Muistiinpano
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
Microsoft Fabric mahdollistaa machine learning-mallien operationalisoimisen skaalautuvan PREDICT-funktion avulla. Tämä funktio tukee erän pisteytystä missä tahansa laskentamoduulissa. Voit luoda eräennusteita suoraan Microsoft Fabric -muistikirjasta tai tietyn koneoppimismallin tehtäväsivulta.
Tässä artikkelissa opit käyttämään PREDICT-funktiota kirjoittamalla koodin itse tai käyttämällä ohjattua käyttöliittymäkokemusta, joka käsittelee erän pisteytyksen puolestasi.
Edellytykset
Hanki Microsoft Fabric-tilaus. Tai tilaa ilmainen Microsoft Fabric kokeilujakso.
Kirjaudu sisään Microsoft Fabric.
Vaihda Fabric-tilaan käyttämällä etusivun vasemmassa alakulmassa olevaa kokemuskytkintä.

Rajoitukset
- PREDICT-funktio tukee tällä hetkellä vain seuraavia ML-mallin muotoja:
- CatBoost
- Keras
- Vaalea Gtm
- ONNX
- Profeetta
- PyTorch
- Sklearn
- Spark
- Tilastomallit
- TensorFlow
- XGBoost
- PREDICT vaatii , että tallennat koneoppimismallit MLflow-muodossa, jossa niiden allekirjoitukset on täytetty.
- PREDICT ei tue koneoppimismalleja, joissa on monitensorin tuloja tai -lähtöjä.
Kutsu PREDICT-kutsua muistikirjasta
PREDICT tukee MLflow-paketoituja malleja Microsoft Fabric -rekisterissä. Jos työtilassa on jo harjoitettu ja rekisteröity koneoppimismalli, voit siirtyä vaiheeseen 2. Jos näin ei ole, vaihe 1 sisältää mallikoodin, joka opastaa sinua mallin logistisen regressiomallin harjoittamisessa. Käytä tätä mallia eräennusteiden tuottamiseen prosessin lopussa.
Harjoita koneoppimismalli ja rekisteröi se MLflow'ssa. Seuraava koodinäyte käyttää MLflow API:ta luodakseen machine learning-kokeen ja käynnistää sitten MLflow-suorituksen scikit-learn-logistiselle regressiomallille. Malliversio tallennetaan ja rekisteröidään Microsoft Fabric -rekisteriin. Lisätietoja mallien kouluttamisesta ja omien kokeiden seurannasta löydät osoitteesta Kuinka kouluttaa koneoppimismalleja scikit-learnilla.
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Lataa testitiedot Spark DataFrame -kehyksenä. Jos haluat luoda eräennusteita edellisessä vaiheessa harjoitetulla koneoppimismallilla, tarvitset testitietoja Spark DataFramen muodossa. Korvaa muuttujan
testarvo seuraavassa koodissa omilla tiedoillasi.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))MLFlowTransformerLuo objekti, joka lataa koneoppimismallin päättelyä varten. Luodaksesi objektinMLFlowTransformer, joka generoi eräennusteita, suorita seuraavat toiminnot:- Määritä tarvitsemasi
testDataFrame-sarakkeet mallisyötteiksi (tässä tapauksessa kaikki). - Valitse nimi uudelle ulostulosarakkeelle (tässä tapauksessa
predictions). - Anna oikea mallin nimi ja malliversio näiden ennusteiden generointia varten.
Jos käytät omaa koneoppimismalliasi, korvaa syötesarakkeiden arvot, tulostarakkeen nimi, mallin nimi ja malliversio.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- Määritä tarvitsemasi
Luo ennusteita KÄYTTÄMÄLLÄ PREDICT-funktiota. Käytä PREDICT-funktion käynnistämiseen Transformer-ohjelmointirajapintaa, Spark SQL -ohjelmointirajapintaa tai käyttäjän määrittämää PySpark-funktiota (UDF). Seuraavissa osissa näytetään, miten luodaan eräennusteita edellisissä vaiheissa määritetyillä testitiedoilla ja koneoppimismallilla käyttämällä eri menetelmiä PREDICT-funktion kutsumiseksi.
