ocasiones podría obtener un resultado que parece "desactivado" de alguna manera. En estas situaciones, tener un fondo en las cuatro fases de ejecución de consultas de Lucene (análisis de consultas, análisis léxico, coincidencia de documentos, puntuación) puede ayudarle a identificar cambios específicos en los parámetros de consulta o la configuración de índice que producen el resultado deseado.
Nota:
Azure AI Search usa Apache Lucene para la búsqueda de texto completo, pero la integración con Lucene no es completa. Exponemos y ampliamos selectivamente la funcionalidad de Lucene para habilitar escenarios importantes en Azure AI Search.
Introducción a la arquitectura y diagrama
La ejecución de la consulta tiene cuatro fases:
- Consulta de análisis
- Análisis léxico
- Recuperación de documentos
- Puntuaciones
Una consulta de búsqueda de texto completo comienza con el análisis del texto de la consulta para extraer los operadores y términos de búsqueda. Hay dos analizadores para que pueda elegir entre velocidad y complejidad. Una fase de análisis es la siguiente, donde los términos de consulta individuales a veces se dividen y se reconstituirán en nuevos formularios. Este paso ayuda a convertir una red más amplia sobre lo que podría considerarse una coincidencia potencial. A continuación, el motor de búsqueda examina el índice para buscar documentos con términos coincidentes y asigna una puntuación a cada coincidencia. Un conjunto de resultados se ordena mediante una puntuación de importancia asignada a cada documento de coincidencia. Los que se encuentran en la parte superior de la lista de clasificación se devuelven a la aplicación que realiza la llamada.
El diagrama siguiente muestra los componentes que se utilizan para procesar una solicitud de búsqueda.
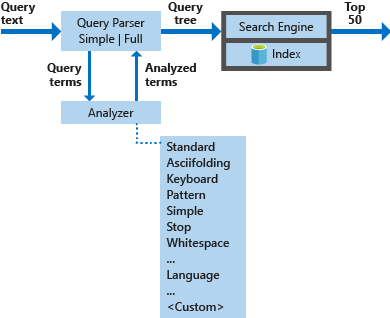
| Componentes claves | Descripción funcional |
|---|---|
| Analizadores de consulta | Separe los términos de consulta de los operadores de consulta y cree la estructura de consulta (un árbol de consulta) que enviar al motor de búsqueda. |
| Analizadores | Realice un análisis léxico sobre los términos de consulta. Este proceso puede implicar la transformación, eliminación o expansión de los términos de consulta. |
| Índice | Una estructura de datos eficiente usada para almacenar y organizar términos que pueden buscarse extraídos de documentos indexados. |
| Motor de búsqueda | Recupera y puntúa los documentos coincidentes en función del contenido del índice invertido. |
Anatomía de una solicitud de búsqueda
Una solicitud de búsqueda es una especificación completa de lo que se debe devolver en un conjunto de resultados. En su forma más simple, se trata de una consulta vacía sin criterios de ningún tipo. Un ejemplo más realista incluye parámetros, varios términos de consulta, quizás con un ámbito en algunos de los campos, con posiblemente una expresión de filtro y reglas de ordenación.
El siguiente ejemplo es una solicitud de búsqueda que puede enviar a Azure AI Search mediante la API de REST.
POST /indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
Para esta solicitud, el motor de búsqueda hace estas operaciones:
Busca los documentos cuyo precio sea al menos de 60 USD y menos de 300 USD.
Ejecuta la consulta. En este ejemplo, la consulta de búsqueda consta de frases y términos:
"Spacious, air-condition* +\"Ocean view\""(por lo general, los usuarios no especifican la puntuación, pero si la incluyen en el ejemplo, podemos explicar cómo la administran los analizadores).Para esta consulta, el motor de búsqueda examina los campos de descripción y título especificados en "searchFields" para los documentos que contienen
"Ocean view"y, además, en el término"spacious"o en términos que comienza con el prefijo"air-condition". El parámetro "searchMode" se usa para que coincida con cualquier término (valor predeterminado) o con todos ellos, para los casos en los que no se requiere explícitamente un término (+).Ordena el conjunto resultante de hoteles por proximidad a una ubicación geográfica determinada y, a continuación, devuelve los resultados a la aplicación que realiza la llamada.
