Oharra
Baimena behar duzu orria atzitzeko. Direktorioetan saioa has dezakezu edo haiek alda ditzakezu.
Baimena behar duzu orria atzitzeko. Direktorioak alda ditzakezu.
Azure Synapse Analytics ofrece varios motores de análisis para ayudarle a ingerir, transformar, modelar y analizar los datos. Un grupo de SQL dedicado ofrece funcionalidades de almacenamiento y proceso basadas en T-SQL. Después de crear un grupo de SQL dedicado en el área de trabajo de Synapse, los datos se pueden cargar, modelar, procesar y entregar para obtener información analítica más rápida.
En este inicio rápido, aprenderá a cargar datos de Azure SQL Database en Azure Synapse Analytics. Puede seguir los mismos pasos para copiar datos de otros tipos de almacenes de datos. Este flujo similar se aplica a la copia de datos en otros orígenes y receptores.
Prerrequisitos
- Suscripción de Azure: si no tiene una suscripción de Azure, cree una cuenta gratuita de Azure antes de empezar.
- Área de trabajo de Azure Synapse: cree un área de trabajo de Synapse mediante Azure Portal siguiendo las instrucciones de Inicio rápido: Creación de un área de trabajo de Synapse.
- Azure SQL Database: este tutorial copia los datos del conjunto de datos de ejemplo Adventure Works LT en Azure SQL Database. Puede crear esta base de datos de ejemplo en SQL Database si sigue las instrucciones que aparecen en Creación de una base de datos de ejemplo en Azure SQL Database. O bien, puede usar otros almacenes de datos siguiendo pasos similares.
- Cuenta de almacenamiento de Azure: Azure Storage se usa como área de almacenamiento provisional en la operación de copia. Si no dispone de una cuenta de almacenamiento de Azure, consulte las instrucciones de Creación de una cuenta de almacenamiento.
- Azure Synapse Analytics: se usa un grupo de SQL dedicado como almacén de datos receptor. Si no tiene una instancia de Azure Synapse Analytics, consulte Creación de un grupo de SQL dedicado para ver los pasos para crear una.
Vaya al Synapse Studio.
Después de crear el área de trabajo de Synapse, tiene dos maneras de abrir Synapse Studio:
- Abra el área de trabajo de Synapse en Azure Portal. Seleccione Abrir en la tarjeta de Synapse Studio bajo Primeros pasos.
- Abra Azure Synapse Analytics e inicie sesión en el área de trabajo.
En este inicio rápido, usamos el área de trabajo denominada "adftest2020" como ejemplo. Le navegará automáticamente a la página principal de Synapse Studio.
Crear servicios vinculados
En Azure Synapse Analytics, un servicio vinculado es el lugar donde se define la información de conexión a otros servicios. En esta sección, creará dos tipos de servicios vinculados siguientes: Azure SQL Database y Azure Data Lake Storage Gen2 (ADLS Gen2).
En la página principal de Synapse Studio, seleccione la pestaña Administrar en el panel de navegación izquierdo.
En Conexiones externas, seleccione Servicios vinculados.
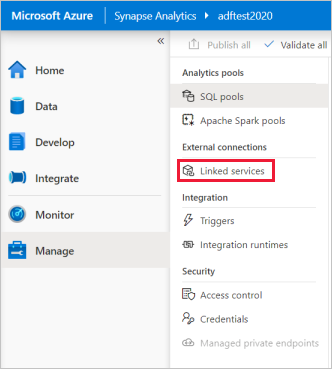
Para agregar un servicio vinculado, seleccione Nuevo.
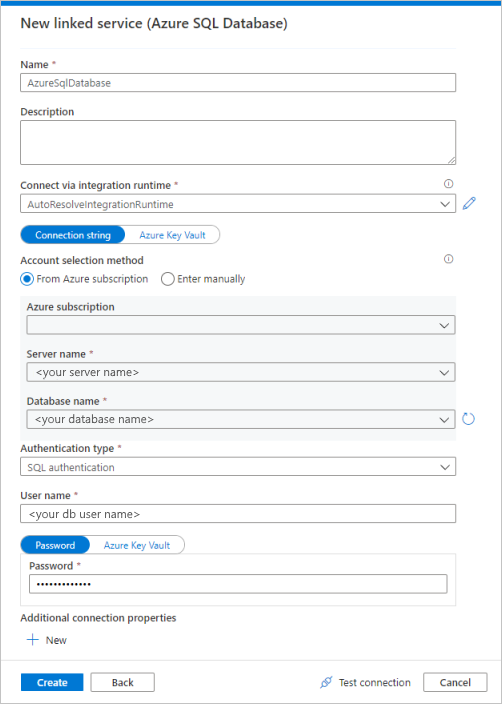
Seleccione Azure SQL Database en la galería y, luego, elija Continuar. Puede escribir "sql" en el cuadro de búsqueda para filtrar los conectores.