ENNUSTA muuntajan ohjelmointirajapinnan avulla
Tämä koodi käynnistää PREDICT-funktion Transformer-ohjelmointirajapinnassa. Jos käytät omaa koneoppimismalliasi, korvaa mallin arvot ja testaa tiedot.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
ENNUSTA Spark SQL -ohjelmointirajapinnan avulla
Tämä koodi kutsuu PREDICT-funktiota käyttämällä Spark SQL API:a. Jos käytät omaa koneoppimismalliasi, vaihda arvot , model_namemodel_version, ja features mallin nimellä, malliversiolla ja ominaisuussarakkeilla.
Muistiinpano
Kun käytät Spark SQL API:ta ennusteiden luomiseen, sinun täytyy silti luoda objekti MLFlowTransformer , kuten vaiheessa 3 näytetään.
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
ENNUSTA käyttäjän määrittämällä funktiolla
Tämä koodi kutsuu PREDICT-funktiota käyttämällä PySpark UDF:ää. Jos käytät omaa koneoppimismalliasi, vaihda mallin ja ominaisuuksien arvot.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
ENNUSTA-koodin luominen koneoppimismallin kohdesivulta
Minkä tahansa koneoppimismallin tuotesivulta voit valita jonkin näistä vaihtoehdoista aloittaaksesi erävaiheen ennustamisen tietylle malliversiolle käyttämällä PREDICT-funktiota:
- Kopioi koodipohja muistikirjaan ja muokkaa parametrit itse.
- Käytä ohjattua käyttöliittymäkokemusta tuottaaksesi PREDICT-koodia.
Ohjatun käyttöliittymäkokemuksen käyttäminen
Ohjattu käyttöliittymäkokemus opastaa sinut seuraaviin vaiheisiin:
