Huomautus
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
Tässä skenaariossa näytetään, miten voit muodostaa yhteyden OneLakeen Azure Databricksin kautta. Kun olet suorittanut tämän opetusohjelman, voit lukea Microsoft Fabric Lakehousea ja kirjoittaa siihen Azure Databricks -työtilastasi.
Edellytykset
Ennen kuin muodostat yhteyden, sinulla on oltava seuraavat:
- Fabric-työtila ja Lakehouse.
- Azure Databricksin premium-työtila. Vain Azure Databricksin premium-työtilat tukevat Microsoft Entran tunnistetietojen läpivientiä, jota tarvitset tässä skenaariossa.
Databricks-työtilan määrittäminen
Avaa Azure Databricks -työtilasi ja valitse Luo>klusteri.
Jotta voit todentaa OneLakeen Microsoft Entra -käyttäjätietosi, sinun on otettava käyttöön Azure Data Lake Tallennus (ADLS) -tunnistetietojen läpivienti klusterissa lisäasetuksissa.
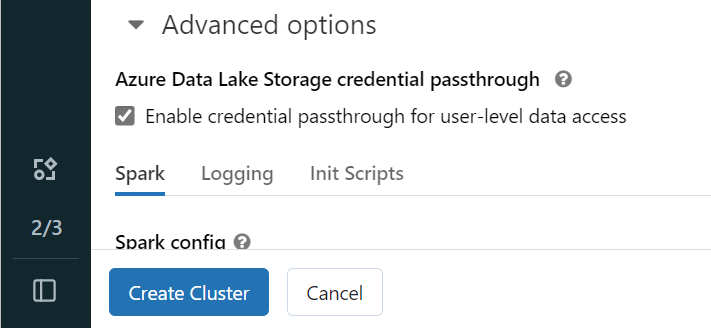
Muistiinpano
Voit myös yhdistää Databricksin OneLakeen palvelun päänimellä. Lisätietoja Azure Databricksin todentamisesta palvelun päänimen avulla on artikkelissa Palvelun päänimien hallinta.
Luo klusteri käyttäen haluamiasi parametreja. Lisätietoja Databricks-klusterin luomisesta on kohdassa Klustereiden määrittäminen – Azure Databricks.
Avaa muistikirja ja yhdistä se juuri luomaasi klusteriin.
Kirjoita muistikirjasi
Siirry Fabric Lakehouse -järvelle ja kopioi Azure Blob Filesystem (ABFS) -polku lakehouse-laitteeseesi. Löydät sen Ominaisuudet-ruudusta.
Muistiinpano
Azure Databricks tukee vain Azure Blob Filesystem (ABFS) -ohjainta, kun hän lukee ja kirjoittaa ADLS Gen2- ja OneLake-järjestelmiin:
abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/.Tallenna polku Lakehouse-taloosi Databricks-muistikirjassasi. Kirjoitat käsitellyt tietosi tässä lakehousessa myöhemmin:
oneLakePath = 'abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/myLakehouse.lakehouse/Files/'Lataa tiedot Databricksin julkisesta tietojoukosta tietokehykseen. Voit myös lukea tiedoston muualta Fabricista tai valita tiedoston toisesta ADLS Gen2 -tilistä, jonka jo omistat.
yellowTaxiDF = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-12.csv.gz")Suodata, muunna tai valmistele tietoja. Tässä skenaariossa voit rajata tietojoukkosi nopeampaa lataamista varten, liittyä muiden tietojoukkojen kanssa tai suodattaa näkyviin tiettyjä tuloksia.
filteredTaxiDF = yellowTaxiDF.where(yellowTaxiDF.fare_amount<4).where(yellowTaxiDF.passenger_count==4) display(filteredTaxiDF)Kirjoita suodatettu tietokehys Fabric Lakehouse -tallennustilaan käyttämällä OneLake-polkuasi.
filteredTaxiDF.write.format("csv").option("header", "true").mode("overwrite").csv(oneLakePath)Testaa, että tietosi on kirjoitettu onnistuneesti lukemalla juuri ladattu tiedostosi.
lakehouseRead = spark.read.format('csv').option("header", "true").load(oneLakePath) display(lakehouseRead.limit(10))
Onnittelut. Voit nyt lukea ja kirjoittaa tietoja Fabricissa Azure Databricksin avulla.