Apache Spark -työmäärityksen luominen Fabricissa
Tässä opetusohjelmassa opit luomaan Spark-työmäärityksen Microsoft Fabricissa.
Edellytykset
Ennen kuin aloitat, tarvitset seuraavat asiat:
- Fabric-vuokraajatili, jolla on aktiivinen tilaus. Luo ilmainen tili.
Vihje
Spark-työn määrityskohteen suorittaminen edellyttää päämääritystiedostoa ja oletuskontekstia. Jos sinulla ei ole Lakehouse-majaa, voit luoda sellaisen noudattamalla kohdassa Luo lakehouse -järvi.
Spark-työn määrityksen luominen
Spark-työn määrityksen luontiprosessi on nopea ja yksinkertainen. Voit aloittaa usealla eri tavalla.
Vaihtoehdot Spark-työn määrityksen luomiseksi
Luontiprosessin voi aloittaa muutamalla eri tavalla:
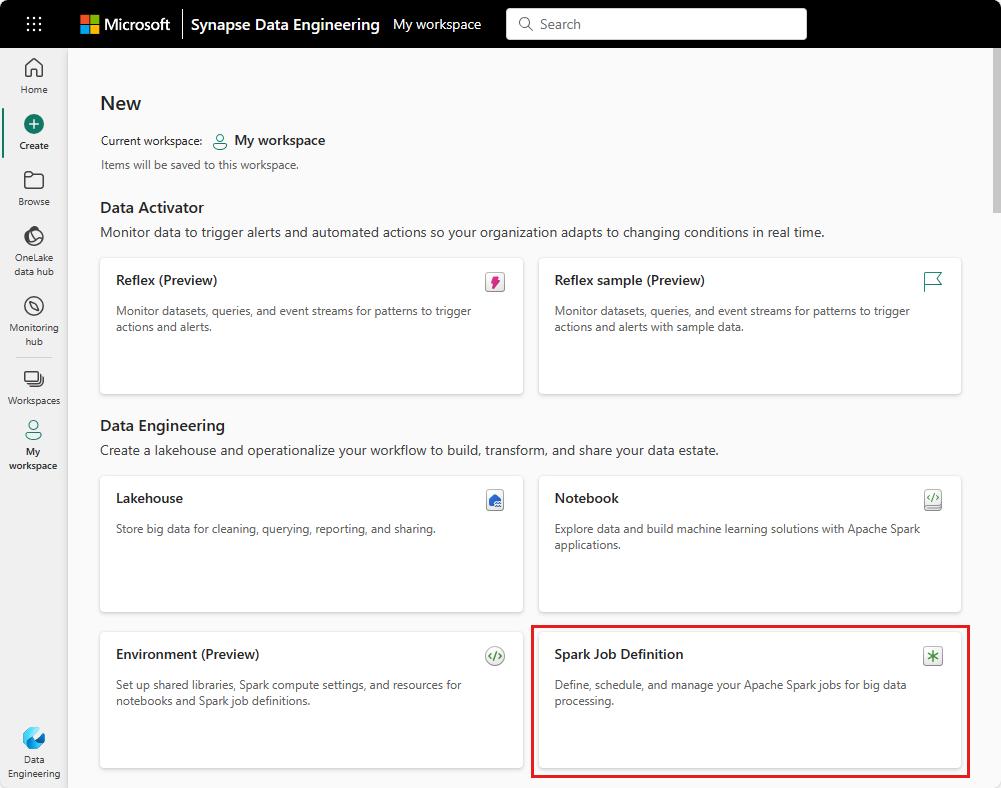
Tietotekniikan aloitussivu: Voit helposti luoda Spark-työn määrityksen spark-työn määritys -kortin kautta aloitussivun Uusi-osiossa .
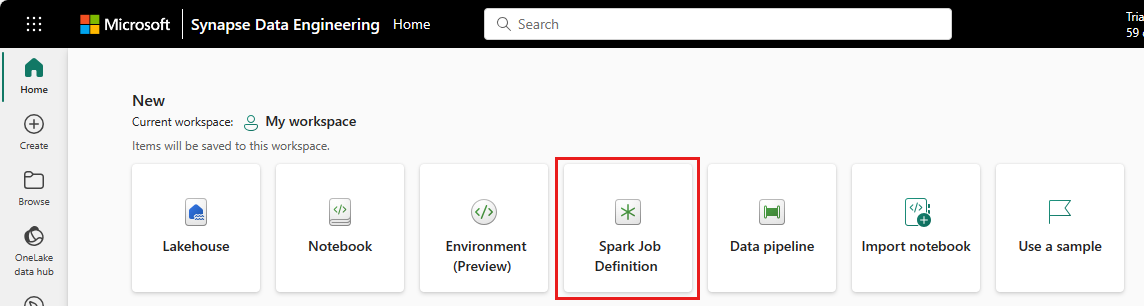
Työtilanäkymä: Voit myös luoda Spark-työn määrityksen työtilan kautta Data-asiantuntija valikkoa käyttämällä avattavaa Uusi-valikkoa.