- Valitse lähdedata pisteytystä varten.
- Yhdistä data oikein koneoppimismallin syötteisiin.
- Määritä mallin ulostulojen kohde.
- Luo muistikirja, joka käyttää PREDICT-toimintoa ennustetulosten tuottamiseen ja tallentamiseen.
Jos haluat käyttää ohjattua käyttökokemusta,
Siirry tietyn koneoppimismallin version kohdesivulle.
Valitse avattavasta Käytä tätä versiota - valikosta Käytä tätä mallia ohjatussa toiminnossa.
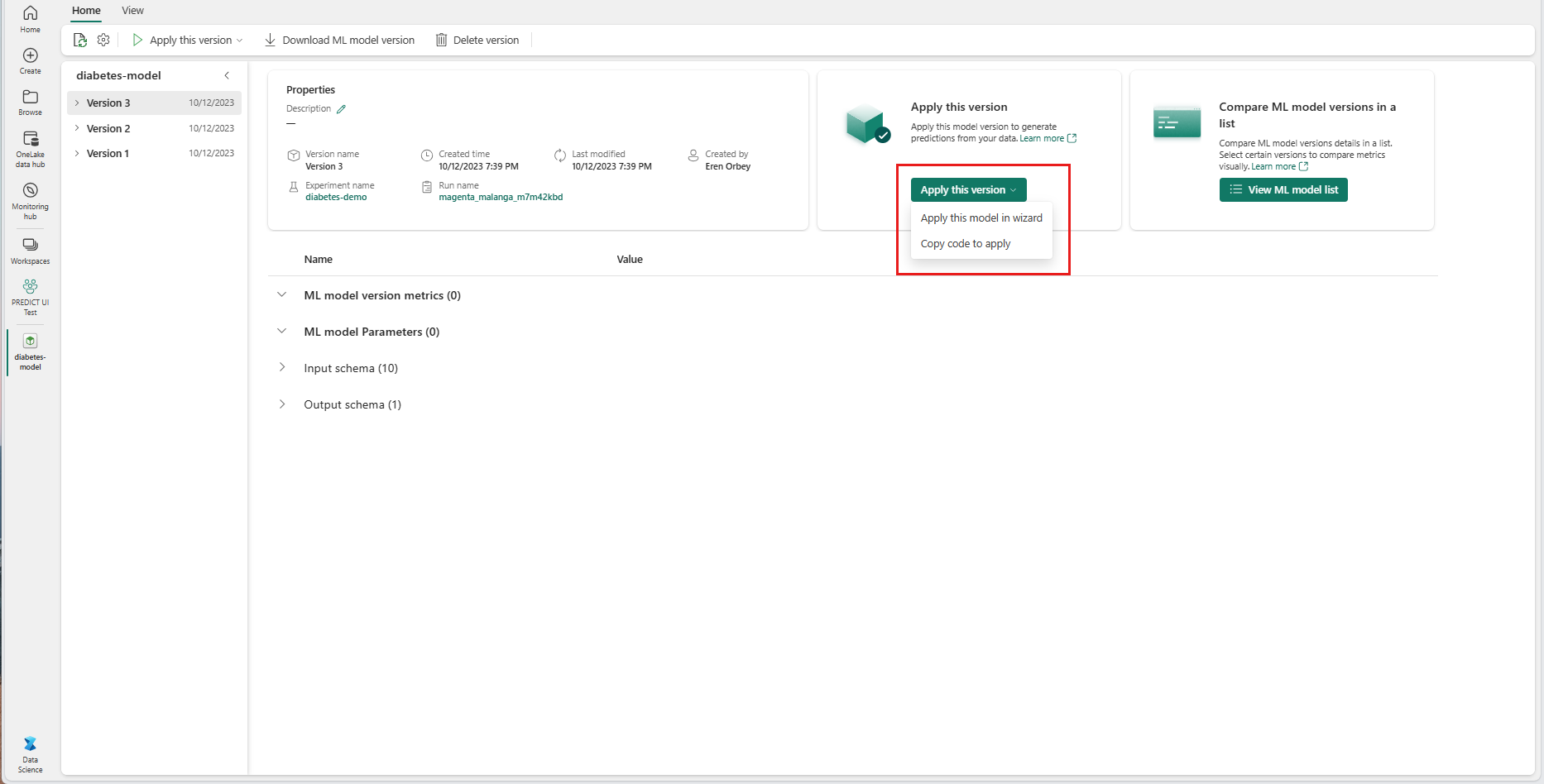
Valitse syötetaulukko -vaiheessa "Käytä koneoppimismallin ennusteita" -ikkuna avautuu.
Valitse syötetaulukko nykyisen työtilasi Lakehouse-kohdasta.
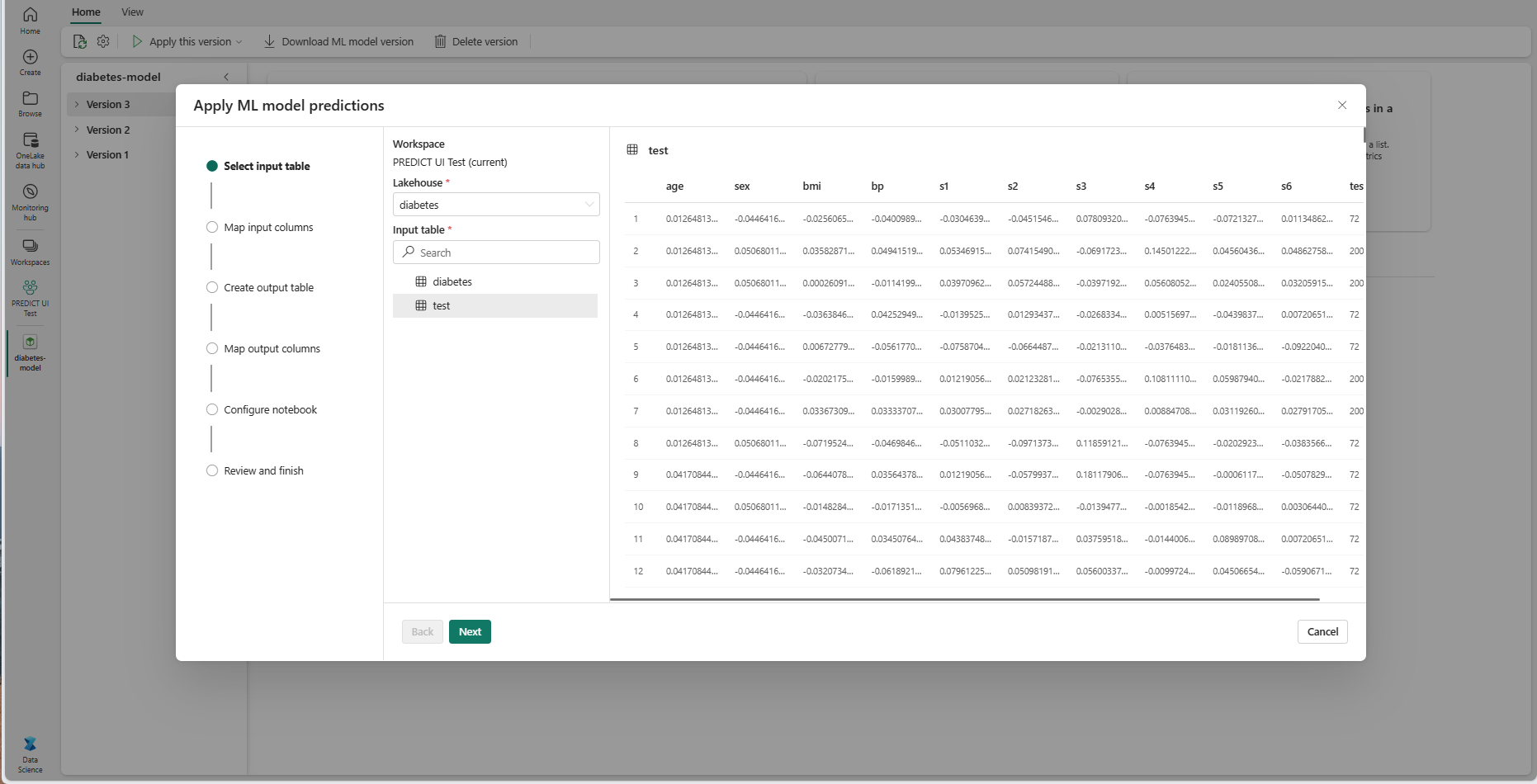
Siirry Yhdistä syötesarakkeet -vaiheeseen valitsemalla Seuraava .
