SQL- ja spark-poolien välisten integrointimenetelmien kuvaus Azure Synapse Analyticsissa
Luomalla analyysiratkaisuja Azure Synapse Analyticsissa sinun ei enää tarvitse määrittää useita palveluita, jotka yhdistävät Apache Spark -klusterin SQL-tietokantaan. Azure Synapse Analytics -ympäristön avulla voit käyttää molempia tekniikoita yhdessä integroidussa ympäristössä. Integroidun käyttöympäristön avulla voit vaihtaa Apache Spark- ja SQL-pohjaisten tietotekniikkatehtävien välillä, jotka soveltuvat talon sisäiseen asiantuntemukseen. Tämän seurauksena Apache Sparkiin suuntautunut tietoteknikko voi helposti viestiä ja työskennellä SQL-pohjaisen tietoteknikkojen kanssa samassa ympäristössä.
Apache Sparkin ja SQL:n yhteentoimivuus auttaa saavuttamaan seuraavat:
- Käytä SQL:ää ja Apache Sparkia ja tutki ja analysoi suoraan Data Lake -järjestelmään tallennettuja Parquet-, CSV-, TSV- ja JSON-tiedostoja.
- Ota käyttöön nopeat ja skaalattavat kuormitukset tietojen siirtämiseksi SQL- ja Apache Spark -tietokantojen välillä.
- Hyödynnä jaettua Hive-yhteensopivaa metatietojärjestelmää, jonka avulla voit määrittää Data Lake -tallennustilassa olevien tiedostojen taulukot niin, että niitä voi käyttää joko Apache Spark- tai Hive-järjestelmässä.
Esiin tulee kysymys SIITÄ, miten SQL ja Apache Spark -integrointi toimivat. Tässä tulee kyse Azure Synapse Apache Sparkistä Synapse SQL:ään -liittimestä.
Azure Synapse Apache Spark to Synapse SQL -liitin on suunniteltu siirtämään tietoja tehokkaasti palvelimettomien Apache Spark -poolien ja erillisiä SQL-varantoja välillä Azure Synapessa. Tällä hetkellä Azure Synapse Apache Spark to Synapse SQL -liitin toimii vain erillisissä SQL-varannoissa. Se ei toimi palvelimettomien SQL-varantojen kanssa.
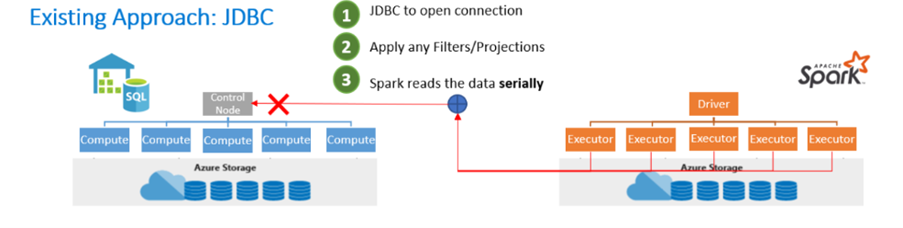
Olemassa olevassa lähestymistavassa näet usein JavaDataBaseConnectivity (JDBC) Application Programming Interfacen (API) käytön. JDBC-ohjelmointirajapinta avaa yhteyden, suodattaa ja ottaa käyttöön ennusteita, ja Apache Spark lukee tiedot sarjaittain. Kun otetaan huomioon, että kahta hajautettua järjestelmää, kuten Apache Spark- ja SQL-varantoa, käytetään, JDBC-ohjelmointirajapinnan käytöstä tulee pullonkaula, joka siirtää tietoja sarjasijainnilla.
Siksi uusi tapa on käyttää sekä JDBC:tä että PolyBasea. Ensin JDBC avaa yhteyden ja myöntää Create External Tables As Select (CETAS) -lausekkeet ja lähettää suodattimia ja ennusteita. Suodattimia ja ennusteita käytetään sitten tietovarastoon, ja ne viedään tietoja rinnakkain PolyBase-tietokannalla. Apache Spark lukee tiedot rinnakkain käyttäjän valmisteleman työtilan ja oletusarvoisen Data Lake -tallennustilan perusteella.

Tämän seurauksena voit käyttää Azure Synapse Apache Spark Poolia Synapse SQL -liittimeen siirtääksesi tietoja Data Lake -säilön välillä Apache Sparkin ja erillisiä SQL-varantoja käyttämällä tehokkaasti.