Huomautus
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
Apache Spark on yhdistetty analytiikkamoduuli laajamittaiseen tietojenkäsittelyyn.
Sparkin Kusto-liitin on avoimen lähdekoodin projekti , joka voidaan suorittaa missä tahansa Spark-klusterissa. Se toteuttaa tietolähteen ja tietoaltaanaltaan tietojen siirtämiseksi Azure Data Explorerissa ja Spark-klustereissa. Eventhousen ja Apache Sparkin avulla voit luoda nopeita ja skaalattavia sovelluksia, jotka kohdistavat aineistoperäisiin skenaarioihin. Esimerkkejä ovat koneoppiminen, Extract-Transform-Load (ETL) ja Log Analytics. Liittimen myötä Eventhouse-taloista tulee kelvollinen tietosäilö Spark-vakiolähde- ja nielutoimintoja, kuten kirjoitus-, luku- ja kirjoitustoimintoja varten.
Voit kirjoittaa Eventhouseen jonossa olevan tietojen käsittelystä tai suoratoiston käsittelystä. Reading from Eventhouses tukee sarakkeen pruning- ja predikate pushdown -toimintoa, joka suodattaa Eventhousessa olevia tietoja vähentäen siirrettyjen tietojen määrää.
Tässä artikkelissa kuvataan, miten Voit asentaa ja määrittää Spark-liittimen sekä siirtää tietoja Eventhouse- ja Apache Spark -klustereiden välillä.
Muistiinpano
Vaikka jotkin alla olevista esimerkeistä viittaavat Azure Databricks Spark -klusteriin, Spark-liitin ei hyödynnä suoria riippuvuuksia Databricksiin tai mihinkään muuhun Spark-jakaumaan.
Edellytykset
- Azure-tilaus. Luo ilmainen Azure-tili. Tätä käytetään todentamiseen Microsoft Entra -tunnuksen avulla.
- KQL-tietokanta Microsoft Fabricissa. Kopioi tämän tietokannan URI-osoite noudattamalla ohjeita kohdassa Olemassa olevan KQL-tietokannan käyttäminen.
- Spark-klusteri
- Asenna liitinkirjasto:
- Valmiit kirjastot Spark 2.4+Scala 2.11:lle tai Spark 3+scala 2.12:lle
- Maven-säilö
- Maven 3.x asennettu
Vihje
Spark 2.3.x -versioita tuetaan myös, mutta ne saattavat vaatia joitakin muutoksia pom.xml riippuvuuksiin.
Spark-liittimen luominen
Versiosta 2.3.0 alkaen esitellään uudet artefaktitunnukset, jotka korvaavat spark-kusto-connectorin: kusto-spark_3.0_2.12,12,55-kohteiden Spark 3.x ja Scala 2.12.
Muistiinpano
Versioita 2.5.1 edeltävät versiot eivät enää toimi olemassa olevan taulukon käytössä. Päivitä ne uudempaan versioon. Tämä vaihe on valinnainen. Jos käytät valmiiksi luotuja kirjastoja, kuten Maven-kirjastoja, katso Spark-klusterin määrittäminen.
Edellytykset
Katso tästä lähteestä Spark-liittimen luominen.
Jos kyseessä on Scala/Java-sovellus, joka käyttää Mavenin projektimääritelmiä, linkitä sovelluksesi uusimpaan artefaktiin. Etsi uusin artefakti Maven Centralista.
For more information, see [https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12](https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12).Jos et käytä valmiita kirjastoja, sinun on asennettava riippuvuuksissa luetellut kirjastot, mukaan lukien seuraavat Kusto Java SDK -kirjastot. Jos haluat löytää oikean version asennettavaksi, tutustu soveltuvan julkaisun säilöyn:
Jar-säätimen luominen ja kaikkien testien suorittaminen:
mvn clean package -DskipTestsRakenna purkki suorittamalla kaikki testit ja asentamalla purkki paikalliseen Maven-säilöön:
mvn clean install -DskipTests
Katso lisätietoja liittimen käytöstä.
Spark-klusterin määrittäminen
Muistiinpano
On suositeltavaa käyttää uusinta Kusto Spark -yhdistimen julkaisua, kun suoritat seuraavat vaiheet.