Yhdistä lähdetaulukosta sarakkeiden nimet koneoppimismallin syötekenttiin, jotka nostetaan mallin allekirjoituksesta. Sinun on annettava syötesarake kaikille mallin pakollisille kentille. Lisäksi lähdesarakkeen tietotyyppien on vastattava mallin odotettuja tietotyyppejä.
Vihje
Ohjattu toiminto määrittää tämän yhdistämisen, jos syötetaulukon sarakkeiden nimet vastaavat koneoppimismallin allekirjoituksessa kirjattuja sarakkeiden nimiä.
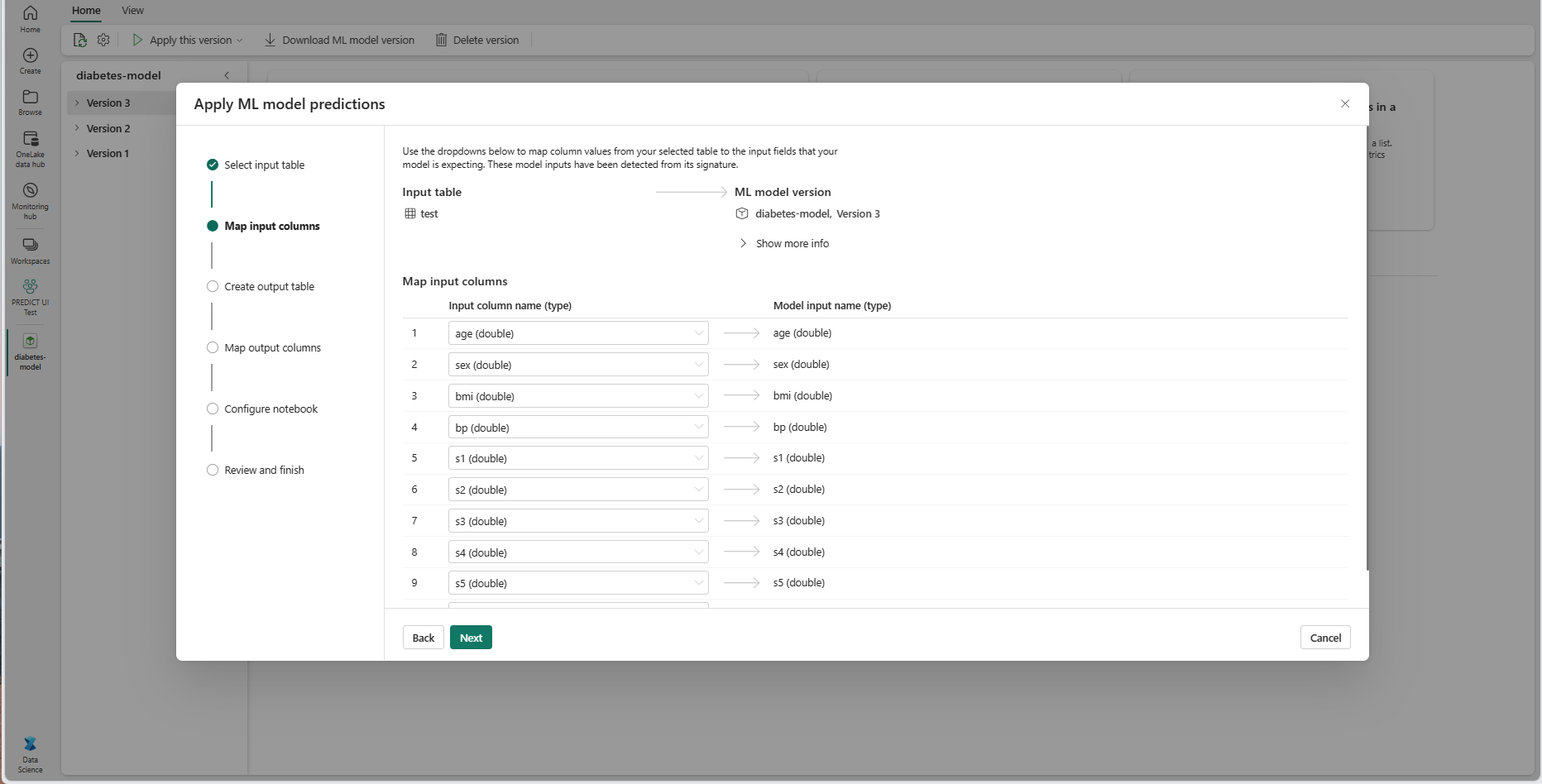
Siirry Luo tulostetaulukko -vaiheeseen valitsemalla Seuraava .
Anna nimi uudelle taulukolle nykyisen työtilasi valitussa lakehousessa. Tämä tulostetaulukko sisältää koneoppimismallin syötearvot, ja se liittää ennustearvot kyseiseen taulukkoon. Oletusarvoisesti tulostetaulukko luodaan samaan lakehouse-tallennustilaan kuin syötetaulukko. Voit muuttaa kohdetta Lakehouse.
