Partición de Reliable Services de Service Fabric
Este artículo proporciona una introducción a los conceptos básicos de la creación de particiones en Reliable Services de Azure Service Fabric. La creación de particiones permite el almacenamiento de datos en las máquinas locales de forma que los datos y el proceso pueden escalarse juntos.
Sugerencia
Un ejemplo completo del código de este artículo está disponible en GitHub.
Creación de particiones
La creación de particiones no es exclusiva de Service Fabric. De hecho, es una función básica de la compilación de servicios escalables. En un sentido amplio, podemos considerar la creación de particiones como un estado de división (datos) y procesamiento en unidades accesibles más pequeñas para mejorar el rendimiento y escalabilidad. Una forma conocida de partición es la partición de datos también conocida como particionamiento.
Partición de los servicios sin estado de Service Fabric
Para los servicios sin estado, puede pensar en una partición como en una unidad lógica que contiene una o varias instancias de un servicio. La ilustración 1 muestra un servicio sin estado con cinco instancias distribuidas en un clúster con una partición.

En realidad hay dos tipos de soluciones de servicios sin estado. La primera corresponde a un servicio que conserva su estado de forma externa, por ejemplo en una base de datos en Azure SQL Database (como un sitio web que almacena la información de sesión y los datos). La segunda corresponde a servicios solo de procesamiento (como una calculadora o un generador de imágenes en miniatura) que no administran ningún estado persistente.
En cualquier caso, la partición de un servicio sin estado es un escenarios muy poco frecuente en el que la escalabilidad y la disponibilidad normalmente se consiguen agregando más instancias. Las únicas ocasiones en las que posiblemente quiera plantearse varias particiones para las instancias de servicios sin estado es cuando tenga que satisfacer solicitudes de enrutamiento especiales.
Por ejemplo, piense en un caso en el que los usuarios con identificadores dentro de un intervalo específico deberán ser atendidos únicamente por una instancia de servicio determinada. Otro ejemplo de cuándo se puede particionar un servicio sin estado es cuando tiene un back-end con particiones, por ejemplo, una base de datos particionada en SQL Database, y desea controlar qué instancia del servicio debe escribir en la partición de la base de datos o realizar otro trabajo de preparación en el servicio sin estado que requiera la misma información de partición que se usa en el back-end. Estos tipos de escenarios también se pueden resolver de maneras diferentes y no requieren necesariamente el particionamiento del servicio.
El resto de este tutorial se centra en los servicios con estado.
Partición de los servicios con estado de Service Fabric
Service Fabric ofrece una manera idónea para particionar el estado (datos) y facilitar el desarrollo de servicios con estado escalables. Conceptualmente, puede pensar en una partición de un servicio con estado como una unidad de escalado muy confiable gracias a las réplicas que se distribuyen y se equilibran entre los nodos en un clúster.
En el contexto de los servicios con estado de Service Fabric, la creación de particiones es el proceso de determinar que una partición de servicio específica es responsable de una parte de todo el estado del servicio. (Como se mencionó anteriormente, una partición es un conjunto de réplicas). Una gran ventaja de Service Fabric es que coloca las particiones en nodos diferentes. Esto les permite crecer hasta el límite de recursos del nodo. A medida que los datos crecen, las particiones también crecen y Service Fabric vuelve a equilibrar las particiones entre los nodos. Esto garantiza el uso continuado y eficaz de los recursos de hardware.
Como ejemplo, digamos que comienza con un clúster de 5 nodos y un servicio configurado para tener 10 particiones y un destino de tres réplicas. En este caso, Service Fabric equilibrará y distribuirá las réplicas en el clúster y acabara con dos réplicas principales por nodo. Si necesita escalar horizontalmente el clúster a 10 nodos, Service Fabric volverá a equilibrar las réplicas principales en los 10 nodos. Del mismo modo, si vuelve a 5 nodos, Service Fabric volverá a equilibrar todas las réplicas en los 5 nodos.
La ilustración 2 muestra la distribución de 10 particiones antes y después de escalar el clúster.