Määritä seuraavat Spark-klusterin asetukset Azure Databricks -klusterin Spark 3.0.1 ja Scala 2.12 perusteella:
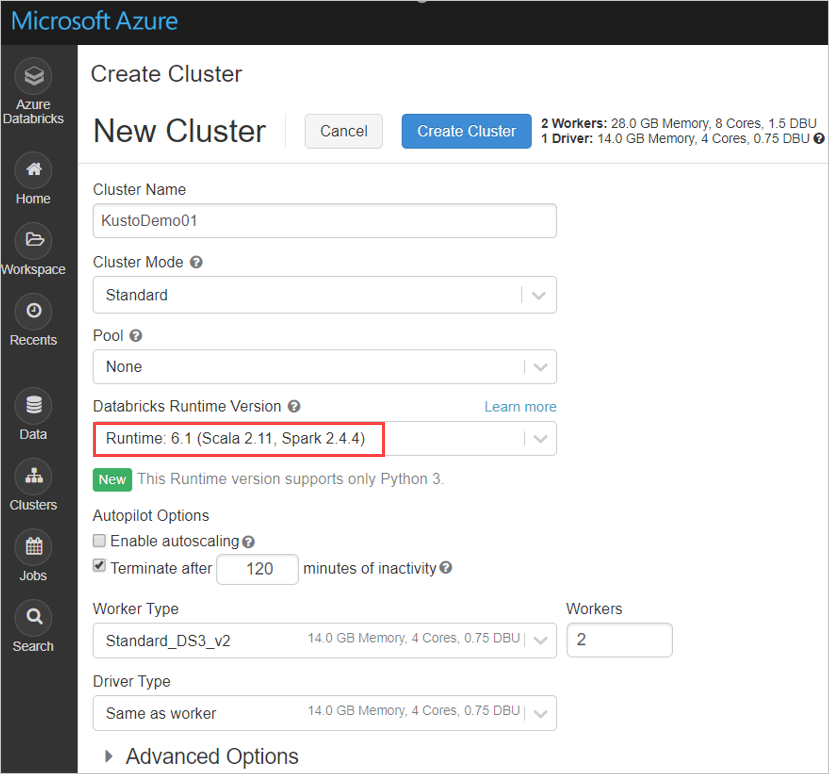
Asenna Mavenin uusin spark-kusto-connector-kirjasto:
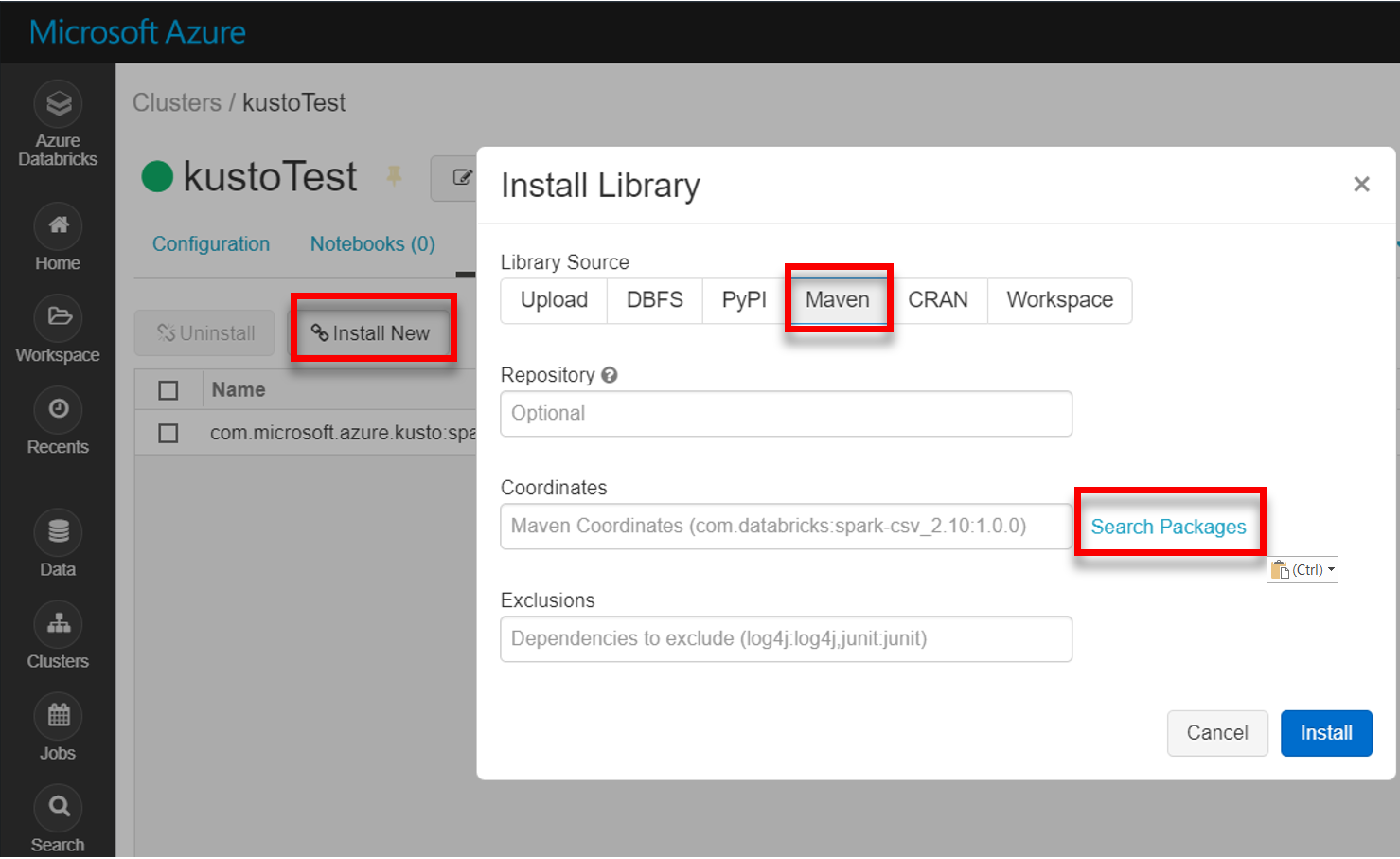
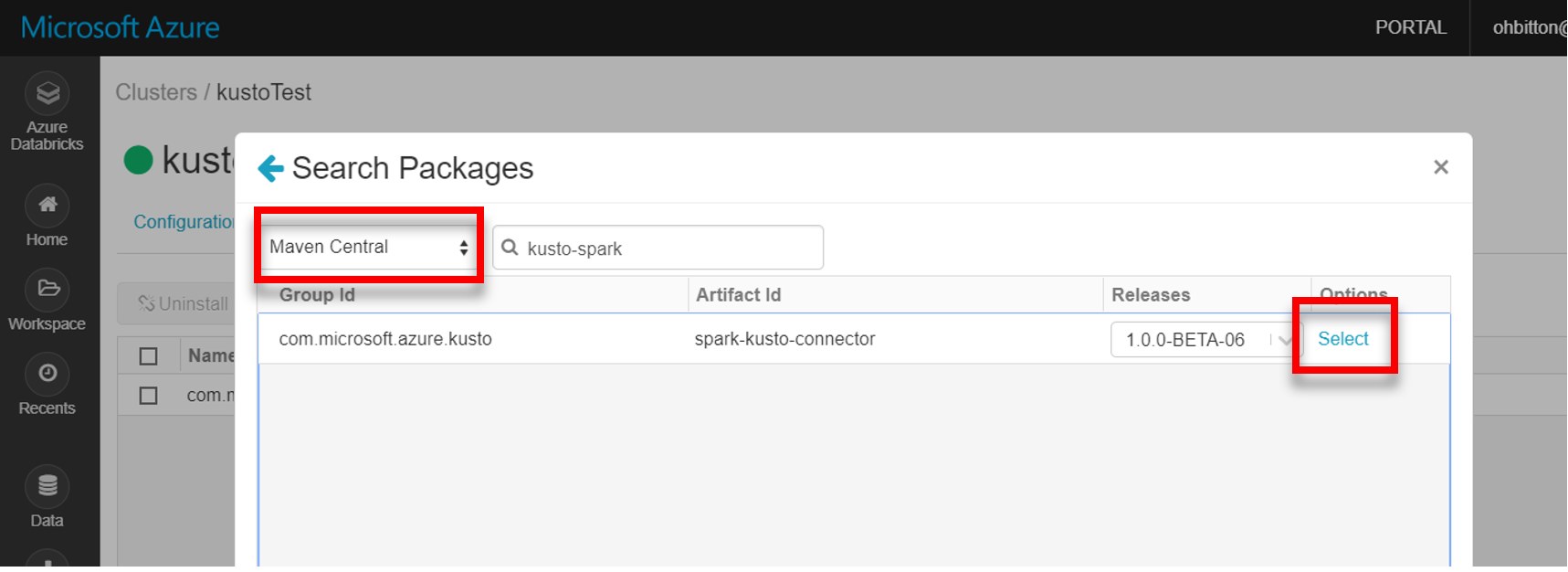
Varmista, että kaikki tarvittavat kirjastot on asennettu:
Kun asennat JAR-tiedoston avulla, tarkista asennettuna muut riippuvuudet:
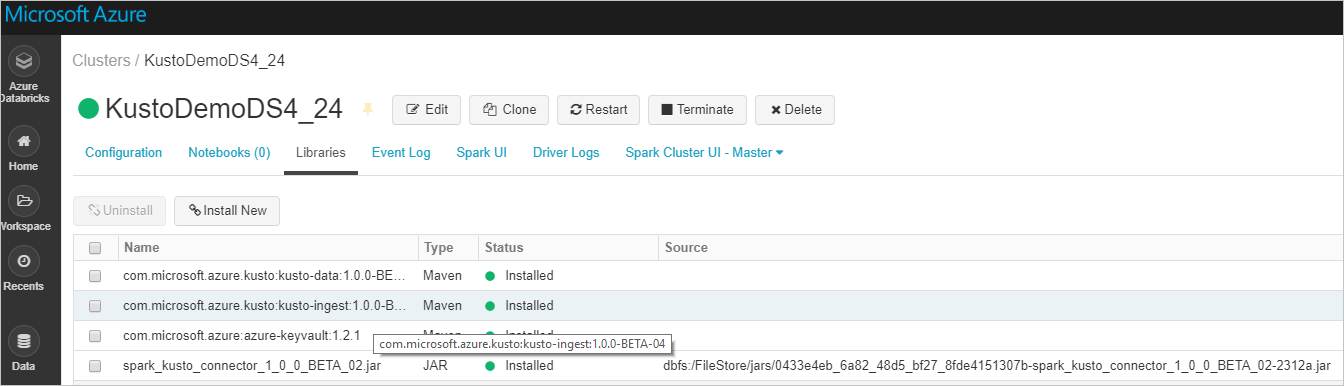
Todentaminen
Kusto Spark -yhdistimen avulla voit todentautua Microsoft Entra -tunnuksella jollakin seuraavista menetelmistä:
- Microsoft Entra -sovellus
- Microsoft Entra - käyttöoikeustietue
- Laitteen todentaminen (ei-tuotantoskenaariot)
- Azure Key Vault Key Vault Key Vault -resurssin käyttämistä varten on asennettava azure-keyvault-paketti ja annettava sovelluksen tunnistetiedot.
Microsoft Entra -sovelluksen todentaminen
Microsoft Entra -sovelluksen todentaminen on yksinkertaisin ja yleisin todentamismenetelmä, ja sitä suositellaan Kusto Spark -liittimelle.
Kirjaudu sisään Azure-tilaukseesi Azuren komentorivikäyttöliittymän kautta. Todenna sitten selaimessa.
az loginValitse tilaus, jossa isännöit päänimeä. Tätä vaihetta tarvitaan, kun sinulla on useita tilauksia.
az account set --subscription YOUR_SUBSCRIPTION_GUIDLuo palvelun päänimi. Tässä esimerkissä palvelun päänimeä kutsutaan nimellä
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}Kopioi palautetut JSON-tiedot
appIdpassword, jatenantjatkokäyttöä varten.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Olet luonut Microsoft Entra -sovelluksen ja palvelun päänimen.
