Muistiinpano
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
Microsoft Fabric on integroitu analytiikkapalvelu, joka nopeuttaa tietovarastojen ja massadatajärjestelmien merkityksellisiä tietoja. Muistikirjojen tietojen visualisointi on tärkeä ominaisuus, jonka avulla voit saada merkityksellisiä tietoja, joiden avulla käyttäjät voivat tunnistaa malleja, trendejä ja poikkeavia arvoja helposti.
Kun työskentelet Apache Sparkin kanssa Fabricissa, sinulla on valmiita vaihtoehtoja tietojen visualisointiin, mukaan lukien Fabric-muistikirjakaavio-ominaisuudet ja pääsy suosittuihin avoimen lähdekoodin kirjastoihin.
Kangasmuistikirjojen avulla voit myös muuntaa taulukkomuotoisia tuloksia mukautetuiksi kaavioiksi kirjoittamatta koodia, mikä takaa entistä intuitiivisemman ja saumattoman tietojen tarkastelukokemuksen.
Sisäinen visualisointikomento – display()-funktio
Fabric-in-visualisointifunktion avulla voit muuntaa Apache Spark DataFrames-, Pandas DataFrames- ja SQL-kyselytulokset monipuolisiksi ja vuorovaikutteisiksi tietojen visualisoinneiksi.
Näyttöfunktiolla voit hahmontaa PySparkin ja Scala Spark DataFramesin tai sitkeät hajautetut tietojoukot dynaamisiksi taulukoiksi tai kaavioiksi.
Voit määrittää hahmonnetun tietokehyksen rivimäärän. Oletusarvo on 1 000

Voit käyttää yleisen työkalurivin suodatinfunktiota mukautettujen sääntöjen käyttämiseksi tiedoissasi. Suodatinehtoa käytetään tiettyyn sarakkeeseen, ja tulokset näkyvät sekä taulukko- että kaavionäkymissä.