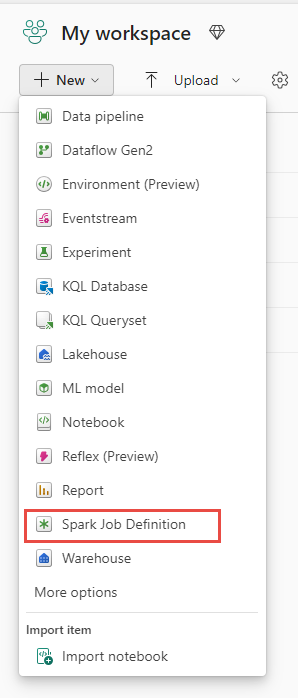
Luo näkymä: Toinen aloituskohta Spark-työn määrityksen luomiseen on Data-asiantuntija kohdassa Luo sivu.
Sinun on annettava Spark-työmääritykselle nimi, kun luot sen. Nimen on oltava yksilöivä nykyisessä työtilassa. Uusi Spark-työn määritys luodaan nykyiseen työtilaasi.
Spark-työn määrityksen luominen PySparkille (Python)
Spark-työmääritelmän luominen PySparkille:
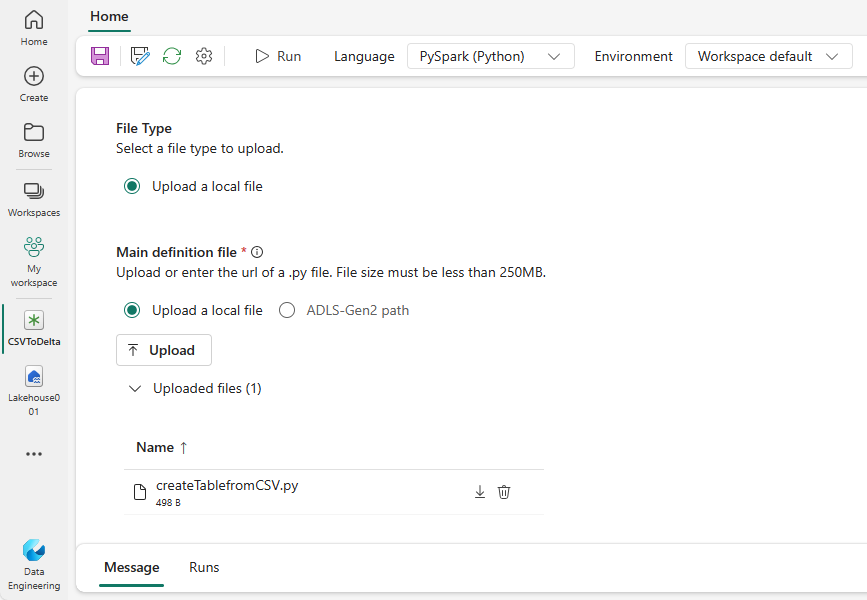
Lataa CSV-mallitiedosto yellow_tripdata_2022_01.csv ja lataa se Lakehousen tiedostot-osioon.
Luo uusi Spark-työn määritys.
Valitse PySpark (Python) avattavasta Kieli-valikosta.
Lataa createTablefromCSV.py malli ja lataa se pääasiallisena määritystiedostona. Päämääritelmätiedosto (työ. Päätiedosto) on tiedosto, joka sisältää sovelluslogiikan ja joka on pakollinen Spark-työn suorittamiseksi. Voit ladata kustakin Spark-työn määrityksestä vain yhden päämääritelmätiedoston.
Voit ladata päämääritelmätiedoston paikallisesta tietokoneesta tai voit ladata sen olemassa olevasta Azure Data Lake Tallennus (ADLS) Gen2:sta antamalla tiedoston ABFSS-polun kokonaisuudessaan. Esimerkki:
abfss://your-storage-account-name.dfs.core.windows.net/your-file-path.Lataa viitetiedostot .py tiedostoina. Viitetiedostot ovat python-moduuleja, jotka päämääritystiedosto tuo. Voit ladata sen työpöydältäsi tai aiemmin luodusta ADLS Gen2 :sta samaan tapaan kuin päämääritystiedoston. Useita viitetiedostoja tuetaan.
Vihje
Jos käytät ADLS Gen2 -polkua varmistaaksesi, että tiedosto on käytettävissä, sinun on annettava työtä suorittavalle käyttäjätilille oikeat käyttöoikeudet tallennustiliin. Suosittelemme tätä kahta eri tapaa:
- Määritä käyttäjätilille Osallistuja-rooli tallennustilille.
- Myönnä tiedoston luku- ja suoritusoikeus käyttäjätilille ADLS Gen2 Käyttöoikeuksien hallinta -luettelon (ACL) kautta.
Manuaalista suorittamista varten työn suorittamiseen käytetään nykyisen kirjautumiskäyttäjän tiliä.
Anna tarvittaessa työn komentoriviargumentit. Erota argumentit osiin käyttämällä välilyöntiä jakoperusteena.
Lisää Lakehouse-viittaus työhön. Työhön täytyy lisätä vähintään yksi Lakehouse-viittaus. Tämä lakehouse on oletus lakehouse-konteksti työlle.