La mayor parte de este artículo trata del procesamiento de la consulta de búsqueda: "Spacious, air-condition* +\"Ocean view\"". El filtrado y la ordenación están fuera del ámbito. Para más información, consulte la Documentación de referencia de API de búsqueda.
Fase 1: Consulta de análisis
Como se mencionó anteriormente, la cadena de consulta es la primera línea de la solicitud:
"search": "Spacious, air-condition* +\"Ocean view\"",
El analizador de consultas separa los operadores (como * y + en el ejemplo) de los términos de búsqueda y deconstruye la consulta de búsqueda en subconsultas de un tipo admitido:
- consulta de término para términos independiente (como "espacioso")
- consultas de frases de términos entre comillas (como "vistas al mar")
- consulta de prefijo de términos seguidos por un operador de prefijo
*(como "post-vacacional")
Para obtener una lista completa de los tipos de consultas admitidas, consulte Sintaxis de consulta de Lucene
Los operadores asociados a una subconsulta determinan si la cadena "tiene que" cumplirse o "debe" cumplirse para que un documento se considere una coincidencia. Por ejemplo, +"Ocean view" es obligatorio debido al operador +.
El analizador de consultas reestructura las subconsultas en un árbol de consulta (una estructura interna que representa la consulta) que pasa al motor de búsqueda. En la primera fase de análisis de la consulta, el árbol de consulta tiene el siguiente aspecto.

Analizadores admitidos: versión simple y completa de Lucene
Azure AI Search expone dos lenguajes de consulta diferentes, simple (valor predeterminado) y full. Si establece el parámetro queryType con su solicitud de búsqueda, indica al analizador de consultas qué lenguaje de consulta elegir de modo que sepa cómo interpretar los operadores y la sintaxis.
El lenguaje de consulta simple es intuitivo y sólido, y suele ser adecuado para interpretar la entrada del usuario como está, sin que sea necesario ningún procesamiento por parte del cliente. Admite los operadores de consulta familiares desde motores de búsqueda web.
El lenguaje de consulta completo de Lucene, que obtendrá estableciendo
queryType=full, amplía el lenguaje de consulta simple predeterminado mediante la adición de compatibilidad con más operadores y tipos de consulta como carácter comodín, coincidencias parciales, regex y consultas centrada en el campo. Por ejemplo, una expresión regular enviada con la sintaxis de consulta simple se interpretaría como una cadena de consulta y no una expresión. La solicitud de ejemplo de este artículo utiliza el lenguaje de consulta completo de Lucene.
Impacto de searchMode en el analizador
Otro parámetro de solicitud de búsqueda que afecta el análisis es el parámetro "searchMode". Controla el operador predeterminado para las consultas booleanas: cualquiera (valor predeterminado) o todos.
Cuando "searchMode=any", que es el valor predeterminado, el delimitador de espacio entre "espacioso" y "post-vacacional" es OR (||), lo que hace que el texto de consulta de ejemplo sea equivalente a:
Spacious,||air-condition*+"Ocean view"
Los operadores explícitos, como + en +"Ocean view", no son ambiguos en la construcción de la consulta booleana (el término debe coincidir). Es menos obvio cómo interpretar los términos restantes: "espacioso" y "post-vacacional". ¿El motor de búsqueda debería encontrar coincidencias en "vistas al mar" y "espacioso" y "post-vacacional"? ¿O debe encontrar "vistas al mar" además de alguno de los términos restantes?