SQL-lausekkeen tuloste käyttää samaa tulostepienoissovellusta, jossa on oletusarvoisesti display().
Rich dataframe -taulukkonäkymä
Vapaan valinnan tuki taulukkonäkymässä
Taulukkonäkymä hahmonnetaan oletusarvoisesti, kun käytetään Display()-komentoa Fabric-muistikirjassa. Monipuolisessa tietokehyksen esikatselussa on intuitiivinen ilmainen valintatoiminto, joka on suunniteltu parantamaan tietojen analysointikokemusta ottamalla käyttöön joustavia ja vuorovaikutteisia valintavaihtoehtoja. Tämän ominaisuuden avulla käyttäjät voivat siirtyä tietokehyksiin ja tutustua niihin tehokkaasti.
sarakkeen valinnan
- Yhden sarakkeen: Valitse koko sarake napsauttamalla sarakeotsikkoa.
- Useita sarakkeita -: Kun olet valinnut yksittäisen sarakkeen, pidä vaihto-näppäintä painettuna ja valitse sitten useita sarakkeita napsauttamalla toista sarakeotsikkoa.
rivin valinnan
- Yksi rivi -: Valitse koko rivi napsauttamalla riviotsikkoa.
- Useita rivejä: Kun olet valinnut yksittäisen rivin, pidä vaihto-näppäintä painettuna ja valitse sitten useita rivejä napsauttamalla toista riviotsikkoa.
Solun sisällön esikatselu: Esikatsele yksittäisten solujen sisältöä, jotta voit tarkastella tietoja nopeasti ja yksityiskohtaisesti ilman, että sinun tarvitsee kirjoittaa lisäkoodia.
sarakeyhteenveto: Saat yhteenvedon kustakin sarakkeesta, mukaan lukien tiedonjakauman ja tärkeimmät tilastotiedot, jotta voit nopeasti ymmärtää tietojen ominaisuudet.
Vapaan alueen valinta -: Valitse mikä tahansa taulukon jatkuva segmentti, jotta saat yleiskatsauksen valittujen solujen kokonaismäärästä ja valitun alueen numeerisista arvoista.
Valitun sisällön kopioiminen: Kaikissa valintatapauksissa voit kopioida valitun sisällön nopeasti Ctrl + C -pikanäppäimen avulla. Valitut tiedot kopioidaan CSV-muodossa, mikä helpottaa käsittelemistä muissa sovelluksissa.
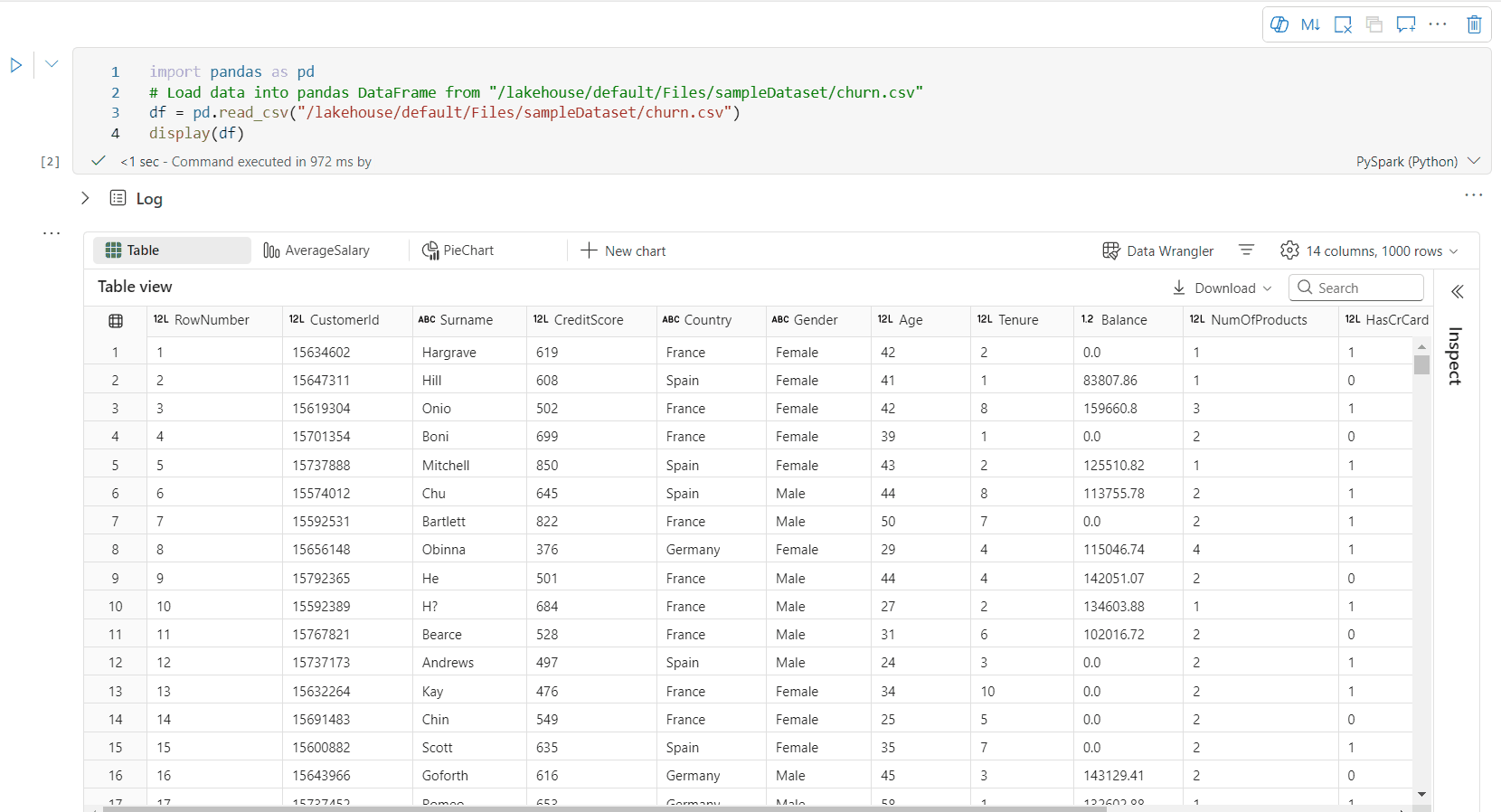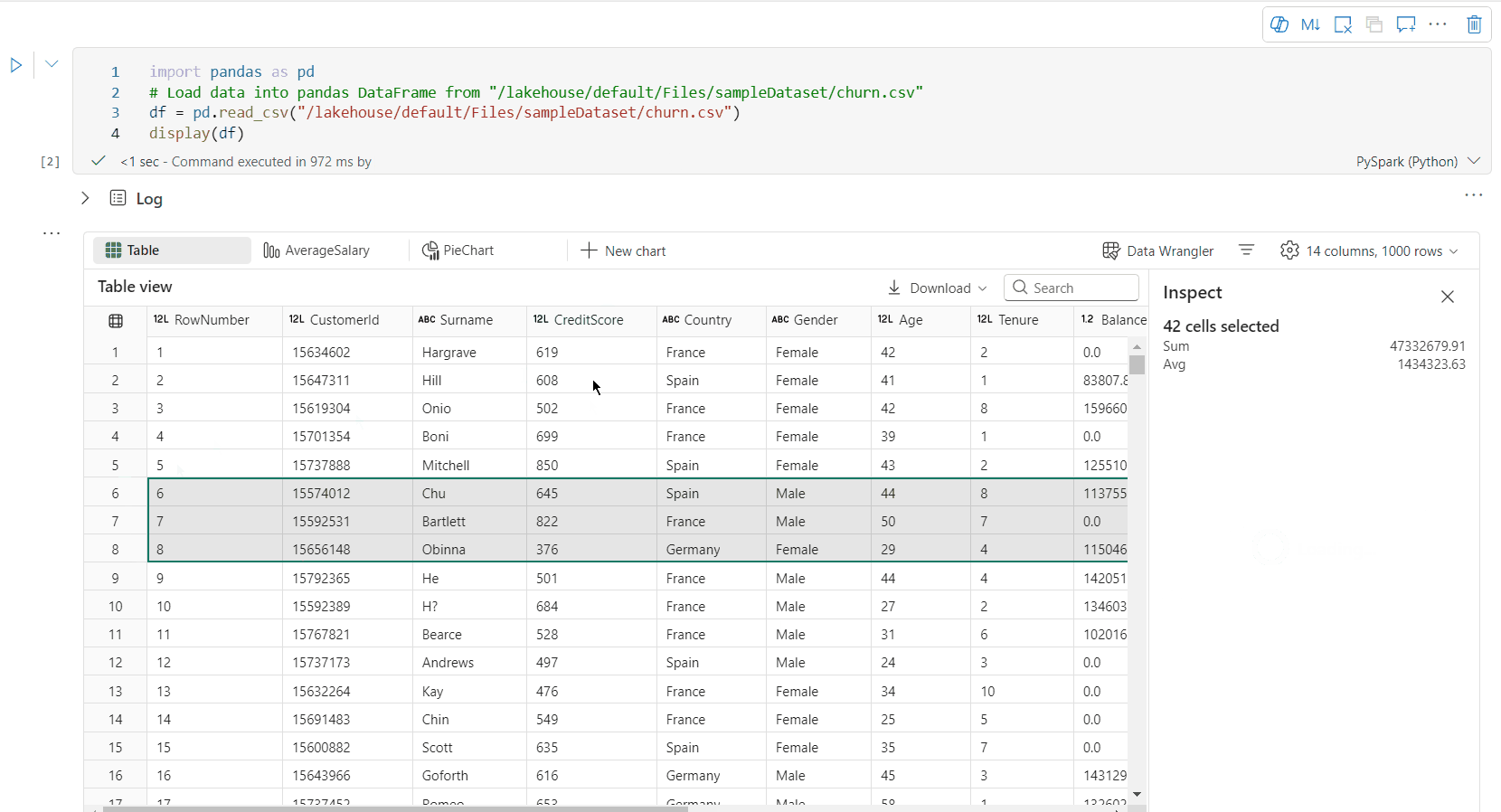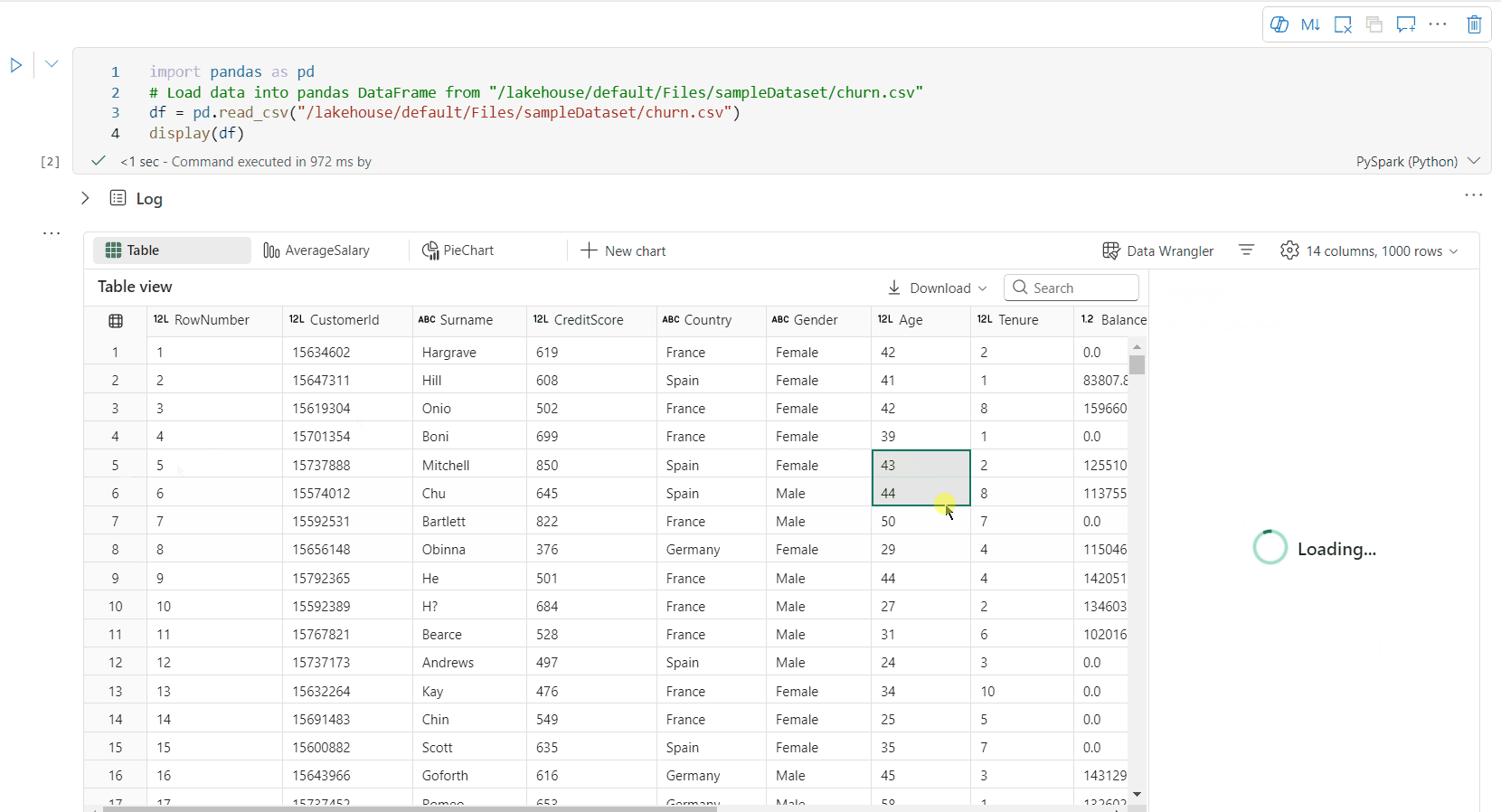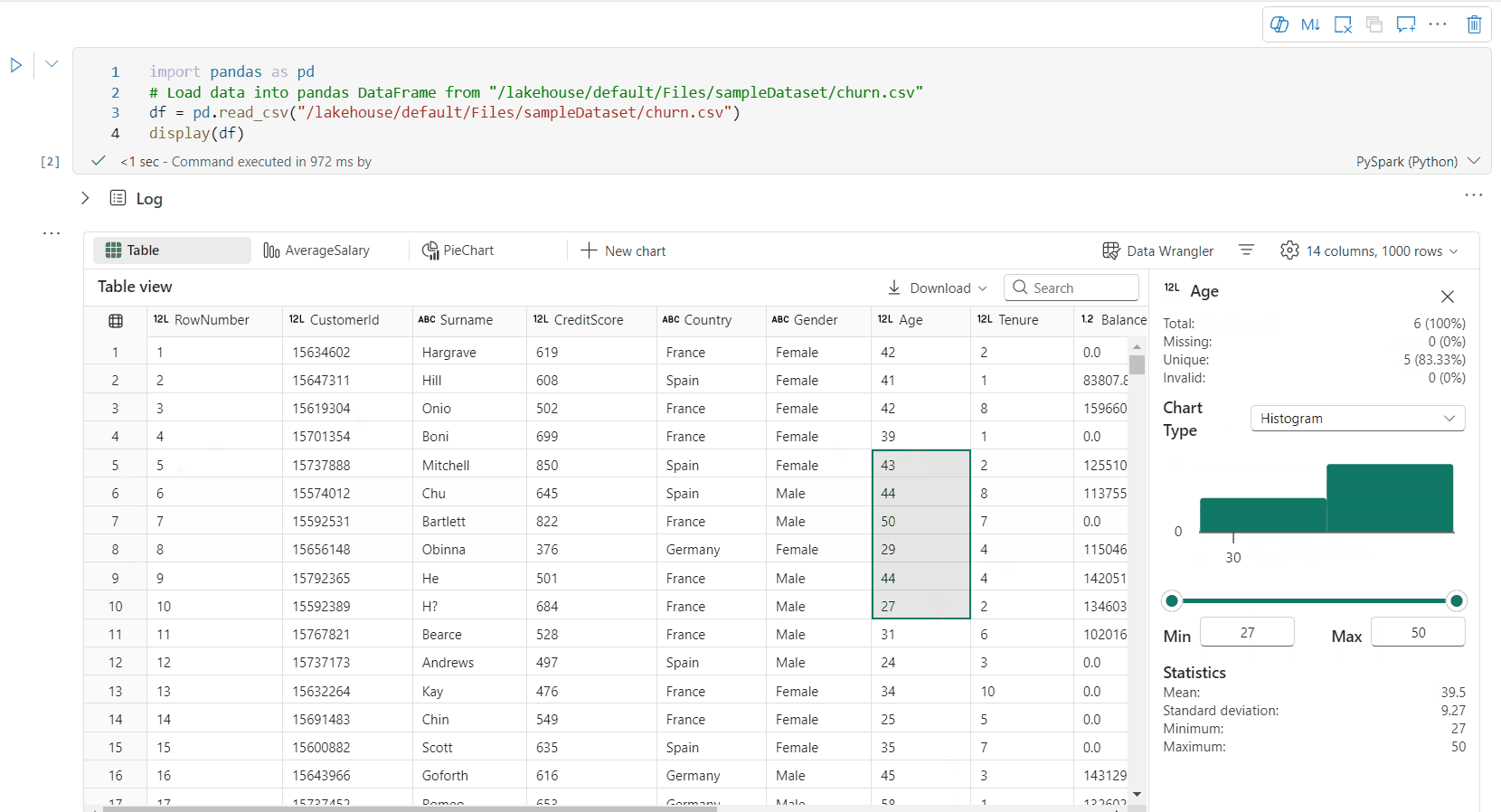

