Muistiinpano
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
Tässä pikaoppaassa kerrotaan, miten voit luoda Spark-työmääritelmän, joka sisältää Python-koodin Spark-rakenteisen suoratoiston avulla tietojen tuomiseksi Lakehouseen, ja tarjota sitten sen SQL-analytiikan päätepisteen kautta. Kun olet suorittanut tämän pikaoppaan, sinulla on Spark Job -määritys, jota suoritetaan jatkuvasti ja SQL-analytiikan päätepiste voi tarkastella saapuvia tietoja.
Python-komentosarjan luominen
Seuraavan Python-komentosarjan avulla voit luoda suoratoisto-Delta-taulukon Lakehousessa Apache Sparkin avulla. Komentosarja lukee luotujen tietojen virran (yksi rivi sekunnissa) ja kirjoittaa sen liittämistilassa Delta-taulukkoon nimeltä streamingtable. Se tallentaa tiedot ja tarkistuspisteen tiedot määritettyyn lakehouse-järjestelmään.
Käytä seuraavaa Python-koodia, joka käyttää Spark-jäsennettyä suoratoistoa tietojen noutamiseen Lakehouse-taulukosta.
from pyspark.sql import SparkSession if __name__ == "__main__": # Start Spark session spark = SparkSession.builder \ .appName("RateStreamToDelta") \ .getOrCreate() # Table name used for logging tableName = "streamingtable" # Define Delta Lake storage path deltaTablePath = f"Tables/{tableName}" # Create a streaming DataFrame using the rate source df = spark.readStream \ .format("rate") \ .option("rowsPerSecond", 1) \ .load() # Write the streaming data to Delta query = df.writeStream \ .format("delta") \ .outputMode("append") \ .option("path", deltaTablePath) \ .option("checkpointLocation", f"{deltaTablePath}/_checkpoint") \ .start() # Keep the stream running query.awaitTermination()Tallenna komentosarja Python-tiedostona (.py) paikallisessa tietokoneessa.
Luo lakehouse
Voit luoda Lakehousen seuraavien vaiheiden avulla:
Kirjaudu sisään Microsoft Fabric -portaalin.
Siirry haluamaasi työtilaan tai luo uusi tarvittaessa.
Jos haluat luoda lakehousen, valitse työtilasta Uusi kohde ja valitse sitten avautuvasta paneelista Lakehouse .
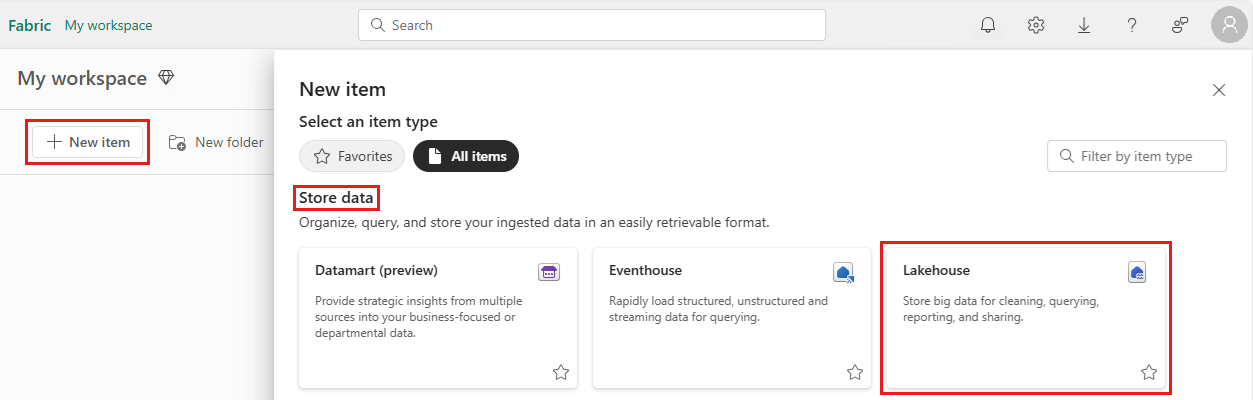
Kirjoita lakehousen nimi ja valitse Luo.

