Capacity planning for Service Fabric applications
This document teaches you how to estimate the amount of resources (CPUs, RAM, disk storage) you need to run your Azure Service Fabric applications. It is common for your resource requirements to change over time. You typically require few resources as you develop/test your service, and then require more resources as you go into production and your application grows in popularity. When you design your application, think through the long-term requirements and make choices that allow your service to scale to meet high customer demand.
When you create a Service Fabric cluster, you decide what kinds of virtual machines (VMs) make up the cluster. Each VM comes with a limited amount of resources in the form of CPUs (cores and speed), network bandwidth, RAM, and disk storage. As your service grows over time, you can upgrade to VMs that offer greater resources and/or add more VMs to your cluster. To do the latter, you must architect your service initially so it can take advantage of new VMs that get dynamically added to the cluster.
Some services manage little to no data on the VMs themselves. Therefore, capacity planning for these services should focus primarily on performance, which means selecting the appropriate CPUs (cores and speed) of the VMs. In addition, you should consider network bandwidth, including how frequently network transfers are occurring and how much data is being transferred. If your service needs to perform well as service usage increases, you can add more VMs to the cluster and load balance the network requests across all the VMs.
For services that manage large amounts of data on the VMs, capacity planning should focus primarily on size. Thus, you should carefully consider the capacity of the VM's RAM and disk storage. The virtual memory management system in Windows makes disk space look like RAM to application code. In addition, the Service Fabric runtime provides smart paging keeping only hot data in memory and moving the cold data to disk. Applications can thus use more memory than is physically available on the VM. Having more RAM simply increases performance, since the VM can keep more disk storage in RAM. The VM you select should have a disk large enough to store the data that you want on the VM. Similarly, the VM should have enough RAM to provide you with the performance you desire. If your service's data grows over time, you can add more VMs to the cluster and partition the data across all the VMs.
Determine how many nodes you need
Partitioning your service allows you to scale out your service's data. For more information on partitioning, see Partitioning Service Fabric. Each partition must fit within a single VM, but multiple (small) partitions can be placed on a single VM. So, having more small partitions gives you greater flexibility than having a few larger partitions. The trade-off is that having lots of partitions increases Service Fabric overhead and you cannot perform transacted operations across partitions. There is also more potential network traffic if your service code frequently needs to access pieces of data that live in different partitions. When designing your service, you should carefully consider these pros and cons to arrive at an effective partitioning strategy.
Let's assume your application has a single stateful service that has a store size that you expect to grow to DB_Size GB in a year. You are willing to add more applications (and partitions) as you experience growth beyond that year. The replication factor (RF), which determines the number of replicas for your service impacts the total DB_Size. The total DB_Size across all replicas is the Replication Factor multiplied by DB_Size. Node_Size represents the disk space/RAM per node you want to use for your service. For best performance, the DB_Size should fit into memory across the cluster, and a Node_Size that is around the RAM of the VM should be chosen. By allocating a Node_Size that is larger than the RAM capacity, you are relying on the paging provided by the Service Fabric runtime. Thus, your performance may not be optimal if your entire data is considered to be hot (since then the data is paged in/out). However, for many services where only a fraction of the data is hot, it is more cost-effective.
The number of nodes required for maximum performance can be computed as follows:
Number of Nodes = (DB_Size * RF)/Node_Size
Account for growth
You may want to compute the number of nodes based on the DB_Size that you expect your service to grow to, in addition to the DB_Size that you began with. Then, grow the number of nodes as your service grows so that you are not over-provisioning the number of nodes. But the number of partitions should be based on the number of nodes that are needed when you're running your service at maximum growth.
It is good to have some extra machines available at any time so that you can handle any unexpected spikes or failure (for example, if a few VMs go down). While the extra capacity should be determined by using your expected spikes, a starting point is to reserve a few extra VMs (5-10 percent extra).
The preceding assumes a single stateful service. If you have more than one stateful service, you have to add the DB_Size associated with the other services into the equation. Alternatively, you can compute the number of nodes separately for each stateful service. Your service may have replicas or partitions that aren't balanced. Keep in mind that partitions may also have more data than others. For more information on partitioning, see partitioning article on best practices. However, the preceding equation is partition and replica agnostic, because Service Fabric ensures that the replicas are spread out among the nodes in an optimized manner.
Use a spreadsheet for cost calculation
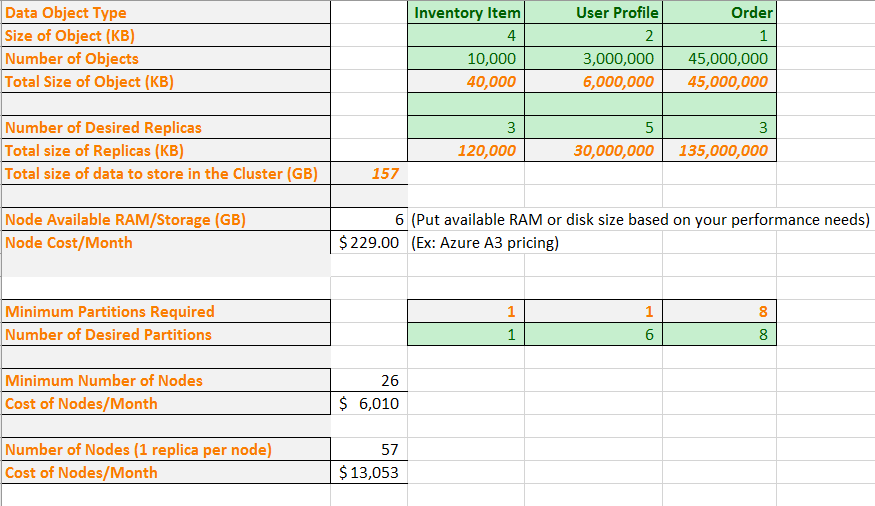
Now let's put some real numbers in the formula. An example spreadsheet shows how to plan the capacity for an application that contains three types of data objects. For each object, we approximate its size and how many objects we expect to have. We also select how many replicas we want of each object type. The spreadsheet calculates the total amount of memory to be stored in the cluster.
Then we enter a VM size and monthly cost. Based on the VM size, the spreadsheet tells you the minimum number of partitions you must use to split your data to physically fit on the nodes. You may desire a larger number of partitions to accommodate your application's specific computation and network traffic needs. The spreadsheet shows the number of partitions that are managing the user profile objects has increased from one to six.
Now, based on all this information, the spreadsheet shows that you could physically get all the data with the desired partitions and replicas on a 26-node cluster. However, this cluster would be densely packed, so you may want some additional nodes to accommodate node failures and upgrades. The spreadsheet also shows that having more than 57 nodes provides no additional value because you would have empty nodes. Again, you may want to go above 57 nodes anyway to accommodate node failures and upgrades. You can tweak the spreadsheet to match your application's specific needs.
Next steps
Check out Partitioning Service Fabric services to learn more about partitioning your service.