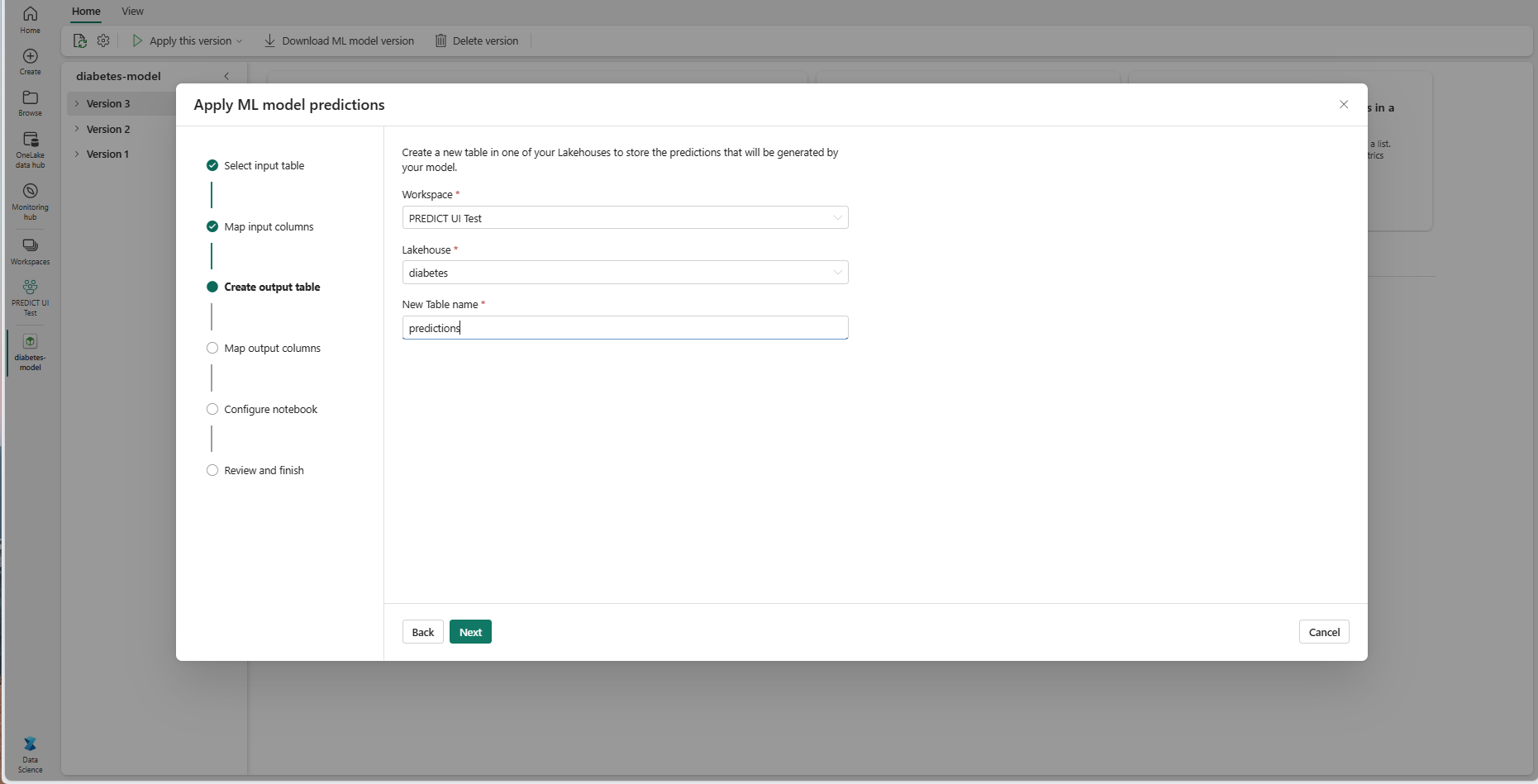
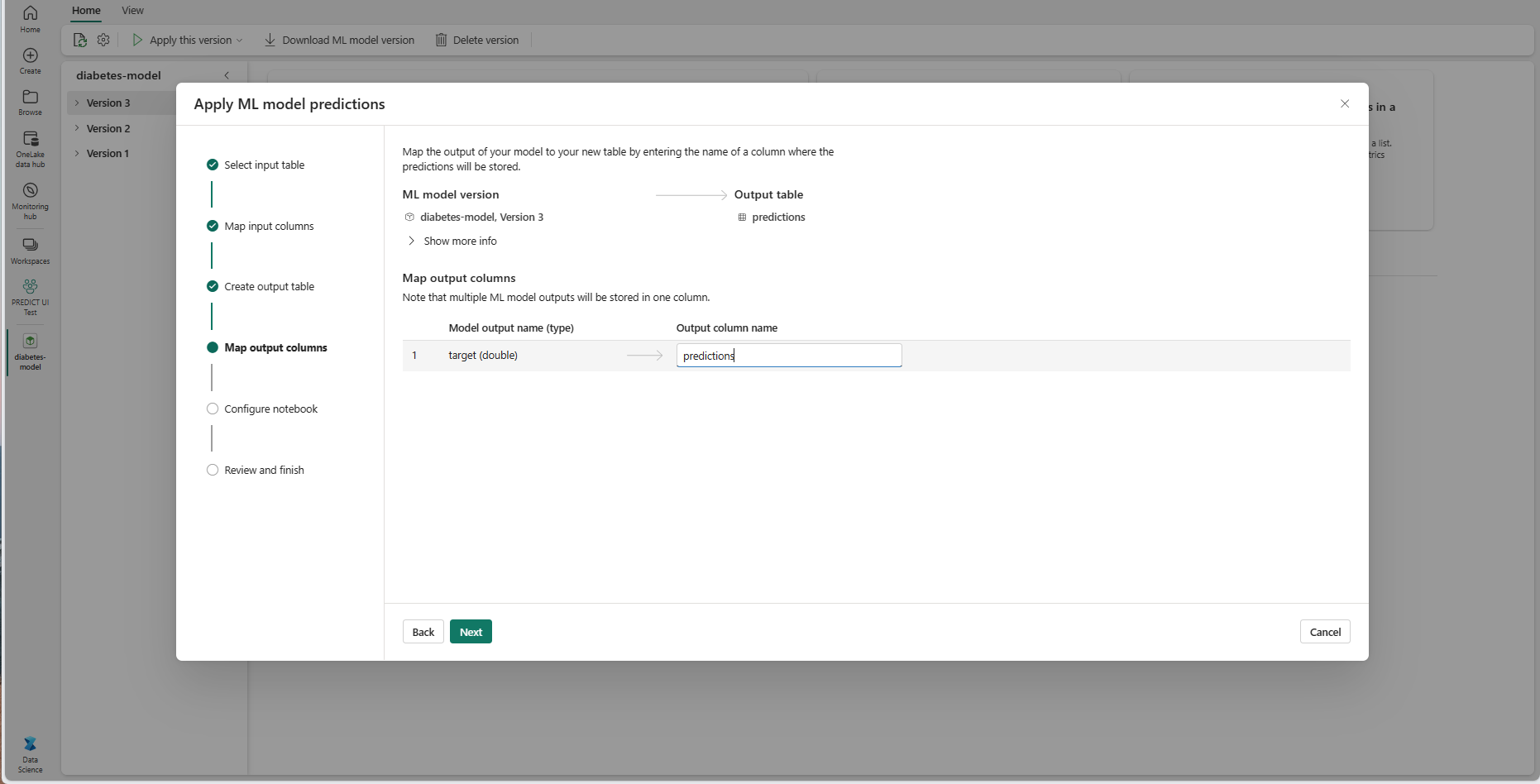
Siirry Yhdistä tulostarakkeet -vaiheeseen valitsemalla Seuraava .
Annettujen tekstikenttien avulla voit nimetä koneoppimismallin ennusteet tallentavan tulostaulukon sarakkeet.
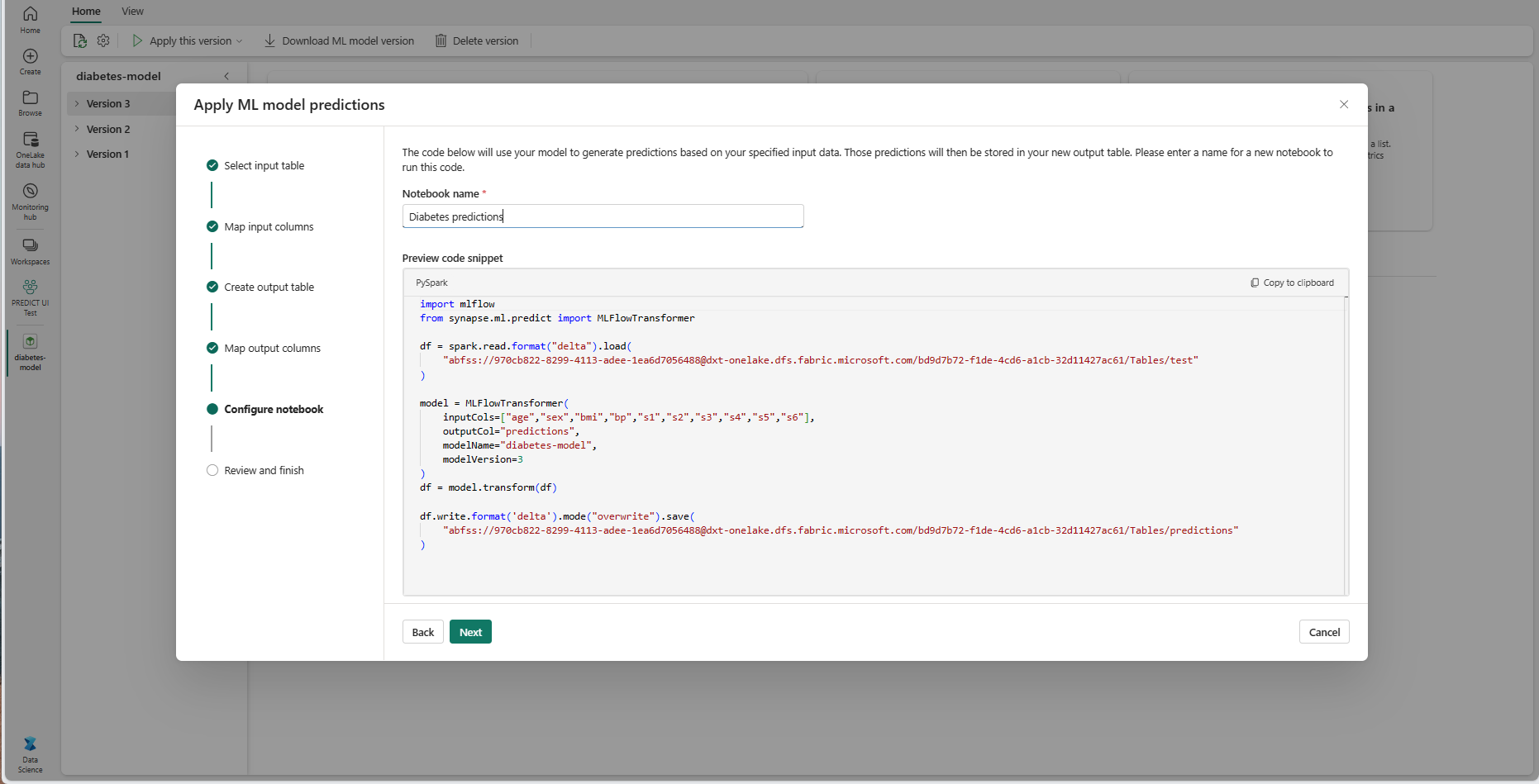
Siirry Määritä muistikirja -vaiheeseen valitsemalla Seuraava .
Anna nimi uudelle muistikirjalle, joka suorittaa luodun PREDICT-koodin. Ohjattu toiminto näyttää luodun koodin esikatselun tässä vaiheessa. Voit halutessasi kopioida koodin leikepöydälle ja liittää sen aiemmin luotuun muistikirjaan.