Useita lakehouse-viittauksia tuetaan. Etsi lakehousen muu kuin oletusnimi ja koko OneLake-URL-osoite Spark Asetukset -sivulta.
Skalaa/Javaavan Spark-työn määrityksen luominen
Skalaa/Javaavan Spark-työn määrityksen luominen:
Luo uusi Spark-työn määritys.
Valitse Spark(Scala/Java) avattavasta Kieli-valikosta.
Lataa päämääritystiedosto .jar tiedostona. Tärkein määritystiedosto on tiedosto, joka sisältää tämän työn sovelluslogiikan ja joka on pakollinen Spark-työn suorittamiseksi. Voit ladata kustakin Spark-työn määrityksestä vain yhden päämääritelmätiedoston. Anna Pääluokan nimi.
Lataa viitetiedostot .jar tiedostoina. Viitetiedostot ovat tiedostoja, joihin päämääritelmätiedosto viittaa/tuodaan.
Anna tarvittaessa työn komentoriviargumentit.
Lisää Lakehouse-viittaus työhön. Työhön täytyy lisätä vähintään yksi Lakehouse-viittaus. Tämä lakehouse on oletus lakehouse-konteksti työlle.
Spark-työn määrityksen luominen R:lle
SparkR(R)-työn määrityksen luominen:
Luo uusi Spark-työn määritys.
Valitse SparkR(R) avattavasta Kieli-valikosta.
Lataa päämääritystiedosto nimellä . R-tiedosto . Tärkein määritystiedosto on tiedosto, joka sisältää tämän työn sovelluslogiikan ja joka on pakollinen Spark-työn suorittamiseksi. Voit ladata kustakin Spark-työn määrityksestä vain yhden päämääritelmätiedoston.
Lataa viitetiedostot nimellä . R-tiedostot . Viitetiedostot ovat tiedostoja, joihin päämääritelmätiedosto viittaa/tuodaan.
Anna tarvittaessa työn komentoriviargumentit.
Lisää Lakehouse-viittaus työhön. Työhön täytyy lisätä vähintään yksi Lakehouse-viittaus. Tämä lakehouse on oletus lakehouse-konteksti työlle.
Muistiinpano
Spark-työn määritys luodaan nykyiseen työtilaasi.
Vaihtoehdot Spark-työn määritelmien mukauttamiseen
Spark-työmääritysten suorittamista voidaan mukauttaa edelleen muutamilla eri vaihtoehdoilla.
- Spark Compute: Spark Compute -välilehdessä näet Runtime-version , joka on työn suorittamiseen käytettävä Spark-versio. Näet myös Spark-määritysasetukset, joita käytetään työn suorittamiseen. Voit mukauttaa Spark-määritysasetuksia napsauttamalla Lisää-painiketta.
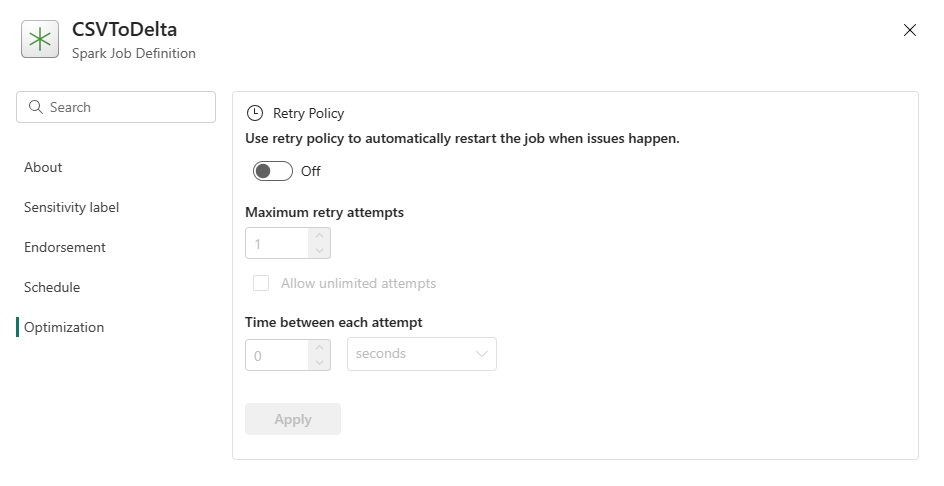
Optimointi: Optimointi-välilehdessä voit ottaa käyttöön ja määrittää työn uudelleenyritysten käytännön . Kun se on käytössä, työtä yritetään uudelleen, jos se epäonnistuu. Voit myös määrittää uudelleenten enimmäismäärän ja uudelleenlyöntien välisen välin. Kunkin uudelleenyritysyrityksen työ käynnistetään uudelleen. Varmista, että työ on idempotenttia.
Liittyvä sisältö
Palaute
Tulossa pian: Vuoden 2024 aikana poistamme asteittain GitHub Issuesin käytöstä sisällön palautemekanismina ja korvaamme sen uudella palautejärjestelmällä. Lisätietoja on täällä: https://aka.ms/ContentUserFeedback.
Lähetä ja näytä palaute kohteelle