De manera predeterminada ("searchMode=any"), el motor de búsqueda da por sentada la interpretación más amplia. El campo debe coincidir, reflejar la semántica "o". El árbol de consulta inicial mostrador anterior, con las dos operaciones "debe", muestra el valor predeterminado.
Imagine que ahora establecemos "searchMode=all". En este caso, el espacio se interpreta como una operación "y". Cada uno de los términos restantes debe estar presente en el documento para considerarse una coincidencia. La consulta de ejemplo resultante podría interpretarse del siguiente modo:
+Spacious,+air-condition*+"Ocean view"
Un árbol de consulta modificado para esta consulta el siguiente, donde un documento coincidente es la intersección de las tres subconsultas:

Nota:
Elegir "searchMode=any" sobre "searchMode=all" es la mejor decisión cuando se ejecutan consultas representativas. Los usuarios que suelen incluir operadores (algo común cuando se busca en almacenes de documentos) pueden encontrar resultados más intuitivos si "searchMode=all" informa de construcciones de consultas booleanas. Para más información sobre la interacción entre "searchMode" y los operadores, consulte Sintaxis de consulta simplificada.
Fase 2: Análisis léxico
Los analizadores léxicos procesan consultas de términos y consultas de frases después de que se estructure el árbol de consulta. Un analizador acepta las entradas de texto especificadas por el analizador, procesa el texto y, a continuación, vuelve a enviar términos acortados que incorporar al árbol de consulta.
La forma más común de análisis de léxico es el *análisis lingüístico que transforma los términos de consulta en función de reglas específicas para un idioma determinado:
- Reducción de un término de consulta a la forma de la raíz de una palabra
- Eliminación de palabras no esenciales (palabras irrelevantes, como "el" o "y")
- División de una palabra compuesta en partes
- Uso de minúsculas en una palabra con mayúsculas
Todas estas operaciones tienden a borrar las diferencias entre la entrada de texto proporcionada por el usuario y los términos almacenados en el índice. Estas operaciones van más allá del procesamiento de texto y requieren un conocimiento más profundo del propio idioma. Para agregar esta capa de reconocimiento lingüístico, Azure AI Search admite una larga de analizadores de idioma de Lucene y Microsoft.
Nota:
Los requisitos de análisis pueden ser mínimos para la elaboración en función de su escenario. Puede controlar la complejidad del análisis léxico seleccionando uno de los analizadores predefinidos o creando su propio analizador personalizado. Los analizadores se limitan a campos de búsqueda y se especifican como parte de una definición de campo. Esto le permite modificar el análisis léxico por campo. Si no se especifica, se utiliza el analizador estándar de Lucene.
En nuestro ejemplo, antes del análisis, el árbol de consulta inicial tiene el término "Espacioso," con una "E" mayúscula y una coma que el analizador de consultas interpreta como parte del término de consulta (la coma no se considera un operador de idioma de consulta).
Cuando el analizador predeterminado procesa el término, cambiará a minúscula "vistas al mar" y "espacioso" y quitará la coma. El árbol de consulta modificado tiene el siguiente aspecto:

Prueba de comportamientos del analizador
Se puede probar el comportamiento de un analizador mediante la Análisis de la API. Proporcione el texto que desea analizar para ver qué términos genera un analizador determinado. Por ejemplo, para ver cómo el analizador estándar procesaría el texto "post-vacacional", puede emitir la solicitud siguiente:
{
"text": "air-condition",
"analyzer": "standard"
}
El analizador estándar divide el texto de entrada en los siguientes dos tokens, anotándolos con atributos como desplazamientos de inicio y final (utilizados para resultados destacados), así como su posición (que se usa para la coincidencia de frase):
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
Excepciones para el análisis léxico
El análisis léxico se aplica únicamente a los tipos de consultas que requieren términos completos: una consulta de término o una consulta de frase. No se aplica a los tipos de consulta con términos incompletos: consulta de prefijo, consulta de carácter comodín, consulta regex o a una consulta de coincidencia parcial. Estos tipos de consulta, incluida la consulta de prefijo con el término air-condition* en nuestro ejemplo, se agregan directamente al árbol de consulta omitiendo la fase de análisis. La única transformación realizada en los términos de consulta de esos tipos es el establecimiento de minúsculas.