Como resultado, se logra el escalado horizontal ya que las solicitudes de los clientes se distribuyen entre los equipos, mejora el rendimiento general de la aplicación y se reduce la contención en el acceso a los fragmentos de datos.
Plan para la creación de particiones
Antes de implementar un servicio, debe considerar siempre la estrategia de particiones que se necesita para el escalado horizontal. Hay diferentes maneras, pero todas ellas se centran en lo que la aplicación necesita lograr. Veamos algunos de los aspectos más importantes dentro del contexto de este artículo.
Un buen método es pensar primero en la estructura del estado que es necesario particionar.
Veamos un sencillo ejemplo. Si tuviera que crear un servicio para un sondeo de ámbito regional, puede crear una partición para cada ciudad de la región. A continuación, puede almacenar los votos de cada persona de la ciudad en la partición correspondiente a esa ciudad. La ilustración 3 muestra un conjunto de usuarios y la ciudad en la que residen.
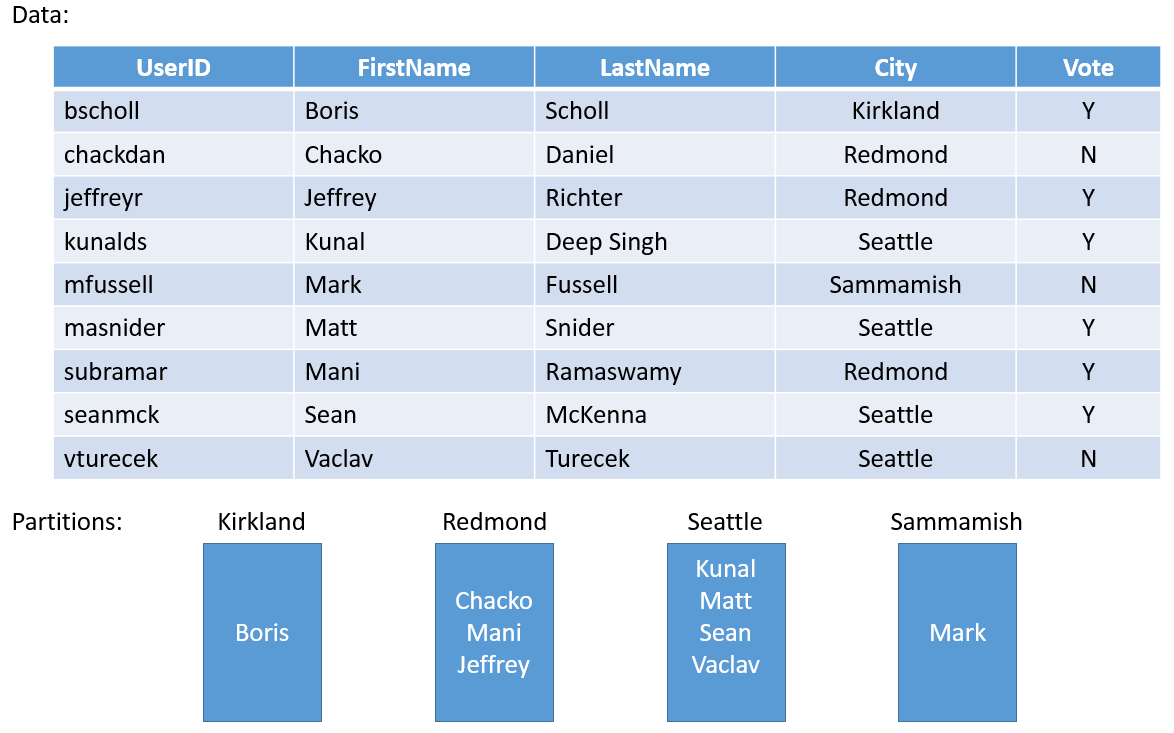
Como la población de las ciudades varía mucho, puede terminar con algunas particiones que contienen grandes cantidades de datos (por ejemplo, Seattle) y otras particiones con muy poco estado (por ejemplo, Kirkland). ¿En qué afecta tener particiones con cantidades de estado desiguales?