Siirry Tarkistus ja valmis -vaiheeseen valitsemalla Seuraava .
Tarkastele yhteenvetosivun tietoja ja valitse Luo muistikirja lisätäksesi uuden muistikirjan, jossa on luotu koodi työtilaasi. Sinut viedään suoraan siihen muistikirjaan, jossa voit suorittaa koodin ennusteiden luomiseksi ja tallentamiseksi.








Mukautettavan koodimallin käyttäminen
Koodimallin käyttäminen eräennusteiden luonnissa:
- Siirry tietyn koneoppimismalliversion kohdesivulle.
- Valitse Kopioi koodi, jota käytetään avattavasta Käytä tätä versiota -valikosta. Valinta kopioi muokattavan koodimallin.
Voit liittää tämän koodimallin muistikirjaan, jotta voit luoda eräennusteita koneoppimismallisi avulla. Jotta koodipohja suoritetaan onnistuneesti, korvaa seuraavat arvot manuaalisesti:
-
<INPUT_TABLE>: Taulukon tiedostopolku, joka tarjoaa syötteet koneoppimismallille. -
<INPUT_COLS>: Taulukko sarakkeennimiä syötetystä taulukosta, jotka syötetään ML-malliin. -
<OUTPUT_COLS>: Nimi uudelle sarakkeelle tulostaulukossa, joka tallentaa ennusteet. -
<MODEL_NAME>: ML-mallin nimi, jota käytetään ennusteiden tuottamiseen. -
<MODEL_VERSION>: ML-mallin versio, jota käytetään ennusteiden generointiin. -
<OUTPUT_TABLE>: Taulukon tiedostopolku, joka tallentaa ennusteet.

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)
Liittyvä sisältö
- Esimerkki päästä päähän -ennusteesta, jossa käytetään petosten havaitsemismallia
Kuinka kouluttaa koneoppimismalleja scikit-learnilla Microsoft Fabric