Fase 3: Recuperación de documentos
La recuperación de documentos hace referencia a la búsqueda de documentos con términos coincidentes en el índice. Esta fase se entiende mejor mediante un ejemplo. Puede empezar con un índice de hoteles que tengan el siguiente esquema simple:
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
Suponga también que este índice contiene los siguientes cuatro documentos:
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
Cómo se indexan los términos
Para entender la recuperación, es útil conocer algunos conceptos básicos acerca de la indexación. La unidad de almacenamiento es un índice invertido, uno para cada campo de búsqueda. Dentro de un índice invertido hay una lista ordenada de todos los términos de todos los documentos. Cada término se asigna a la lista de documentos en el que aparece, tal como aparece en el ejemplo siguiente.
Para generar los términos en un índice invertido, el motor de búsqueda realiza un análisis léxico del contenido de los documentos, de forma similar a lo que sucede durante el procesamiento de consultas:
- Las entradas de texto se pasan al analizador, en minúsculas, con una puntuación fragmentada y así sucesivamente, dependiendo de la configuración del analizador.
- Los tokens son las salidas del análisis léxico.
- Los términos se agregan al índice.
Es común, pero no necesario, usar los mismos analizadores para las operaciones de búsqueda e indexación para que los términos de consulta tengan un aspecto más parecido a los términos de dentro del índice.
Nota:
Azure AI Search le permite especificar diferentes analizadores para la indexación y búsqueda a través de parámetros de campo indexAnalyzer y searchAnalyzer adicionales. Si no se especifica, el analizador establecido con la propiedad analyzer se utiliza para la indexación y la búsqueda.
Índice invertido para documentos de ejemplo
Volviendo a nuestro ejemplo, para el campo título, el índice invertido tendría el siguiente aspecto:
| Término | Lista de documento |
|---|---|
| atman | 1 |
| playa | 2 |
| hotel | 1, 3 |
| océano | 4 |
| playa | 3 |
| resort | 3 |
| retirada | 4 |
En el campo de título, solo hotel aparece en dos documentos: 1 y 3.
Para el campo descripción, el índice es el siguiente:
| Término | Lista de documento |
|---|---|
| air | 3 |
| y | 4 |
| playa | 1 |
| vacacional | 3 |
| cómodo | 3 |
| distance | 1 |
| isla | 2 |
| kauai | 2 |
| ubicado | 2 |
| north | 2 |
| océano | 1, 2, 3 |
| de | 2 |
| en | 2 |
| silencioso | 4 |
| habitaciones | 1, 3 |
| aislado | 4 |
| costa | 2 |
| espacioso | 1 |
| el | 1, 2 |
| to | 1 |
| view | 1, 2, 3 |
| paseo | 1 |
| con | 3 |
Coincidencia de términos de consulta con términos indexados
Dados los índices invertidos anteriores, volvamos a la consulta de ejemplo y veamos cómo se encuentran los documentos coincidentes para nuestra consulta de ejemplo. Recuerde que el árbol de consulta final tendrá el siguiente aspecto:
Durante la ejecución de la consulta, las consultas individuales se ejecutan en los campos de búsqueda por separado.
La consulta de término "espacioso" coincide con el documento 1 (Hotel Atman).
La consulta de prefijo "post-vacacional*" no coincide con ningún documento.
Este es el comportamiento que normalmente confunde a los desarrolladores. Aunque el término "post-vacacional" existe en el documento, el analizador predeterminado lo divide en dos términos. Recuerde que las consultas de prefijo, que contienen términos parciales, no se analizan. Por lo tanto, los términos con el prefijo "post-vacacional" se buscan en el índice invertido y no se encuentran.
