Administración de paquetes de ámbito de sesión
Además de los paquetes de nivel de grupo, también puede especificar bibliotecas de ámbito de sesión al comienzo de una sesión del cuaderno. Las bibliotecas de ámbito de sesión permiten especificar y usar los paquetes de Python, jar y R en una sesión de cuaderno.
Cuando se usan bibliotecas de ámbito de sesión, es importante tener en cuenta lo siguiente:
- Al instalar las bibliotecas de ámbito de sesión, solo el cuaderno actual tiene acceso a las bibliotecas especificadas.
- Estas bibliotecas no afectan a otras sesiones o trabajos que usen el mismo grupo de Spark.
- Estas bibliotecas se instalan sobre el entorno de ejecución base y las bibliotecas de nivel de grupo, y tienen la prioridad más alta.
- Las bibliotecas de R con ámbito de sesión no se conservan entre sesiones.
Paquetes de Python con ámbito de sesión
Administración de paquetes de Python con ámbito de sesión mediante el archivo environment.yml
Para especificar los paquetes de ámbito de sesión de Python:
- Vaya al grupo de Spark seleccionado y asegúrese de que ha habilitado las bibliotecas de nivel de sesión. Para habilitar esta configuración, vaya a la pestaña Administrar>Grupo de Apache Spark>Paquetes.

- Una vez aplicada la configuración, puede abrir un cuaderno y seleccionar Configurar sesión>Paquetes.

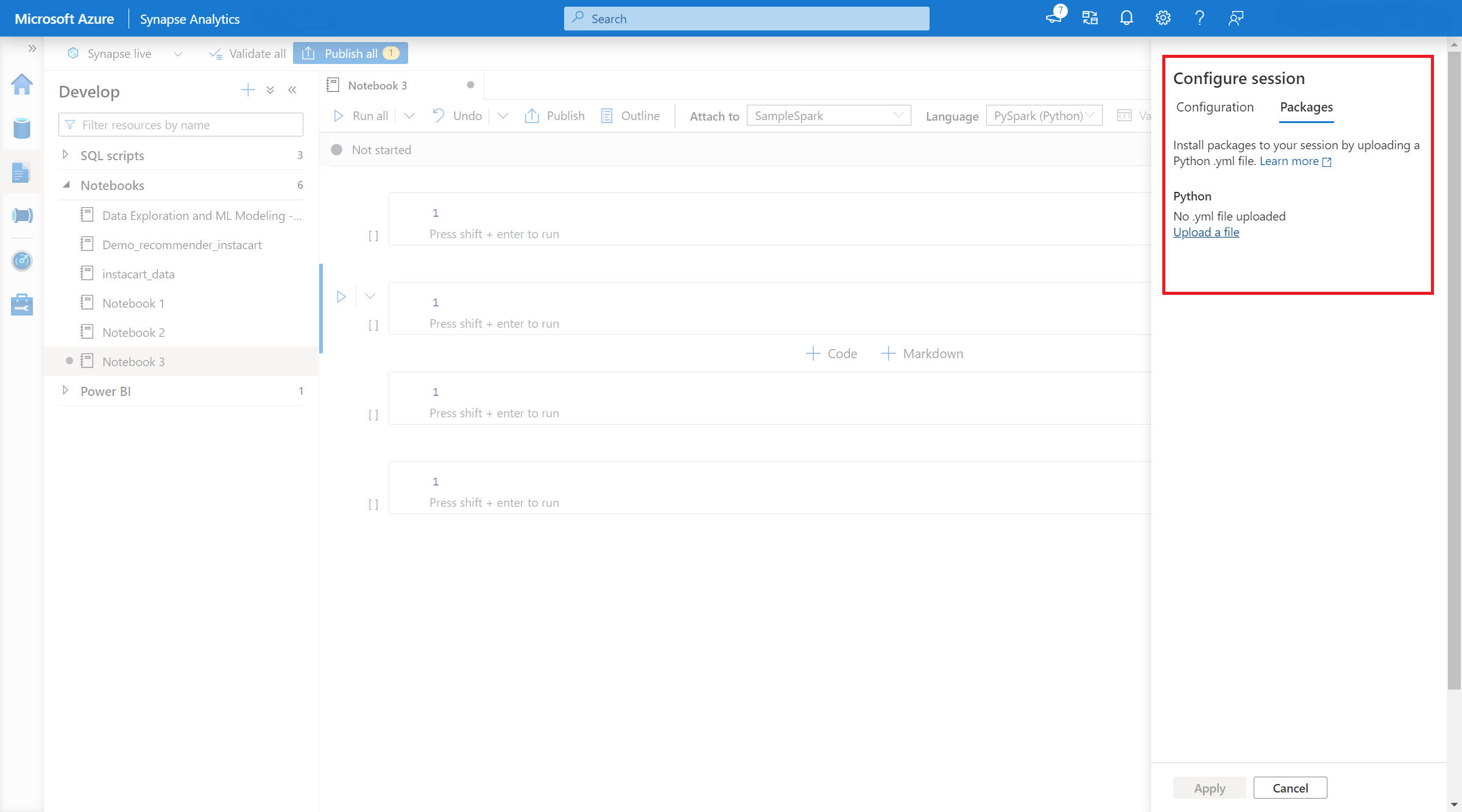
- Aquí puede cargar un archivo environment.yml de Conda para instalar o actualizar paquetes dentro de una sesión. Las bibliotecas especificadas están presentes una vez que se inicia la sesión. Estas bibliotecas ya no estarán disponibles una vez finalizada la sesión.