Tietojen profiloinnin tuki Tarkistus-ruudun kautta

Voit profiloida tietokehyksen napsauttamalla Tarkista-painiketta. Se tarjoaa tietojen yhteenvedon jakauman ja näyttää kunkin sarakkeen tilastotiedot.
Jokainen Tarkasta-puolen ruudun kortti yhdistää tietokehyksen sarakkeeseen. Voit tarkastella lisätietoja napsauttamalla korttia tai valitsemalla sarakkeen taulukosta.
Voit tarkastella solun tietoja napsauttamalla taulukon solua. Tästä ominaisuudesta on hyötyä, kun tietokehys sisältää pitkän merkkijonotyypin sisältöä.
Parannettu rich dataframe -kaavionäkymä
Display()-komennon parannettu kaavionäkymä tarjoaa entistä intuitiivisemman ja dynaamisemman tavan tietojen visualisointiin.
Avainparannukset:
Usean kaavion tuki: Lisää enintään viisi kaaviota yksittäiseen display() -tulostepienoissovellukseen valitsemalla Uusi kaavio, mikä helpottaa vertailua eri sarakkeissa.
Älykkään kaavion suositukset: Hanki ehdotettujen kaavioiden luettelo DataFramen perusteella. Valitse muokkaa suositeltua visualisointia tai luo mukautettu kaavio alusta alkaen.