Si vuelve a pensar en el ejemplo, verá fácilmente que la partición que contiene los votos de Seattle tendrá más tráfico que la de Kirkland. De forma predeterminada, Service Fabric se asegura de que hay aproximadamente el mismo número de réplicas principales y secundarias en cada nodo. Por lo que puede encontrarse con nodos que contienen réplicas que atienden más tráfico y otros que atienden de menos tráfico. Es preferible evitar puntos con tráfico intenso y puntos con apenas tráfico como estos en un clúster.
Para ello, debe hacer dos cosas desde el punto de vista de la creación de particiones:
- Pruebe a particionar el estado para que se distribuya uniformemente en todas las particiones.
- Notifique la carga de cada una de las réplicas del servicio. (Para más información al respecto, consulte este artículo sobre métricas y carga). Service Fabric ofrece la posibilidad de notificar la carga consumida por los servicios, como la cantidad de memoria o el número de registros. En base a las métricas notificadas, Service Fabric detecta que algunas particiones atienden cargas mayores que otras y vuelve a equilibrar el clúster moviendo las réplicas a nodos más adecuados, de modo que en general ningún nodo resulta sobrecargado.
A veces, no es posible saber la cantidad de datos que habrá en una partición determinada. Por ello se recomienda realizar ambas acciones: primero adoptar una estrategia para distribuir los datos uniformemente entre las particiones y, después, crear informes de la carga. El primer método evita situaciones como las descritas en el ejemplo de la votación, mientras que el segundo ayuda a suavizar las diferencias temporales en el acceso o la carga con el tiempo.
Otro aspecto de la planeación de las particiones es elegir el número correcto de particiones para comenzar. Desde la perspectiva de Service Fabric, nada le impide comenzar con un número de particiones mayor del previsto para su escenario. De hecho, adoptar el número máximo de particiones es un enfoque válido.
En raras ocasiones puede acabar necesitando más particiones que las elegidas inicialmente. En estos casos, como no se puede cambiar el número de particiones después, tendría que aplicar algunos métodos de partición avanzados, como crear una nueva instancia de servicio del mismo tipo de servicio. También tendrá que implementar alguna lógica del lado cliente que enruta las solicitudes a la instancia de servicio correcta, en base al conocimiento del cliente que debe mantener el código de cliente.
Otra consideración a la hora de planear las particiones es cuáles son los recursos disponibles en el equipo. Como es necesario almacenar el estado y acceder a él, depende de lo siguiente:
- Límites del ancho de banda de red
- Límites de la memoria del sistema
- Límites del almacenamiento en disco
Entonces, ¿qué ocurre si se producen restricciones de recursos en un clúster en ejecución? La respuesta es que solo tiene que escalar horizontalmente el clúster para dar cabida a los nuevos requisitos.
La guía de planeación de la capacidad ofrece orientación para determinar cuántos nodos necesita su clúster.
Introducción a la creación de particiones
En esta sección se describe cómo empezar a particionar el servicio.
En primer lugar, Service Fabric ofrece tres esquemas de partición posibles:
- Particiones de intervalo (también conocidas como UniformInt64Partition)
- Particiones con nombre. Las aplicaciones que usan este modelo suelen tener datos que se pueden incluir en cubos, dentro de un conjunto enlazado. Algunos ejemplos habituales de campos de datos que se usan como claves de partición con nombre son regiones, códigos postales, grupos de clientes u otros límites empresariales.
- Particiones de singleton. Las particiones de singleton se usan normalmente cuando el servicio no requiere ningún enrutamiento adicional. Por ejemplo, los servicios sin estado usan este esquema de partición de forma predeterminada.
Los esquemas de particiones con nombre y de singleton son formas especiales de particiones de intervalos. De forma predeterminada, las plantillas de Visual Studio para Service Fabric usan las particiones de intervalo, ya que es el esquema más habitual y útil. El resto de este artículo se centra en el esquema de particiones de intervalo.