En la página Nuevo servicio vinculado, seleccione el nombre del servidor y el nombre de la base de datos en la lista desplegable y especifique el nombre de usuario y la contraseña. Haga clic en Probar conexión para validar la configuración y, a continuación, seleccione Crear.
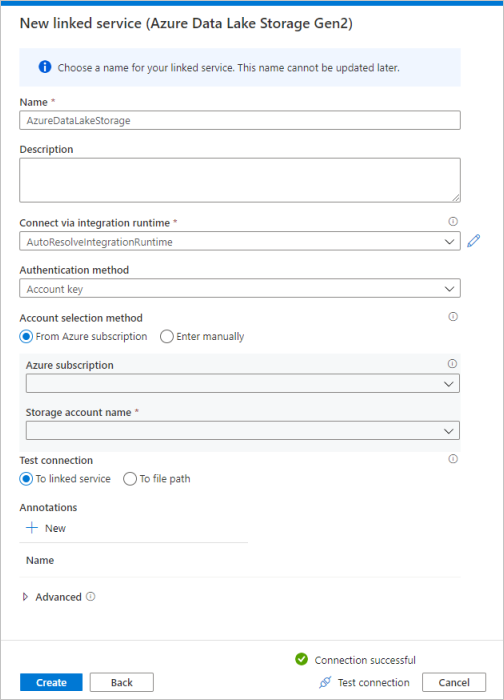
Repita los pasos del 3 al 4, pero seleccione Azure Data Lake Storage Gen2 en su lugar en la galería. En la página Nuevo servicio vinculado, seleccione el nombre de la cuenta de almacenamiento en la lista desplegable. Haga clic en Probar conexión para validar la configuración y, a continuación, seleccione Crear.
Crear una canalización
Una canalización contiene el flujo lógico para una ejecución de un conjunto de actividades. En esta sección, creará una canalización que contiene una actividad de copia que ingiere datos de Azure SQL Database en un grupo de SQL dedicado.
Vaya a la pestaña Integrar. Haga clic en el icono más situado junto al encabezado de las canalizaciones y elija Canalización.
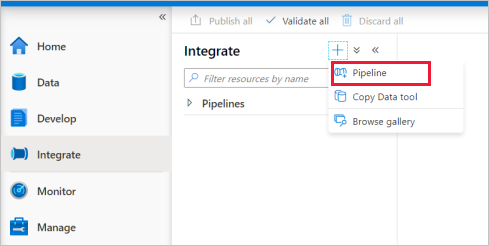
En la sección Move and Transform (Mover y transformar) del panel Activities (Actividades), arrastre Copy data (Copiar datos) al lienzo de la canalización.
Seleccione en la actividad de copia y vaya a la pestaña Origen. Seleccione Nuevo para crear un nuevo conjunto de datos de origen.
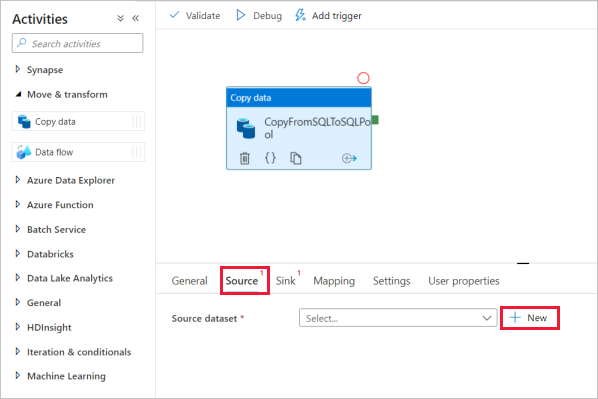
Seleccione Azure SQL Database como almacén de datos y seleccione Continuar.
En el panel Establecer propiedades , seleccione el servicio vinculado de Azure SQL Database que creó en el paso anterior.
En Nombre de tabla, seleccione una tabla de ejemplo que se usará en la siguiente actividad de copia. En este inicio rápido, usamos la tabla "SalesLT.Customer" como ejemplo.
