Muistiinpano
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
Power BI:n näytteenottoalgoritmi parantaa visuaaleja, jotka ottavat tiheän datan näytteen. Esimerkiksi voit luoda rivikaavion vähittäismyymälöidesi myyntituloksista, joissa jokaisella myymälällä on yli 10 000 myyntikuittia vuosittain. Tällaisista myyntitiedoista koostuvat viivakaaviot ottavat dataa jokaisesta myymälästä ja muodostavat monisarjaisen viivakaavion, joka edustaa taustalla olevaa dataa. Valitse merkityksellinen esitys kyseisestä datasta havainnollistamaan, miten myynti vaihtelee ajan myötä. Tämä käytäntö on yleinen tiheän datan visualisoinnissa. Tässä artikkelissa kuvataan tiheän datan otannan yksityiskohdat.
Note
Tässä artikkelissa kuvattu korkean tiheyden otantaalgoritmi on saatavilla sekä Power BI Desktopissa että Power BI -palvelussa.
Miten tiheä viivaotanta toimii
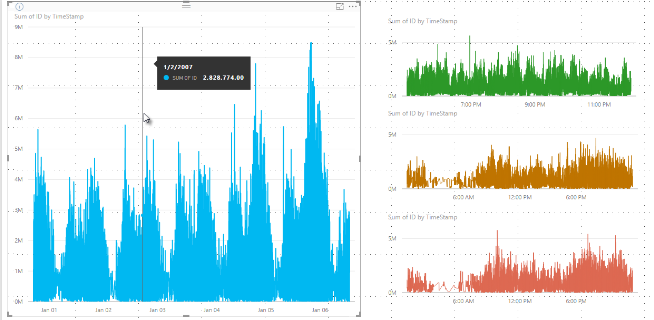
Aiemmin Power BI valitsi kokoelman näytepisteitä koko taustalla olevan datan kirjosta deterministisesti. Esimerkiksi, kun visuaalissa on tiheää dataa, joka kattaa yhden kalenterivuoden, visuaalinen näyttää 350 näytepistettä. Algoritmi valitsee jokaisen datapisteen varmistaakseen, että koko datavalikoima esitetään visuaalissa. Tämän ymmärtämiseksi kuvittele, että piirrät osakekurssin yhden vuoden ajalta ja valitset 365 datapistettä luodaksesi viivakaavion visuaalin. Se on yksi datapiste jokaiselle päivälle.
Tällaisessa tilanteessa on useita arvoja osakkeen hinnalle joka päivä. Tietenkin on päivittäinen huippu ja pohja, mutta nuo arvot voivat tapahtua milloin tahansa päivän aikana, kun osakemarkkinat ovat auki. Tiheässä viivaotannassa, jos taustalla oleva datanäyte otetaan päivittäin klo 10.30 ja 12.00, saat edustavan tilannekuvan taustatiedoista, kuten hinnan klo 10.30 ja 12.00. Kuitenkin tilannekuva ei välttämättä kuvaa kyseisen päivän edustavan datapisteen todellista osakkeen hintaa ja pohjaa. Tässä ja muissa tilanteissa otanta edustaa taustalla olevaa dataa, mutta se ei aina kata tärkeitä pisteitä, jotka tässä tapauksessa tarkoittaisivat päivittäisiä osakekurssien huippuja ja pohjalukemia.
Määritelmän mukaan tiheän datan näytteitä otetaan luomaan visualisointeja kohtuullisen nopeasti, jotka reagoivat interaktiivisuuteen. Liian moni datapiste visuaalissa voi hidastaa sitä ja heikentää trendien näkyvyyttä. Se, miten data otetaan näytteenotteesta, ohjaa näytteenottoalgoritmin luomista parhaan visualisointikokemuksen saavuttamiseksi. Power BI Desktopissa algoritmi tarjoaa parhaan yhdistelmän reagointia, esitystä ja tärkeiden pisteiden selkeää säilymistä jokaisessa aikaviipaleessa.
Miten viivanotantaalgoritmi toimii
Korkean tiheyden viivaotannan algoritmi on käytettävissä viivakaavio- ja pinta-alakaavioiden visuaaleihin, joissa on jatkuva x-akseli.
Tiheän visuaalin saamiseksi Power BI pilkoo tietosi älykkäästi korkean resoluution osiin ja valitsee tärkeät kohdat kunkin lohkon edustamiseksi. Korkearesoluutioisen datan leikkausprosessi on säädetty siten, että tuloksena oleva kaavio on visuaalisesti erottamaton kaikkien taustalla olevien datapisteiden renderöinnistä, mutta on nopeampi ja vuorovaikutteisempi.
