Automate the replication of schema changes in Azure SQL Data Sync
Applies to: ![]() Azure SQL Database
Azure SQL Database
Important
SQL Data Sync will be retired on 30 September 2027. Consider migrating to alternative data replication/synchronization solutions.
SQL Data Sync lets users synchronize data between databases in Azure SQL Database and SQL Server instances in one direction or in both directions. One of the current limitations of SQL Data Sync is a lack of support for the replication of schema changes. Every time you change the table schema, you need to apply the changes manually on all endpoints, including the hub and all members, and then update the sync schema.
This article introduces a solution to automatically replicate schema changes to all SQL Data Sync endpoints.
- This solution uses a DDL trigger to track schema changes.
- The trigger inserts the schema change commands in a tracking table.
- This tracking table is synced to all endpoints using the Data Sync service.
- DML triggers after insertion are used to apply the schema changes on the other endpoints.
This article uses ALTER TABLE as an example of a schema change, but this solution also works for other types of schema changes.
Read this article carefully, especially the sections about Troubleshooting and Other considerations, before you start to implement automated schema change replication in your sync environment. Some database operations might break the solution described in this article. Additional domain knowledge of SQL Server and Transact-SQL might be required to troubleshoot those issues.
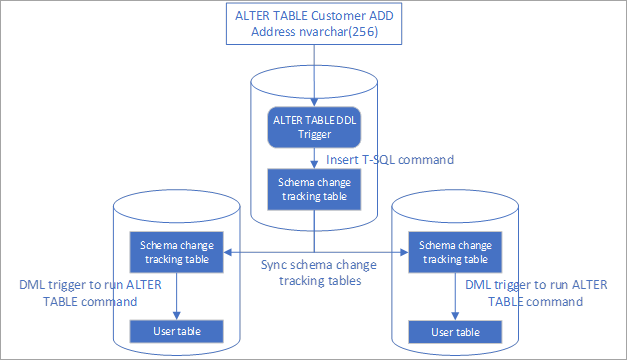
Set up automated schema change replication
Create a table to track schema changes
Create a table to track schema changes in all databases in the sync group:
CREATE TABLE SchemaChanges (
ID bigint IDENTITY(1,1) PRIMARY KEY,
SqlStmt nvarchar(max),
[Description] nvarchar(max)
)
This table has an identity column to track the order of schema changes. You can add more fields to log more information if needed.
Create a table to track the history of schema changes
On all endpoints, create a table to track the ID of the most recently applied schema change command.
CREATE TABLE SchemaChangeHistory (
LastAppliedId bigint PRIMARY KEY
)
GO
INSERT INTO SchemaChangeHistory VALUES (0)
Create an ALTER TABLE DDL trigger in the database where schema changes are made
Create a DDL trigger for ALTER TABLE operations. You only need to create this trigger in the database where schema changes are made. To avoid conflicts, only allow schema changes in one database in a sync group.
CREATE TRIGGER AlterTableDDLTrigger
ON DATABASE
FOR ALTER_TABLE
AS
-- You can add your own logic to filter ALTER TABLE commands instead of replicating all of them.
IF NOT (EVENTDATA().value('(/EVENT_INSTANCE/SchemaName)[1]', 'nvarchar(512)') like 'DataSync')
INSERT INTO SchemaChanges (SqlStmt, Description)
VALUES (EVENTDATA().value('(/EVENT_INSTANCE/TSQLCommand/CommandText)[1]', 'nvarchar(max)'), 'From DDL trigger')
The trigger inserts a record in the schema change tracking table for each ALTER TABLE command. This example adds a filter to avoid replicating schema changes made under schema DataSync, because these are most likely made by the Data Sync service. Add more filters if you only want to replicate certain types of schema changes.
You can also add more triggers to replicate other types of schema changes. For example, create CREATE_PROCEDURE, ALTER_PROCEDURE and DROP_PROCEDURE triggers to replicate changes to stored procedures.
Create a trigger on other endpoints to apply schema changes during insertion
This trigger executes the schema change command when it is synced to other endpoints. You need to create this trigger on all the endpoints, except the one where schema changes are made (that is, in the database where the DDL trigger AlterTableDDLTrigger is created in the previous step).
CREATE TRIGGER SchemaChangesTrigger
ON SchemaChanges
AFTER INSERT
AS
DECLARE @lastAppliedId bigint
DECLARE @id bigint
DECLARE @sqlStmt nvarchar(max)
SELECT TOP 1 @lastAppliedId=LastAppliedId FROM SchemaChangeHistory
SELECT TOP 1 @id = id, @SqlStmt = SqlStmt FROM SchemaChanges WHERE id > @lastAppliedId ORDER BY id
IF (@id = @lastAppliedId + 1)
BEGIN
EXEC sp_executesql @SqlStmt
UPDATE SchemaChangeHistory SET LastAppliedId = @id
WHILE (1 = 1)
BEGIN
SET @id = @id + 1
IF exists (SELECT id FROM SchemaChanges WHERE ID = @id)
BEGIN
SELECT @sqlStmt = SqlStmt FROM SchemaChanges WHERE ID = @id
EXEC sp_executesql @SqlStmt
UPDATE SchemaChangeHistory SET LastAppliedId = @id
END
ELSE
BREAK;
END
END
This trigger runs after the insertion and checks whether the current command should run next. The code logic ensures that no schema change statement is skipped, and all changes are applied even if the insertion is out of order.