Administración de paquetes de Python con ámbito de sesión mediante comandos %pip y %conda
Puede usar los comandos %pip y %conda populares para instalar bibliotecas de terceros adicionales o bibliotecas personalizadas durante la sesión del cuaderno de Apache Spark. En esta sección, usamos comandos %pip para mostrar varios escenarios comunes.
Nota
- Se recomienda colocar los comandos %pip y %conda en la primera celda del cuaderno si desea instalar nuevas bibliotecas. El intérprete de Python se reiniciará después de que la biblioteca de nivel de sesión se administre para que los cambios sean efectivos.
- Estos comandos de administración de bibliotecas de Python se deshabilitarán al ejecutar trabajos de canalización. Si desea instalar un paquete dentro de una canalización, debe aprovechar las funcionalidades de administración de bibliotecas en el nivel de grupo.
- Las bibliotecas de Python con ámbito de sesión se instalan automáticamente en los nodos de controlador y de trabajo.
- No se admiten los siguientes comandos %conda : crear, limpiar, comparar, activar, desactivar, ejecutar, empaquetar.
- Puede hacer referencia a comandos %pip y comandos %conda para obtener la lista completa de comandos.
Instalación de un paquete de terceros
Puede instalar fácilmente una biblioteca de Python desde PyPI.
# Install vega_datasets
%pip install altair vega_datasets
Para comprobar el resultado de la instalación, puede ejecutar el código siguiente para visualizar vega_datasets
# Create a scatter plot
# Plot Miles per gallon against the horsepower across different region
import altair as alt
from vega_datasets import data
cars = data.cars()
alt.Chart(cars).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color='Origin',
).interactive()
Instalación de un paquete wheel desde la cuenta de almacenamiento
Para instalar la biblioteca desde el almacenamiento, debe montarla en la cuenta de almacenamiento mediante la ejecución de los siguientes comandos.
from notebookutils import mssparkutils
mssparkutils.fs.mount(
"abfss://<<file system>>@<<storage account>.dfs.core.windows.net",
"/<<path to wheel file>>",
{"linkedService":"<<storage name>>"}
)
Y, a continuación, puede usar el comando %pip install para instalar el paquete wheel necesario.
%pip install /<<path to wheel file>>/<<wheel package name>>.whl
Instalar otra versión de la biblioteca integrada
Puede usar el siguiente comando para ver cuál es la versión integrada de un paquete determinado. Usamos Pandas como ejemplo
%pip show pandas
El resultado es el siguiente registro:
Name: pandas
Version: **1.2.3**
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
... ...
Puede usar el siguiente comando para cambiar pandas a otra versión, supongamos 1.2.4.
%pip install pandas==1.2.4
Desinstalación de una biblioteca con ámbito de sesión
Si desea desinstalar un paquete, que se instaló en esta sesión de cuaderno, puede hacer referencia a los siguientes comandos. Sin embargo, no se pueden desinstalar los paquetes integrados.