Minimi- ja maksimiarvot tiheälle viivavisualisoinnille
Visualisoinnissa koskevat seuraavat rajoitukset:
- 3 500 on suurin määrä datapisteitä, jotka näytetään useimmissa visuaaleissa, riippumatta taustalla olevien datapisteiden tai sarjojen määrästä. Poikkeuksia varten katso seuraava lista. Esimerkiksi, jos sinulla on 10 sarjaa, joissa kussakin on 350 datapistettä, visuaalinen saavutus saavuttaa maksimirajansa. Jos sinulla on yksi sarja, siinä voi olla jopa 3 500 datapistettä, jos algoritmi katsoo sen parhaaksi otantaksi taustalla olevalle datalle.
- Kaikissa visuaaleissa on enintään 60 sarjaa . Jos sinulla on yli 60 sarjaa, jaa data ja luo useita visuaaleja, joissa on 60 tai vähemmän sarjaa kussakin. On hyvä käytäntö käyttää viipalointia näyttämään vain osia datasta, mutta vain tietyille sarjoille. Esimerkiksi, jos näytät kaikki alikategoriat legendassa, voisit käyttää viipalointityökalua suodattamaan koko kategorian mukaan samalla raporttisivulla.
Datarajojen enimmäismäärä on suurempi seuraaville visuaalisille tyypeille, jotka ovat poikkeuksia 3 500 datapisteen rajasta:
- Enintään 150 000 datapistettä R-visuaaleille.
- 30 000 datapistettä Azure Map -visualisaatioille.
- 10 000 datapistettä joillekin scatter-kaaviokonfiguraatioille (hajontakaaviot ovat oletuksena 3 500).
- 3 500 kaikista muista visuaaleista, joissa käytetään tiheyttä näytteenottoa. Jotkut muut visuaalit saattavat visualisoida enemmän dataa, mutta niissä ei käytetä näytteenottoa.
Nämä parametrit varmistavat, että Power BI Desktopin visuaalit renderöityvät nopeasti, reagoivat käyttäjän vuorovaikutukseen eivätkä aiheuta kohtuutonta laskentakuormaa tietokoneelle, joka renderöi visuaalin.
Arvioi edustavia datapisteitä tiheästi tiheissä viivakuvissa
Kun taustalla olevien datapisteiden määrä ylittää visuaalin esittämän maksimipisteen, alkaa prosessi nimeltä binning . Binnointi jakaa taustalla olevan datan ryhmiin, joita kutsutaan bineiksi ja sitten tarkentaa näitä binejä iteratiivisesti.
Algoritmi luo mahdollisimman monta biniä, jotta visuaalinen sisältö saadaan mahdollisimman tarkalle. Jokaisessa binissä algoritmi löytää minimi- ja maksimidatan arvon varmistaakseen, että tärkeät ja merkittävät arvot, kuten poikkeavat, tallennetaan ja näytetään visuaalissa. Binning-tulosten ja Power BI:n myöhemmän datan arvioinnin perusteella määritetään visuaalisen x-akselin minimitarkkuus varmistamaan visuaalin maksimaalinen tarkkuus.
Kuten aiemmin mainittiin, kunkin sarjan minimitarkkuus on 350 pistettä ja maksimi 3 500 useimmissa visuaaleissa. Poikkeukset on lueteltu edellisessä osiossa.
Jokainen bin-piste esitetään kahdella datapisteellä, jotka muodostavat binin edustavat datapisteet visuaalissa. Datapisteet ovat kyseisen binin korkein ja matala arvo. Valitsemalla korkeat ja matalat arvot binning-prosessi varmistaa, että kaikki tärkeät high value tai merkittävät matalat arvot tallennetaan ja renderöidään visuaalissa.
Jos tuo prosessi kuulostaa paljon analyysiltä, jotta satunnaiset poikkeamat saadaan tallennettua ja näytetään oikein visuaalissa, olet oikeassa. Tämä on juuri se syy algoritmille ja binning-prosessille.
Työkaluvihjeet ja tiheän viivaotannan käyttö
Binning-prosessi tallentaa ja näyttää minimiarvon ja maksimiarvon tietyssä binissä. Tämä prosessi voi vaikuttaa siihen, miten työkaluvihjeet näyttävät dataa, kun viet hiiren datapisteiden päälle. Selittääksemme, miten ja miksi tämä prosessi vaikuttaa työkaluvihjeisiin, tarkastellaan esimerkkiämme osakekursseista.