Esquema de particiones de intervalo
Se usa para especificar un intervalo de enteros (identificado por una clave baja y otra alta) y un número de particiones (n). Crea n particiones, cada una de ellas responsable de un subintervalo no superpuesto del intervalo de claves de partición general. Por ejemplo: un esquema de partición de intervalo con una clave baja 0, una clave alta de 99 y un recuento de 4 crearía 4 particiones, tal y como se muestra a continuación.

Un enfoque habitual es crear un hash basado en una clave única dentro del conjunto de datos. Algunos ejemplos comunes de claves son un número de identificación de vehículo (VIN), identificación de empleado o una cadena única. Con esa clave única, se genera un código hash, módulo del intervalo de claves, para usarlo como clave. Puede especificar los límites superior e inferior del intervalo de claves permitido.
Selección de un algoritmo hash
Una parte importante de los algoritmos hash es seleccionar su algoritmo hash. Una cuestión que se debe tener en cuenta es si el objetivo es agrupar claves similares próximas entre sí (algoritmos hash sensibles a la ubicación) o si la actividad se debería distribuir ampliamente entre todas las particiones (algoritmos hash de distribución), que suele ser lo más común.
Las características de un buen algoritmo hash de distribución son que sea fácil de calcular, que tenga pocas colisiones y que distribuya las claves uniformemente. Un buen ejemplo de un algoritmo hash eficaz es el algoritmo hash FNV-1 .
Un buen recurso para las opciones de algoritmo de código hash generales es la página de Wikipedia sobre las funciones hash.
Creación de un servicio con estado con varias particiones
Vamos a crear su primer servicio con estado confiable con varias particiones. En este ejemplo, creará una aplicación muy sencilla para almacenar todos los apellidos que comienzan con la misma letra en la misma partición.
Antes de escribir ningún código, tiene que pensar en las particiones y en las claves de partición. Necesita 26 particiones, una para cada letra del alfabeto, pero ¿qué hay de las claves inferiores y superiores? Puesto que literalmente queremos tener una partición por cada letra, podemos usar 0 como clave inferior y 25 como clave superior porque cada letra es su propia clave.
Nota:
Este es un escenario simplificado porque, en realidad, la distribución sería desigual. Los apellidos que comienzan por las letras S o M son más comunes que los que comienzan por X o Y.
Abra Visual Studio>Archivo>Nuevo>Proyecto.
En el cuadro de diálogo Nuevo proyecto , elija la aplicación de Service Fabric.
Llame al proyecto AlphabetPartitions.
En el cuadro de diálogo Crear un servicio, elija el servicio Con estado y llámelo Alphabet.Processing.
Establezca el número de particiones. Abra el archivo ApplicationManifest.xml de la carpeta ApplicationPackageRoot del proyecto AlphabetPartitions y actualice el parámetro Processing_PartitionCount con el valor 26, tal y como se muestra a continuación.
<Parameter Name="Processing_PartitionCount" DefaultValue="26" />También tendrá que actualizar las propiedades LowKey y HighKey del elemento StatefulService del archivo ApplicationManifest.xml tal y como se muestra a continuación.
<Service Name="Alphabet.Processing"> <StatefulService ServiceTypeName="Alphabet.ProcessingType" TargetReplicaSetSize="[Processing_TargetReplicaSetSize]" MinReplicaSetSize="[Processing_MinReplicaSetSize]"> <UniformInt64Partition PartitionCount="[Processing_PartitionCount]" LowKey="0" HighKey="25" /> </StatefulService> </Service>Para que el servicio sea accesible, abra un punto de conexión en un puerto agregando el elemento punto de conexión de ServiceManifest.xml (que se encuentra en la carpeta PackageRoot) para el servicio Alphabet.Processing, tal y como se muestra a continuación:
<Endpoint Name="ProcessingServiceEndpoint" Port="8089" Protocol="http" Type="Internal" />Ahora, el servicio está configurado para escuchar a un punto de conexión interno con 26 particiones.
A continuación, tiene que invalidar el método
CreateServiceReplicaListeners()de la clase Processing.Nota:
Para este ejemplo, asumimos que está usando un HttpCommunicationListener simple. Para más información sobre la comunicación de Reliable Service, consulte Modelo de comunicación de Reliable Service.
