Train your conversational language understanding model
After you have completed labeling your utterances, you can start training a model. Training is the process where the model learns from your labeled utterances.
To train a model, start a training job. Only successfully completed jobs create a model. Training jobs expire after seven days, after this time you will no longer be able to retrieve the job details. If your training job completed successfully and a model was created, it won't be affected by the job expiring. You can only have one training job running at a time, and you can't start other jobs in the same project.
The training times can be anywhere from a few seconds when dealing with simple projects, up to a couple of hours when you reach the maximum limit of utterances.
Model evaluation is triggered automatically after training is completed successfully. The evaluation process starts by using the trained model to run predictions on the utterances in the testing set, and compares the predicted results with the provided labels (which establishes a baseline of truth).
Prerequisites
- A successfully created project with a configured Azure blob storage account
- Labeled utterances
Balance training data
When it comes to training data, try to keep your schema well balanced. Including large quantities of one intent and very few of another results in a model that's biased toward particular intents.
To address this scenario, you might need to downsample your training set. Or you might need to add to it. To downsample, you can:
- Get rid of a certain percentage of the training data randomly.
- Analyze the dataset and remove overrepresented duplicate entries, which is a more systematic manner.
To add to the training set, in Language Studio, on the Data labeling tab, select Suggest utterances. Conversational Language Understanding sends a call to Azure OpenAI to generate similar utterances.

You should also look for unintended "patterns" in the training set. For example, look to see if the training set for a particular intent is all lowercase or starts with a particular phrase. In such cases, the model you train might learn these unintended biases in the training set instead of being able to generalize.
We recommend that you introduce casing and punctuation diversity in the training set. If your model is expected to handle variations, be sure to have a training set that also reflects that diversity. For example, include some utterances in proper casing and some in all lowercase.
Data splitting
Before you start the training process, labeled utterances in your project are divided into a training set and a testing set. Each one of them serves a different function. The training set is used in training the model, this is the set from which the model learns the labeled utterances. The testing set is a blind set that isn't introduced to the model during training but only during evaluation.
After the model is trained successfully, the model can be used to make predictions from the utterances in the testing set. These predictions are used to calculate evaluation metrics. It is recommended to make sure that all your intents and entities are adequately represented in both the training and testing set.
Conversational language understanding supports two methods for data splitting:
- Automatically splitting the testing set from training data: The system will split your tagged data between the training and testing sets, according to the percentages you choose. The recommended percentage split is 80% for training and 20% for testing.
Note
If you choose the Automatically splitting the testing set from training data option, only the data assigned to training set will be split according to the percentages provided.
- Use a manual split of training and testing data: This method enables users to define which utterances should belong to which set. This step is only enabled if you have added utterances to your testing set during labeling.
Training modes
CLU supports two modes for training your models
Standard training uses fast machine learning algorithms to train your models relatively quickly. This is currently only available for English and is disabled for any project that doesn't use English (US), or English (UK) as its primary language. This training option is free of charge. Standard training allows you to add utterances and test them quickly at no cost. The evaluation scores shown should guide you on where to make changes in your project and add more utterances. Once you’ve iterated a few times and made incremental improvements, you can consider using advanced training to train another version of your model.
Advanced training uses the latest in machine learning technology to customize models with your data. This is expected to show better performance scores for your models and will enable you to use the multilingual capabilities of CLU as well. Advanced training is priced differently. See the pricing information for details.
Use the evaluation scores to guide your decisions. There might be times where a specific example is predicted incorrectly in advanced training as opposed to when you used standard training mode. However, if the overall evaluation results are better using advanced, then it is recommended to use your final model. If that isn’t the case and you are not looking to use any multilingual capabilities, you can continue to use model trained with standard mode.
Note
You should expect to see a difference in behaviors in intent confidence scores between the training modes as each algorithm calibrates their scores differently.