Joustava mukauttaminen: Mukauta visualisointeja valitun kaaviotyypin mukaan mukautuvalla säädettävissä olevalla asetuksilla.
Luokka Perusasetukset Kuvaus Kaaviotyyppi Näyttöfunktio tukee monenlaisia kaaviotyyppejä, kuten palkkikaavioita, pistekaavioita, viivakaavioita ja pivot-taulukoita. Nimike Nimike Kaavion otsikko. Nimike Tekstitys Lisää kuvauksia sisältävän kaavion alaotsikko. Tiedot X-akseli Määritä kaavion avain. Tiedot Y-akseli Määritä kaavion arvot. Selite Näytä selite Ota selite käyttöön tai poista se käytöstä. Selite Asema Mukauta selitteen sijaintia. Muu Sarjaryhmä Tämän määrityksen avulla voit määrittää koosteen ryhmät. Muu Yhdistäminen Tämän menetelmän avulla voit koostaa tietoja visualisoinnissa. Muu Pinottu Määritä tuloksen näyttötyyli. Muu Puuttuvat ja tyhjäarvot Määritä, miten puuttuvat tai tyhjäarvot näytetään. Muistiinpano
Lisäksi voit määrittää näytettävien rivien määrän, ja oletusasetus on 1 000. Muistikirjan näyttötulostepienoissovellus tukee jopa 10 000 rivin DataFramen tarkastelemista ja profilointia. Valitse Koosta kaikille tuloksille ja valitse sitten Käytä , jos haluat ottaa käyttöön kaavion luonnin koko tietokehyksestä. Spark-työ käynnistyy, kun kaavion asetus muuttuu. Laskennan viimeisteleminen ja kaavion hahmontaminen voi kestää useita minuutteja.
Luokka Lisäasetukset Kuvaus Väri Teema Määritä kaavion teemavärijoukko. X-akseli Otsikko Määritä X-akselin nimi. X-akseli Mittakaava Määritä X-akselin skaalausfunktio. X-akseli Alue Määritä arvoalue X-akseli. Y-akseli Otsikko Määritä Y-akselin nimi. Y-akseli Mittakaava Määritä Y-akselin skaalausfunktio. Y-akseli Alue Määritä arvoalue Y-akseli. Näyttö Näytä selitteet Näytä