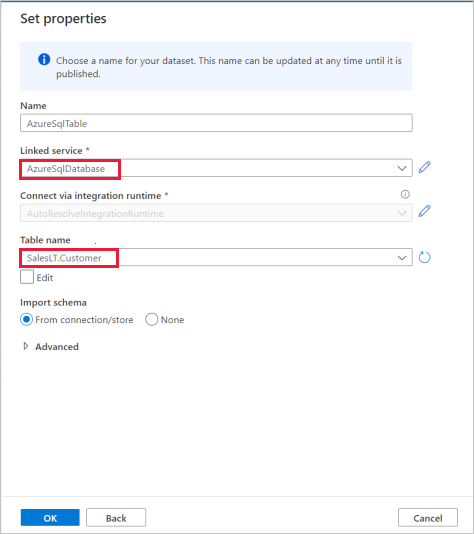
Seleccione Aceptar cuando haya terminado.
Seleccione la actividad de copia y vaya a la pestaña Receptor. Seleccione Nuevo para crear un conjunto de datos de receptor.
Seleccione Grupo de SQL dedicado de Azure Synapse como almacén de datos y seleccione Continuar.
En el panel Establecer propiedades , seleccione el grupo de SQL Analytics que creó en el paso anterior. Si está escribiendo en una tabla existente, en Nombre de tabla, selecciónela en la lista desplegable. De lo contrario, seleccione "Editar" y escriba el nuevo nombre de la tabla. Seleccione Aceptar cuando haya terminado.
Para la configuración del conjunto del receptor, habilite Auto create table (Creación automática de tabla) en el campo Opción de tabla.
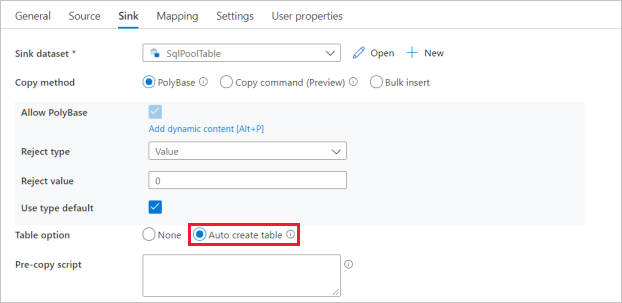
En la página Configuración, seleccione la casilla de verificación para habilitar staging. Esta opción se aplica si los datos de origen no son compatibles con PolyBase. En la sección Configuración de almacenamiento provisional, seleccione el servicio vinculado de Azure Data Lake Storage Gen2 que creó en el paso anterior como almacenamiento provisional.
El almacenamiento se usa para almacenar provisionalmente los datos antes de cargarlos en Azure Synapse Analytics mediante PolyBase. Una vez completada la copia, los datos provisionales de Azure Data Lake Storage Gen2 se limpian automáticamente.
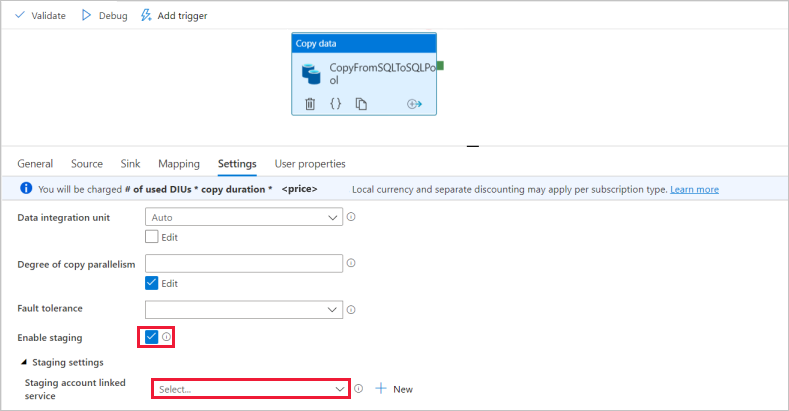
Para validar la canalización, seleccione Validar en la barra de herramientas. Verá el resultado de la salida de la validación de canalización en el lado derecho de la página.
Depuración y publicación de la canalización
Una vez que haya terminado de configurar la canalización, puede ejecutar una depuración antes de publicar los artefactos para verificar que todo esté correcto.
Para depurar la canalización, seleccione Depurar en la barra de herramientas. Verá el estado de ejecución de la canalización en la pestaña Output (Salida) en la parte inferior de la ventana.
