Azure HDInsight highly available solution architecture case study
Azure HDInsight's replication mechanisms can be integrated into a highly available solution architecture. In this article, a fictional case study for Contoso Retail is used to explain possible high availability disaster recovery approaches, cost considerations, and their corresponding designs.
High availability disaster recovery recommendations can have many permutations and combinations. These solutions are to be arrived at after deliberating the pros and cons of each option. This article only discusses one possible solution.
Customer architecture
The following image depicts the Contoso Retail primary architecture. The architecture consists of a streaming workload, batch workload, serving layer, consumption layer, storage layer, and version control.
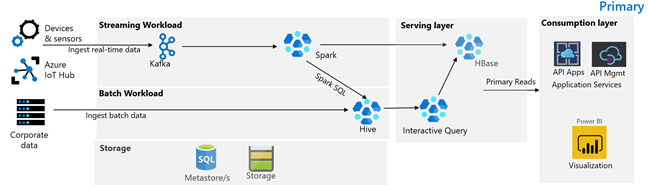
Streaming workload
Devices and sensors produce data to HDInsight Kafka, which constitutes the messaging framework. An HDInsight Spark consumer reads from the Kafka Topics. Spark transforms the incoming messages and writes it to an HDInsight HBase cluster on the serving layer.
Batch workload
An HDInsight Hadoop cluster running Hive and MapReduce ingests data from on-premises transactional systems. Raw data transformed by Hive and MapReduce is stored in Hive tables on a logical partition of the data lake backed by Azure Data Lake Storage Gen2. Data stored in Hive tables is also made available to Spark SQL, which does batch transforms before storing the curated data in HBase for serving.
Serving layer
An HDInsight HBase cluster with Apache Phoenix is used to serve data to web applications and visualization dashboards. An HDInsight LLAP cluster is used to fulfill internal reporting requirements.
Consumption layer
An Azure API Apps and API Management layer back a public facing webpage. Internal reporting requirements are fulfilled by Power BI.
Storage layer
Logically partitioned Azure Data Lake Storage Gen2 is used as an enterprise data lake. The HDInsight metastores are backed by Azure SQL DB.
Version control system
A version control system integrated into an Azure Pipelines and hosted outside of Azure.
Customer business continuity requirements
It's important to determine the minimal business functionality you'll need if there is a disaster.
Contoso Retail's business continuity requirements
- We must be protected against a regional failure or regional service health issue.
- My customers must never see a 404 error. Public content must always be served. (RTO = 0)