La consulta de frase "vistas al mar", busca los términos "mar" y "vistas" y comprueba la proximidad de términos en el documento original. Los documentos 1, 2 y 3 coinciden con esta consulta en el campo de descripción. Tenga en cuenta que el documento 4 tiene el término "mar" en el título, pero no se considera una coincidencia ya que estamos buscando la frase "vistas al mar" y no palabras individuales.
Nota:
Se ejecuta una consulta de búsqueda de forma independiente en todos los campos de búsqueda en el índice de Azure AI Search a no ser que limite los campos establecidos con el parámetro searchFields, como se muestra en la solicitud de búsqueda de ejemplo. Se devuelven documentos que coinciden con cualquiera de los campos seleccionados.
En general, para la consulta en cuestión, los documentos que coinciden son 1, 2 y 3.
Fase 4: Puntuación
A todos los documentos de un conjunto de resultados de búsqueda se les asigna una puntuación de relevancia. La función de la puntuación de relevancia es rango superior en aquellos documentos que responden mejor a una pregunta de usuario según lo expresado por la consulta de búsqueda. La puntuación se calcula en función de propiedades estadísticas de términos que coinciden. La base de la fórmula de puntuación es TF/IDF (frecuencia del documento de frecuencia inversa del término). En las consultas que contienen términos comunes y poco frecuentes, TF/IDF favorece a los resultados que contienen el término poco frecuente. Por ejemplo, en un índice hipotético con todos los artículos de Wikipedia, de documentos que coincidían con la consulta el presidente, los documentos que coinciden con presidente se consideran más importantes que los documentos que coinciden con el.
Ejemplo de puntuación
Recuerde los tres documentos que coinciden con la consulta de ejemplo:
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
El documento 1 coincidió con la mejor consulta porque tanto el término espacioso y la frase necesaria vistas al mar aparecen en el campo de descripción. Los siguientes dos documentos coinciden solo con la frase vistas al mar. Podría ser sorprendente que la puntuación por relevancia para el documento 2 y 3 fuera diferente, aunque coincide con la consulta de la misma manera. Se debe a que la fórmula de puntuación tiene más componentes que simplemente TF/IDF. En este caso, al documento 3 se le asignó una puntuación ligeramente superior porque su descripción es más corta. Obtenga información sobre Fórmula de puntuación práctica de Lucene para entender cómo longitud de campo y otros factores pueden influir en la puntuación por relevancia.
Algunos tipos de consulta (comodín, prefijo y regex) siempre aportan una puntuación constante a la puntuación total del documento. Esto permite la inclusión de las coincidencias encontradas a través de la expansión de consultas en los resultados, pero sin que ello afecte a la clasificación.
El ejemplo muestra por qué esto es importante. Las búsquedas con caracteres comodín, incluidas las búsquedas de prefijo, son ambiguas por definición, dado que la entrada es una cadena parcial con coincidencias posibles en un gran número de términos dispares (tenga en cuenta una entrada de "tour*", con las coincidencias encontradas en "tours", "tourettes" y "touroperador"). Dada la naturaleza de estos resultados, no hay ninguna manera razonable de deducir qué términos son más valiosos que los demás. Por este motivo, se omiten las frecuencias de término cuando realiza la puntuación de resultados en consultas de tipo caracteres comodín, prefijo y regex. En una solicitud de búsqueda de varias partes que incluye términos parciales y totales, se incorporan los resultados de la entrada parcial con una puntuación constante para evitar un sesgo hacia coincidencias potencialmente inesperadas.
Ajuste de relevancia
Existen dos maneras de optimizar las puntuaciones de relevancia en Azure AI Search:
Los perfiles de puntuación favorecen a los documentos de la lista de clasificación basados en un conjunto de reglas. En nuestro ejemplo, podemos considerar los documentos que coincidieron en el campo de título más importantes que los documentos que coincidieron en el campo de descripción. Además, si el índice tenía un campo de precio para cada hotel, podríamos favorecer a los documentos con un precio menor. Obtenga información sobre cómo agregar perfiles de puntuación a un índice de búsqueda.