tai piilota tulosotsikot kaaviossa. Määritysten muutokset tulevat voimaan heti ja kaikki määritykset tallennetaan automaattisesti muistikirjan sisältöön.
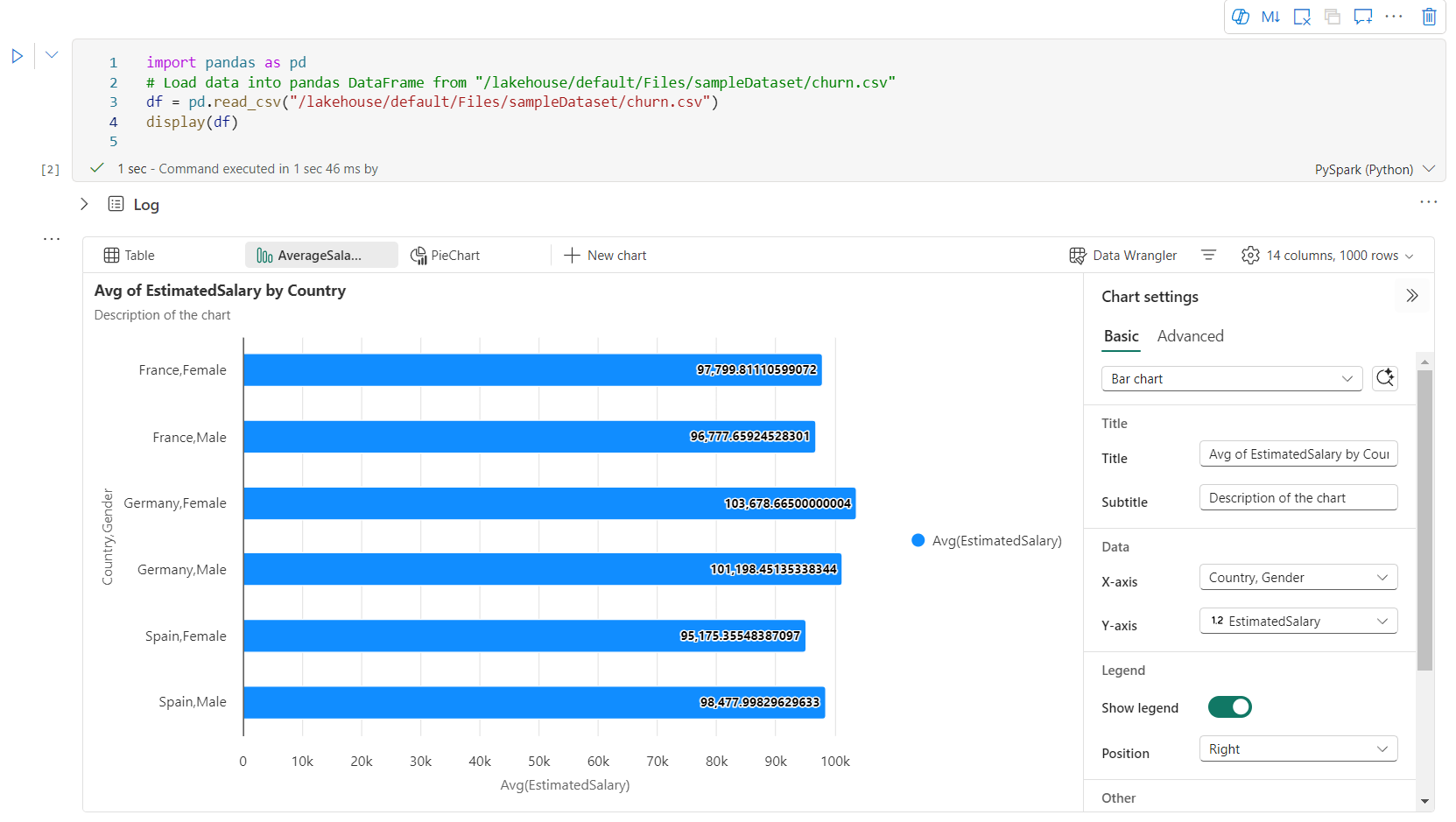
Voit helposti nimetä uudelleen, monistaa, poistaa tai siirtää kaavioita kaavion välilehtivalikossa. Voit myös järjestää niitä uudelleen vetämällä ja pudottamalla välilehtiä. Ensimmäinen välilehti näkyy oletusarvona, kun muistikirja avataan.
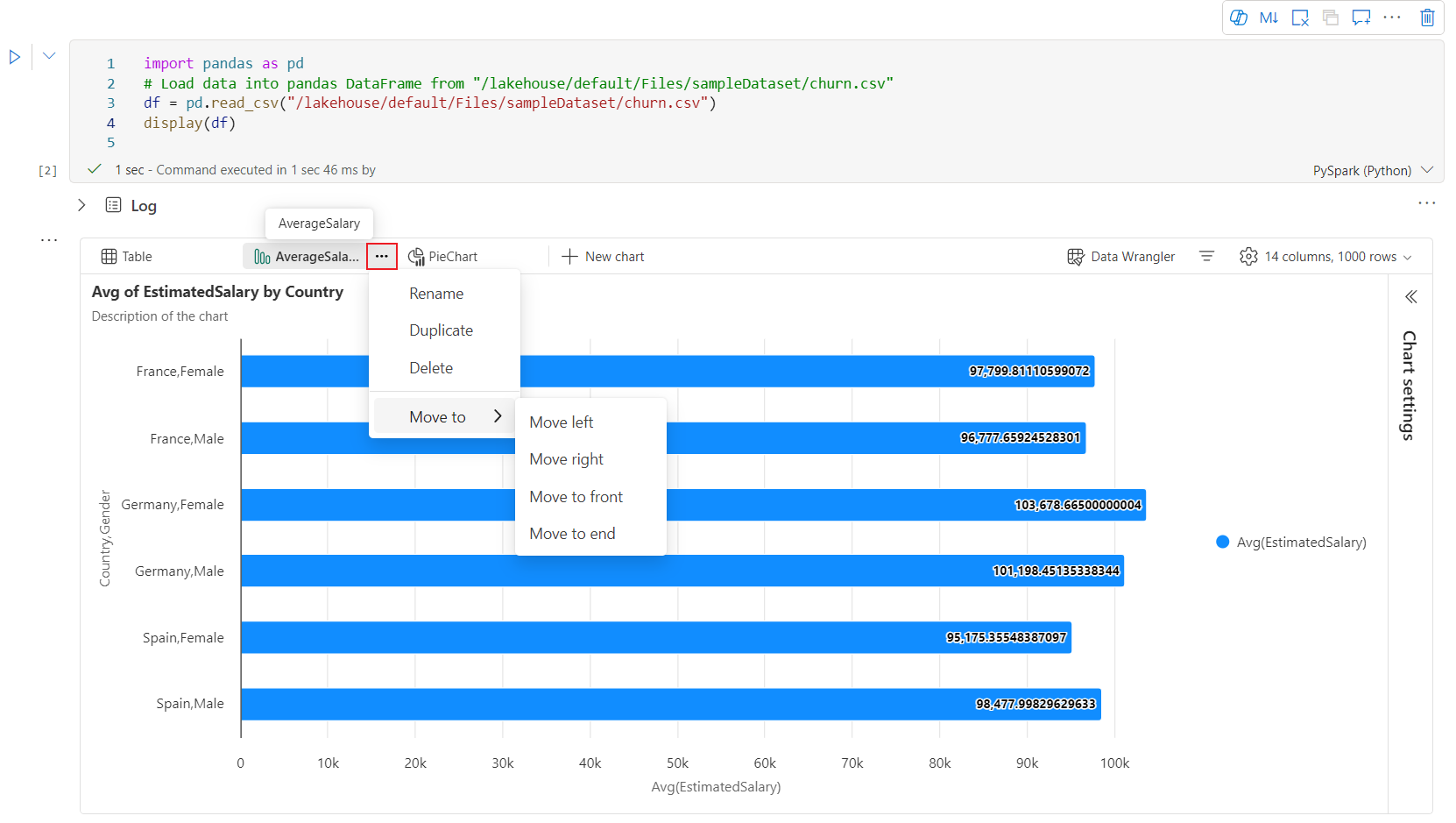
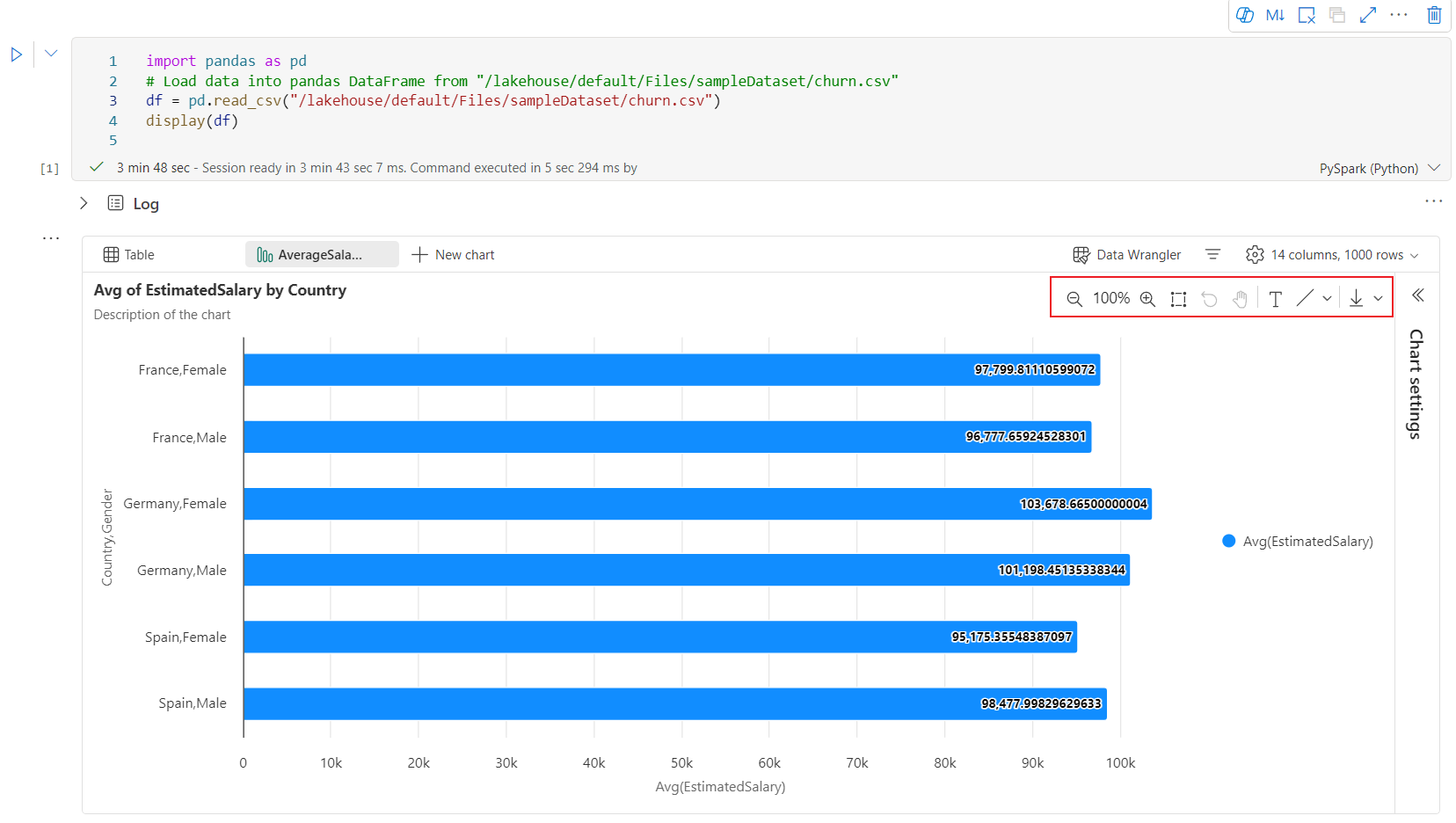
Vuorovaikutteinen työkalurivi on käytettävissä uudessa kaaviossa, kun käyttäjä siirtää hiiren osoittimen kaavion päälle. Tukitoiminnot, kuten lähentäminen, loitontaminen, zoomaus, nollaaminen, panorointi, huomautuksen muokkaus jne.
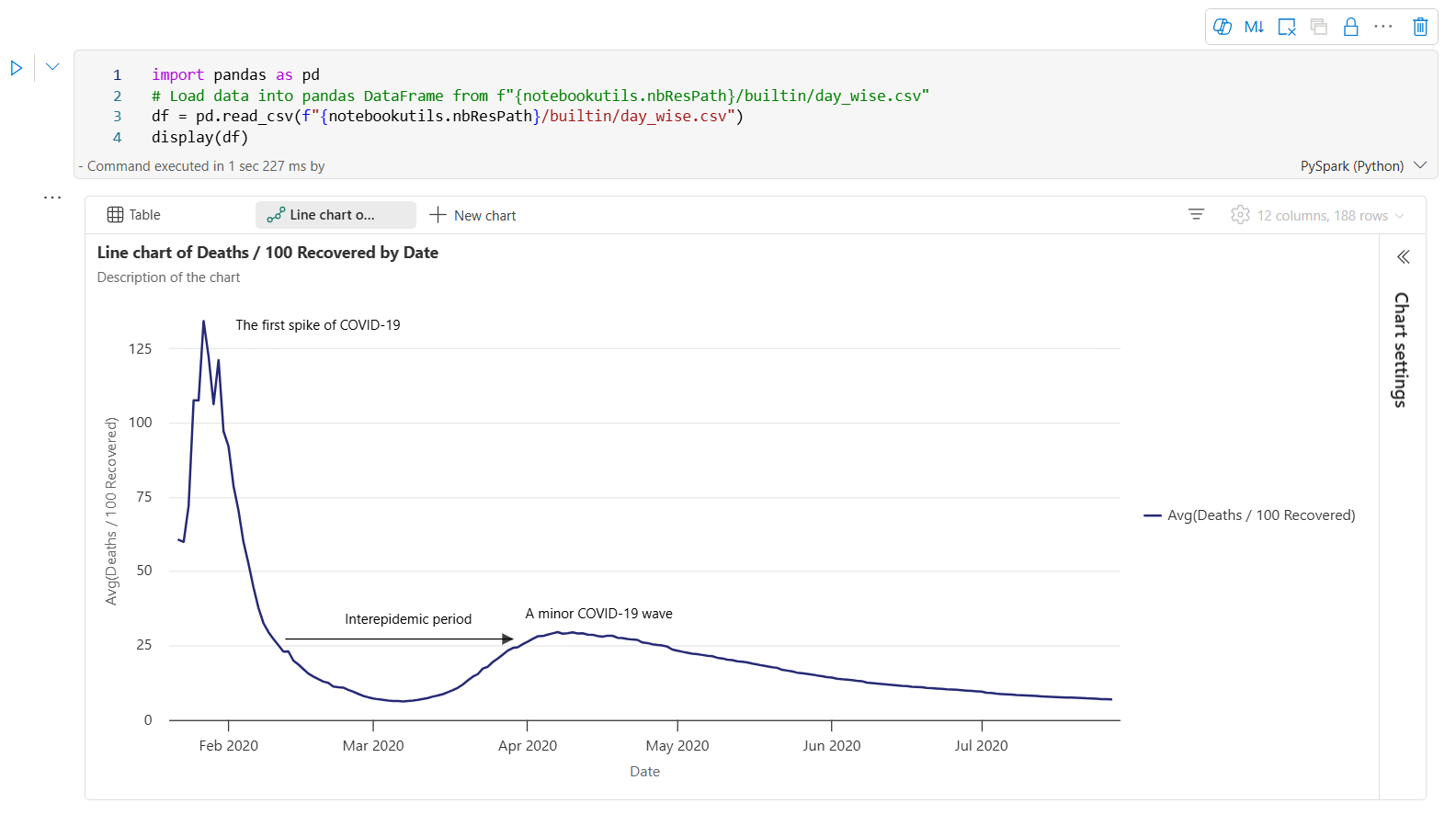
Tässä on esimerkki kaaviomerkinnästä.




