Tutustu stream-käsittelyarkkitehtuurin yleisiin elementteihin
Voit käyttää monia tekniikoita suoratoiston käsittelyratkaisun käyttöönottoon, mutta vaikka tietyt toteutustiedot saattavat vaihdella, useimmissa suoratoistoarkkitehtuurissa on yleisiä elementtejä.
Streamin käsittelyn yleinen arkkitehtuuri
Yksinkertaisimmillaan korkean tason arkkitehtuuri suoratoiston käsittelyssä näyttää tältä:
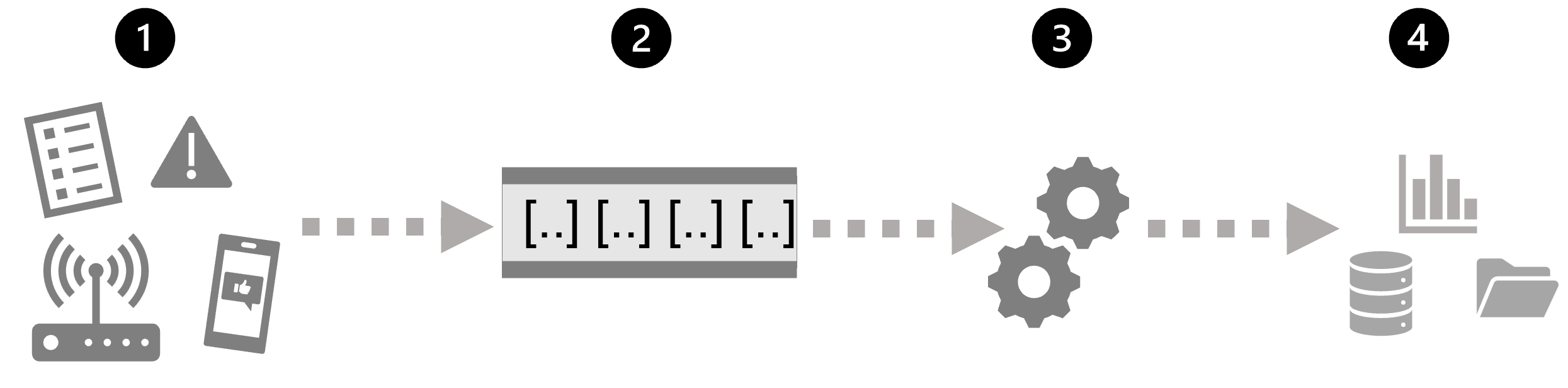
- Tapahtuma luo joitakin tietoja. Tämä voi olla anturin lähettämä signaali, julkaistava sosiaalisen median viesti, kirjoitettava lokitiedostomerkintä tai mikä tahansa muu esiintymä, joka johtaa johonkin digitaaliseen tietoon.
- Luodut tiedot tallennetaan suoratoistettavaan lähteeseen käsiteltäviksi. Yksinkertaisissa tapauksissa lähde voi olla kansio pilvipalvelutietosäilössä tai taulukko tietokannassa. Vankemmissa virtautusratkaisuissa lähde voi olla "jono", joka kiteyttää logiikan sen varmistamiseksi, että tapahtumatiedot käsitellään järjestyksessä ja että kutakin tapahtumaa käsitellään vain kerran.
- Tapahtumatiedot käsitellään usein jatkuvalla kyselyllä, joka käyttää tapahtumatietoja valitakseen tietyntyyppisten tapahtumien, projektitietojen tai koostetietojen tiedot ajallisille (aikaan perustuville) jaksoille (tai ikkunoille) koskevia tietoja esimerkiksi laskemalla tunnistimien päästöjen määrän minuutissa.
- Streamin käsittelytoiminnon tulokset kirjoitetaan tulosteeseen (tai nieluun), joka voi olla tiedosto, tietokantataulukko, reaaliaikainen visualisoinnin koontinäyttö tai toinen jono myöhempää jatkokäsittelykyselyä varten.
Reaaliaikaiset analytiikkapalvelut
Microsoft tukee useita tekniikoita, joiden avulla voit toteuttaa reaaliaikaisia analyyseja suoratoistotiedoilla, kuten:
- Azure Stream Analytics: Käyttöympäristö palveluna (PaaS) -ratkaisu, jonka avulla voit määrittää virtautettavia töitä , jotka käyttävät tietoja virtautuslähteestä, käyttävät jatkuvaa kyselyä ja kirjoittavat tulokset tulosteeseen.
- Spark Structured Streaming: Avoimen lähdekoodin kirjasto, jonka avulla voit kehittää monimutkaisia virtautusratkaisuja Apache Spark -pohjaisissa palveluissa, kuten Microsoft Fabricissa ja Azure Databricksissä.
- Microsoft Fabric: Korkean suorituskyvyn tietokanta- ja analytiikkaalusta, joka sisältää Data Engineeringin, Data Factoryn, Data Sciencen, Real-Time Intelligencen, Data Warehousen ja tietokannat.
Tietovirtojen käsittelyn lähteet
Seuraavia palveluita käytetään yleisesti tietojen käsittelyyn Streamin käsittelyssä Azuressa:
- Azure-tapahtumatoiminnot: Tietojen käsittelypalvelu, jonka avulla voit hallita tapahtumatietojen jonoja ja varmistaa, että kutakin tapahtumaa käsitellään järjestyksessä täsmälleen kerran.
- Azure IoT Hub: Azure-tapahtumatoimintojen kaltainen tietojen käsittelypalvelu, joka on optimoitu hallitsemaan tapahtumatietoja Internet-laitteista (IoT).
- Azure Data Lake Store Gen 2: Erittäin skaalattava tallennuspalvelu, jota käytetään usein erän käsittelytilanteissa , mutta sitä voidaan käyttää myös virtautettavien tietojen lähteenä.
- Apache Kafka: Avoimen lähdekoodin tietojen käsittelyratkaisu, jota käytetään yleisesti yhdessä Apache Sparkin kanssa.
Nielut virran käsittelyä varten
Tietovirran käsittelyn tulokset lähetetään usein seuraaviin palveluihin:
- Azure-tapahtumatoiminnot: Tämä siirtää käsitellyt tiedot jonoon jatkokäsittelyä varten.
- Azure Data Lake Store Gen 2, Microsoft OneLake tai Azure Blob -säilö: Tätä käytetään käsiteltyjen tulosten säilyttämiseen tiedostona.
- Azure SQL -tietokanta, Azure Databricks tai Microsoft Fabric: Näitä käytetään käsiteltyjen tulosten säilymiseen kysely- ja analyysitaulukossa.
- Microsoft Power BI: Käytetään reaaliaikaisten tietojen visualisointien luomiseen raporteissa ja koontinäytöissä.