Huomautus
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
The Azure Synapse Spark job definition Activity in a pipeline runs a Synapse Spark job definition in your Azure Synapse Analytics workspace. This article builds on the data transformation activities article, which presents a general overview of data transformation and the supported transformation activities.
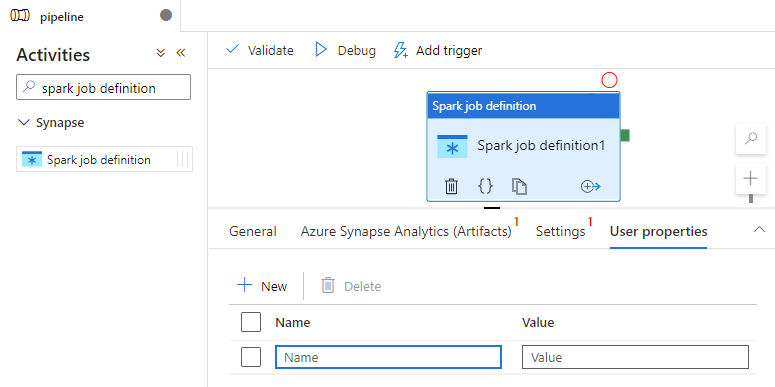
Set Apache Spark job definition canvas
To use a Spark job definition activity for Synapse in a pipeline, complete the following steps:
General settings
Search for Spark job definition in the pipeline Activities pane, and drag a Spark job definition activity under the Synapse to the pipeline canvas.
Select the new Spark job definition activity on the canvas if it isn't already selected.
In the General tab, enter sample for Name.
(Option) You can also enter a description.
Timeout: Maximum amount of time an activity can run. Default is seven days, which is also the maximum amount of time allowed. Format is in D.HH:MM:SS.
Retry: Maximum number of retry attempts.
Retry interval: The number of seconds between each retry attempt.
Secure output: When checked, output from the activity won't be captured in logging.
Secure input: When checked, input from the activity won't be captured in logging.
Azure Synapse Analytics (Artifacts) settings
Select the new Spark job definition activity on the canvas if it isn't already selected.
Select the Azure Synapse Analytics (Artifacts) tab to select or create a new Azure Synapse Analytics linked service that will execute the Spark job definition activity.
Settings tab
Select the new Spark job definition activity on the canvas if it isn't already selected.
Select the Settings tab.
Expand the Spark job definition list, you can select an existing Apache Spark job definition in the linked Azure Synapse Analytics workspace.
(Optional) You can fill in information for Apache Spark job definition. If the following settings are empty, the settings of the spark job definition itself will be used to run; if the following settings aren't empty, these settings will replace the settings of the spark job definition itself.
Property Description Main definition file The main file used for the job. Select a PY/JAR/ZIP file from your storage. You can select Upload file to upload the file to a storage account.
Sample:abfss://…/path/to/wordcount.jarReferences from subfolders Scanning subfolders from the root folder of the main definition file, these files will be added as reference files. The folders named "jars", "pyFiles", "files" or "archives" will be scanned, and the folders name are case sensitive. Main class name The fully qualified identifier or the main class that is in the main definition file.
Sample:WordCountCommand-line arguments You can add command-line arguments by clicking the New button. It should be noted that adding command-line arguments will override the command-line arguments defined by the Spark job definition.
Sample:abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultApache Spark pool You can select Apache Spark pool from the list. Python code reference Additional python code files used for reference in the main definition file.