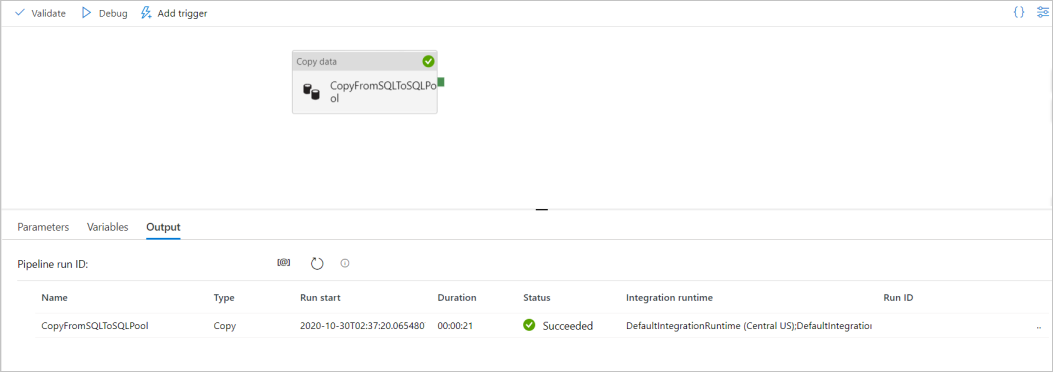
Una vez que la ejecución de la canalización se realice correctamente, en la barra de herramientas superior, seleccione Publicar todo. Esta acción publica entidades (conjuntos de datos y canalizaciones) que creó en el servicio Synapse Analytics.
Espere a que aparezca el mensaje Successfully published (Publicado correctamente). Para ver los mensajes de notificación, seleccione el botón de campana en la parte superior derecha.
Activa y supervisa la tubería
En esta sección, se desencadena manualmente la canalización publicada en el paso anterior.
Seleccione Add Trigger (Agregar desencadenador) en la barra de herramientas y, después, seleccione Trigger Now (Desencadenar ahora). En la página Pipeline Run (Ejecución de la canalización), seleccione OK (Aceptar).
Vaya a la pestaña Monitor ubicada en la barra lateral izquierda. Verá una ejecución de canalización que se desencadena de forma manual.
Cuando la ejecución de la canalización se complete correctamente, seleccione el vínculo en la columna Nombre de canalización para ver los detalles de ejecución de la actividad o para volver a ejecutar la canalización. En este ejemplo, solo hay una actividad, así que solo verá una entrada en la lista.
Para más información sobre la operación de copia, seleccione el vínculo Details (Detalles) (icono de gafas) en la columna Activity name (Nombre de actividad). Puede supervisar detalles como el volumen de datos copiados desde el origen al receptor, el rendimiento de los datos, los pasos de ejecución con su duración correspondiente y las configuraciones que se utilizan.
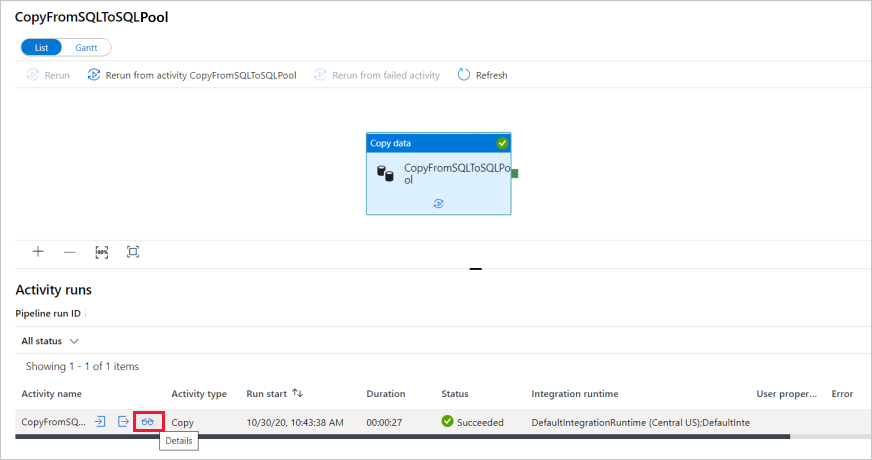
Para volver a la vista de ejecuciones de canalización, seleccione el vínculo Todas las ejecuciones de la canalización. Seleccione Refresh (Actualizar) para actualizar la lista.
Compruebe que los datos están escritos correctamente en el grupo de SQL dedicado.
Pasos siguientes
Continúe al artículo siguiente para obtener información sobre la compatibilidad de Azure Synapse Analytics:
Información general sobre la canalización y las actividadesdel conectorActividad de copia