Luot visuaalisen kuvan osakekurssin perusteella ja vertaat kahta eri osaketta, jotka molemmat käyttävät korkean tiheyden otantaa. Jokaisen sarjan taustalla oleva data sisältää monia datapisteitä. Esimerkiksi saat osakkeen hinnan joka sekunti päivässä. Korkean tiheyden viivanotantaalgoritmi suorittaa binningin jokaiselle sarjalle erillään toisistaan.
Nyt ensimmäisen osakkeen hinta nousee klo 12:02 ja laskee nopeasti takaisin 10 sekunnin kuluttua. Se on tärkeä datapiste. Kun kyseiselle osakkeelle tehdään binning, korkein arvo kohdassa 12:02 on edustava datapiste kyseiselle binille.
Toisen osakkeen kohdalla 12:02 ei kuitenkaan ole huippu eikä pohja siinä laatikossa, johon tuo aika sisältyy. Ehkä 12:02 sisältävän roskiksen ylä- ja matalimmat hetket tapahtuvat kolme minuuttia myöhemmin. Tällaisessa tilanteessa, kun viivakaavio luodaan ja viet hiiren 12:02 päälle, näet työkaluvihjeessä arvon ensimmäiselle osakkeelle. Tämä arvo on olemassa, koska ensimmäinen osake hyppää kohdassa 12:02 ja algoritmi valitsee kyseisen arvon binin korkeimmaksi datapisteeksi. Kuitenkin et näe mitään arvoa työkaluvihjeessä kohdassa 12:02 toisen osakkeen kohdalla. Toisessa varastossa ei ollut korkeinta tai pohjaa laatikolle, joka sisälsi 12:02. Siksi toisen osakkeen kohdalla 12:02 ei ole näytettävää dataa, joten työkaluvihjetietoja ei näytetä.
Tämä tilanne tapahtuu usein työkaluvihjeiden kanssa. Tietyn binin korkeat ja matalat arvot eivät todennäköisesti täsmää täydellisesti tasaisesti skaalattujen x-akselin arvopisteiden kanssa, joten työkaluvihje ei näytä arvoa.
Ota käyttöön tiheä viivanäytteenotto
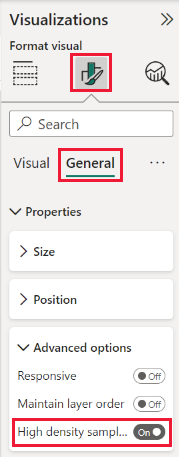
Oletuksena algoritmi on päällä. Muuttaaksesi tämän asetuksen, mene Muotoilu-paneeliin Yleisessä kortissa, ja alareunassa näet Korkean tiheyden näytteenottoliukusäädin. Valitse liukusäädin, jolla voit kytkeä päälle tai pois.
Huomioitavat asiat ja rajoitukset
Korkean tiheyden viivaotannan algoritmi on tärkeä parannus Power BI:hin, mutta on muutama seikka, jotka sinun tulee tietää työskennellessäsi korkean tiheyden arvojen ja datan kanssa.
- Koska tarkkuus ja binning-prosessi ovat lisääntyneet, työkaluvihjeet saattavat näyttää arvon vain, jos edustava data on linjassa kursorisi kanssa. Lisätietoja löytyy tämän artikkelin Työkaluvihjeistä ja korkean tiheyden viivaotanta-osiosta .
- Kun koko tietolähteen koko on liian suuri, algoritmi poistaa sarjat (legendaelementit) täyttääkseen datan tuonnin maksimirajoituksen.
- Tässä tilanteessa algoritmi järjestää legendasarjat aakkosjärjestykseen. Se aloittaa legendaelementtien listan aakkosjärjestyksessä, kunnes datan tuontimaksimi saavutetaan, eikä se tuo lisää sarjoja.
- Kun taustalla olevalla aineistolla on yli 60 sarjaa, eli suurin sarjojen määrä, algoritmi järjestää sarjat aakkosjärjestykseen ja poistaa sarjat yli 60. aakkosjärjestyksen sarjan.
- Jos datan arvot eivät ole numeerisia tai päivämäärä/aika-tyyppejä, Power BI ei käytä algoritmia ja palaa aiempaan, ei-korkean tiheyden otantaalgoritmiin.
- Algoritmi ei tue Näytä kohteita ilman data-asetusta .
- Algoritmia ei tueta, kun käytetään reaaliaikaista yhteyttä malliin, joka on isännöity SQL Server Analysis Servicesin versiossa 2016 tai sitä aiemmin. Sitä tuetaan malleissa, jotka on isännöity Power BI :ssä tai Azure Analysis Servicesissä.