Un patrón recomendado para la dirección URL que escucha una réplica es el siguiente formato:
{scheme}://{nodeIp}:{port}/{partitionid}/{replicaid}/{guid}. Por ello deberá configurar el agente de escucha de comunicación para escuchar en los puntos de conexión correctos y con este patrón.Se pueden hospedar varias réplicas de este servicio en el mismo equipo, por lo que esta dirección debe ser única para la réplica. Por este motivo el identificador de la partición y el identificador de la réplica están incluidos en la dirección URL. HttpListener puede escuchar varias direcciones en el mismo puerto siempre que el prefijo de dirección URL sea único.
El GUID adicional es para casos avanzados en los que las réplicas secundarias también escuchan solicitudes de solo lectura. En este caso, querrá asegurarse de que se usa una dirección única nueva al realizar la transición de principal a secundario para obligar a los clientes a volver a resolver la dirección. "+" se usa como dirección aquí de forma que la réplica escucha en todos los hosts disponibles (IP, FQDN, localhost, etc.). El código siguiente muestra un ejemplo.
protected override IEnumerable<ServiceReplicaListener> CreateServiceReplicaListeners() { return new[] { new ServiceReplicaListener(context => this.CreateInternalListener(context))}; } private ICommunicationListener CreateInternalListener(ServiceContext context) { EndpointResourceDescription internalEndpoint = context.CodePackageActivationContext.GetEndpoint("ProcessingServiceEndpoint"); string uriPrefix = String.Format( "{0}://+:{1}/{2}/{3}-{4}/", internalEndpoint.Protocol, internalEndpoint.Port, context.PartitionId, context.ReplicaOrInstanceId, Guid.NewGuid()); string nodeIP = FabricRuntime.GetNodeContext().IPAddressOrFQDN; string uriPublished = uriPrefix.Replace("+", nodeIP); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInternalRequest); }También merece la pena tener en cuenta que la dirección URL publicada es ligeramente diferente del prefijo de URL de escucha. La dirección URL de escucha se envía a HttpListener. La dirección URL publicada es la dirección URL que se publica en el servicio de nombres de Service Fabric, que se usa para la detección de servicios. Los clientes preguntarán por esta dirección mediante ese servicio de detección. La dirección en la que los clientes obtienen tiene que tener la dirección IP o FQDN real del nodo para poder conectar. Por lo que necesitará reemplazar '+' por la IP o el FQDN del nodo, como se mostró anteriormente.
El último paso es agregar la lógica de procesamiento al servicio, tal y como se muestra a continuación.
private async Task ProcessInternalRequest(HttpListenerContext context, CancellationToken cancelRequest) { string output = null; string user = context.Request.QueryString["lastname"].ToString(); try { output = await this.AddUserAsync(user); } catch (Exception ex) { output = ex.Message; } using (HttpListenerResponse response = context.Response) { if (output != null) { byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } } private async Task<string> AddUserAsync(string user) { IReliableDictionary<String, String> dictionary = await this.StateManager.GetOrAddAsync<IReliableDictionary<String, String>>("dictionary"); using (ITransaction tx = this.StateManager.CreateTransaction()) { bool addResult = await dictionary.TryAddAsync(tx, user.ToUpperInvariant(), user); await tx.CommitAsync(); return String.Format( "User {0} {1}", user, addResult ? "successfully added" : "already exists"); } }ProcessInternalRequestlee los valores del parámetro de cadena de consulta usado para llamar a la partición y llama aAddUserAsyncpara agregar el apellido al diccionario confiabledictionary.Vamos a agregar un servicio sin estado al proyecto para ver cómo se puede llamar a una partición determinada.
Este servicio actúa como una interfaz web simple que acepta el apellido como parámetro de cadena de consulta, determina la clave de partición y la envía al servicio Alphabet.Processing para su procesamiento.
En el cuadro de diálogo Crear un servicio, elija el servicio Sin estado y llámelo Alphabet.Web, tal y como se muestra en la imagen siguiente.
 .
.Actualice la información del punto de conexión en el archivo ServiceManifest.xml del servicio Alphabet.WebApi para abrir un puerto, tal como se muestra a continuación.