- For most part of the year, we can show public content that is stale by 5 hours. (RPO = 5 hours)
- During holiday season, our public facing content must always be up to date. (RPO = 0)
- My internal reporting requirements aren't considered critical to business continuity.
- Optimize business continuity costs.
Proposed solution
The following image shows Contoso Retail's high availability disaster recovery architecture.
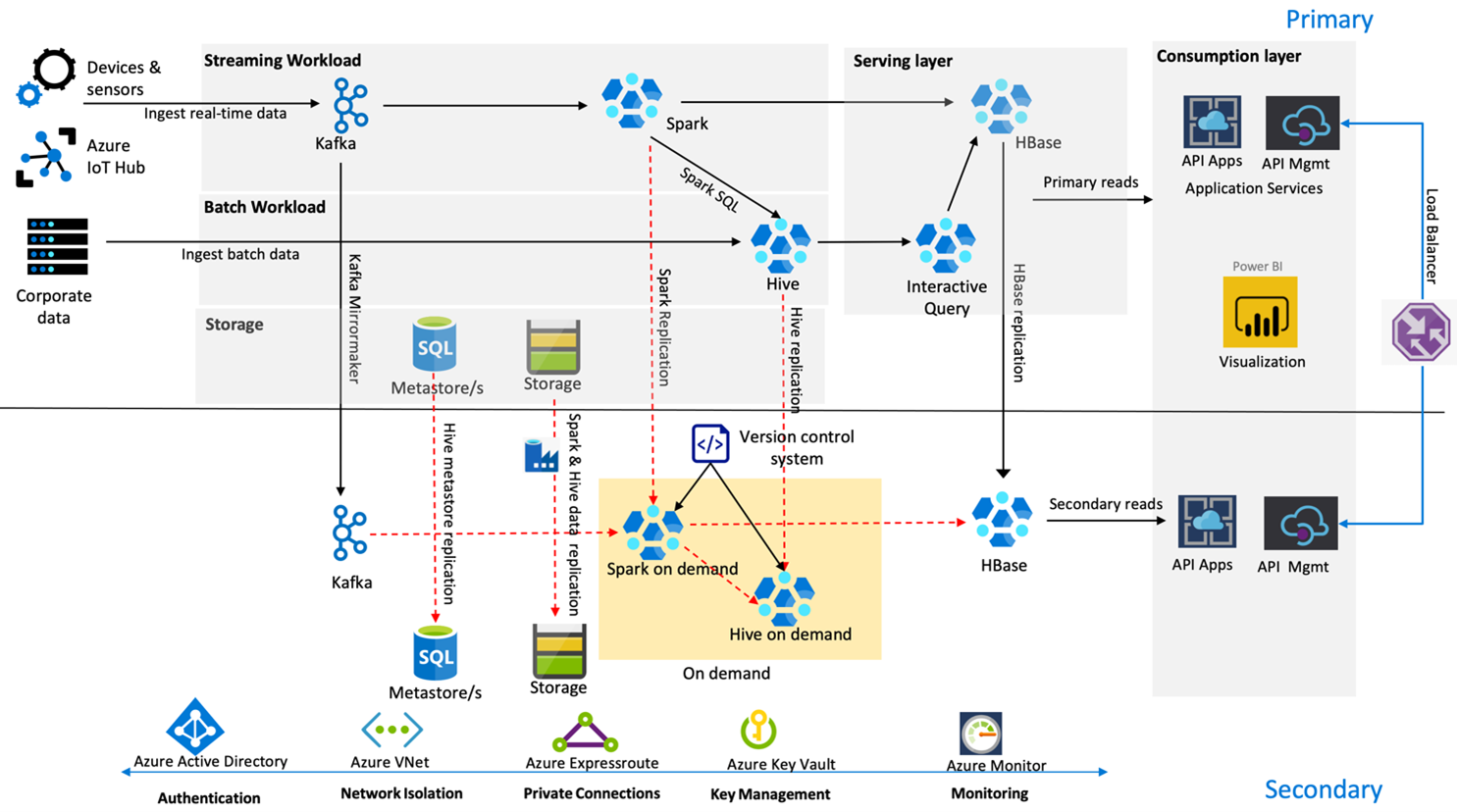
Kafka uses Active – Passive replication to mirror Kafka Topics from the primary region to the secondary region. An alternative to Kafka replication could be to produce to Kafka in both the regions.
Hive and Spark use Active Primary – On-Demand Secondary replication models during normal times. The Hive replication process runs periodically and accompanies the Hive Azure SQL metastore and Hive storage account replication. The Spark storage account is periodically replicated using ADF DistCP. The transient nature of these clusters helps optimize costs. Replications are scheduled every 4 hours to arrive at an RPO that is well within the five-hour requirement.
HBase replication uses the Leader – Follower model during normal times to ensure that data is always served regardless of the region and the RPO is very low.
If there is a regional failure in the primary region, the webpage and backend content are served from the secondary region for 5 hours with some degree of staleness. If the Azure service health dashboard does not indicate a recovery ETA in the five-hour window, the Contoso Retail will create the Hive and Spark transformation layer in the secondary region, and then point all upstream data sources to the secondary region. Making the secondary region writable would cause a failback process that involves replication back to the primary.
During a peak shopping season, the entire secondary pipeline is always active and running. Kafka producers produce to both regions and the HBase replication would be changed from Leader-Follower to Leader-Leader to ensure that public facing content is always up to date.
No failover solution needs to be designed for internal reporting since it's not critical to business continuity.
Next steps
To learn more about the items discussed in this article, see:
Palaute
Tulossa pian: Vuoden 2024 aikana poistamme asteittain GitHub Issuesin käytöstä sisällön palautemekanismina ja korvaamme sen uudella palautejärjestelmällä. Lisätietoja on täällä: https://aka.ms/ContentUserFeedback.
Lähetä ja näytä palaute kohteelle