Use C# with MapReduce streaming on Apache Hadoop in HDInsight
Learn how to use C# to create a MapReduce solution on HDInsight.
Apache Hadoop streaming allows you to run MapReduce jobs using a script or executable. Here, .NET is used to implement the mapper and reducer for a word count solution.
.NET on HDInsight
HDInsight clusters use Mono (https://mono-project.com) to run .NET applications. Mono version 4.2.1 is included with HDInsight version 3.6. For more information on the version of Mono included with HDInsight, see Apache Hadoop components available with HDInsight versions.
For more information on Mono compatibility with .NET Framework versions, see Mono compatibility.
How Hadoop streaming works
The basic process used for streaming in this document is as follows:
- Hadoop passes data to the mapper (mapper.exe in this example) on STDIN.
- The mapper processes the data, and emits tab-delimited key/value pairs to STDOUT.
- The output is read by Hadoop, and then passed to the reducer (reducer.exe in this example) on STDIN.
- The reducer reads the tab-delimited key/value pairs, processes the data, and then emits the result as tab-delimited key/value pairs on STDOUT.
- The output is read by Hadoop and written to the output directory.
For more information on streaming, see Hadoop Streaming.
Prerequisites
Visual Studio.
A familiarity with writing and building C# code that targets .NET Framework 4.5.
A way to upload .exe files to the cluster. The steps in this document use the Data Lake Tools for Visual Studio to upload the files to primary storage for the cluster.
If using PowerShell, you'll need the Az Module.
An Apache Hadoop cluster on HDInsight. See Get Started with HDInsight on Linux.
The URI scheme for your clusters primary storage. This scheme would be
wasb://for Azure Storage,abfs://for Azure Data Lake Storage Gen2 oradl://for Azure Data Lake Storage Gen1. If secure transfer is enabled for Azure Storage or Data Lake Storage Gen2, the URI would bewasbs://orabfss://, respectively.
Create the mapper
In Visual Studio, create a new .NET Framework console application named mapper. Use the following code for the application:
using System;
using System.Text.RegularExpressions;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
string line;
//Hadoop passes data to the mapper on STDIN
while((line = Console.ReadLine()) != null)
{
// We only want words, so strip out punctuation, numbers, etc.
var onlyText = Regex.Replace(line, @"\.|;|:|,|[0-9]|'", "");
// Split at whitespace.
var words = Regex.Matches(onlyText, @"[\w]+");
// Loop over the words
foreach(var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t1",word);
}
}
}
}
}
After you create the application, build it to produce the /bin/Debug/mapper.exe file in the project directory.
Create the reducer
In Visual Studio, create a new .NET Framework console application named reducer. Use the following code for the application:
using System;
using System.Collections.Generic;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
//Dictionary for holding a count of words
Dictionary<string, int> words = new Dictionary<string, int>();
string line;
//Read from STDIN
while ((line = Console.ReadLine()) != null)
{
// Data from Hadoop is tab-delimited key/value pairs
var sArr = line.Split('\t');
// Get the word
string word = sArr[0];
// Get the count
int count = Convert.ToInt32(sArr[1]);
//Do we already have a count for the word?
if(words.ContainsKey(word))
{
//If so, increment the count
words[word] += count;
} else
{
//Add the key to the collection
words.Add(word, count);
}
}
//Finally, emit each word and count
foreach (var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t{1}", word.Key, word.Value);
}
}
}
}
After you create the application, build it to produce the /bin/Debug/reducer.exe file in the project directory.
Upload to storage
Next, you need to upload the mapper and reducer applications to HDInsight storage.
In Visual Studio, select View > Server Explorer.
Right-click Azure, select Connect to Microsoft Azure Subscription..., and complete the sign-in process.
Expand the HDInsight cluster that you wish to deploy this application to. An entry with the text (Default Storage Account) is listed.
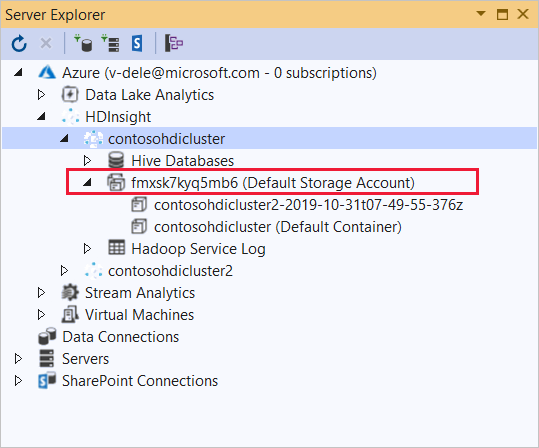
If the (Default Storage Account) entry can be expanded, you're using an Azure Storage Account as default storage for the cluster. To view the files on the default storage for the cluster, expand the entry and then double-click (Default Container).
If the (Default Storage Account) entry can't be expanded, you're using Azure Data Lake Storage as the default storage for the cluster. To view the files on the default storage for the cluster, double-click the (Default Storage Account) entry.