Priorización de términos (disponible solo en la sintaxis de consulta completa Lucene) proporciona un operador de priorización
^que puede aplicarse a cualquier parte del árbol de consulta. En nuestro ejemplo, en lugar de buscar en el prefijo air-condition*, puede buscar el término exacto post-vacacional o el prefijo, pero los documentos que coinciden con el término exacto se clasifican en una posición superior aplicando la priorización a la consulta de término: post-vacacional^2||post-vacacional*. Más información sobre la priorización de términos de una consulta.
Puntuación en un índice distribuido
Todos los índices de Azure AI Search se dividen automáticamente en varias particiones, lo que nos permite distribuir rápidamente el índice en varios nodos durante el escalado vertical o la reducción vertical del servicio. Cuando se emite una solicitud de búsqueda, se emite de forma independiente en cada partición. Los resultados de cada partición se combinan y se ordenan por puntuación (si no se ha definido ningún otro orden). Es importante saber que la función de puntuación mide la frecuencia del término de consulta con la frecuencia inversa del documento en todos los documentos dentro de la partición, no en todas las particiones.
Esto significa que una puntuación por relevancia puede ser diferente para los documentos idénticos si residen en diferentes particiones. Afortunadamente, estas diferencias tienden a desaparecer a medida que aumenta el número de documentos en el índice debido a una mejor distribución de los términos. No es posible suponer en qué partición se colocará un documento determinado. Sin embargo, suponiendo que la clave de documento no cambie, siempre se asignará a la misma partición.
En general, la puntuación del documento no es el mejor atributo para ordenar los documentos si la estabilidad del orden es importante. Por ejemplo, en dos documentos con una puntuación idéntica, no existe ninguna garantía sobre cuál aparecerá en primer lugar en las ejecuciones posteriores de la misma consulta. La puntuación del documento solo debe proporcionar una idea general de la relevancia del documento con respecto a otros documentos en el conjunto de resultados.
Conclusión
El éxito de los motores de búsqueda comerciales ha generado expectativas respecto de la búsqueda de texto completo sobre datos privados. Para casi cualquier tipo de experiencia de búsqueda, esperamos que el motor comprenda nuestra intención, incluso cuando los términos son incorrectos o están incompletos. Esperamos incluso coincidencias basadas en términos casi equivalentes o sinónimos que nunca hemos especificado.
Desde un punto de vista técnico, la búsqueda de texto completo es muy compleja, lo que requiere un análisis lingüístico sofisticado y un enfoque sistemático para el procesamiento de forma que sintetice, expanda y transforme términos de consulta para proporcionar un resultado relevante. Dada la complejidad inherente, existen muchos factores que pueden afectar el resultado de una consulta. Por esta razón, dedique tiempo a comprender las ventajas concretas que ofrece la mecánica de la búsqueda de texto completo cuando intenta trabajar con resultados inesperados.
En este artículo se ha analizado la búsqueda de texto completo en el contexto de Azure AI Search. Esperamos haberle proporcionado información suficiente como para reconocer las posibles causas y soluciones para resolver problemas de consultas comunes.
Pasos siguientes
Generar el índice de ejemplo, probar distintas consultas y revisar los resultados. Para obtener instrucciones, vea Creación y consulta de un índice en el portal.
Probar otra sintaxis de consulta de la sección de ejemploBuscar en documentos o en Sintaxis de consulta simple en el Explorador de búsqueda del portal.
Revisar los perfiles de puntuación si desea ajustar la clasificación en la aplicación de búsqueda.
Obtener información sobre cómo aplicar analizadores léxicos específicos del idioma.
Configurar los analizadores personalizados para un procesamiento mínimo o especializado en campos específicos.
Consulte también
API de REST de documentos de búsqueda
Sintaxis de consulta simplificada