<Endpoint Name="WebApiServiceEndpoint" Protocol="http" Port="8081"/>Debe devolver una colección de ServiceInstanceListeners en la clase Web. De nuevo, puede elegir implementar un HttpCommunicationListener simple.
protected override IEnumerable<ServiceInstanceListener> CreateServiceInstanceListeners() { return new[] {new ServiceInstanceListener(context => this.CreateInputListener(context))}; } private ICommunicationListener CreateInputListener(ServiceContext context) { // Service instance's URL is the node's IP & desired port EndpointResourceDescription inputEndpoint = context.CodePackageActivationContext.GetEndpoint("WebApiServiceEndpoint") string uriPrefix = String.Format("{0}://+:{1}/alphabetpartitions/", inputEndpoint.Protocol, inputEndpoint.Port); var uriPublished = uriPrefix.Replace("+", FabricRuntime.GetNodeContext().IPAddressOrFQDN); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInputRequest); }Ahora debe implementar la lógica de procesamiento. HttpCommunicationListener llama a
ProcessInputRequestcuando llega una solicitud. Vamos a seguir y agregar el código siguienteprivate async Task ProcessInputRequest(HttpListenerContext context, CancellationToken cancelRequest) { String output = null; try { string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A'); ResolvedServicePartition partition = await this.servicePartitionResolver.ResolveAsync(alphabetServiceUri, partitionKey, cancelRequest); ResolvedServiceEndpoint ep = partition.GetEndpoint(); JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri); output = String.Format( "Result: {0}. <p>Partition key: '{1}' generated from the first letter '{2}' of input value '{3}'. <br>Processing service partition ID: {4}. <br>Processing service replica address: {5}", result, partitionKey, firstLetterOfLastName, lastname, partition.Info.Id, primaryReplicaAddress); } catch (Exception ex) { output = ex.Message; } using (var response = context.Response) { if (output != null) { output = output + "added to Partition: " + primaryReplicaAddress; byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } }Le guiaremos paso a paso. El código lee la primera letra del parámetro de la cadena de consulta
lastnameen un carácter. Después determina la clave de partición de esta letra al restar el valor hexadecimal deAdel valor hexadecimal de la primera letra de los apellidos.string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A');Recuerde que, en este ejemplo, usamos 26 particiones con una clave de partición por partición. A continuación, obtenemos la partición de servicio
partitionpara esta clave usando el métodoResolveAsyncen el objetoservicePartitionResolver.servicePartitionResolverse define comoprivate readonly ServicePartitionResolver servicePartitionResolver = ServicePartitionResolver.GetDefault();El método
ResolveAsynctoma el URI del servicio, la clave de partición y un token de cancelación como parámetros. El servicio de URI para el servicio de procesamiento esfabric:/AlphabetPartitions/Processing. A continuación, obtenemos el punto de conexión de la partición.ResolvedServiceEndpoint ep = partition.GetEndpoint()Por último, compilamos la dirección URL del punto de conexión además de la cadena de consulta, y llamamos al servicio de procesamiento.
JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri);Después de realizar el procesamiento, escribimos la salida.