To upload the .exe files, use one of the following methods:
If you're using an Azure Storage Account, select the Upload Blob icon.

In the Upload New File dialog box, under File name, select Browse. In the Upload Blob dialog box, go to the bin\debug folder for the mapper project, and then choose the mapper.exe file. Finally, select Open and then OK to complete the upload.
For Azure Data Lake Storage, right-click an empty area in the file listing, and then select Upload. Finally, select the mapper.exe file and then select Open.
Once the mapper.exe upload has finished, repeat the upload process for the reducer.exe file.
Run a job: Using an SSH session
The following procedure describes how to run a MapReduce job using an SSH session:
Use ssh command to connect to your cluster. Edit the command below by replacing CLUSTERNAME with the name of your cluster, and then enter the command:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netUse one of the following commands to start the MapReduce job:
If the default storage is Azure Storage:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files wasbs:///mapper.exe,wasbs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutIf the default storage is Data Lake Storage Gen1:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files adl:///mapper.exe,adl:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutIf the default storage is Data Lake Storage Gen2:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files abfs:///mapper.exe,abfs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout
The following list describes what each parameter and option represents:
Parameter Description hadoop-streaming.jar Specifies the jar file that contains the streaming MapReduce functionality. -files Specifies the mapper.exe and reducer.exe files for this job. The wasbs:///,adl:///, orabfs:///protocol declaration before each file is the path to the root of default storage for the cluster.-mapper Specifies the file that implements the mapper. -reducer Specifies the file that implements the reducer. -input Specifies the input data. -output Specifies the output directory. Once the MapReduce job completes, use the following command to view the results:
hdfs dfs -text /example/wordcountout/part-00000The following text is an example of the data returned by this command:
you 1128 young 38 younger 1 youngest 1 your 338 yours 4 yourself 34 yourselves 3 youth 17
Run a job: Using PowerShell
Use the following PowerShell script to run a MapReduce job and download the results.
# Login to your Azure subscription
$context = Get-AzContext
if ($context -eq $null)
{
Connect-AzAccount
}
$context
# Get HDInsight info
$clusterName = Read-Host -Prompt "Enter the HDInsight cluster name"
$creds=Get-Credential -Message "Enter the login for the cluster"
# Path for job output
$outputPath="/example/wordcountoutput"
# Progress indicator
$activity="C# MapReduce example"
Write-Progress -Activity $activity -Status "Getting cluster information..."
#Get HDInsight info so we can get the resource group, storage, etc.
$clusterInfo = Get-AzHDInsightCluster -ClusterName $clusterName
$resourceGroup = $clusterInfo.ResourceGroup
$storageActArr=$clusterInfo.DefaultStorageAccount.split('.')
$storageAccountName=$storageActArr[0]
$storageType=$storageActArr[1]
# Progress indicator
#Define the MapReduce job
# Note: using "/mapper.exe" and "/reducer.exe" looks in the root
# of default storage.
$jobDef=New-AzHDInsightStreamingMapReduceJobDefinition `
-Files "/mapper.exe","/reducer.exe" `
-Mapper "mapper.exe" `
-Reducer "reducer.exe" `
-InputPath "/example/data/gutenberg/davinci.txt" `
-OutputPath $outputPath
# Start the job
Write-Progress -Activity $activity -Status "Starting MapReduce job..."
$job=Start-AzHDInsightJob `
-ClusterName $clusterName `
-JobDefinition $jobDef `
-HttpCredential $creds
#Wait for the job to complete
Write-Progress -Activity $activity -Status "Waiting for the job to complete..."
Wait-AzHDInsightJob `
-ClusterName $clusterName `
-JobId $job.JobId `
-HttpCredential $creds
Write-Progress -Activity $activity -Completed
# Download the output
if($storageType -eq 'azuredatalakestore') {
# Azure Data Lake Store
# Fie path is the root of the HDInsight storage + $outputPath
$filePath=$clusterInfo.DefaultStorageRootPath + $outputPath + "/part-00000"
Export-AzDataLakeStoreItem `
-Account $storageAccountName `
-Path $filePath `
-Destination output.txt
} else {
# Az.Storage account
# Get the container
$container=$clusterInfo.DefaultStorageContainer
#NOTE: This assumes that the storage account is in the same resource
# group as HDInsight. If it is not, change the
# --ResourceGroupName parameter to the group that contains storage.
$storageAccountKey=(Get-AzStorageAccountKey `
-Name $storageAccountName `
-ResourceGroupName $resourceGroup)[0].Value
#Create a storage context
$context = New-AzStorageContext `
-StorageAccountName $storageAccountName `
-StorageAccountKey $storageAccountKey
# Download the file
Get-AzStorageBlobContent `
-Blob 'example/wordcountoutput/part-00000' `
-Container $container `
-Destination output.txt `
-Context $context
}
This script prompts you for the cluster login account name and password, along with the HDInsight cluster name. Once the job completes, the output is downloaded to a file named output.txt. The following text is an example of the data in the output.txt file:
you 1128
young 38
younger 1
youngest 1
your 338
yours 4
yourself 34
yourselves 3
youth 17