It supports passing files (.py, .py3, .zip) to the "pyFiles" property. It will override the "pyFiles" property defined in Spark job definition.Reference files Additional files used for reference in the main definition file. Apache Spark pool You can select Apache Spark pool from the list. Dynamically allocate executors This setting maps to the dynamic allocation property in Spark configuration for Spark Application executors allocation. Min executors Min number of executors to be allocated in the specified Spark pool for the job. Max executors Max number of executors to be allocated in the specified Spark pool for the job. Driver size Number of cores and memory to be used for driver given in the specified Apache Spark pool for the job. Spark configuration Specify values for Spark configuration properties listed in the topic: Spark Configuration - Application properties. Users can use default configuration and customized configuration. Authentication User-assigned managed identities or system-assigned managed identities already supported in Spark job definitions. 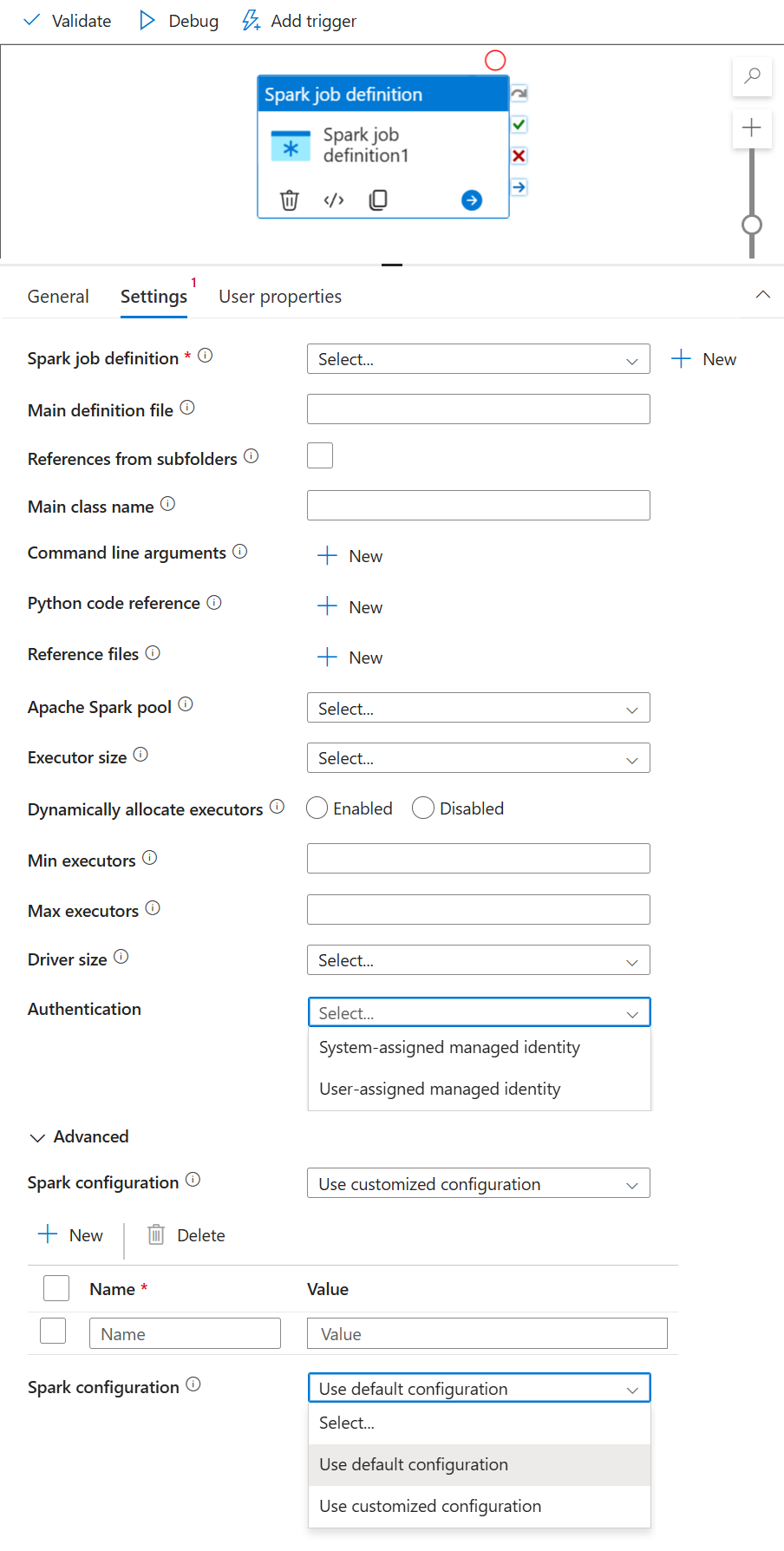
You can add dynamic content by clicking the Add Dynamic Content button or by pressing the shortcut key Alt+Shift+D. In the Add Dynamic Content page, you can use any combination of expressions, functions, and system variables to add to dynamic content.
User properties tab
You can add properties for Apache Spark job definition activity in this panel.