%pip uninstall altair vega_datasets --yes
Uso del comando %pip para instalar bibliotecas desde un archivo requirement.txt
%pip install -r /<<path to requirement file>>/requirements.txt
Paquetes de Java o Scala con ámbito de sesión
Para especificar paquetes de Java o Scala de ámbito de sesión, puede usar la opción %%configure:
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<file system>>@<<storage account>.dfs.core.windows.net/<<path to JAR file>>",
}
}
Nota:
- Se recomienda ejecutar el comando %%configure al principio del cuaderno. Puede consultar este documento para obtener la lista completa de parámetros válidos.
Paquetes de ámbito de sesión de R (versión preliminar)
Los grupos de Azure Synapse Analytics incluyen muchas bibliotecas de R populares listas para usar. También puede instalar otras bibliotecas de terceros durante la sesión del cuaderno de Apache Spark.
Nota:
- Estos comandos de administración de bibliotecas de R se deshabilitarán al ejecutar trabajos de canalización. Si desea instalar un paquete dentro de una canalización, debe aprovechar las funcionalidades de administración de bibliotecas en el nivel de grupo.
- Las bibliotecas de R con ámbito de sesión se instalan automáticamente en los nodos de controlador y de trabajo.
Instalación de un paquete
Puede instalar fácilmente una biblioteca de R desde CRAN.
# Install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
También puede usar instantáneas de CRAN como repositorio para asegurarse de que siempre se descarga la misma versión del paquete.
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
Uso de devtools para instalar paquetes
La biblioteca devtools simplifica el desarrollo de paquetes para acelerar las tareas comunes. Esta biblioteca se instala dentro del entorno de ejecución de Azure Synapse Analytics predeterminado.
Puede usar devtools para especificar una versión específica de una biblioteca para instalarla. Estas bibliotecas se instalarán en todos los nodos del clúster.
# Install a specific version.
install_version("caesar", version = "1.0.0")
De forma similar, puede instalar una biblioteca directamente desde GitHub.
# Install a GitHub library.
install_github("jtilly/matchingR")
Actualmente, en Azure Synapse Analytics se admiten las siguientes funciones devtools:
| Get-Help | Descripción |
|---|---|
| install_github() | Instala un paquete de R desde GitHub |
| install_gitlab() | Instala un paquete de R desde GitLab |
| install_bitbucket() | Instala un paquete de R desde BitBucket |
| install_url() | Instala un paquete de R desde una dirección URL arbitraria |
| install_git() | Se instala desde un repositorio git arbitrario |
| install_local() | Se instala desde un archivo local en el disco |
| install_version() | Se instala desde una versión específica en CRAN |
Visualización de las bibliotecas instaladas
Puede consultar todas las bibliotecas instaladas en la sesión mediante el comando library.
library()
Puede usar la función packageVersion para comprobar la versión de la biblioteca:
packageVersion("caesar")
Eliminación de un paquete de R de una sesión
Puede usar la función detach para quitar una biblioteca del espacio de nombres. Estas bibliotecas permanecen en el disco hasta que se carguen de nuevo.
# detach a library
detach("package: caesar")
Para quitar un paquete con ámbito de sesión de un cuaderno, use el comando remove.packages(). Este cambio de biblioteca no afecta a otras sesiones del mismo clúster. Los usuarios no pueden desinstalar ni quitar bibliotecas integradas del entorno de ejecución predeterminado de Azure Synapse Analytics.
remove.packages("caesar")
Nota:
No se pueden quitar paquetes principales como SparkR, SparklyR o R.
Bibliotecas de R con ámbito de sesión y SparkR
Las bibliotecas con ámbito de cuaderno están disponibles en los nodos de trabajo de SparkR.
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
Bibliotecas de R con ámbito de sesión y SparklyR
Con spark_apply() en SparklyR, puede usar cualquier paquete de R dentro de Spark. De forma predeterminada, en sparklyr::spark_apply(), el argumento de los paquetes se establece en FALSE. Este valor copia las bibliotecas del objeto libPaths actual en los nodos de trabajo, lo que le permite importarlas y usarlas en ellos. Por ejemplo, puede ejecutar lo siguiente para generar un mensaje con cifrado césar con sparklyr::spark_apply():
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- "3.2"
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
Pasos siguientes
- Visualización de las bibliotecas predeterminadas: Compatibilidad de las versiones de Azure Spark
- Administración de los paquetes fuera del portal de Synapse Studio: Administración de paquetes a través de comandos de Az y API de REST