Train model
To start training your model from within the Language Studio:
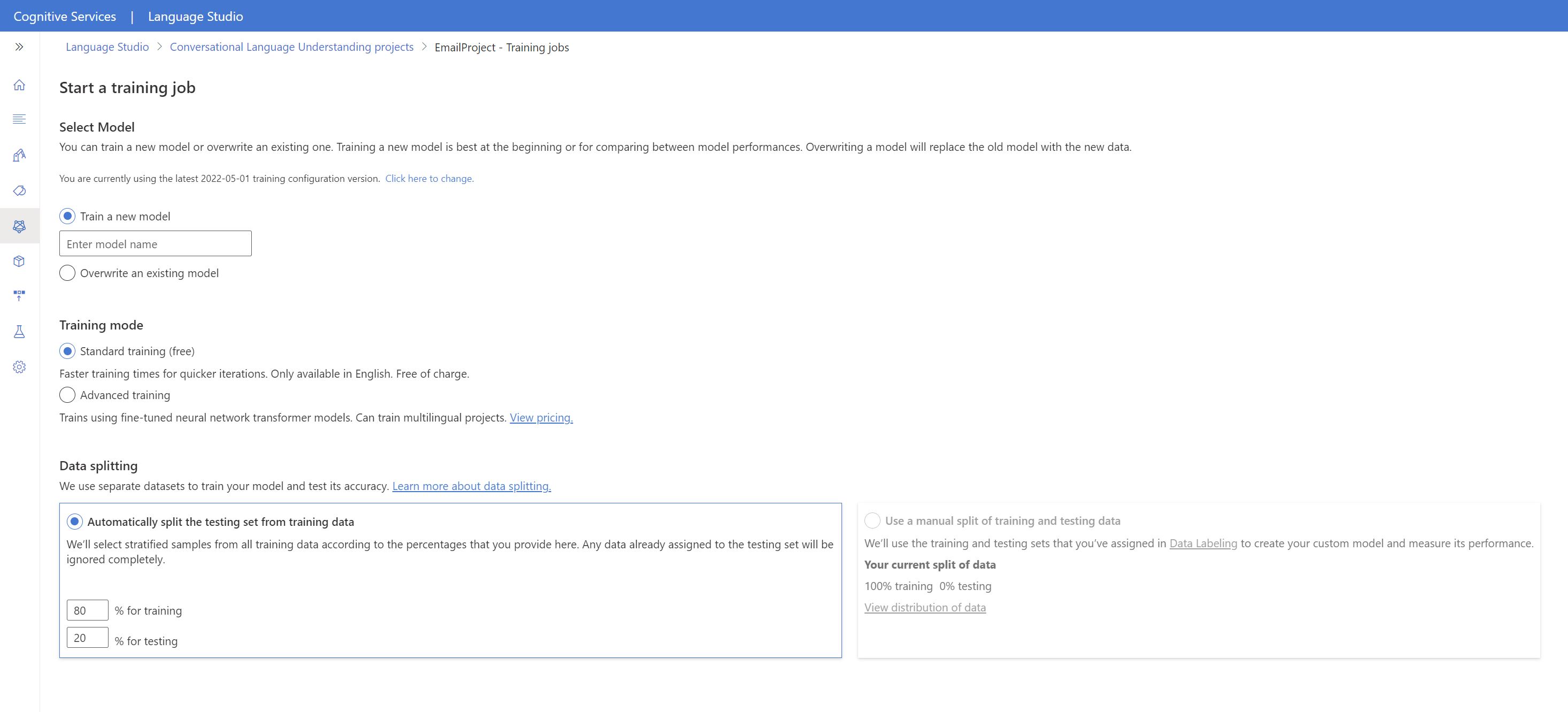
Select Train model from the left side menu.
Select Start a training job from the top menu.
Select Train a new model and enter a new model name in the text box. Otherwise to replace an existing model with a model trained on the new data, select Overwrite an existing model and then select an existing model. Overwriting a trained model is irreversible, but it won't affect your deployed models until you deploy the new model.
Select training mode. You can choose Standard training for faster training, but it is only available for English. Or you can choose Advanced training which is supported for other languages and multilingual projects, but it involves longer training times. Learn more about training modes.
Select a data splitting method. You can choose Automatically splitting the testing set from training data where the system will split your utterances between the training and testing sets, according to the specified percentages. Or you can Use a manual split of training and testing data, this option is only enabled if you have added utterances to your testing set when you labeled your utterances.
Select the Train button.
Select the training job ID from the list. A panel will appear where you can check the training progress, job status, and other details for this job.
Note
- Only successfully completed training jobs will generate models.
- Training can take some time between a couple of minutes and couple of hours based on the count of utterances.
- You can only have one training job running at a time. You can't start other training jobs within the same project until the running job is completed.
- The machine learning used to train models is regularly updated. To train on a previous configuration version, select Select here to change from the Start a training job page and choose a previous version.

Cancel training job
To cancel a training job from within Language Studio
- In the Train model page, select the training job you want to cancel and select Cancel from the top menu.