Using a partitioned graph in Azure Cosmos DB
APPLIES TO:
![]() Gremlin
Gremlin
One of the key features of the API for Gremlin in Azure Cosmos DB is the ability to handle large-scale graphs through horizontal scaling. The containers can scale independently in terms of storage and throughput. You can create containers in Azure Cosmos DB that can be automatically scaled to store a graph data. The data is automatically balanced based on the specified partition key.
Partitioning is done internally if the container is expected to store more than 20 GB in size or if you want to allocate more than 10,000 request units per second (RUs). Data is automatically partitioned based on the partition key you specify. Partition key is required if you create graph containers from the Azure portal or the 3.x or higher versions of Gremlin drivers. Partition key is not required if you use 2.x or lower versions of Gremlin drivers.
The same general principles from the Azure Cosmos DB partitioning mechanism apply with a few graph-specific optimizations described below.
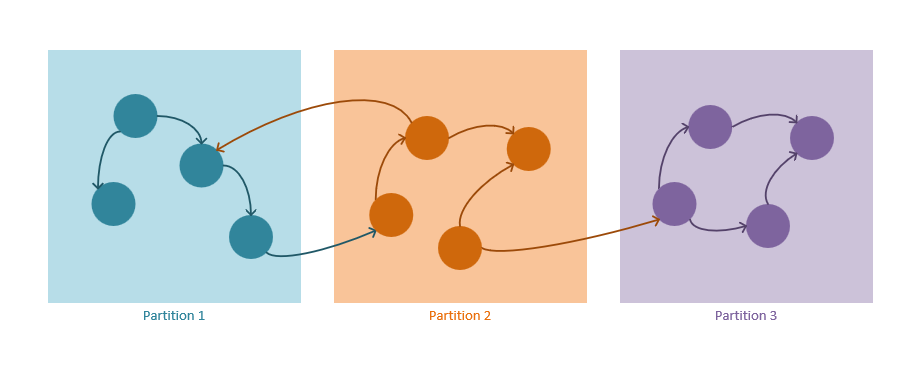
Graph partitioning mechanism
The following guidelines describe how the partitioning strategy in Azure Cosmos DB operates:
Both vertices and edges are stored as JSON documents.
Vertices require a partition key. This key will determine in which partition the vertex will be stored through a hashing algorithm. The partition key property name is defined when creating a new container and it has a format:
/partitioning-key-name.Edges will be stored with their source vertex. In other words, for each vertex its partition key defines where they are stored along with its outgoing edges. This optimization is done to avoid cross-partition queries when using the
out()cardinality in graph queries.Edges contain references to the vertices they point to. All edges are stored with the partition keys and IDs of the vertices that they are pointing to. This computation makes all
out()direction queries always be a scoped partitioned query, and not a blind cross-partition query.Graph queries need to specify a partition key. To take full advantage of the horizontal partitioning in Azure Cosmos DB, the partition key should be specified when a single vertex is selected, whenever it's possible. The following are queries for selecting one or multiple vertices in a partitioned graph:
/idand/labelare not supported as partition keys for a container in API for Gremlin.Selecting a vertex by ID, then using the
.has()step to specify the partition key property:g.V('vertex_id').has('partitionKey', 'partitionKey_value')Selecting a vertex by specifying a tuple including partition key value and ID:
g.V(['partitionKey_value', 'vertex_id'])Selecting a set of vertices with their IDs and specifying a list of partition key values:
g.V('vertex_id0', 'vertex_id1', 'vertex_id2', …).has('partitionKey', within('partitionKey_value0', 'partitionKey_value01', 'partitionKey_value02', …)Using the Partition strategy at the beginning of a query and specifying a partition for the scope of the rest of the Gremlin query:
g.withStrategies(PartitionStrategy.build().partitionKey('partitionKey').readPartitions('partitionKey_value').create()).V()
Best practices when using a partitioned graph
Use the following guidelines to ensure performance and scalability when using partitioned graphs with unlimited containers:
Always specify the partition key value when querying a vertex. Getting vertex from a known partition is a way to achieve performance. All subsequent adjacency operations will always be scoped to a partition since Edges contain reference ID and partition key to their target vertices.
Use the outgoing direction when querying edges whenever it's possible. As mentioned above, edges are stored with their source vertices in the outgoing direction. So the chances of resorting to cross-partition queries are minimized when the data and queries are designed with this pattern in mind. On the contrary, the
in()query will always be an expensive fan-out query.Choose a partition key that will evenly distribute data across partitions. This decision heavily depends on the data model of the solution. Read more about creating an appropriate partition key in Partitioning and scale in Azure Cosmos DB.
Optimize queries to obtain data within the boundaries of a partition. An optimal partitioning strategy would be aligned to the querying patterns. Queries that obtain data from a single partition provide the best possible performance.
Next steps
Next you can proceed to read the following articles:
- Learn about Partition and scale in Azure Cosmos DB.
- Learn about the Gremlin support in API for Gremlin.
- Learn about Introduction to API for Gremlin.