Spark-työn määrityksen luominen
Seuraavien vaiheiden avulla voit luoda Spark-työn määrityksen:
Valitse samasta työtilasta, jossa loit lakehousen, Uusi kohde.
Valitse avautuvan paneelin Nouda tiedot -kohdassa Spark-työn määritys.
Kirjoita Spark-työmäärityksen nimi ja valitse Luo.
Valitse Lataa ja valitse edellisessä vaiheessa luomasi Python-tiedosto.
Valitse Lakehouse-viite-kohdasta luomasi lakehouse.
Määritä Spark-työn määrityksen uudelleenyritysten käytäntö
Määritä Uudelleenyritysten käytäntö Spark-työmääritykselle seuraavien vaiheiden avulla:
Valitse ylävalikosta Asetus-kuvake .
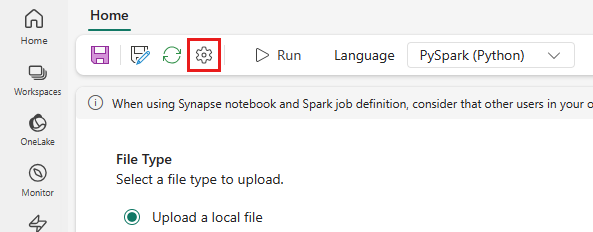
Avaa Optimointi-välilehti ja aseta Yritä uudelleen -käytäntökäynnistimentilalle Käytössä.
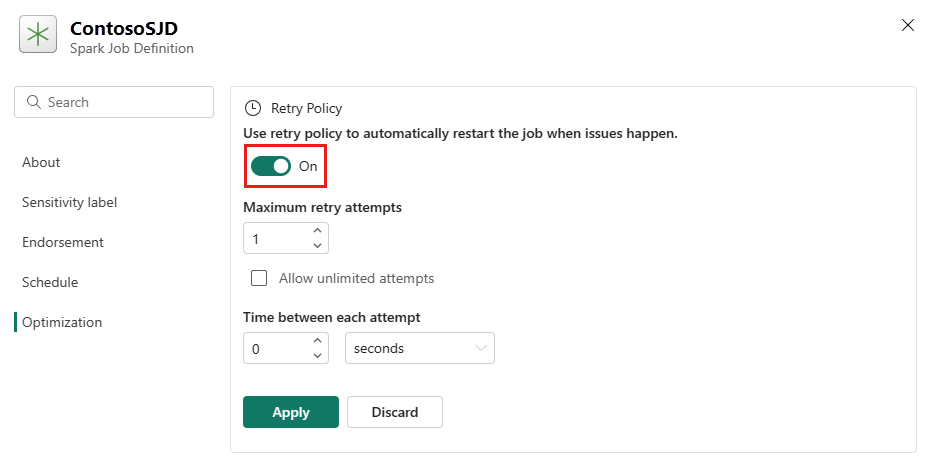
Määritä uudelleenyritysten enimmäismäärä tai valitse Salli rajoittamattomat yritykset.
Määritä kunkin uudelleenyrityksen välinen aika ja valitse Käytä.


Note
Uudelleenyritysten käytännön määrityksen elinkaarirajoitus on 90 päivää. Kun uudelleenyritysten käytäntö on käytössä, työ käynnistetään uudelleen käytännön mukaisesti 90 päivän kuluessa. Tämän jakson jälkeen uudelleenyritysten käytäntö lakkaa automaattisesti toimimasta, ja työ lopetetaan. Käyttäjien on sen jälkeen käynnistettävä työ manuaalisesti uudelleen, jolloin uudelleenyritysten käytäntö otetaan uudelleen käyttöön.
Spark Job -määritelmän suorittaminen ja valvonta
Valitse ylävalikosta Suorita-kuvake .
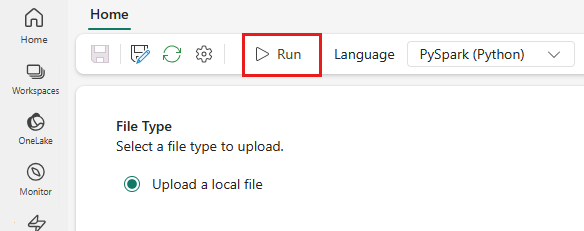
Varmista, että Spark Job - määritys on lähetetty onnistuneesti ja että sen suorittaminen onnistui.

Tietojen tarkasteleminen SQL-analytiikan päätepisteen avulla
Kun komentosarja on suoritettu, lakehouseen luodaan taulukko nimeltä streamingtable, jossa on aikaleima- ja arvosarakkeet . Voit tarkastella tietoja SQL-analytiikan päätepisteen avulla:
Avaa Lakehouse työtilasta.
Vaihda SQL Analytics -päätepisteeseen oikeasta yläkulmasta.
Laajenna vasemmassa siirtymisruudussa Rakenteet-dbo-taulukot >>, valitse streamingtable tietojen esikatselua varten.