El último paso es probar el servicio. Visual Studio usa parámetros de aplicación para la implementación local y de nube. Para probar localmente el servicio con 26 particiones, tiene que actualizar el archivo
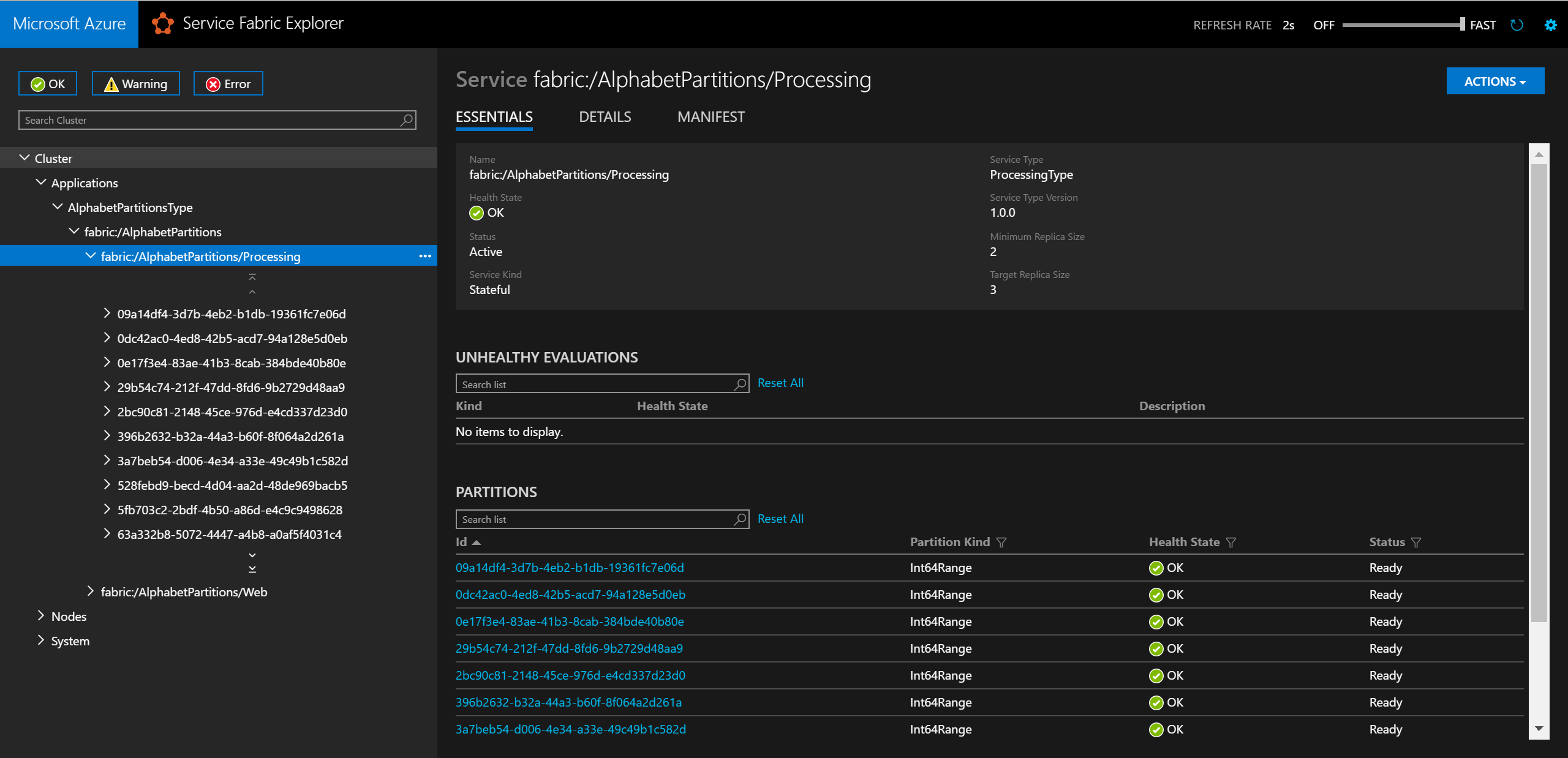
Local.xmlen la carpeta ApplicationParameters del proyecto AlphabetPartitions, tal y como se muestra a continuación:<Parameters> <Parameter Name="Processing_PartitionCount" Value="26" /> <Parameter Name="WebApi_InstanceCount" Value="1" /> </Parameters>Cuando haya terminado la implementación, puede comprobar el servicio y todas sus particiones en el Explorador de Service Fabric.
En un explorador, escriba
http://localhost:8081/?lastname=somenameprobar la lógica de partición. Verá que todos los apellidos que empiezan por la misma letra se almacenan en la misma partición.
La solución completa del código que se usa en este artículo está disponible aquí: https://github.com/Azure-Samples/service-fabric-dotnet-getting-started/tree/classic/Services/AlphabetPartitions.
Pasos siguientes
Más información sobre los servicios de Service Fabric: