Muistiinpano
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
Use Azure Batch to run large-scale parallel and high-performance computing (HPC) batch jobs efficiently in Azure. This tutorial walks through a Python example of running a parallel workload using Batch. You learn a common Batch application workflow and how to interact programmatically with Batch and Storage resources.
- Authenticate with Batch and Storage accounts.
- Upload input files to Storage.
- Create a pool of compute nodes to run an application.
- Create a job and tasks to process input files.
- Monitor task execution.
- Retrieve output files.
In this tutorial, you convert MP4 media files to MP3 format, in parallel, by using the ffmpeg open-source tool.
If you don't have an Azure account, create a free account before you begin.
Prerequisites
An Azure Batch account and a linked Azure Storage account. To create these accounts, see the Batch quickstart guides for Azure portal or Azure CLI.
Sign in to Azure
Sign in to the Azure portal.
Get account credentials
For this example, you need to provide credentials for your Batch and Storage accounts. A straightforward way to get the necessary credentials is in the Azure portal. (You can also get these credentials using the Azure APIs or command-line tools.)
Select All services > Batch accounts, and then select the name of your Batch account.
To see the Batch credentials, select Keys. Copy the values of Batch account, URL, and Primary access key to a text editor.
To see the Storage account name and keys, select Storage account. Copy the values of Storage account name and Key1 to a text editor.
Download and run the sample app
Download the sample app
Download or clone the sample app from GitHub. To clone the sample app repo with a Git client, use the following command:
git clone https://github.com/Azure-Samples/batch-python-ffmpeg-tutorial.git
Navigate to the directory that contains the file batch_python_tutorial_ffmpeg.py.
In your Python environment, install the required packages using pip.
pip install -r requirements.txt
Use a code editor to open the file config.py. Update the Batch and storage account credential strings with the values unique to your accounts. For example:
_BATCH_ACCOUNT_NAME = 'yourbatchaccount'
_BATCH_ACCOUNT_KEY = 'xxxxxxxxxxxxxxxxE+yXrRvJAqT9BlXwwo1CwF+SwAYOxxxxxxxxxxxxxxxx43pXi/gdiATkvbpLRl3x14pcEQ=='
_BATCH_ACCOUNT_URL = 'https://yourbatchaccount.yourbatchregion.batch.azure.com'
_STORAGE_ACCOUNT_NAME = 'mystorageaccount'
_STORAGE_ACCOUNT_KEY = 'xxxxxxxxxxxxxxxxy4/xxxxxxxxxxxxxxxxfwpbIC5aAWA8wDu+AFXZB827Mt9lybZB1nUcQbQiUrkPtilK5BQ=='
Run the app
To run the script:
python batch_python_tutorial_ffmpeg.py
When you run the sample application, the console output is similar to the following. During execution, you experience a pause at Monitoring all tasks for 'Completed' state, timeout in 00:30:00... while the pool's compute nodes are started.
Sample start: 11/28/2018 3:20:21 PM
Container [input] created.
Container [output] created.
Uploading file LowPriVMs-1.mp4 to container [input]...
Uploading file LowPriVMs-2.mp4 to container [input]...
Uploading file LowPriVMs-3.mp4 to container [input]...
Uploading file LowPriVMs-4.mp4 to container [input]...
Uploading file LowPriVMs-5.mp4 to container [input]...
Creating pool [LinuxFFmpegPool]...
Creating job [LinuxFFmpegJob]...
Adding 5 tasks to job [LinuxFFmpegJob]...
Monitoring all tasks for 'Completed' state, timeout in 00:30:00...
Success! All tasks completed successfully within the specified timeout period.
Deleting container [input]....
Sample end: 11/28/2018 3:29:36 PM
Elapsed time: 00:09:14.3418742
Go to your Batch account in the Azure portal to monitor the pool, compute nodes, job, and tasks. For example, to see a heat map of the compute nodes in your pool, select Pools > LinuxFFmpegPool.
When tasks are running, the heat map is similar to the following:
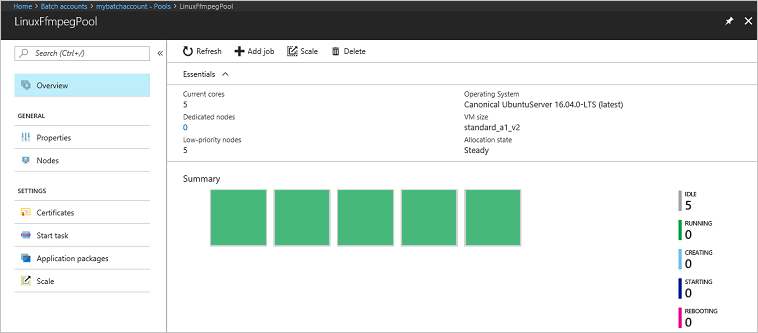
Typical execution time is approximately 5 minutes when you run the application in its default configuration. Pool creation takes the most time.
Retrieve output files
You can use the Azure portal to download the output MP3 files generated by the ffmpeg tasks.
- Click All services > Storage accounts, and then click the name of your storage account.
- Click Blobs > output.
- Right-click one of the output MP3 files and then click Download. Follow the prompts in your browser to open or save the file.
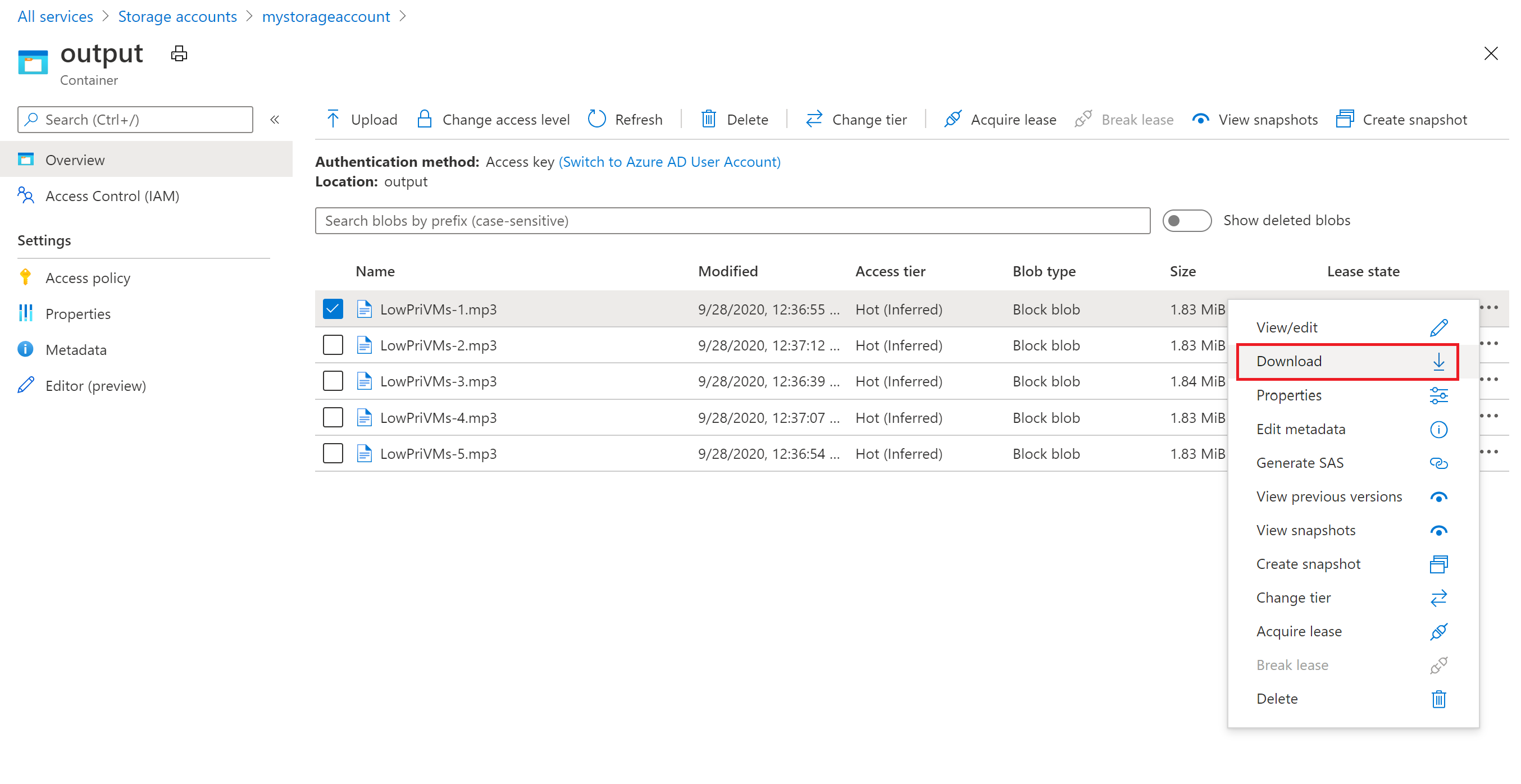
Although not shown in this sample, you can also download the files programmatically from the compute nodes or from the storage container.
Review the code
The following sections break down the sample application into the steps that it performs to process a workload in the Batch service. Refer to the Python code while you read the rest of this article, since not every line of code in the sample is discussed.
Authenticate Blob and Batch clients
To interact with a storage account, the app uses the azure-storage-blob package to create a BlockBlobService object.
blob_client = azureblob.BlockBlobService(
account_name=_STORAGE_ACCOUNT_NAME,
account_key=_STORAGE_ACCOUNT_KEY)
The app creates a BatchServiceClient object to create and manage pools, jobs, and tasks in the Batch service. The Batch client in the sample uses shared key authentication. Batch also supports authentication through Microsoft Entra ID, to authenticate individual users or an unattended application.
credentials = batchauth.SharedKeyCredentials(_BATCH_ACCOUNT_NAME,
_BATCH_ACCOUNT_KEY)
batch_client = batch.BatchServiceClient(
credentials,
base_url=_BATCH_ACCOUNT_URL)
Upload input files
The app uses the blob_client reference create a storage container for the input MP4 files and a container for the task output. Then, it calls the upload_file_to_container function to upload MP4 files in the local InputFiles directory to the container. The files in storage are defined as Batch ResourceFile objects that Batch can later download to compute nodes.
blob_client.create_container(input_container_name, fail_on_exist=False)
blob_client.create_container(output_container_name, fail_on_exist=False)
input_file_paths = []
for folder, subs, files in os.walk(os.path.join(sys.path[0], './InputFiles/')):
for filename in files:
if filename.endswith(".mp4"):
input_file_paths.append(os.path.abspath(
os.path.join(folder, filename)))
# Upload the input files. This is the collection of files that are to be processed by the tasks.
input_files = [
upload_file_to_container(blob_client, input_container_name, file_path)
for file_path in input_file_paths]
Create a pool of compute nodes
Next, the sample creates a pool of compute nodes in the Batch account with a call to create_pool. This defined function uses the Batch PoolAddParameter class to set the number of nodes, VM size, and a pool configuration. Here, a VirtualMachineConfiguration object specifies an ImageReference to an Ubuntu Server 20.04 LTS image published in the Azure Marketplace. Batch supports a wide range of VM images in the Azure Marketplace, as well as custom VM images.
The number of nodes and VM size are set using defined constants. Batch supports dedicated nodes and Spot nodes, and you can use either or both in your pools. Dedicated nodes are reserved for your pool. Spot nodes are offered at a reduced price from surplus VM capacity in Azure. Spot nodes become unavailable if Azure doesn't have enough capacity. The sample by default creates a pool containing only five Spot nodes in size Standard_A1_v2.
In addition to physical node properties, this pool configuration includes a StartTask object. The StartTask executes on each node as that node joins the pool, and each time a node is restarted. In this example, the StartTask runs Bash shell commands to install the ffmpeg package and dependencies on the nodes.
The pool.add method submits the pool to the Batch service.
new_pool = batch.models.PoolAddParameter(
id=pool_id,
virtual_machine_configuration=batchmodels.VirtualMachineConfiguration(
image_reference=batchmodels.ImageReference(
publisher="Canonical",
offer="UbuntuServer",
sku="20.04-LTS",
version="latest"
),
node_agent_sku_id="batch.node.ubuntu 20.04"),
vm_size=_POOL_VM_SIZE,
target_dedicated_nodes=_DEDICATED_POOL_NODE_COUNT,
target_low_priority_nodes=_LOW_PRIORITY_POOL_NODE_COUNT,
start_task=batchmodels.StartTask(
command_line="/bin/bash -c \"apt-get update && apt-get install -y ffmpeg\"",
wait_for_success=True,
user_identity=batchmodels.UserIdentity(
auto_user=batchmodels.AutoUserSpecification(
scope=batchmodels.AutoUserScope.pool,
elevation_level=batchmodels.ElevationLevel.admin)),
)
)
batch_service_client.pool.add(new_pool)
Create a job
A Batch job specifies a pool to run tasks on and optional settings such as a priority and schedule for the work. The sample creates a job with a call to create_job. This defined function uses the JobAddParameter class to create a job on your pool. The job.add method submits the pool to the Batch service. Initially the job has no tasks.
job = batch.models.JobAddParameter(
id=job_id,
pool_info=batch.models.PoolInformation(pool_id=pool_id))
batch_service_client.job.add(job)
Create tasks
The app creates tasks in the job with a call to add_tasks. This defined function creates a list of task objects using the TaskAddParameter class. Each task runs ffmpeg to process an input resource_files object using a command_line parameter. ffmpeg was previously installed on each node when the pool was created. Here, the command line runs ffmpeg to convert each input MP4 (video) file to an MP3 (audio) file.
The sample creates an OutputFile object for the MP3 file after running the command line. Each task's output files (one, in this case) are uploaded to a container in the linked storage account, using the task's output_files property.
Then, the app adds tasks to the job with the task.add_collection method, which queues them to run on the compute nodes.
tasks = list()
for idx, input_file in enumerate(input_files):
input_file_path = input_file.file_path
output_file_path = "".join((input_file_path).split('.')[:-1]) + '.mp3'
command = "/bin/bash -c \"ffmpeg -i {} {} \"".format(
input_file_path, output_file_path)
tasks.append(batch.models.TaskAddParameter(
id='Task{}'.format(idx),
command_line=command,
resource_files=[input_file],
output_files=[batchmodels.OutputFile(
file_pattern=output_file_path,
destination=batchmodels.OutputFileDestination(
container=batchmodels.OutputFileBlobContainerDestination(
container_url=output_container_sas_url)),
upload_options=batchmodels.OutputFileUploadOptions(
upload_condition=batchmodels.OutputFileUploadCondition.task_success))]
)
)
batch_service_client.task.add_collection(job_id, tasks)
Monitor tasks
When tasks are added to a job, Batch automatically queues and schedules them for execution on compute nodes in the associated pool. Based on the settings you specify, Batch handles all task queuing, scheduling, retrying, and other task administration duties.
There are many approaches to monitoring task execution. The wait_for_tasks_to_complete function in this example uses the TaskState object to monitor tasks for a certain state, in this case the completed state, within a time limit.
while datetime.datetime.now() < timeout_expiration:
print('.', end='')
sys.stdout.flush()
tasks = batch_service_client.task.list(job_id)
incomplete_tasks = [task for task in tasks if
task.state != batchmodels.TaskState.completed]
if not incomplete_tasks:
print()
return True
else:
time.sleep(1)
...
Clean up resources
After it runs the tasks, the app automatically deletes the input storage container it created, and gives you the option to delete the Batch pool and job. The BatchClient's JobOperations and PoolOperations classes both have delete methods, which are called if you confirm deletion. Although you're not charged for jobs and tasks themselves, you are charged for compute nodes. Thus, we recommend that you allocate pools only as needed. When you delete the pool, all task output on the nodes is deleted. However, the input and output files remain in the storage account.
When no longer needed, delete the resource group, Batch account, and storage account. To do so in the Azure portal, select the resource group for the Batch account and choose Delete resource group.
Next steps
In this tutorial, you learned how to:
- Authenticate with Batch and Storage accounts.
- Upload input files to Storage.
- Create a pool of compute nodes to run an application.
- Create a job and tasks to process input files.
- Monitor task execution.
- Retrieve output files.
For more examples of using the Python API to schedule and process Batch workloads, see the Batch Python samples on GitHub.