display()-yhteenvetonäkymä
Käytä display(df, summary = true) tietyn Apache Spark DataFrame -kehyksen tilastoyhteenvedon tarkistamiseen. Yhteenveto sisältää sarakkeen nimen, saraketyypin, yksilölliset arvot ja puuttuvat arvot kullekin sarakkeelle. Voit myös valita tietyn sarakkeen nähdäksesi sen vähimmäisarvon, enimmäisarvon, keskiarvon ja keskihajonnan.

displayHTML()-vaihtoehto
Fabric-muistikirjat tukevat HTML-grafiikkaa displayHTML-funktion avulla.
Seuraava kuva on esimerkki visualisointien luomisesta D3.js avulla.

Voit luoda tämän visualisoinnin suorittamalla seuraavan koodin.
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
Power BI -raportin upottaminen muistikirjaan
Powerbiclient Python -pakettia tuetaan nyt suoraan Fabric-muistikirjoissa. Sinun ei tarvitse tehdä lisäasetuksia (kuten todennusprosessia) Fabric-muistikirja spark runtime 3.4:ssä.
powerbiclient Tuo se ja jatka sitten tutkimista. Lisätietoja powerbiclient-paketin käytöstä on powerbiclient-dokumentaatiossa.
Powerbiclient tukee seuraavia avainominaisuuksia.
Olemassa olevan Power BI -raportin hahmontaminen
Voit helposti upottaa ja käsitellä Power BI -raportteja muistikirjoissasi vain muutamalla koodirivillä.
Seuraava kuva on esimerkki olemassa olevan Power BI -raportin hahmontamisesta.

Hahmonna olemassa oleva Power BI -raportti suorittamalla seuraava koodi.
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Raportin visualisointien luominen Spark DataFramesta
Voit luoda nopeasti oivaltavia visualisointeja muistikirjasi Spark DataFramen avulla. Voit myös valita Tallenna upotetussa raportissa luodaksesi raporttikohteen kohdetyötilaan.
Seuraavassa kuvassa on esimerkki QuickVisualize() Spark DataFrame -kehyksestä.

Suorita seuraava koodi, jotta voit hahmontaa raportin Spark DataFramesta.
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
Raportin visualisointien luominen pandas DataFrame -kehyksestä
Voit myös luoda pandas DataFrame -kehykseen perustuvia raportteja muistikirjassa.
Seuraava kuva on esimerkki QuickVisualize() pandas DataFrame -kehyksestä.

Suorita seuraava koodi, jotta voit hahmontaa raportin Spark DataFramesta.
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
Suositut kirjastot
Tietojen visualisoinnin osalta Python tarjoaa useita kaaviokirjastoja, jotka ovat täynnä monia eri ominaisuuksia. Oletuksena jokainen Fabricin Apache Spark -allas sisältää joukon valittuja ja suosittuja avoimen lähdekoodin kirjastoja.
Matplotlib
Voit hahmontaa vakiopiirtokirjastoja, kuten Matplotlib, käyttämällä kunkin kirjaston sisäisiä hahmontamisfunktioita.
Seuraava kuva on esimerkki palkkikaavion luomisesta Matplotlib-toiminnolla.


Piirrä tämä palkkikaavio suorittamalla seuraava mallikoodi.
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
Bokeh
Voit hahmontaa HTML- tai vuorovaikutteisia kirjastoja (esimerkiksi bokeh) käyttämällä displayHTML(df) -parametria.
Seuraava kuva on esimerkki glyfien piirtämisestä kartan ylle bokeh-toiminnolla.

Jos haluat piirtää tämän kuvan, suorita seuraava mallikoodi.
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Kaavio
Voit hahmontaa HTML-kirjastoja tai vuorovaikutteisia kirjastoja, kuten Plotly, käyttämällä displayHTML()-tiedostoa.
Jos haluat piirtää tämän kuvan, suorita seuraava mallikoodi.

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Pandas
Voit tarkastella pandas DataFrame -tietojen HTML-tulostetta oletustulosteena. Kangasmuistikirjoissa näytetään automaattisesti tyylitelty HTML-sisältö.

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df