Azure Synapse spark job definition activity definition
Here's the sample JSON definition of an Azure Synapse Analytics Notebook Activity:
{
"activities": [
{
"name": "Spark job definition1",
"type": "SparkJob",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"typeProperties": {
"sparkJob": {
"referenceName": {
"value": "Spark job definition 1",
"type": "Expression"
},
"type": "SparkJobDefinitionReference"
}
},
"linkedServiceName": {
"referenceName": "AzureSynapseArtifacts1",
"type": "LinkedServiceReference"
}
}
],
}
Azure Synapse Spark job definition properties
The following table describes the JSON properties used in the JSON definition:
| Property | Description | Required |
|---|---|---|
| name | Name of the activity in the pipeline. | Yes |
| description | Text describing what the activity does. | No |
| type | For Azure Synapse spark job definition Activity, the activity type is SparkJob. | Yes |
See Azure Synapse Spark job definition activity run history
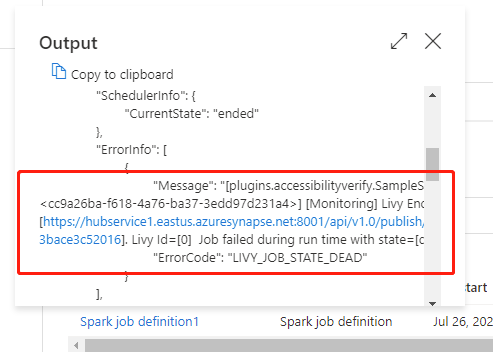
Go to Pipeline runs under the Monitor tab, you'll see the pipeline you've triggered. Open the pipeline that contains Azure Synapse Spark job definition activity to see the run history.
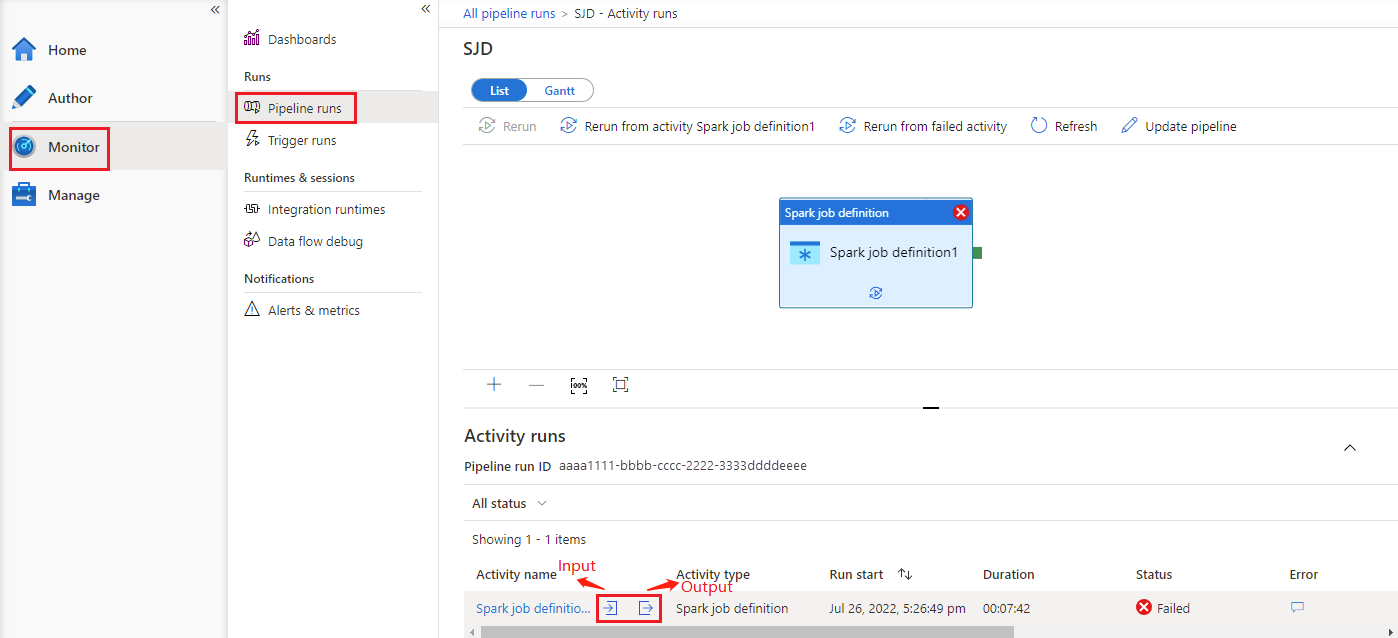
You can see the notebook activity input or output by selecting the input or Output button. If your pipeline failed with a user error, select the output to check the result field to see the detailed user error traceback.