Spark-liitin käyttää seuraavia Entra-sovelluksen ominaisuuksia todentamiseen:
| Ominaisuudet | Asetusmerkkijono | Kuvaus |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Microsoft Entra -sovelluksen (asiakkaan) tunniste. |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Microsoft Entra -todennuksen myöntäjä. Microsoft Entra Directoryn (vuokraajan) tunnus. Valinnainen – oletusarvo on microsoft.com. Jos haluat lisätietoja, katso Microsoft Entra authority. |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | Microsoft Entra -sovellusavain asiakkaalle. |
| KUSTO_ACCESS_TOKEN | kustoAccessToken | Jos sinulla on jo käyttöoikeustietue, joka on luotu Kusto-käyttöoikeudella, jota voidaan käyttää myös todennukseen liittimeen. |
Muistiinpano
Vanhemmissa ohjelmointirajapintaversioissa (alle 2.0.0) on seuraavat nimet: "kusto AAD ClientID", "kustoClient AAD ClientPassword", "kusto AAD AuthorityID"
Kusto-oikeudet
Myönnä seuraavat käyttöoikeudet kusto-puolella sen Spark-toiminnon perusteella, jonka haluat suorittaa.
| Spark-toiminto | Oikeudet |
|---|---|
| Lue - Yksittäinen tila | Lukija |
| Lue – Pakota hajautettu tila | Lukija |
| Write – Jonotustila, jossa on CreateTableIfNotExist-taulukon luontivaihtoehto | Järjestelmänvalvoja |
| Write – Jonotustila, jossa failIfNotExist-taulukon luontitoiminto | Ingestor |
| Write – TransactionalMode | Järjestelmänvalvoja |
Lisätietoja päärooleista on artikkelissa Roolipohjaisen käytön hallinta. Lisätietoja käyttöoikeusroolien hallinnasta on kohdassa Käyttöoikeusroolien hallinta.
Spark-pesuallas: kirjoittaminen Kustolle
Määritä nielun parametrit:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Kirjoita Spark DataFrame Kusto-klusteriin eränä:
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()Voit myös käyttää yksinkertaistettua syntaksia:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ // Optional, for any extra options: val conf: Map[String, String] = Map() val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)Kirjoita virtautettavia tietoja:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // As an alternative to adding .option by .option, you can provide a map: val conf: Map[String, String] = Map( KustoSinkOptions.KUSTO_CLUSTER -> cluster, KustoSinkOptions.KUSTO_TABLE -> table, KustoSinkOptions.KUSTO_DATABASE -> database, KustoSourceOptions.KUSTO_ACCESS_TOKEN -> accessToken) // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Spark-lähde: lukeminen Kustosta
Kun luet pieniä tietomääriä, määritä tietokysely:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)Valinnainen: Jos annat tilapäisen blob-säilön (ei Kustoa), blob-objektit luodaan soittajan vastuulla. Tämä sisältää tallennustilan valmistelun, käyttöavainten kiertämisen ja tilapäisten artefaktien poistamisen. KustoBlobStorageUtils-moduuli sisältää aputoimintofunktioita blob-objektien poistamiseen joko tilin ja säilön koordinaattien ja tilin tunnistetietojen perusteella tai täyden SAS-URL-osoitteen, jolla on kirjoitus-, luku- ja luettelo-oikeudet. Kun vastaavaa RDD:tä ei enää tarvita, jokainen tapahtuma tallentaa tilapäiset blob-artefaktit erilliseen hakemistoon. Tämä hakemisto tallennetaan osana Spark Driver -solmuun ilmoitettuja lukutapahtumien tietolokeja.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")Yllä olevassa esimerkissä Key Vaultia ei voi käyttää liittimen käyttöliittymän avulla. Käytetään yksinkertaisempaa Databricks-salaisten koodien käyttötapaa.
Lue Kustosta.
Jos annat tilapäisen blob-säilön, lue Kustosta seuraavasti:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Jos Kusto tarjoaa tilapäisen blob-säilön, lue Kustosta seuraavasti:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)
Liittyvä sisältö
- Kusto Spark Connectorin GitHub-säilö
- Katso Scala- ja Python-mallikoodi