Sync the schema change tracking table to all endpoints
You can sync the schema change tracking table to all endpoints using the existing sync group or a new sync group. Make sure the changes in the tracking table can be synced to all endpoints, especially when you're using one-direction sync.
Don't sync the schema change history table, since that table maintains different state on different endpoints.
Apply the schema changes in a sync group
Only schema changes made in the database where the DDL trigger is created are replicated. Schema changes made in other databases are not replicated.
After the schema changes are replicated to all endpoints, you also need to take extra steps to update the sync schema to start or stop syncing the new columns.
Add new columns
Make the schema change.
Avoid any data change where the new columns are involved until you've completed the step that creates the trigger.
Wait until the schema changes are applied to all endpoints.
Refresh the database schema and add the new column to the sync schema.
Data in the new column is synced during next sync operation.
Remove columns
Remove the columns from the sync schema. Data Sync stops syncing data in these columns.
Make the schema change.
Refresh the database schema.
Update data types
Make the schema change.
Wait until the schema changes are applied to all endpoints.
Refresh the database schema.
If the new and old data types are not fully compatible - for example, if you change from
inttobigint- sync might fail before the steps that create the triggers are completed. Sync succeeds after a retry.
Rename columns or tables
Renaming columns or tables makes Data Sync stop working. Create a new table or column, backfill the data, and then delete the old table or column instead of renaming.
Other types of schema changes
For other types of schema changes - for example, creating stored procedures or dropping an index- updating the sync schema is not required.
Troubleshoot automated schema change replication
The replication logic described in this article stops working in some situations- for example, if you made a schema change in an on-premises database which is not supported in Azure SQL Database. In that case, syncing the schema change tracking table fails. You need fix this problem manually:
Disable the DDL trigger and avoid any further schema changes until the issue is fixed.
In the endpoint database where the issue is happening, disable the AFTER INSERT trigger on the endpoint where the schema change can't be made. This action allows the schema change command to be synced.
Trigger sync to sync the schema change tracking table.
In the endpoint database where the issue is happening, query the schema change history table to get the ID of last applied schema change command.
Query the schema change tracking table to list all the commands with an ID greater than the ID value you retrieved in the previous step.
a. Ignore those commands that can't be executed in the endpoint database. You need to deal with the schema inconsistency. Revert the original schema changes if the inconsistency impacts your application.
b. Manually apply those commands that should be applied.
Update the schema change history table and set the last applied ID to the correct value.
Double-check whether the schema is up-to-date.
Re-enable the AFTER INSERT trigger disabled in the second step.
Re-enable the DDL trigger disabled in the first step.
If you want to clean up the records in the schema change tracking table, use DELETE instead of TRUNCATE. Never reseed the identity column in schema change tracking table by using DBCC CHECKIDENT. You can create new schema change tracking tables and update the table name in the DDL trigger if reseeding is required.
Other Considerations
Database users who configure the hub and member databases need to have enough permission to execute the schema change commands.
You can add more filters in the DDL trigger to only replicate schema change in selected tables or operations.
You can only make schema changes in the database where the DDL trigger is created.
If you are making a change in a SQL Server database, make sure the schema change is supported in Azure SQL Database.
If schema changes are made in databases other than the database where the DDL trigger is created, the changes are not replicated. To avoid this issue, you can create DDL triggers to block changes on other endpoints.
If you need to change the schema of the schema change tracking table, disable the DDL trigger before you make the change, and then manually apply the change to all endpoints. Updating the schema in an AFTER INSERT trigger on the same table does not work.
Don't reseed the identity column by using DBCC CHECKIDENT.
Don't use TRUNCATE to clean up data in the schema change tracking table.
Related content
- What is SQL Data Sync for Azure?
- Tutorial: Set up SQL Data Sync between databases in Azure SQL Database and SQL Server
- Use PowerShell to sync data between multiple databases in Azure SQL Database
- Use PowerShell to sync data between SQL Database and SQL Server
- Data Sync Agent for SQL Data Sync
- Best practices for Azure SQL Data Sync
- Monitor and performance tuning in Azure SQL Database and Azure SQL Managed Instance
- Troubleshoot issues with SQL Data Sync
- Use PowerShell to update the sync schema in an existing sync group